Download as PDF, PPTX







![OpenMPIのPTLとしてTCPを指定し
OpenOnloadに適したチューニングを⾏行行う
OpenMPIのスタックとしてOpenOnloadを用いるときのチューニングパラメータ
[/etc/openmpi-x86_64/openmpi-mca-params.conf]
btl_tcp_if_include = eth4,eth5
btl_tcp_if_exclude = lo,eth0,eth1
btl_tcp_bandwidth = 12500
btl_tcp_latency = 1](https://image.slidesharecdn.com/gpuclusterinterconnect-lowlatencyethernet-130622022501-phpapp01/75/10Gb-Ethernet-GPU-24-2048.jpg)
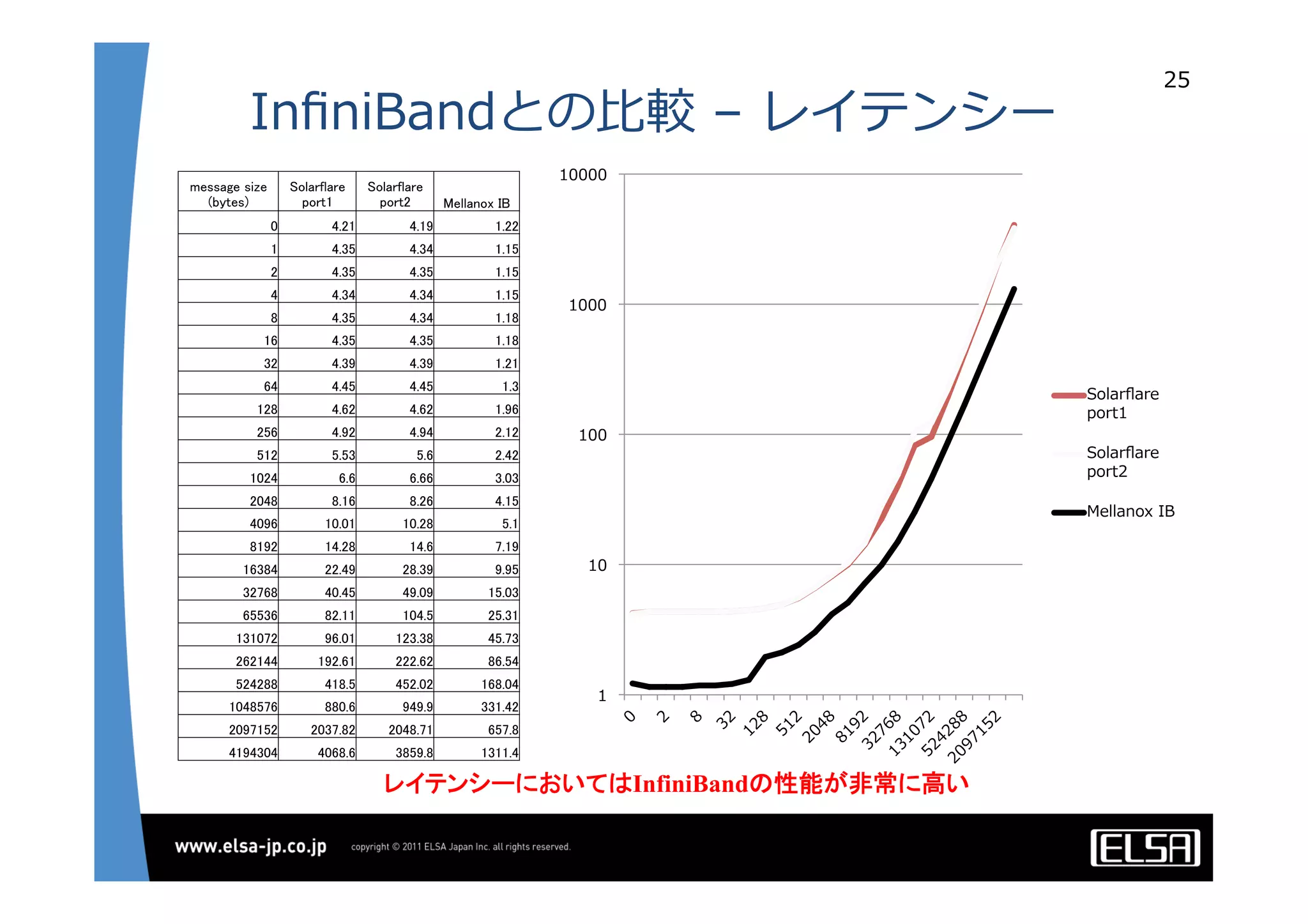
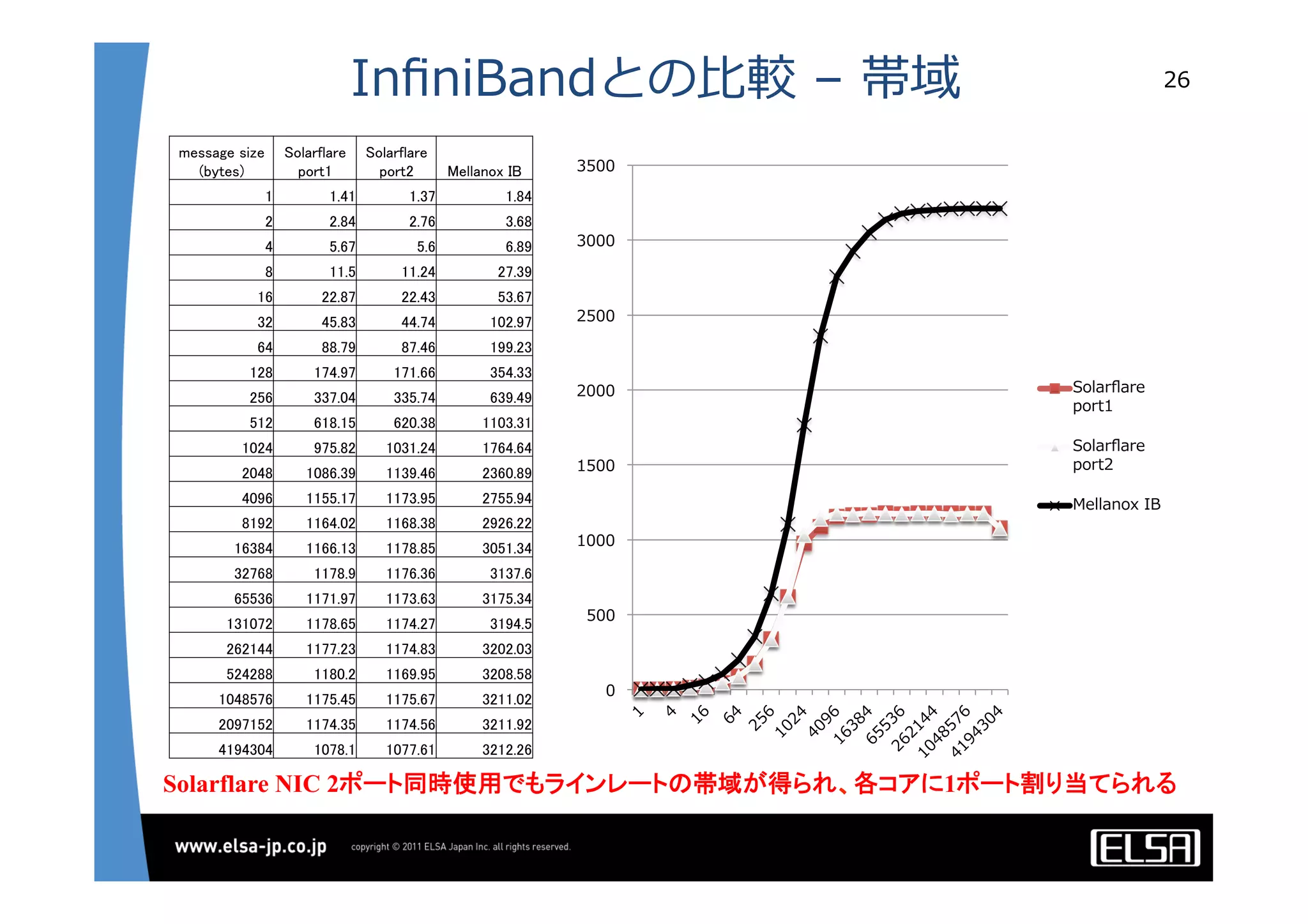



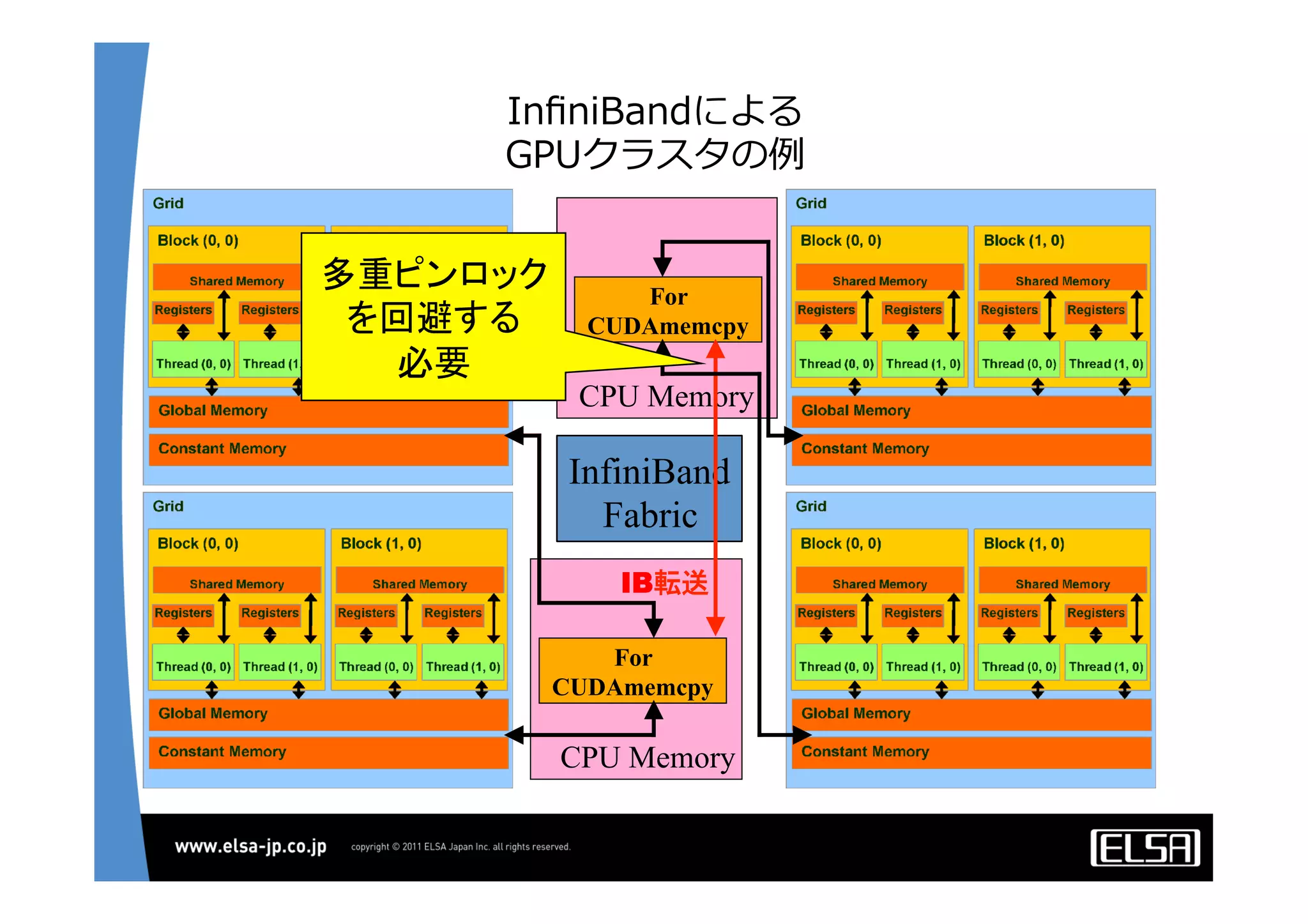
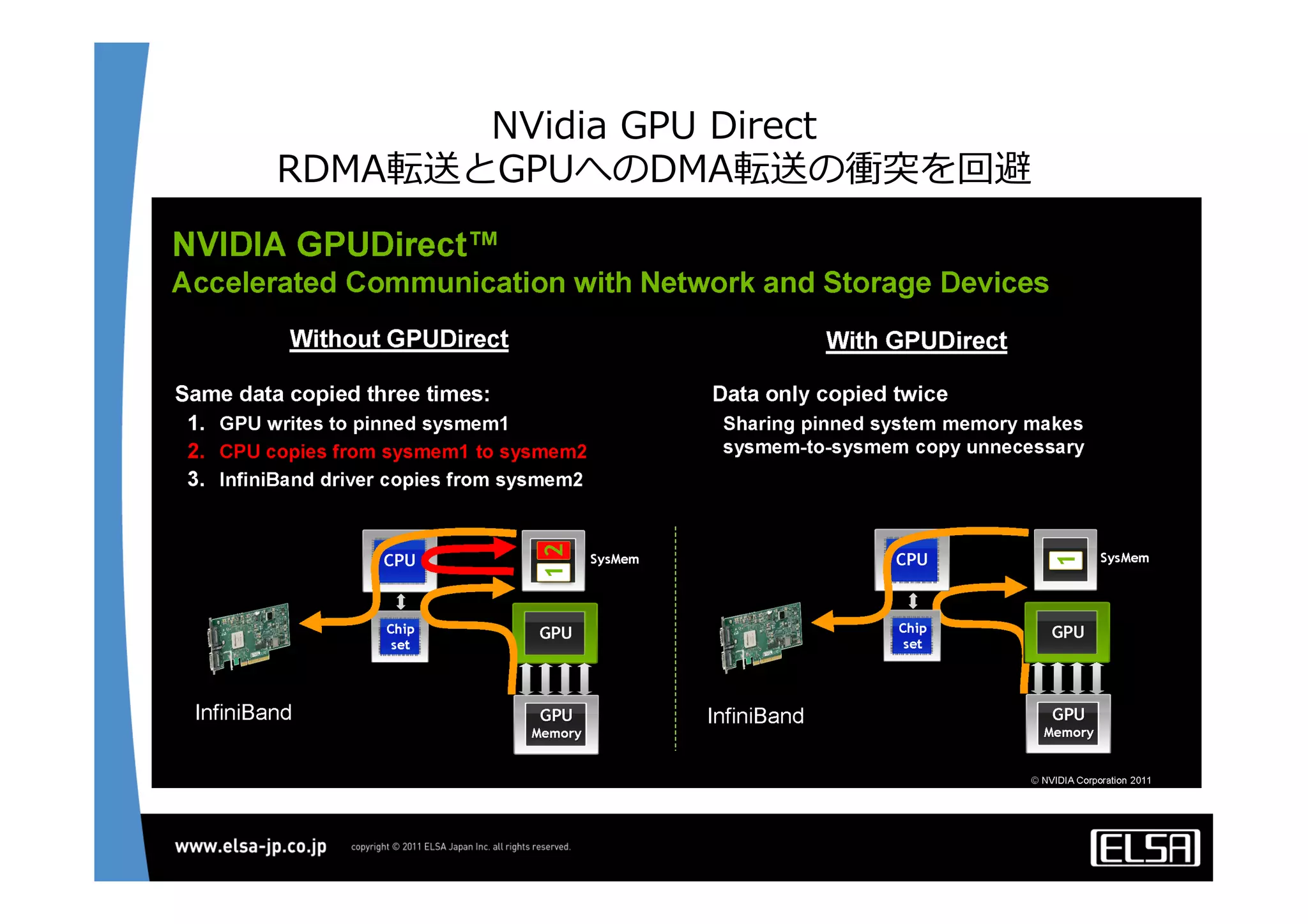
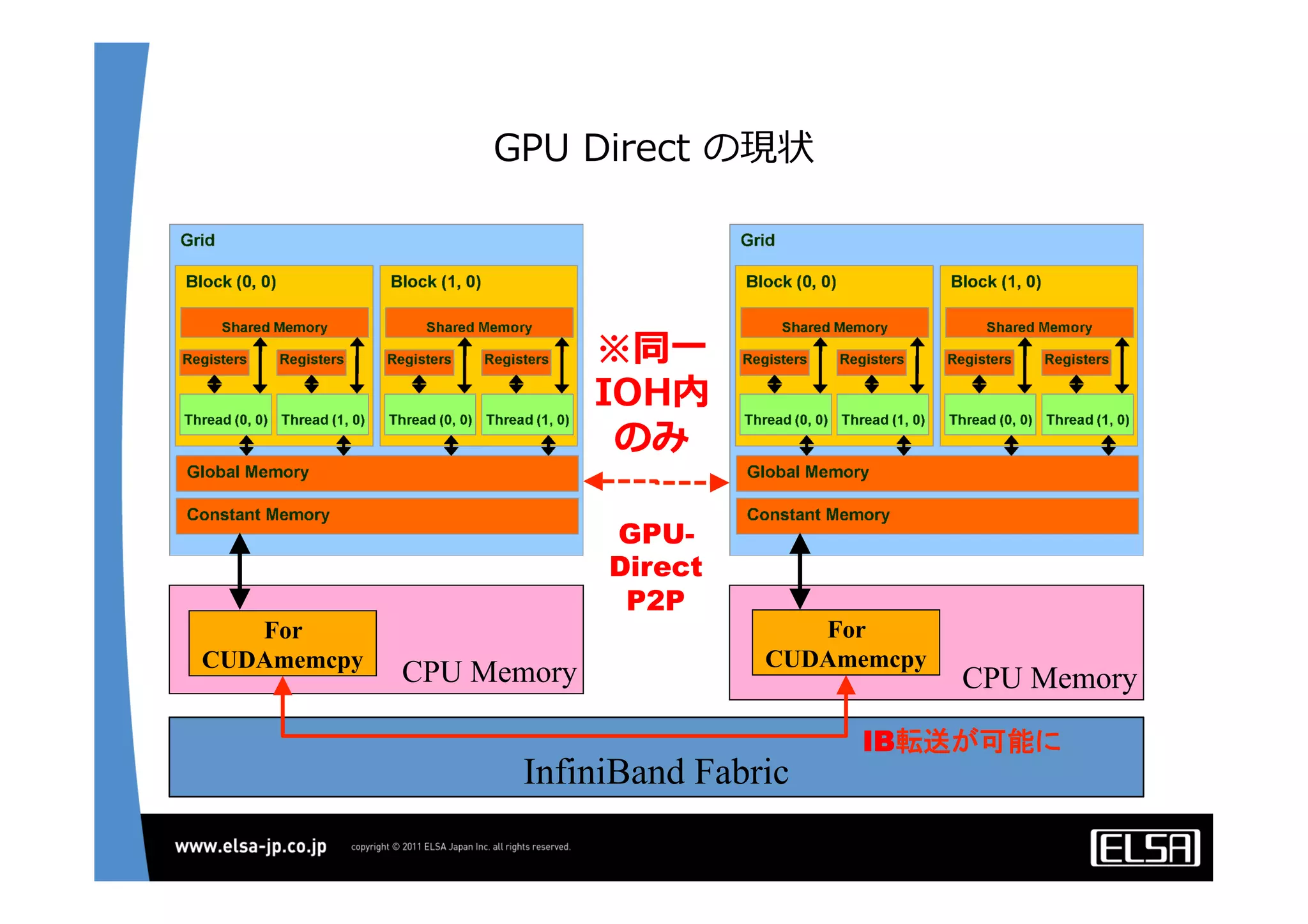
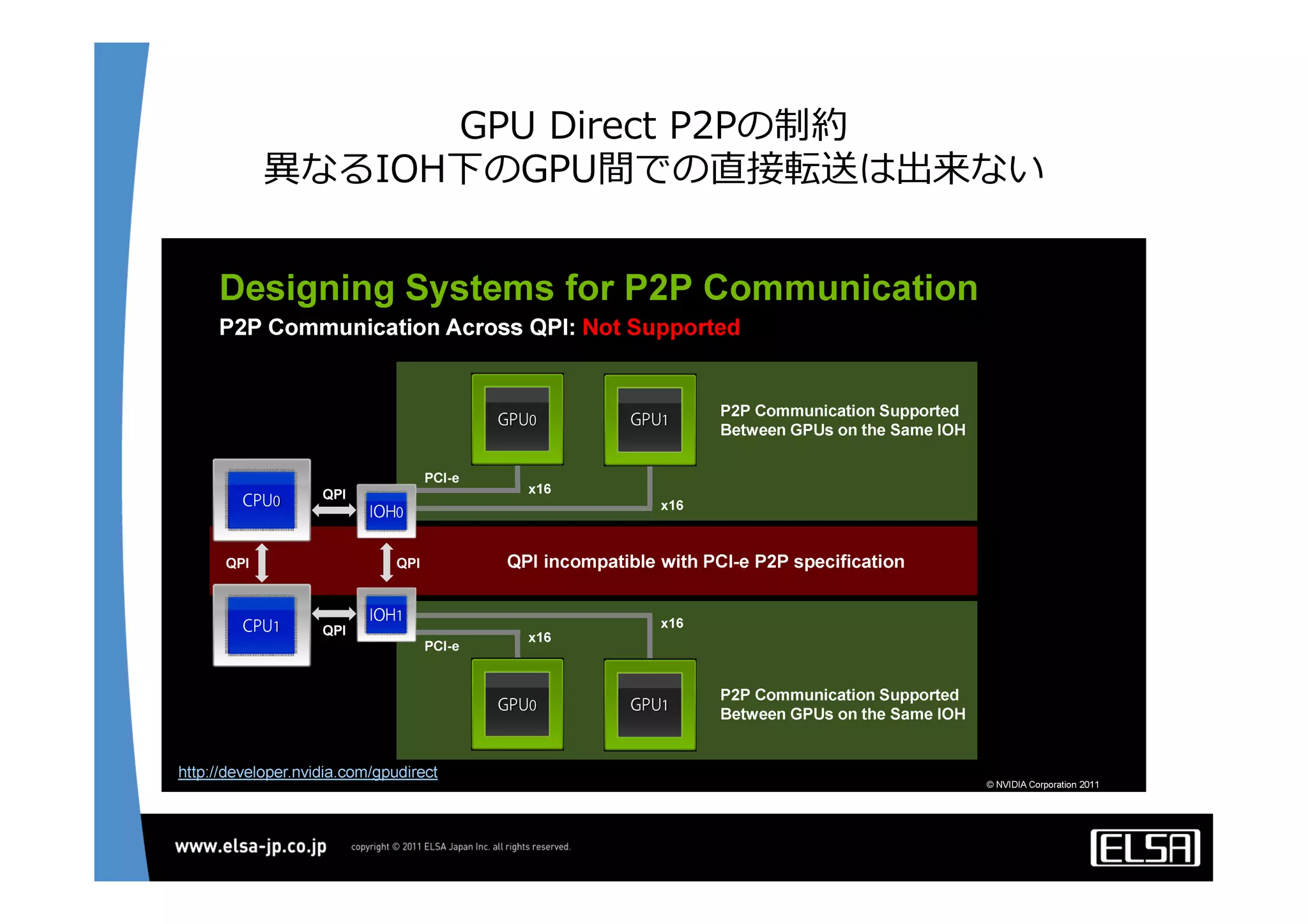
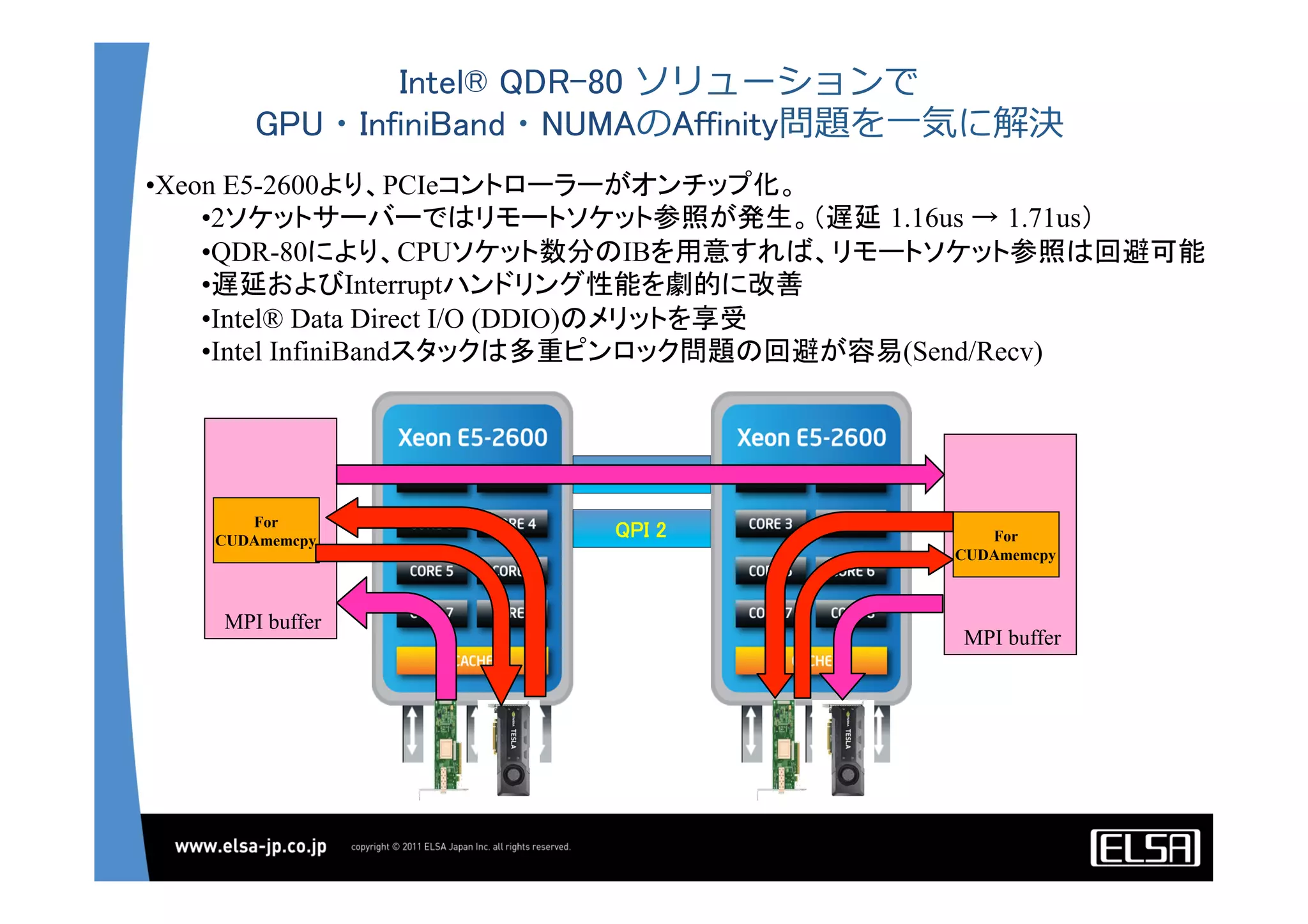
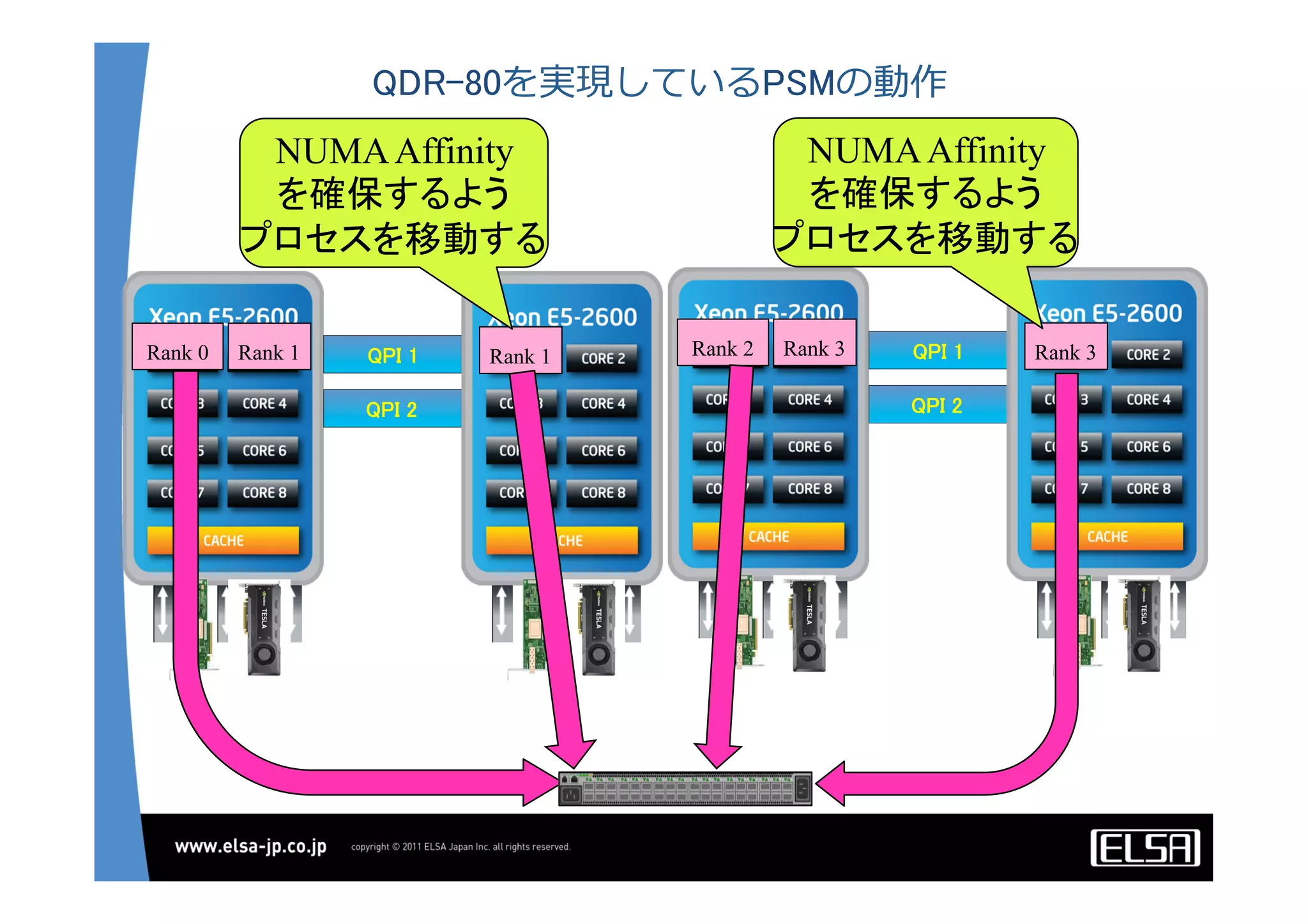
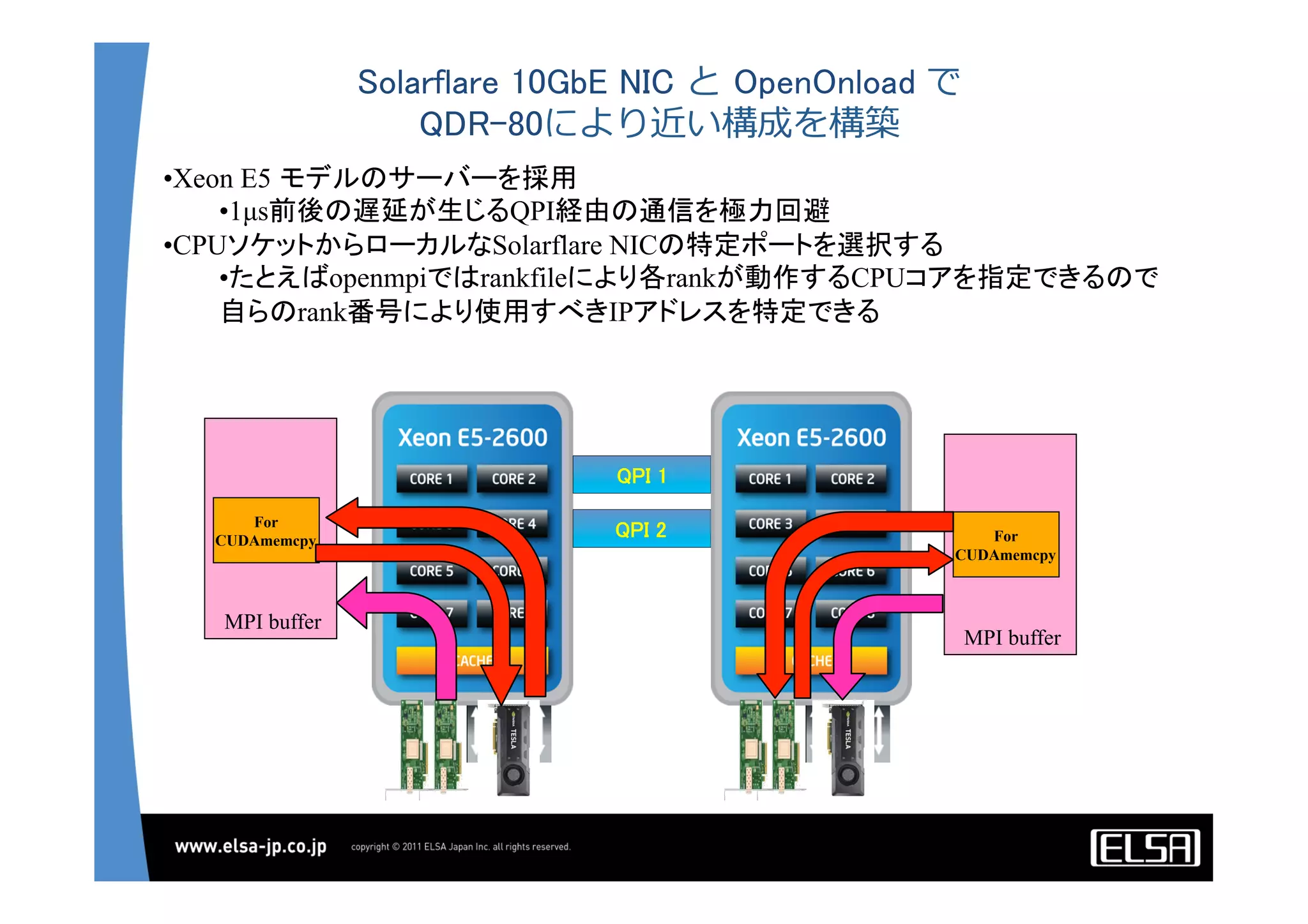
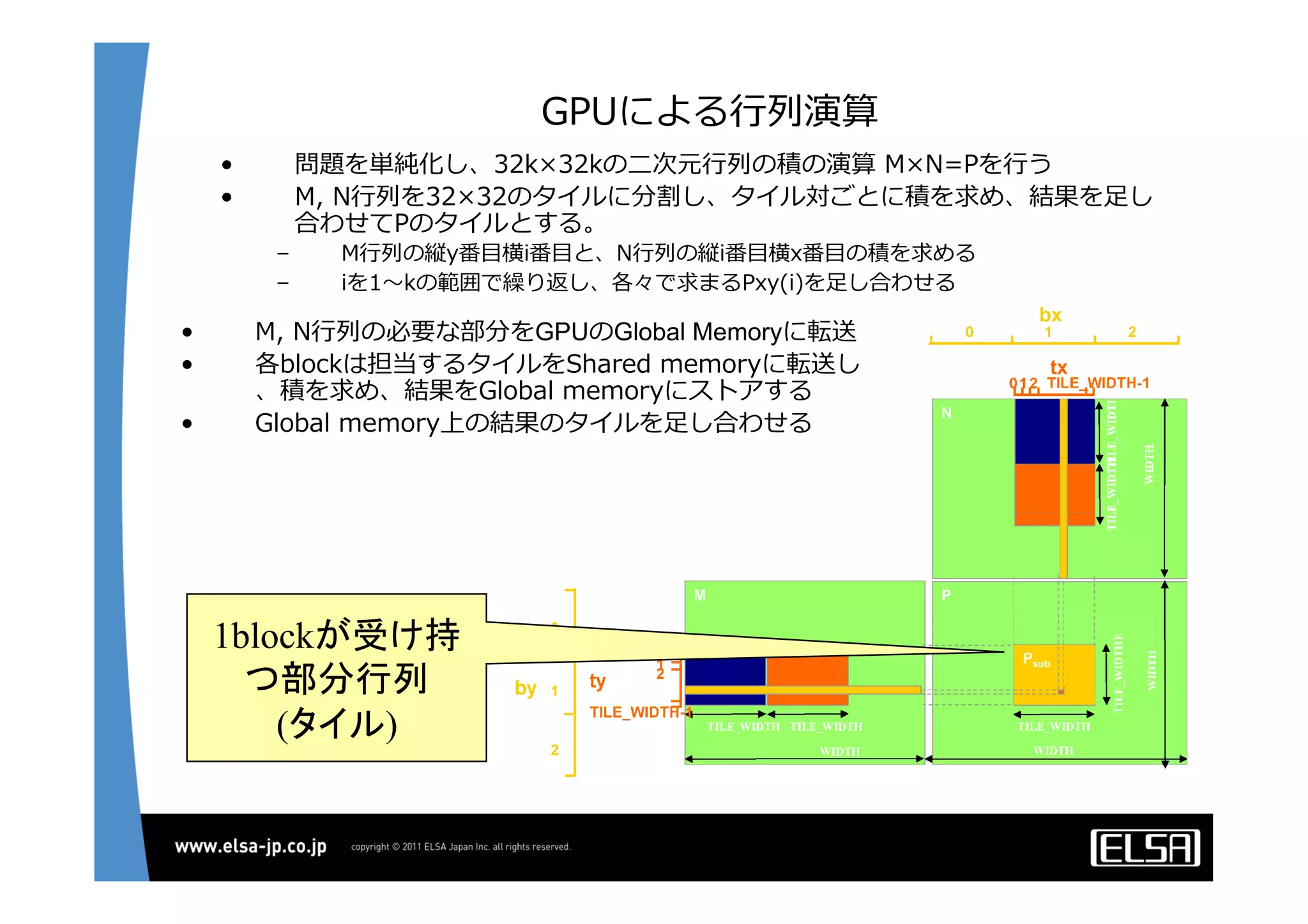
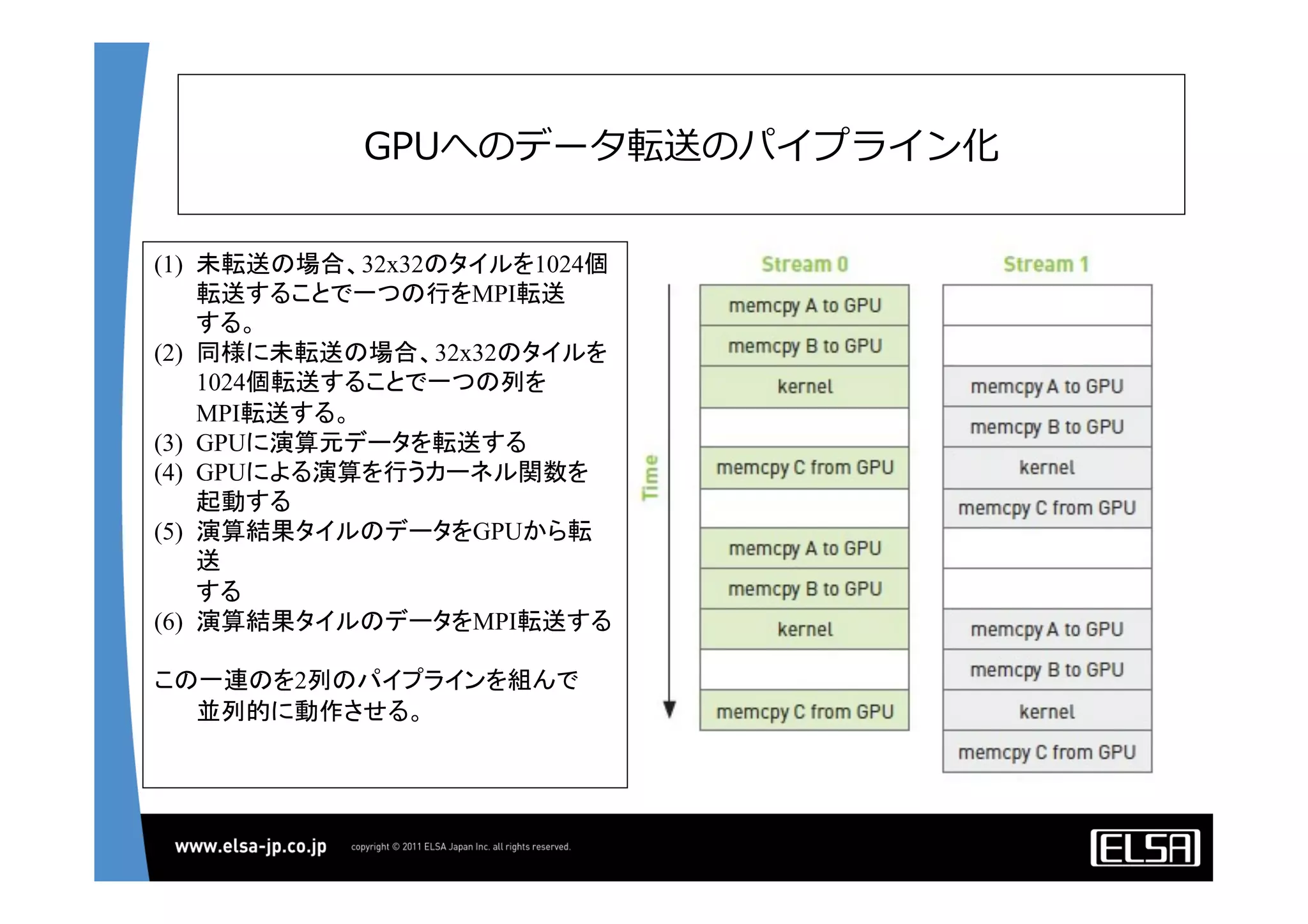
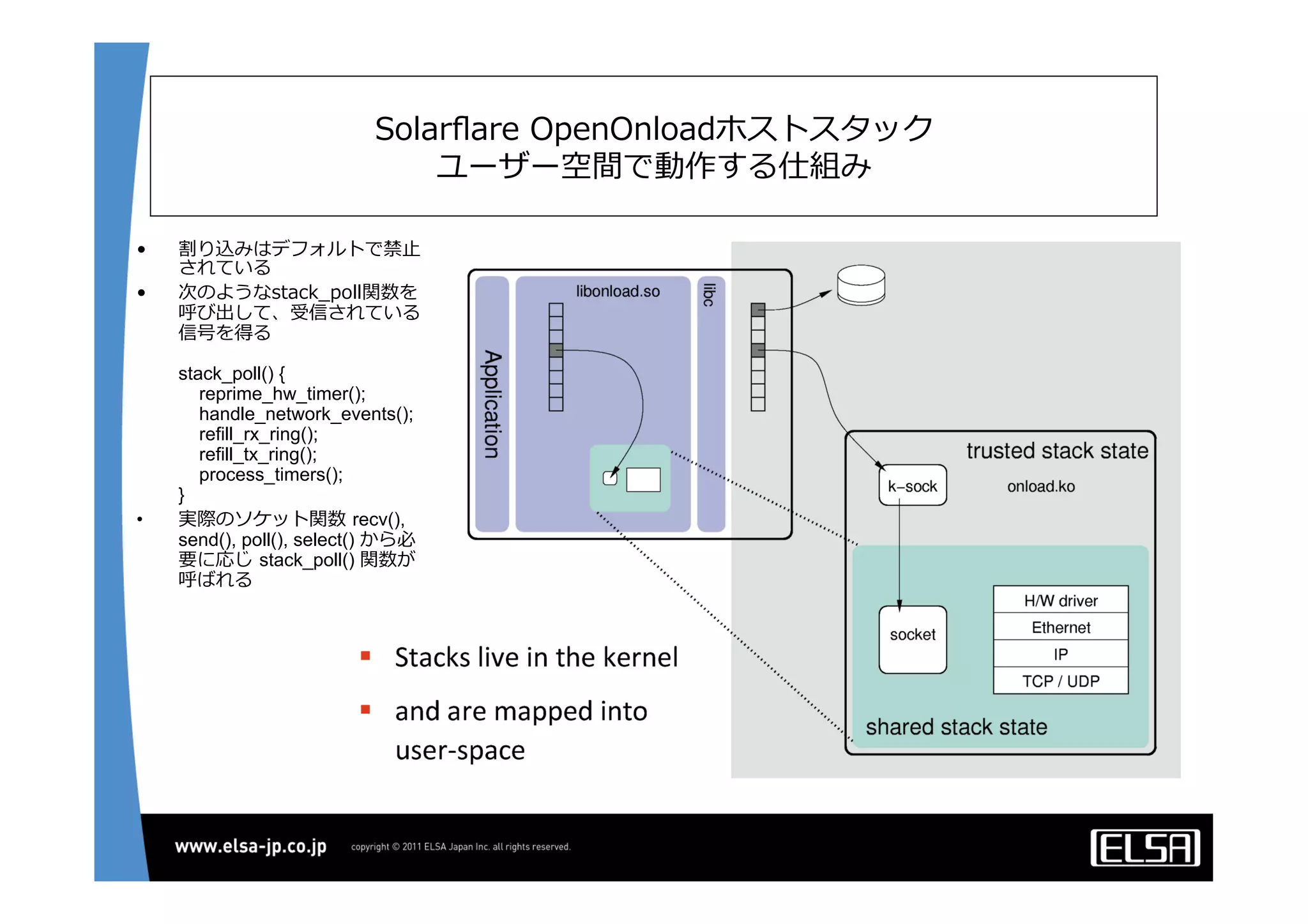
今日のHPCにおいて急速な普及を見せているGPUコンピューティングは基本的に, 1.CPUメモリからGPUメモリに演算データを転送する 2.GPU上の大量の並列プロセッサ上で同一のプロセスを起動して演算データを処理する 3.GPUメモリからCPUメモリに演算結果を転送する というプロセスを通じて演算を行う. 単一のGPUによる処理能力では不足がある場合,多数のGPUを並列に使うこととなるが,そのとき演算データを転送するバス転送能力もまた並列的に確保する必要があり,CPUと主メモリもまた並列化することとなる.その際,CPU間のメモリ転送を行うMPIライブラリと高速のインターコネクトも同時に必要となる. 代表的な大規模並列GPUコンピュータである東京工業大学のTSUBAMEではインターコネクトにInfiniBandを用いている[2].InfiniBandはその低遅延性と広帯域の伝送能力から,HPC領域においては最適なインターコネクト技術と認知されている.しかし,特にIPベースの既存の装置・ソリューションとの相互接続において弱点がある. この論文においては,インターコネクト技術として10Gb Ethernet,中でも特に低遅延性で知られるSolarflare[3]社のネットワークインターフェイスを用いることとする. その上で以下の点をそれぞれ検討して最適な設定や手法を割り出し,結果として得られる性能を評価する.







![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=640&height=640&fit=bounds)



















