Recommended
PPTX
PDF
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
PPTX
PDF
PDF
/etc/network/interfaces について
PDF
PDF
PPTX
PDF
PDF
PDF
Docker Compose入門~今日から始めるComposeの初歩からswarm mode対応まで
PDF
GPU仮想化最前線 - KVMGTとvirtio-gpu -
PDF
ZigBee/IEEE802.15.4について調べてみた
PDF
サーバーが完膚なきまでに死んでもMySQLのデータを失わないための表技
PDF
コンテナを止めるな! PacemakerによるコンテナHAクラスタリングとKubernetesとの違いとは
PDF
PDF
PDF
Serf / Consul 入門 ~仕事を楽しくしよう~
PDF
DPDKを用いたネットワークスタック,高性能通信基盤開発
PDF
PDF
なぜディスクレスハイパーバイザに至ったのか / Why did we select to the diskless hypervisor? #builde...
PDF
PDF
Container Network Interface: Network Plugins for Kubernetes and beyond
PPTX
PDF
PDF
PDF
PDF
FreeSWITCH Cluster by K8s
PDF
第21回「Windows Server 2012 DeepDive!! Hyper-V と VDI を徹底解説」(2012/10/18 on しすなま!)...
PDF
低遅延10Gb EthernetによるGPUクラスタの構築と性能向上手法について
More Related Content
PPTX
PDF
知っているようで知らないNeutron -仮想ルータの冗長と分散- - OpenStack最新情報セミナー 2016年3月
PPTX
PDF
PDF
/etc/network/interfaces について
PDF
PDF
PPTX
What's hot
PDF
PDF
PDF
Docker Compose入門~今日から始めるComposeの初歩からswarm mode対応まで
PDF
GPU仮想化最前線 - KVMGTとvirtio-gpu -
PDF
ZigBee/IEEE802.15.4について調べてみた
PDF
サーバーが完膚なきまでに死んでもMySQLのデータを失わないための表技
PDF
コンテナを止めるな! PacemakerによるコンテナHAクラスタリングとKubernetesとの違いとは
PDF
PDF
PDF
Serf / Consul 入門 ~仕事を楽しくしよう~
PDF
DPDKを用いたネットワークスタック,高性能通信基盤開発
PDF
PDF
なぜディスクレスハイパーバイザに至ったのか / Why did we select to the diskless hypervisor? #builde...
PDF
PDF
Container Network Interface: Network Plugins for Kubernetes and beyond
PPTX
PDF
PDF
PDF
PDF
FreeSWITCH Cluster by K8s
Similar to InfiniBandをPCIパススルーで用いるHPC仮想化クラスタの性能評価
PDF
第21回「Windows Server 2012 DeepDive!! Hyper-V と VDI を徹底解説」(2012/10/18 on しすなま!)...
PDF
低遅延10Gb EthernetによるGPUクラスタの構築と性能向上手法について
PDF
Microsoft tech fielders_cisco_20150126_配布版
PPTX
PPTX
JAWS-UG HPC #17 - HPC on AWS @ 2019
PDF
PDF
PPTX
PPTX
TechEd2008_T1-407_EffectiveHyper-V
PDF
PPTX
20120822_dstn技術交流会_仮想化について
PPT
遊休リソースを用いた�相同性検索処理の並列化とその評価
PDF
Amazon EC2 HPCインスタンス - AWSマイスターシリーズ
PPTX
Windows Server 2012 で管理をもっと自動化する
PDF
G tech2016 シスコのハイパーコンバージドインフラCisco Hyper-Flexと、その先にあるIoE/BigDataインフラの世界
PDF
PDF
Hyper-V の本格採用に必要なエンタープライズ設計術
PPTX
PDF
VIOPS06: Infiniband技術動向および導入事例
PDF
Vyatta: The Virtual Router for Cloud Computing Enviroment
More from Ryousei Takano
PDF
Error Permissive Computing
PDF
Opportunities of ML-based data analytics in ABCI
PDF
ABCI: An Open Innovation Platform for Advancing AI Research and Deployment
PDF
PDF
クラウド環境におけるキャッシュメモリQoS制御の評価
PDF
USENIX NSDI 2016 (Session: Resource Sharing)
PDF
User-space Network Processing
PDF
Flow-centric Computing - A Datacenter Architecture in the Post Moore Era
PDF
A Look Inside Google’s Data Center Networks
PDF
PDF
AIST Super Green Cloud: lessons learned from the operation and the performanc...
PDF
PDF
Expectations for optical network from the viewpoint of system software research
PDF
Exploring the Performance Impact of Virtualization on an HPC Cloud
PDF
PDF
High-resolution Timer-based Packet Pacing Mechanism on the Linux Operating Sy...
PDF
クラウドの垣根を超えた高性能計算に向けて~AIST Super Green Cloudでの試み~
PDF
From Rack scale computers to Warehouse scale computers
PDF
高性能かつスケールアウト可能なHPCクラウド AIST Super Green Cloud
PDF
Iris: Inter-cloud Resource Integration System for Elastic Cloud Data Center
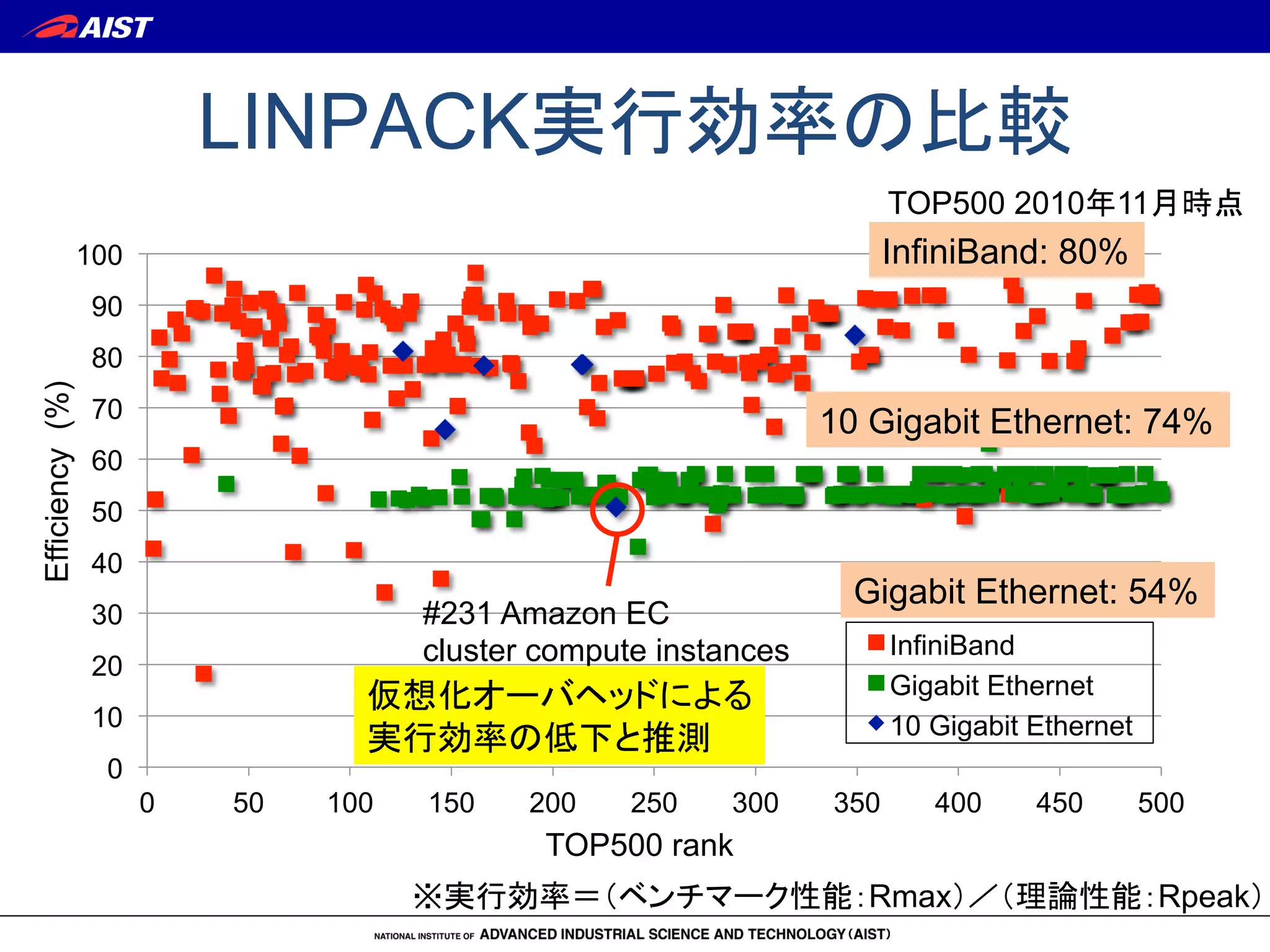
InfiniBandをPCIパススルーで用いるHPC仮想化クラスタの性能評価 1. 2. 3. LINPACK実行効率の比較
0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200 250 300 350 400 450 500
InfiniBand
Gigabit Ethernet
10 Gigabit Ethernet
※実行効率=(ベンチマーク性能:Rmax)/(理論性能:Rpeak)
InfiniBand: 80%
Gigabit Ethernet: 54%
10 Gigabit Ethernet: 74%
TOP500 rank
Efficiency(%)
TOP500 2010年11月時点
#231 Amazon EC
cluster compute instances
仮想化オーバヘッドによる
実行効率の低下と推測
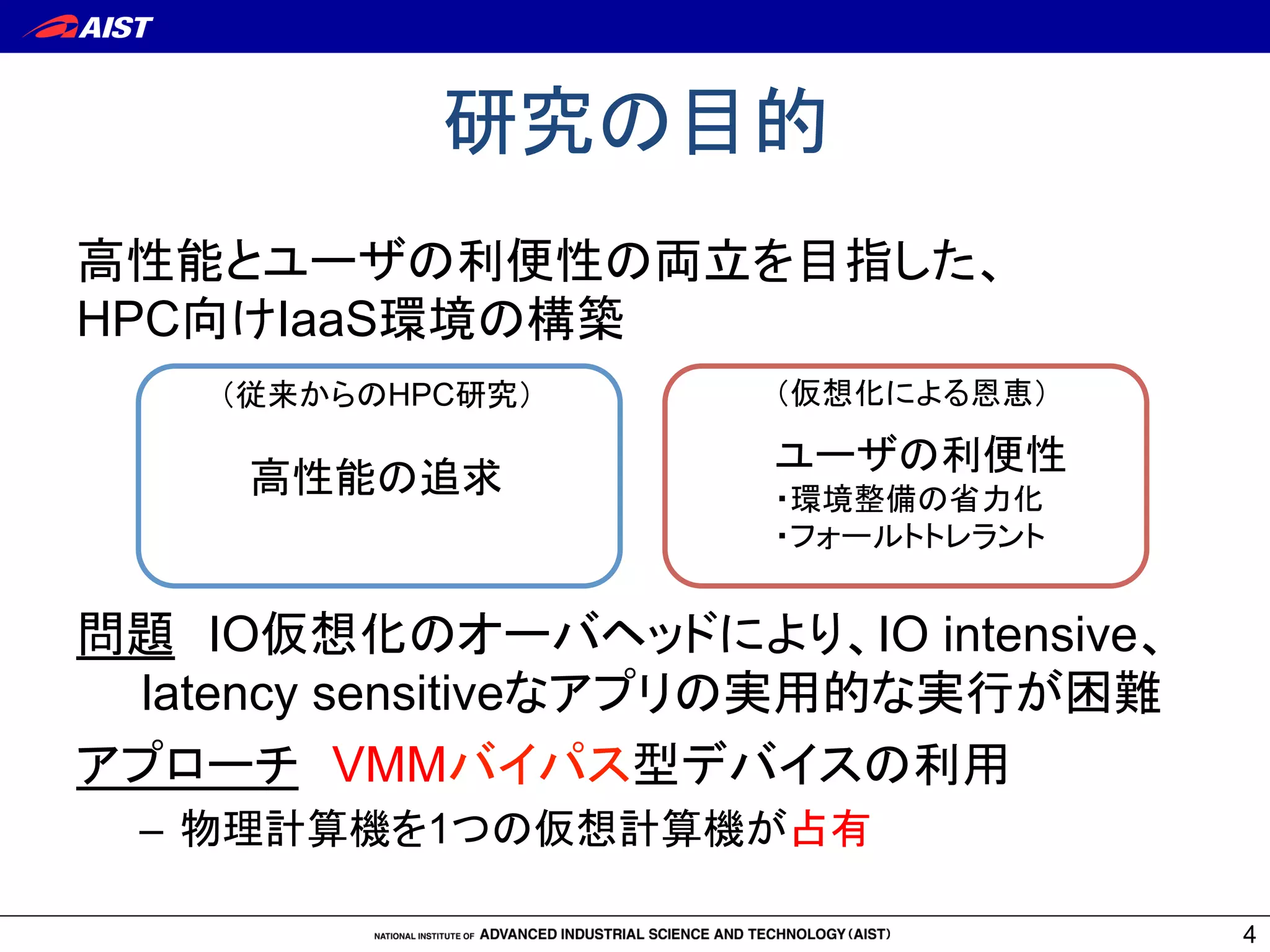
4. 5. 6. 7. 8. 仮想CPUスケジューリング
8
Xen
VM (Xen DomU)
Xen Hypervisor
Physical
CPU
VCPU
VM
(Dom0)
Domain
scheduler
Guest OS
Process
KVM
VM (QEMU process)
Linux
KVM
Physical
CPU
VCPU
threads
Process
scheduler
Guest OS
Process
Xenの場合、CPUと
VCPUの対応を固定
しないと性能がでない
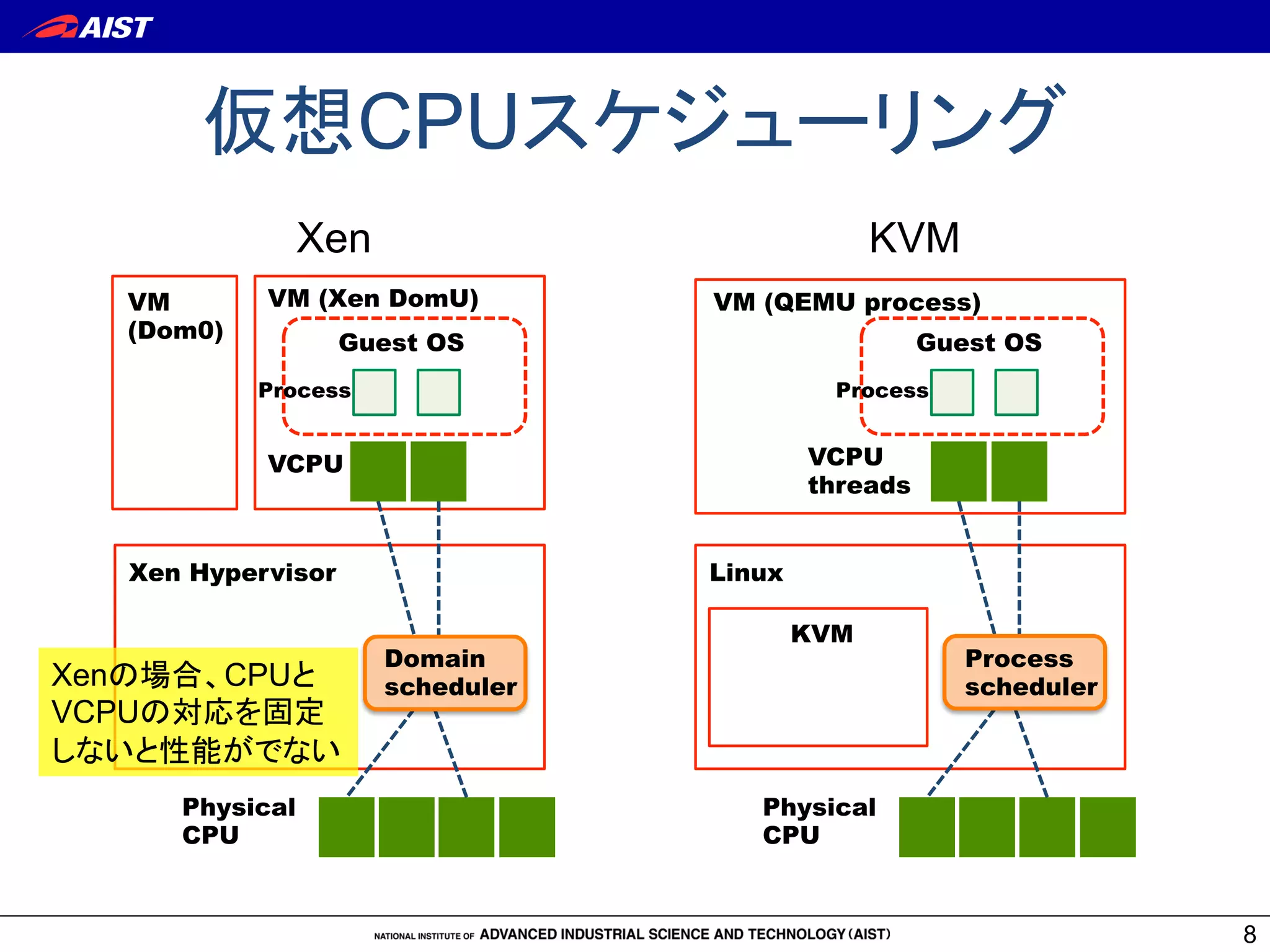
9. メモリ仮想化方式(1)
9
VA
PA
GVA
GPA
非仮想化環境
MMU
(CR3)
page
H/W
OS
ページテーブル
ゲスト仮想アドレス(GVA)
ゲスト物理アドレス(GPA)
ホスト物理アドレス(HPA)
仮想化環境
page
MMU
(CR3)
Guest
OS
VMM
ページテーブル
VMMはGPAをMMUが解釈できる
HPAへの変換する必要あり
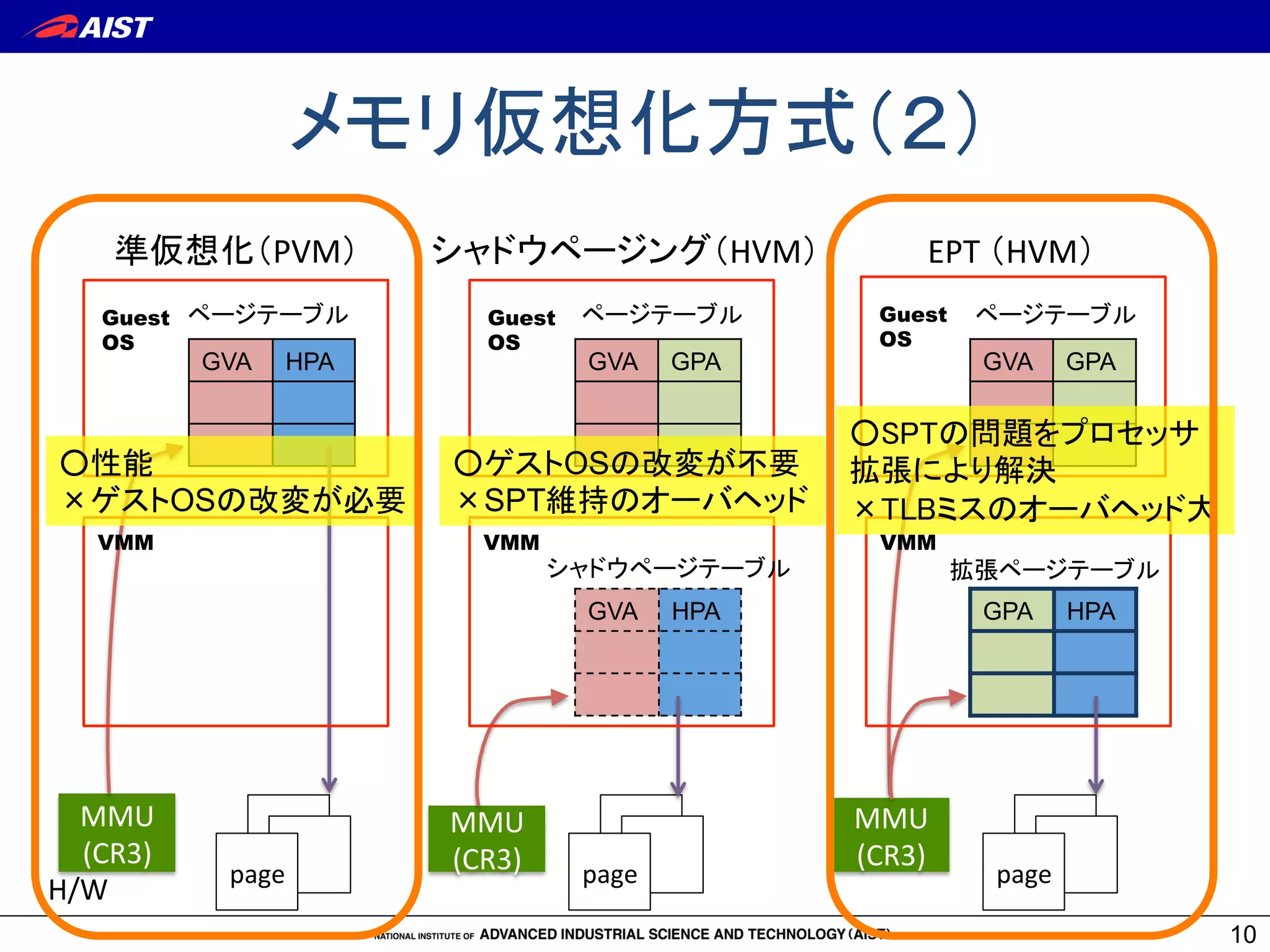
10. メモリ仮想化方式(2)
10
GVA
HPA
GVA
GPA
GVA
GPA
GVA
HPA
GPA
HPA
準仮想化(PVM)
シャドウページング(HVM)
EPT
(HVM)
MMU
(CR3)
page
H/W
Guest
OS
VMM
page
MMU
(CR3)
Guest
OS
VMM
シャドウページテーブル
ページテーブル
ページテーブル
○性能
×ゲストOSの改変が必要
○ゲストOSの改変が不要
×SPT維持のオーバヘッド
page
MMU
(CR3)
Guest
OS
ページテーブル
VMM
拡張ページテーブル
○SPTの問題をプロセッサ
拡張により解決
×TLBミスのオーバヘッド大
11. 12. 13. 14. 15. 実験環境:AIST Green Cloud
計算ノード(Dell PowerEdge M610)
CPU
Intel Xeon E5540/2.53GHz x2
Chipset
Intel 5520
Memory
48 GB DDR3
InfiniBand Mellanox ConnectX (MT26428)
15
ブレードスイッチ
InfiniBand
Mellanox M3601Q (QDR 16 ports)
AGCクラスタの1エンクロージャ(16ノード)を使用
実計算機のソフトウェア
OS
CentOS 5.5
Linux
kernel
2.6.18-194.32.1.el5(
KVMの場合は、
2.6.32.28)
Xen
3.4.3
KVM
0.13.50
仮想計算機環境
OS
CentOS 5.5
VCPU
8
Memory
45 GB
16. 使用ベンチマーク
• マイクロベンチマーク
– Intel MPI Benchmark 3.2
• HPCアプリケーション
– NAS Parallel Benchmark (NPB) 3.3.1, class C
• MPIとOpenMPのハイブリッド版(NPB MZ)のSP、BTを使用
– Bloss
• ブロック櫻井・杉浦法を用いた疎行列非線形固有値問題ソルバ
16
コンパイラ: gcc/gfortran 4.1.2
MPI処理系: Open MPI 1.4 (TransportはInfiniBand)
並列数値計算ライブラリ: Intel Math Kernel Library (MKL) 11.1
17. MPI片道レイテンシ
計算ノード内
(c)
計算ノード間
(a) CPUソケット内
(b) CPUソケット間
BMM 0.41 (1.00)
0.86 (1.00)
1.79 (1.00)
Xen
0.41 (1.00)
083 (1.04)
3.30 (1.84)
KVM
0.54 (1.32)
1.21 (1.46)
1.71 (0.96)
17
• 計算ノード内通信
– メモリ仮想化のオーバヘッド
– BMM ≒ Xen > KVM
• 計算ノード間通信
– IO仮想化のオーバヘッド
– BMM ≒ KVM > Xen
計算ノード
コア
CPU
(c)
IB
HBA
IB
HBA
(b)
(a)
Mem.
Mem.
Mem.
Mem.
単位はマイクロ秒(括弧内はBMMからの相対値)
18. MPI PingPong スループット
18
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(a) CPUソケット内通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(b) CPUソケット間通信
メモリ仮想化のオーバヘッド:
BMM = Xen > KVM
BMMのピーク: 5.7GB/s
BMMのピーク: 3.9GB/s
ノード内通信
19. MPI PingPongスループット
19
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(a) CPUソケット内通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(b) CPUソケット間通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(c) ノード間通信
小メッセージ:
Xen < KVM
BMMのピーク:
5.7GB/s
BMMのピーク:
3.9GB/s
BMMのピーク: 2.5GB/s
ノード間通信
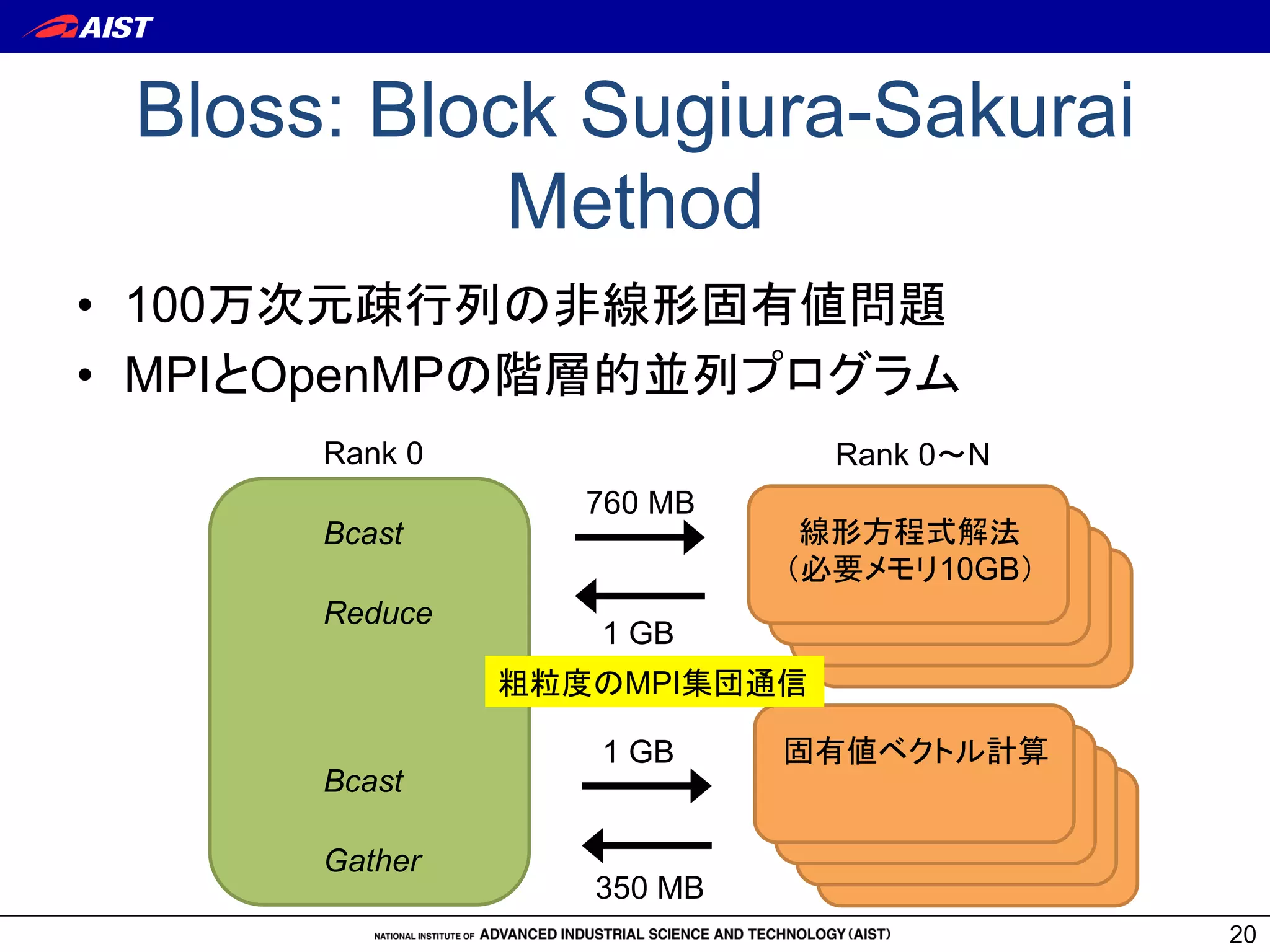
20. Bloss: Block Sugiura-Sakurai
Method
• 100万次元疎行列の非線形固有値問題
• MPIとOpenMPの階層的並列プログラム
20
Rank 0
線形方程式解法
(必要メモリ10GB)
固有値ベクトル計算
Rank 0〜N
760 MB
1 GB
1 GB
350 MB
Bcast
Reduce
Bcast
Gather
粗粒度のMPI集団通信
21. ノード単体計算性能
21
SP-MZ [sec]
BT-MZ [sec]
Bloss [min]
BMM
86.45 (1.00)
132.06 (1.00)
21.00 (1.00)
Xen 100.12 (1.16)
137.66 (1.04)
22.38 (1.07)
KVM
104.36 (1.21)
144.92 (1.10)
22.98 (1.09)
NPB MZ: 4プロセス x 2スレッド
Bloss: 2プロセス x 4スレッド
• メモリ仮想化のオーバヘッドは5〜20%
– Xen > KVM
アプリケーション実行時間
22. 0
20
40
60
80
100
0
50
100
150
200
250
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
BMM (PE)
Xen (PE)
KVM (PE)
NPB MZ: 性能と並列化効率
22
0
20
40
60
80
100
0
50
100
150
200
250
300
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
BMM (PE)
Xen (PE)
KVM (PE)
SP-MZ
BT-MZ
並列度が上がるほど、KVMとXenの差が開く
比較的細粒度の通信が影響と推測
23. 24. 25. 26. 関連研究
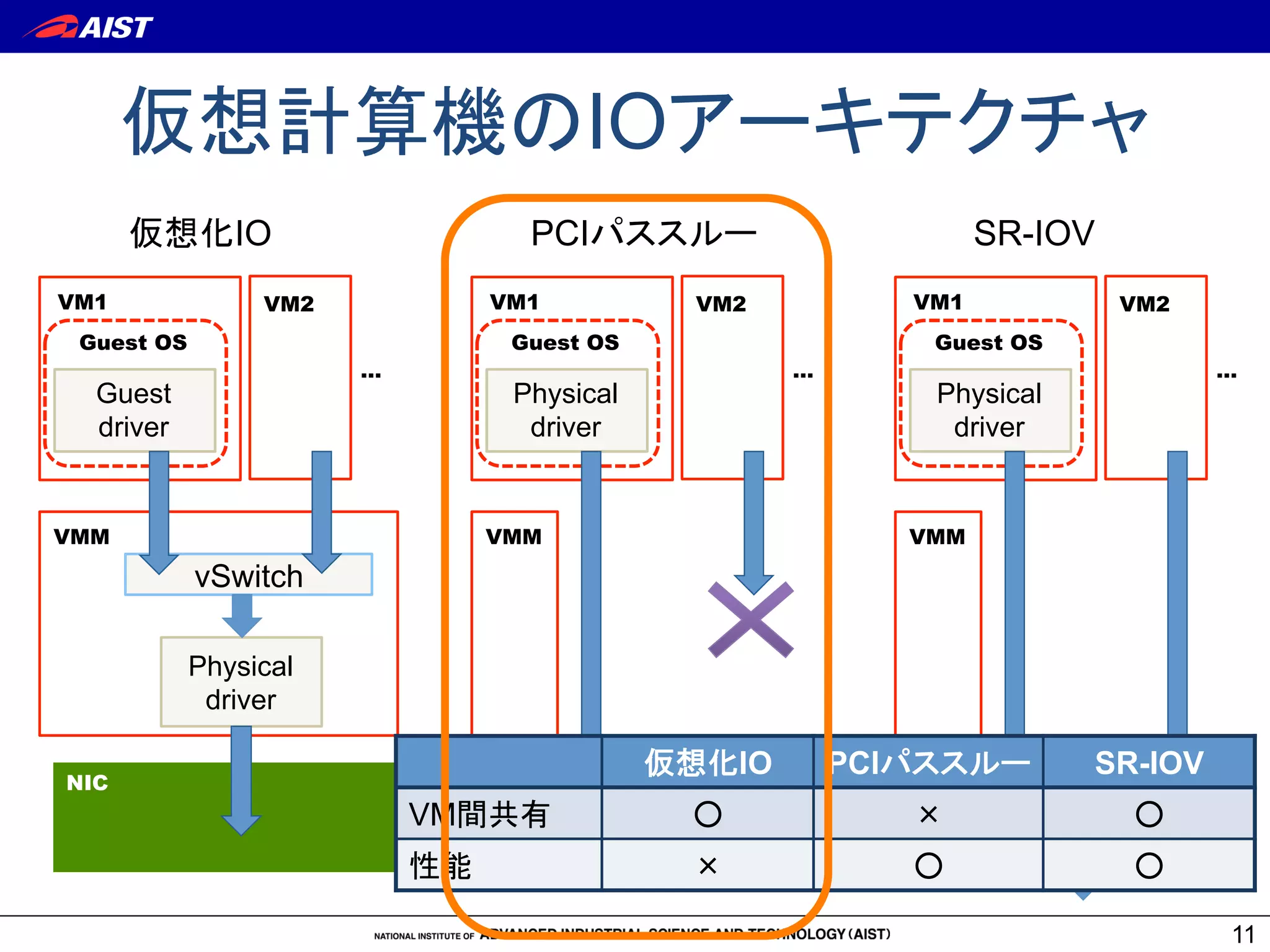
仮想計算機の通信性能改善
1. 仮想化デバイス処理の最適化
• 性能チューニング [Menon2008]
• vhost-net
2. VMMバイパス型IOの利用
• (ハードウェア) PCIパススルー、SR-IOV
• (ソフトウェア) VirtIO [Liu2006]
3. 仮想計算機のスケジューリングを考慮した通信
• vSNOOP [Kangarlou2010]
• MPI実行時のスケジューリングパラメータ調整 [本庄2010]
26
27. 28. 29. 30. 31. ノード単体計算性能 (w/ EC2)
31
SP-MZ [sec]
BT-MZ [sec]
Bloss [min]
BMM
86.45 (1.00)
132.06 (1.00)
21.00 (1.00)
Xen 100.12 (1.16)
137.66 (1.04)
22.38 (1.07)
KVM
104.36 (1.21)
144.92 (1.10)
22.98 (1.09)
EC2 (Xen HVM)
88.00
126.01
20.00
EC2)
CPU: X5570/2.93GHz x2
Mem: 23 GB
NPB MZ: 4プロセス x 2スレッド
Bloss: 2プロセス x 4スレッド
• 仮想化のオーバヘッドは5〜20%
AGC)
CPU: E5540/2.53GHz x2
Mem: 45 GB
アプリケーション実行時間
32. 0
20
40
60
80
100
0
50
100
150
200
250
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
EC2
BMM (PE)
Xen (PE)
KVM (PE)
EC2 (PE)
NPB MultiZone (w/ EC2)
32
0
20
40
60
80
100
0
50
100
150
200
250
300
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
EC2
BMM (PE)
Xen (PE)
KVM (PE)
EC2 (PE)
SP-MZ
BT-MZ
33.












![MPI PingPong スループット
18
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(a) CPUソケット内通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(b) CPUソケット間通信
メモリ仮想化のオーバヘッド:
BMM = Xen > KVM
BMMのピーク: 5.7GB/s
BMMのピーク: 3.9GB/s
ノード内通信](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-18-2048.jpg)
![MPI PingPongスループット
19
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(a) CPUソケット内通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(b) CPUソケット間通信
1
10
100
1000
10000
10 100 1k 10k 100k 1M 10M100M 1G
BMM
Xen
KVM
Message size [byte]
Bandwidth[MB/sec]
(c) ノード間通信
小メッセージ:
Xen < KVM
BMMのピーク:
5.7GB/s
BMMのピーク:
3.9GB/s
BMMのピーク: 2.5GB/s
ノード間通信](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-19-2048.jpg)
![ノード単体計算性能
21
SP-MZ [sec]
BT-MZ [sec]
Bloss [min]
BMM
86.45 (1.00)
132.06 (1.00)
21.00 (1.00)
Xen 100.12 (1.16)
137.66 (1.04)
22.38 (1.07)
KVM
104.36 (1.21)
144.92 (1.10)
22.98 (1.09)
NPB MZ: 4プロセス x 2スレッド
Bloss: 2プロセス x 4スレッド
• メモリ仮想化のオーバヘッドは5〜20%
– Xen > KVM
アプリケーション実行時間](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-21-2048.jpg)
![0
20
40
60
80
100
0
50
100
150
200
250
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
BMM (PE)
Xen (PE)
KVM (PE)
NPB MZ: 性能と並列化効率
22
0
20
40
60
80
100
0
50
100
150
200
250
300
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
BMM (PE)
Xen (PE)
KVM (PE)
SP-MZ
BT-MZ
並列度が上がるほど、KVMとXenの差が開く
比較的細粒度の通信が影響と推測](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-22-2048.jpg)
![Bloss:並列化効率
23
16ノード(32x4スレッド)
実行時の理論値に対す
る並列化効率
BMM: 92.15 %
Xen: 85.60 %
KVM: 84.49 %
Xen、KVMにおける仮想
化オーバヘッドは約9%
粗粒度通信のプログラ
ムでは両者に差がない
0
20
40
60
80
100
120
2x4 4x4 8x4 16x4 32x4
BMM
Xen
KVM
Ideal
Number of threads
ParallelEfficiency[%]](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-23-2048.jpg)


![関連研究
仮想計算機の通信性能改善
1. 仮想化デバイス処理の最適化
• 性能チューニング [Menon2008]
• vhost-net
2. VMMバイパス型IOの利用
• (ハードウェア) PCIパススルー、SR-IOV
• (ソフトウェア) VirtIO [Liu2006]
3. 仮想計算機のスケジューリングを考慮した通信
• vSNOOP [Kangarlou2010]
• MPI実行時のスケジューリングパラメータ調整 [本庄2010]
26](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-26-2048.jpg)




![ノード単体計算性能 (w/ EC2)
31
SP-MZ [sec]
BT-MZ [sec]
Bloss [min]
BMM
86.45 (1.00)
132.06 (1.00)
21.00 (1.00)
Xen 100.12 (1.16)
137.66 (1.04)
22.38 (1.07)
KVM
104.36 (1.21)
144.92 (1.10)
22.98 (1.09)
EC2 (Xen HVM)
88.00
126.01
20.00
EC2)
CPU: X5570/2.93GHz x2
Mem: 23 GB
NPB MZ: 4プロセス x 2スレッド
Bloss: 2プロセス x 4スレッド
• 仮想化のオーバヘッドは5〜20%
AGC)
CPU: E5540/2.53GHz x2
Mem: 45 GB
アプリケーション実行時間](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-31-2048.jpg)
![0
20
40
60
80
100
0
50
100
150
200
250
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
EC2
BMM (PE)
Xen (PE)
KVM (PE)
EC2 (PE)
NPB MultiZone (w/ EC2)
32
0
20
40
60
80
100
0
50
100
150
200
250
300
4x2 8x2 16x2 32x2 64x2
ParallelEfficiency[%]
Performance[Mop/stotal]
x1000
Number of threads
BMM
Xen
KVM
EC2
BMM (PE)
Xen (PE)
KVM (PE)
EC2 (PE)
SP-MZ
BT-MZ](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-32-2048.jpg)
![Bloss:並列化効率 (w/ EC2)
33
0
20
40
60
80
100
120
2x4 4x4 8x4 16x4 32x4
ParallelEfficiency[%]
Number of threads
BMM
Xen
KVM
EC2
Ideal
16ノード(32x4スレッド)
実行時の理論値に対す
る並列化効率
BMM: 92.15 %
Xen: 85.60 %
KVM: 84.49 %
EC2: 74.51 %
Xen、KVMにおける仮想
化オーバヘッドは約9%](https://image.slidesharecdn.com/sacsis2011-takano-110704233247-phpapp02/75/InfiniBand-PCI-HPC-33-2048.jpg)



































































