Download as PDF, PPTX










![MapReduce Intro
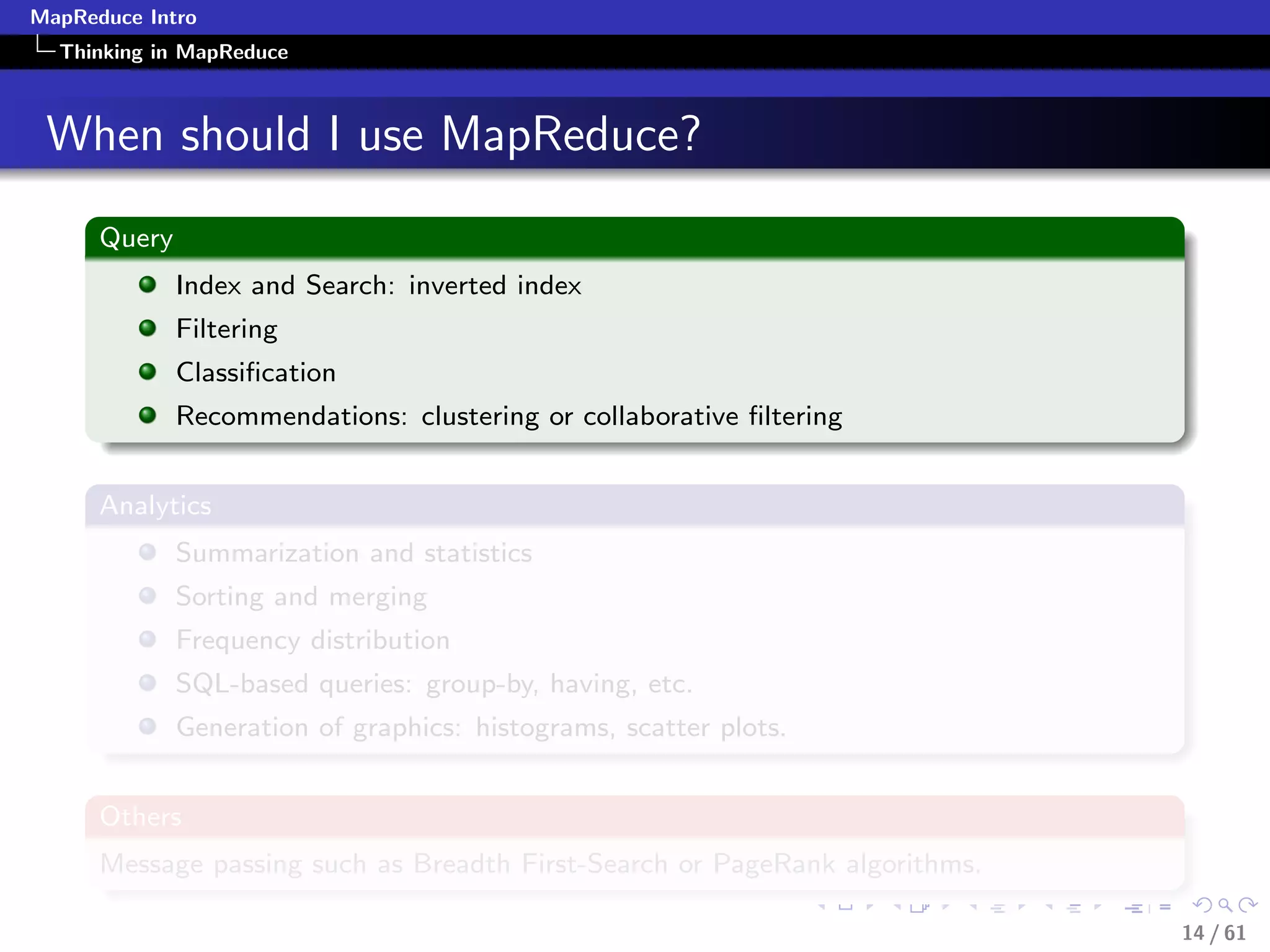
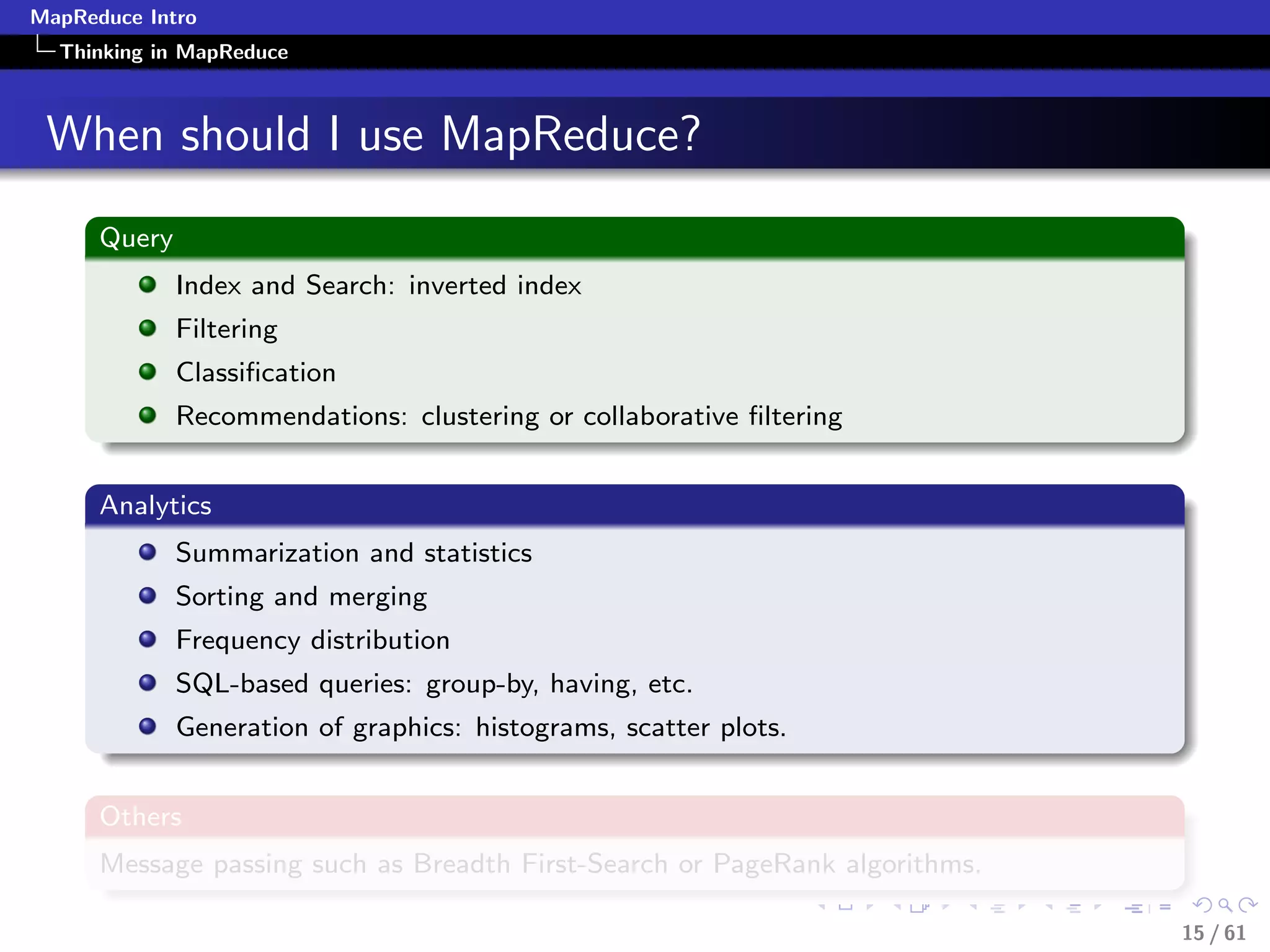
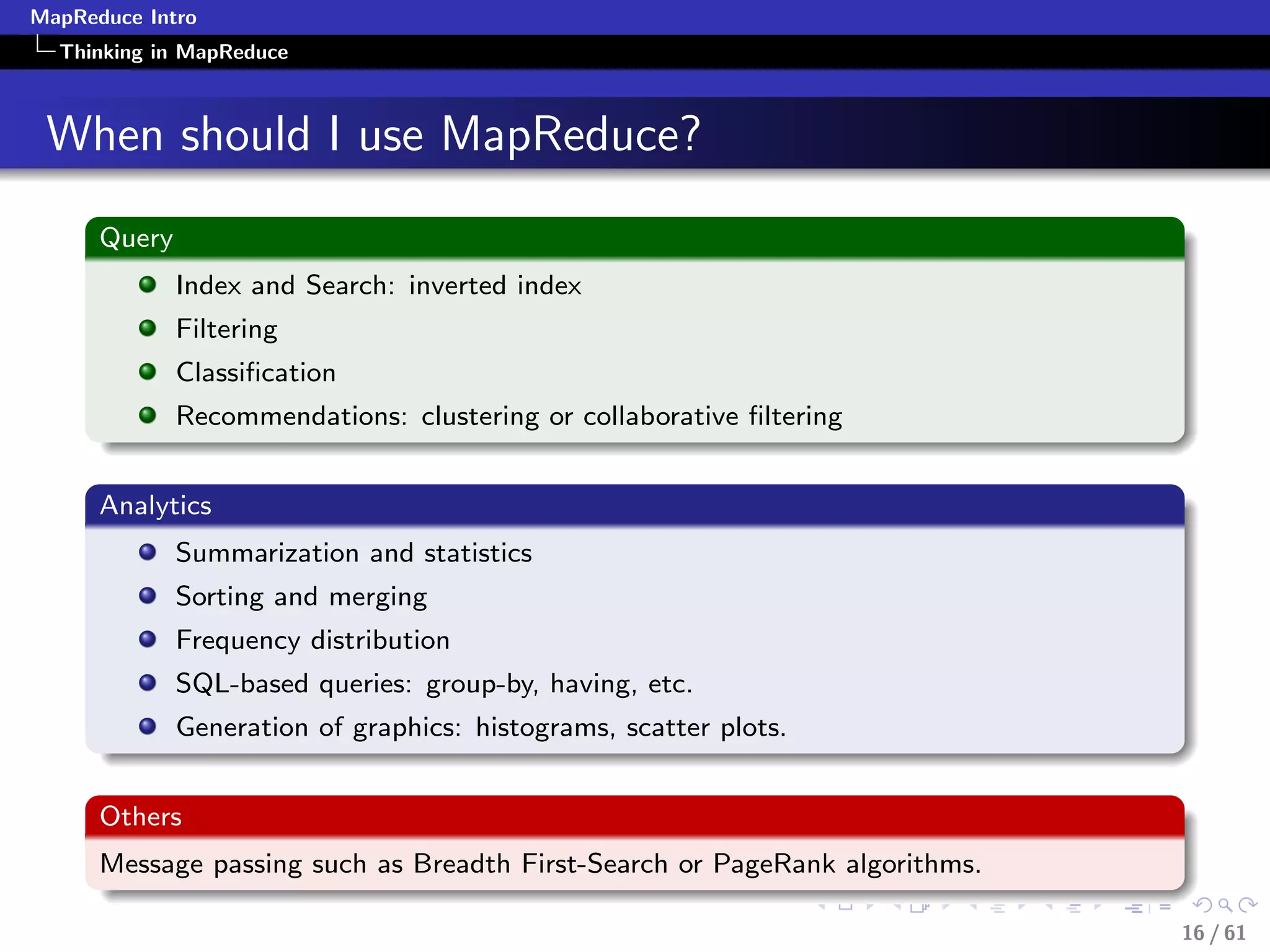
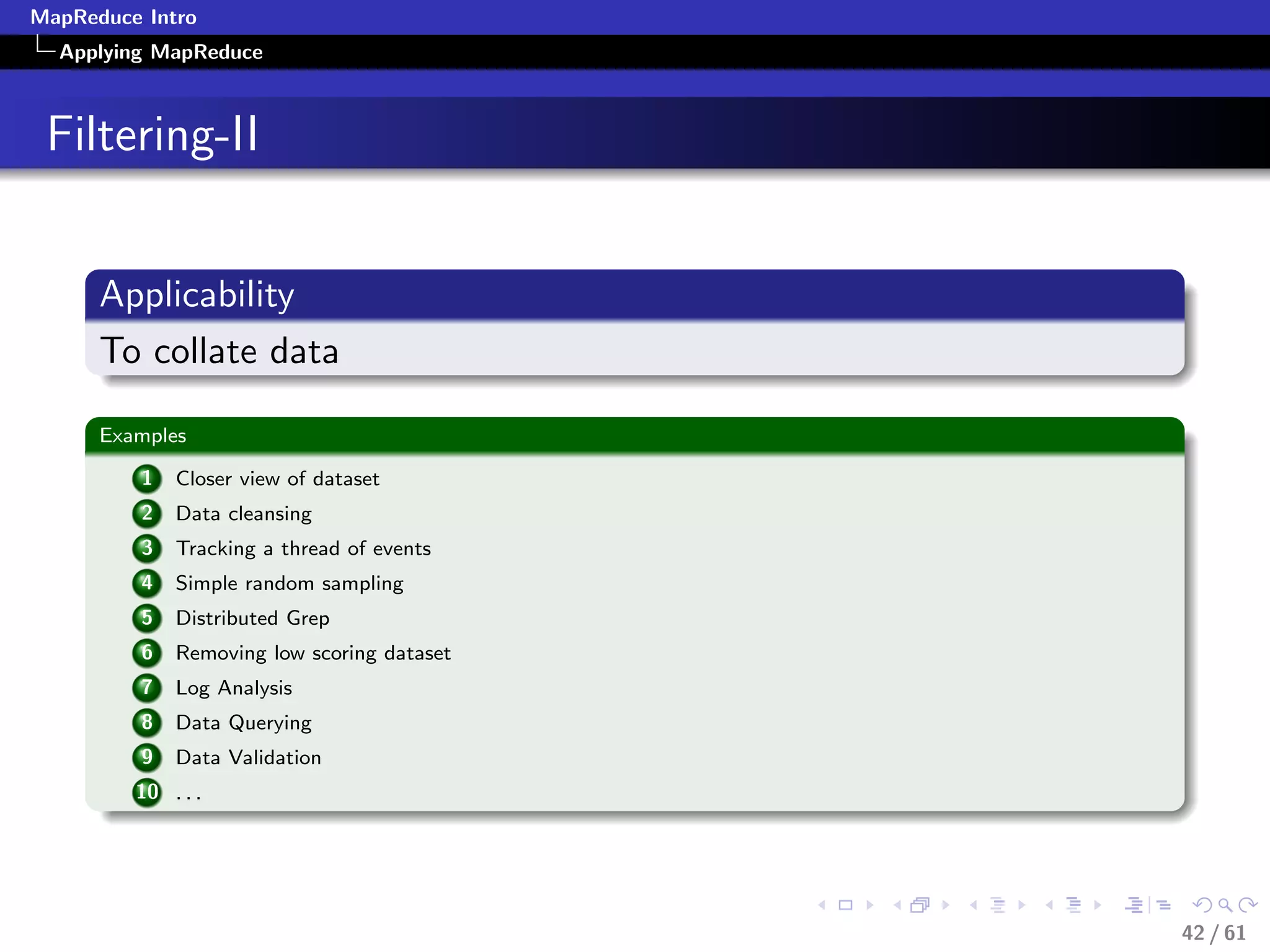
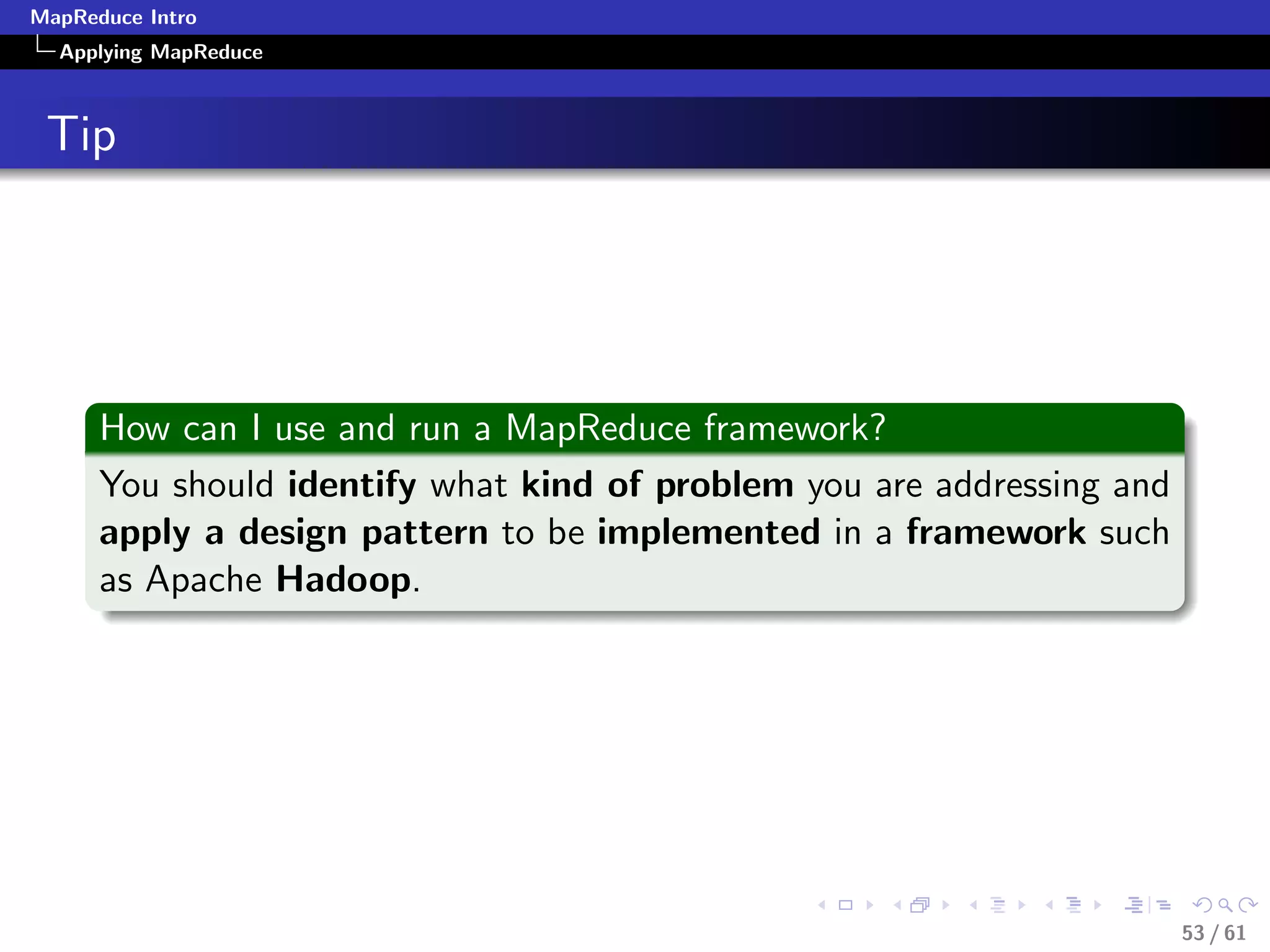
Applying MapReduce
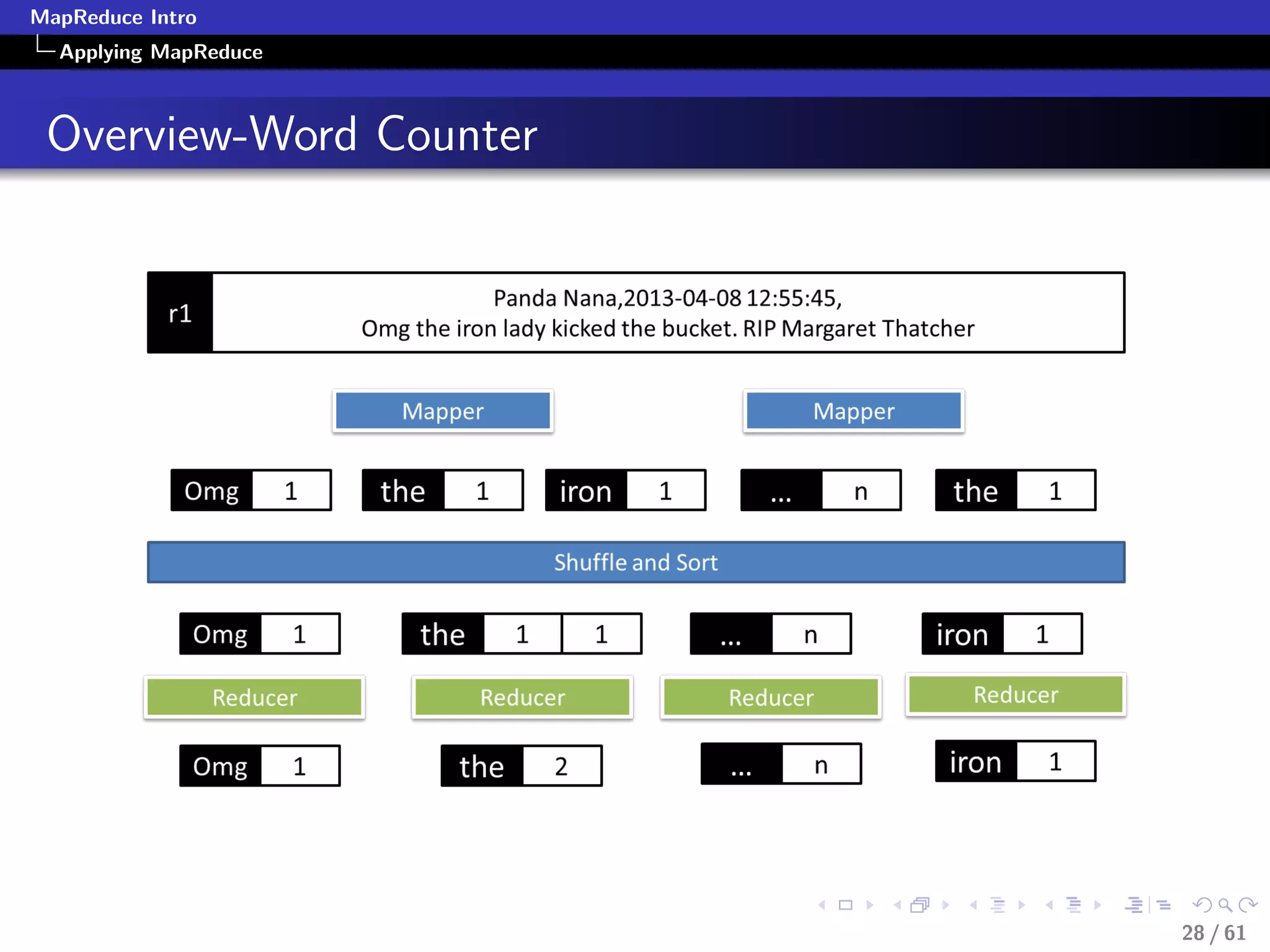
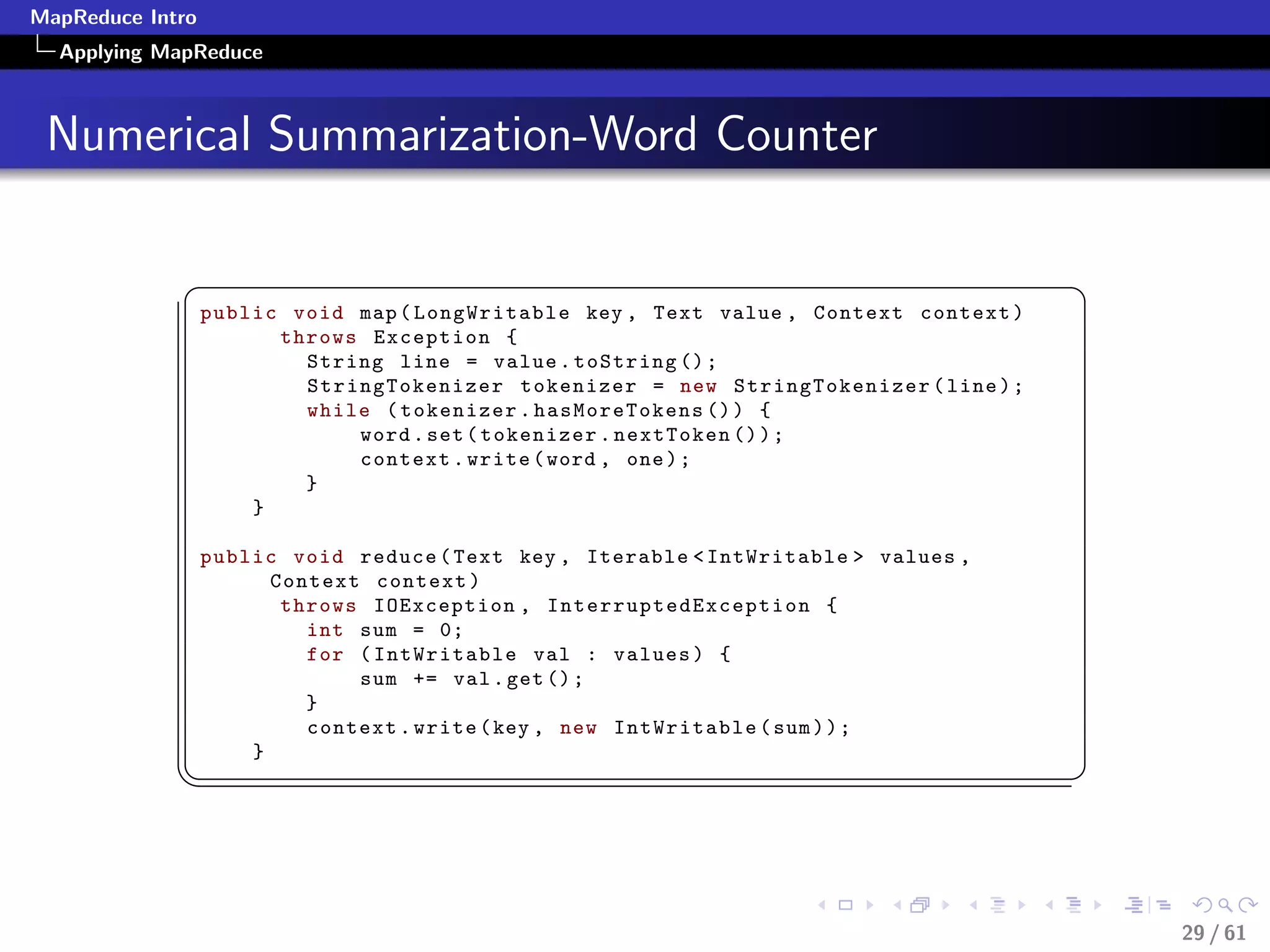
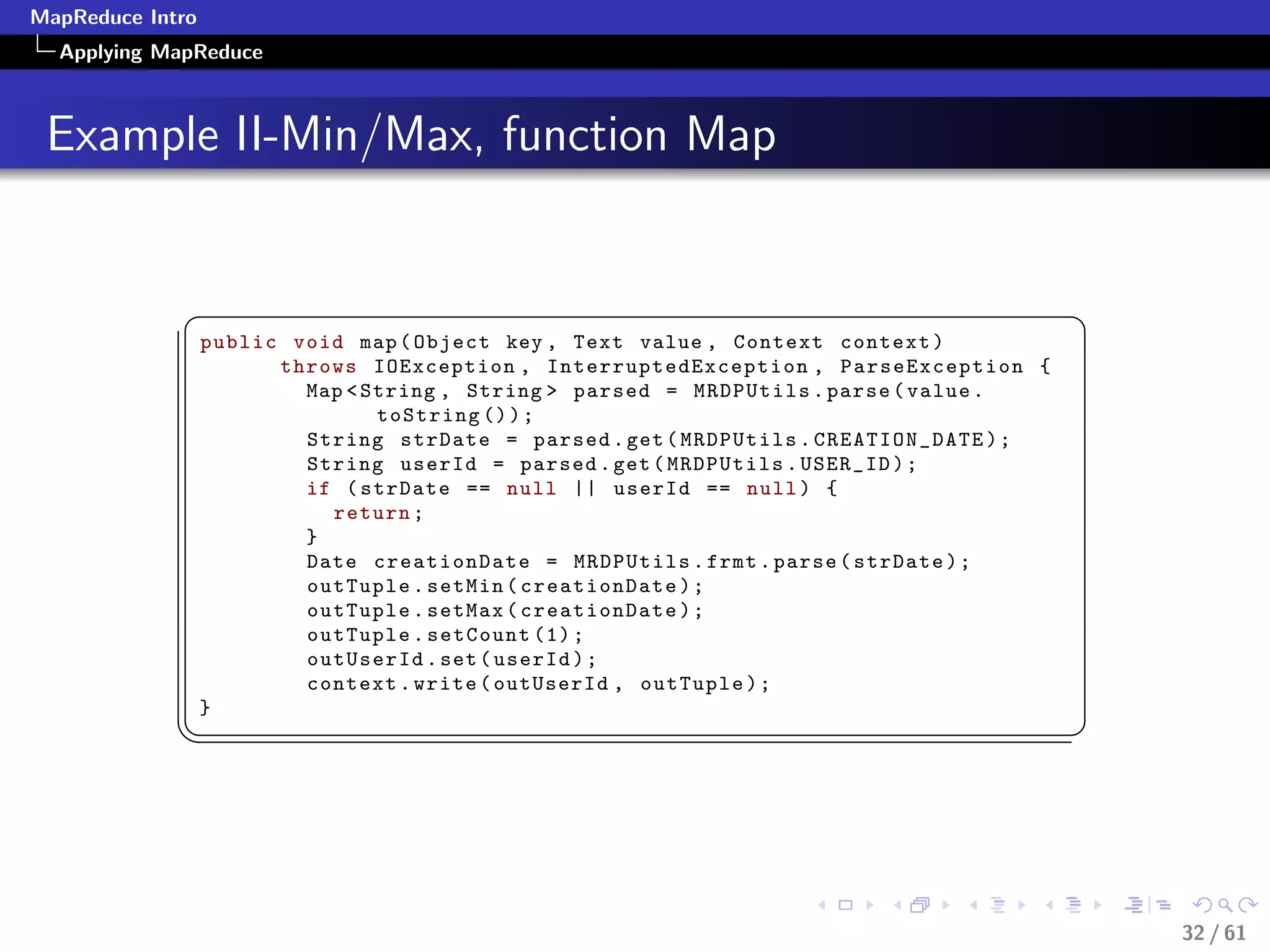
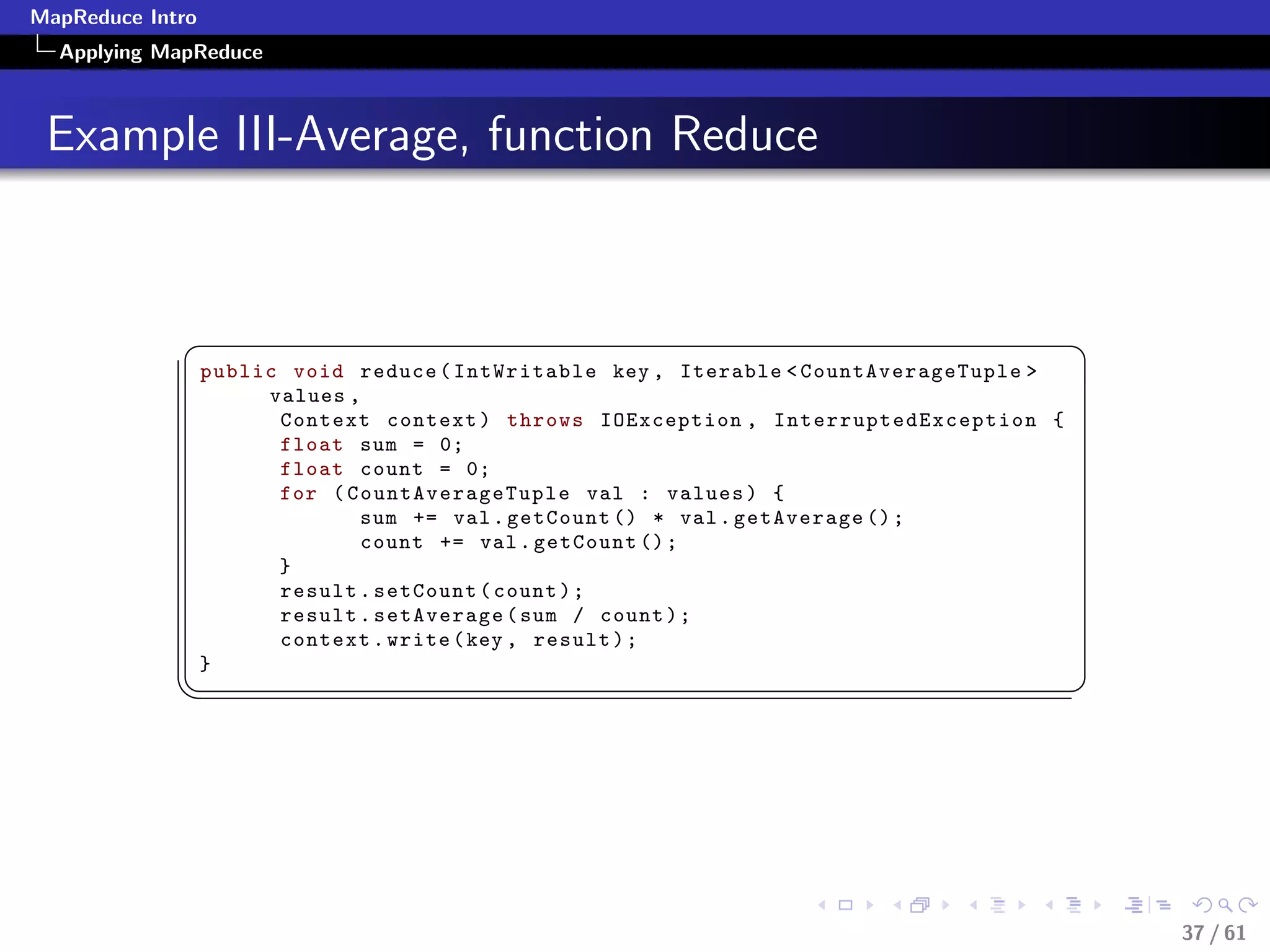
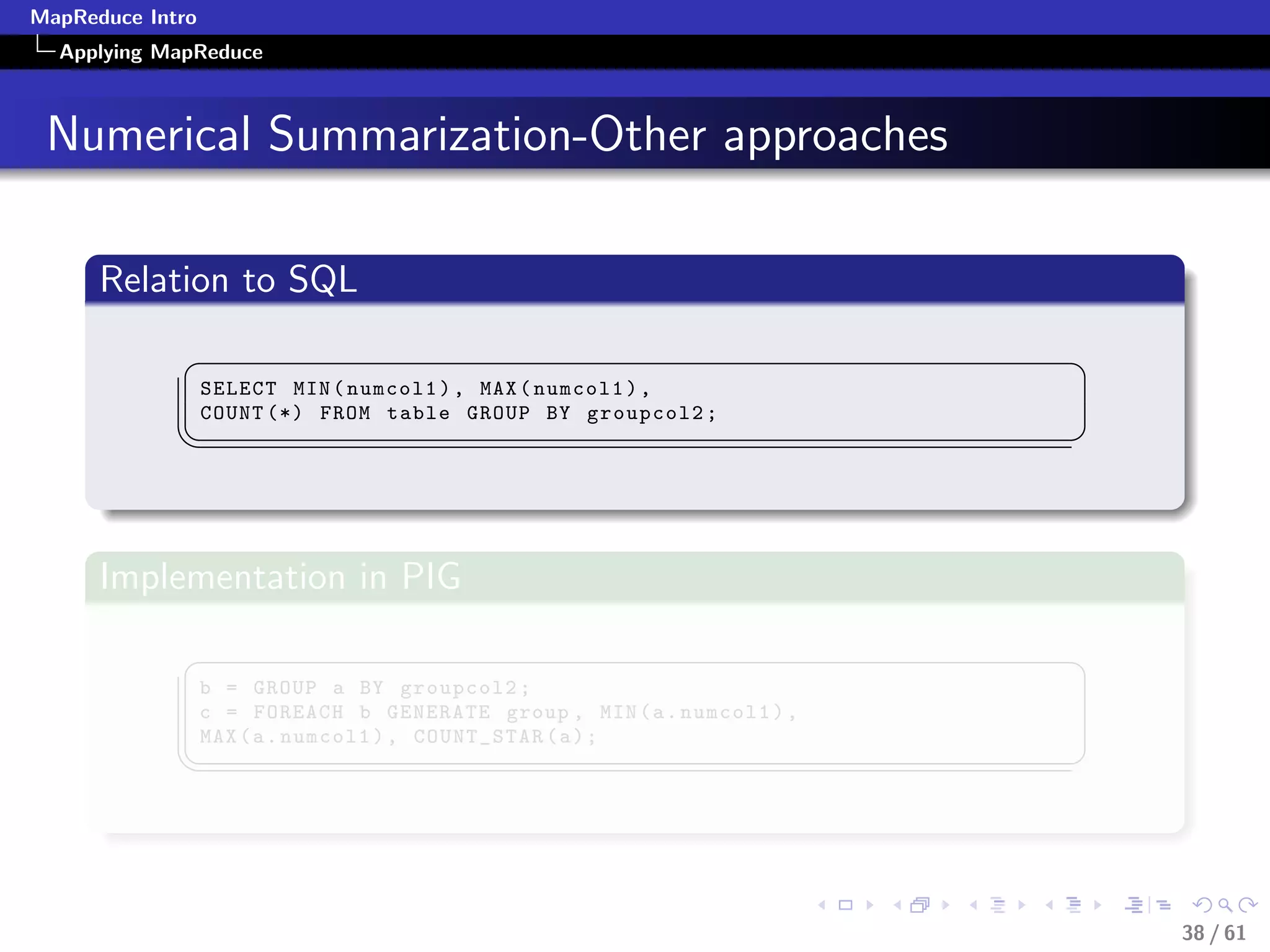
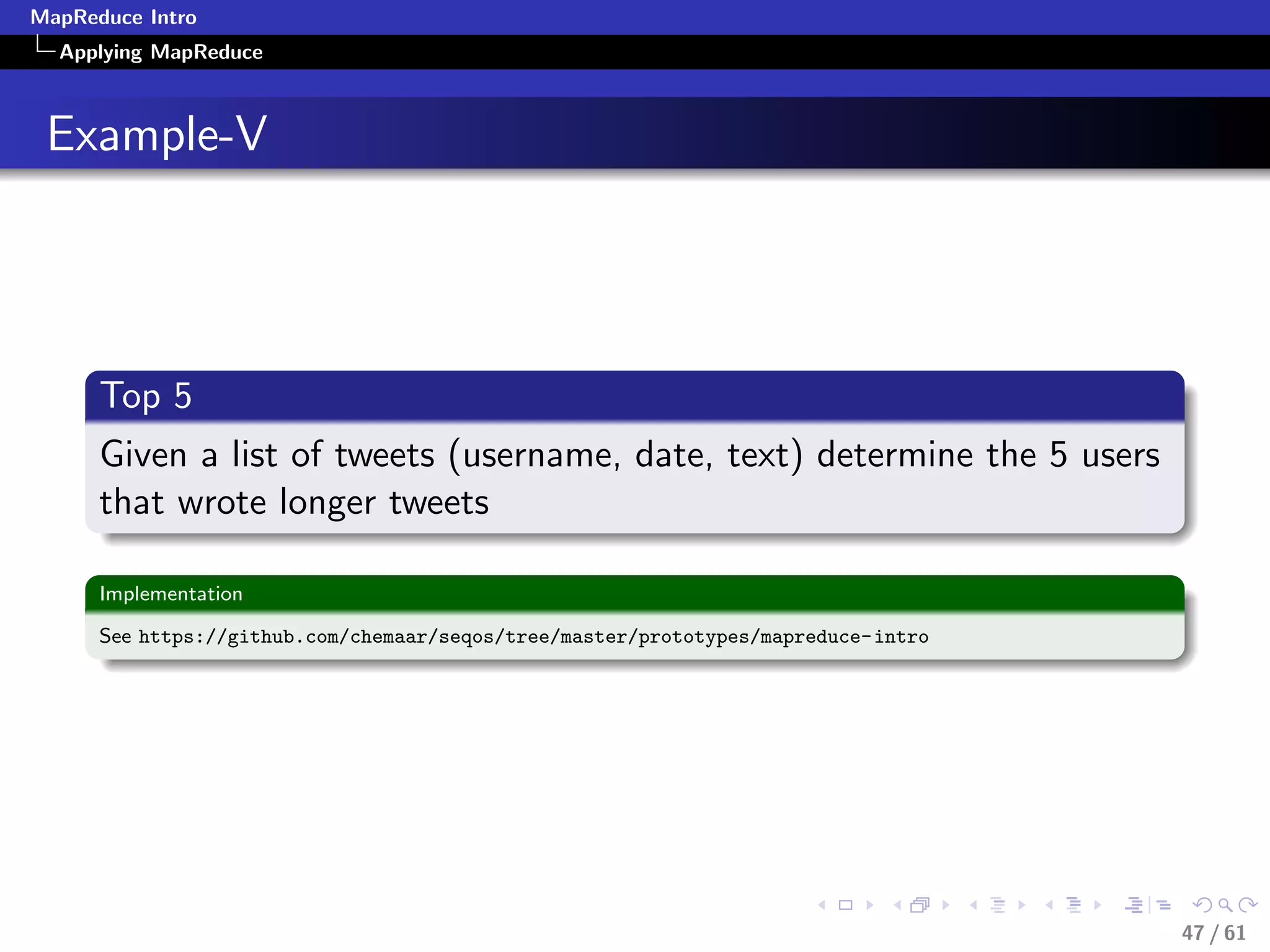
Numerical Summarization-Pseudocode
class Mapper
method Map(recordid id, record r)
for all term t in record r do
Emit(term t, count 1)
class Reducer
method Reduce(term t, counts [c1, c2,...])
sum = 0
for all count c in [c1, c2,...] do
sum = sum + c
Emit(term t, count sum)
27 / 61](https://image.slidesharecdn.com/map-reduce-intro-130424032255-phpapp01/75/Map-Reduce-intro-27-2048.jpg)


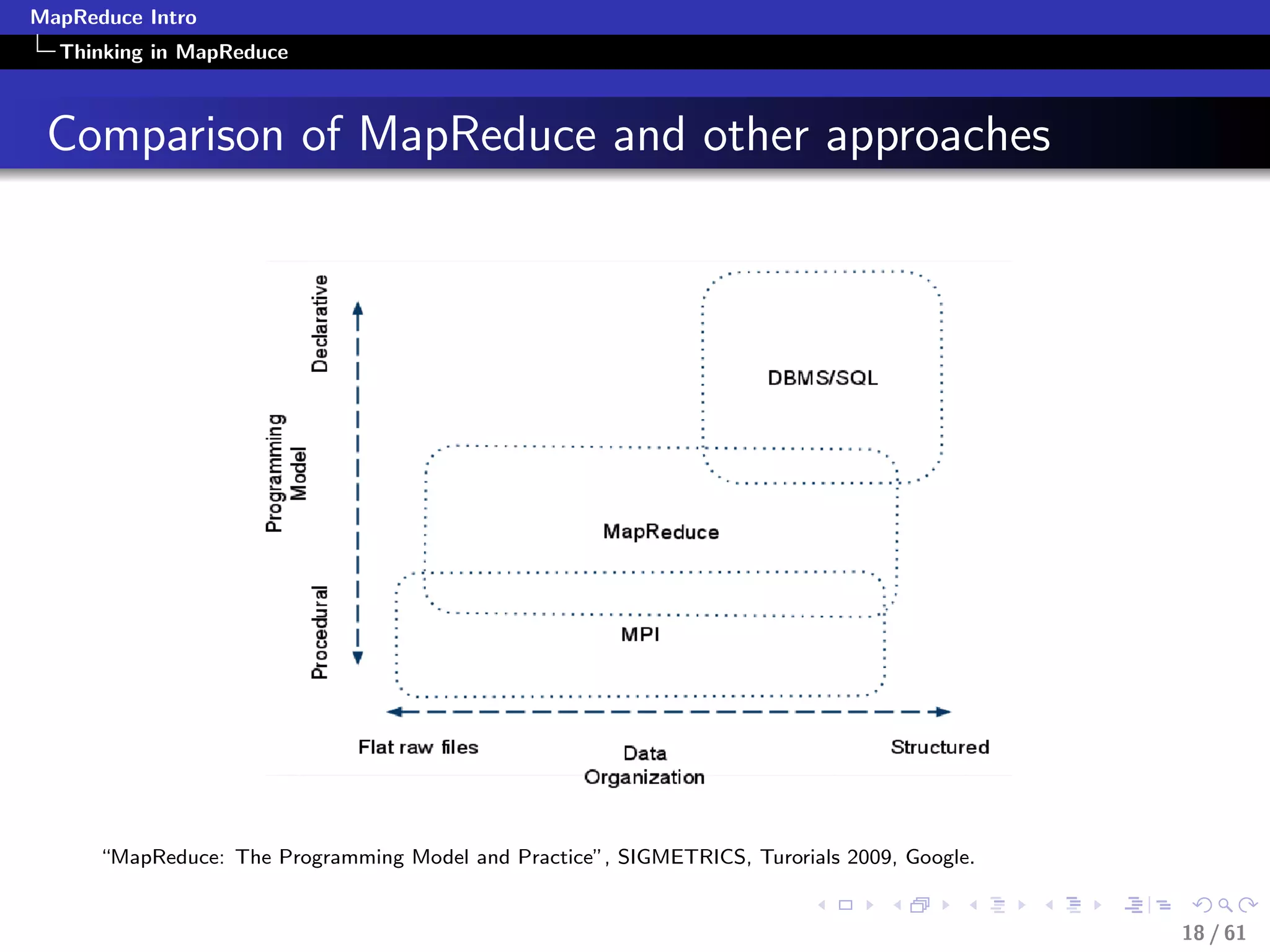
![MapReduce Intro
Applying MapReduce
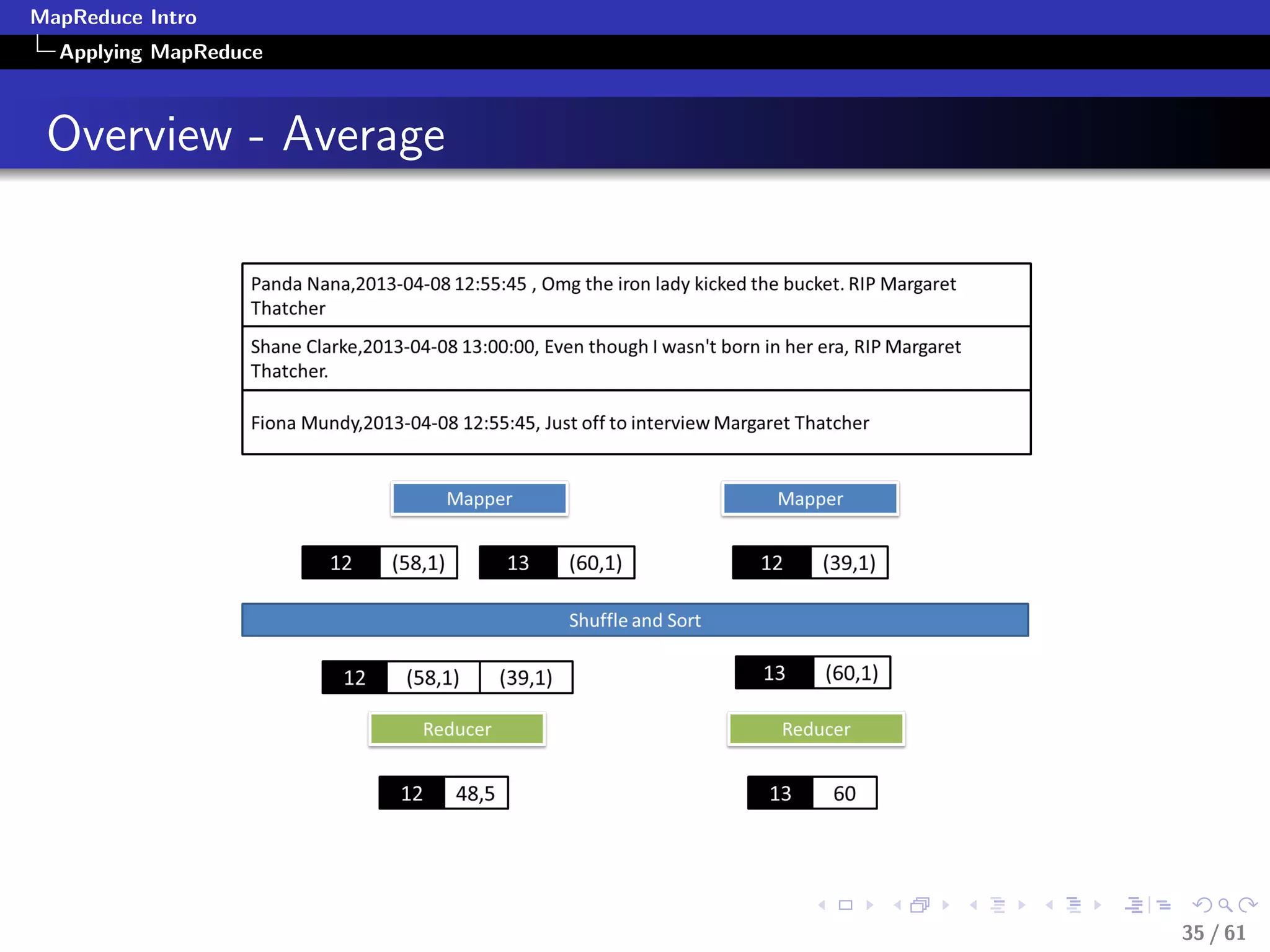
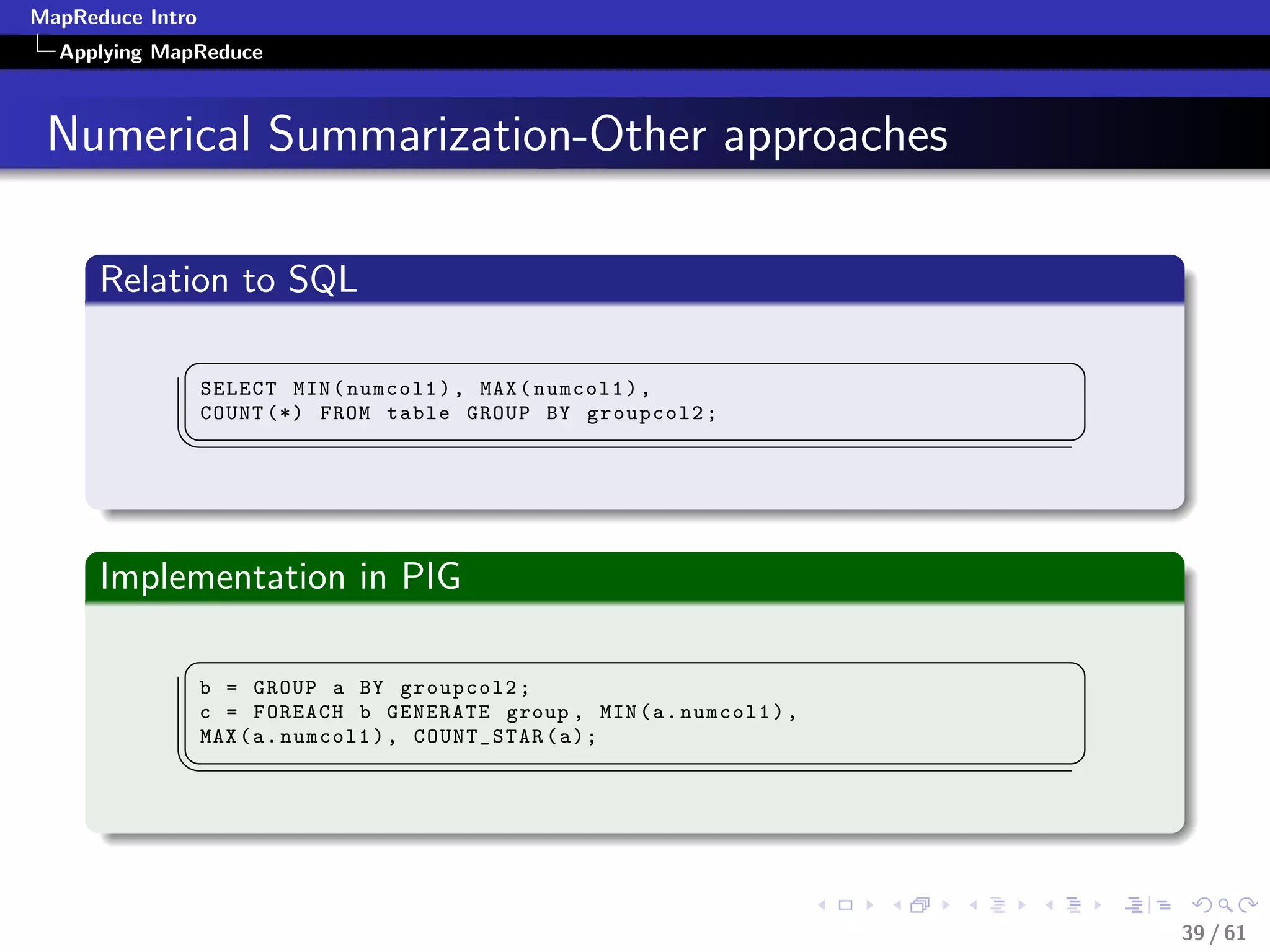
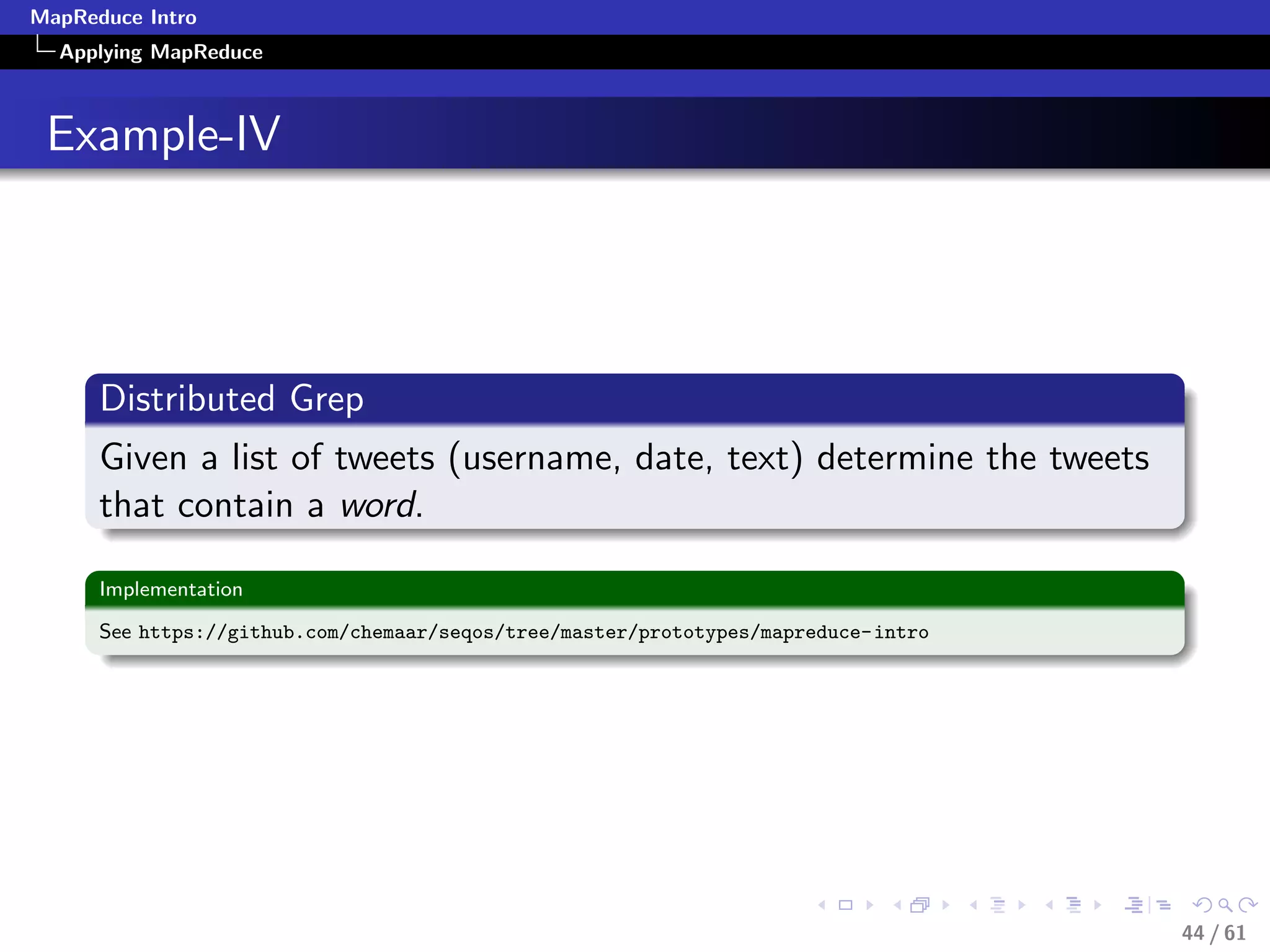
Filtering-Pseudocode
class Mapper
method Map(recordid id, record r)
field f = extract(r)
if predicate (f)
Emit(recordid id, value(r))
class Reducer
method Reduce(recordid id, values [r1, r2,...])
//Whatever
Emit(recordid id, aggregate (values))
43 / 61](https://image.slidesharecdn.com/map-reduce-intro-130424032255-phpapp01/75/Map-Reduce-intro-43-2048.jpg)
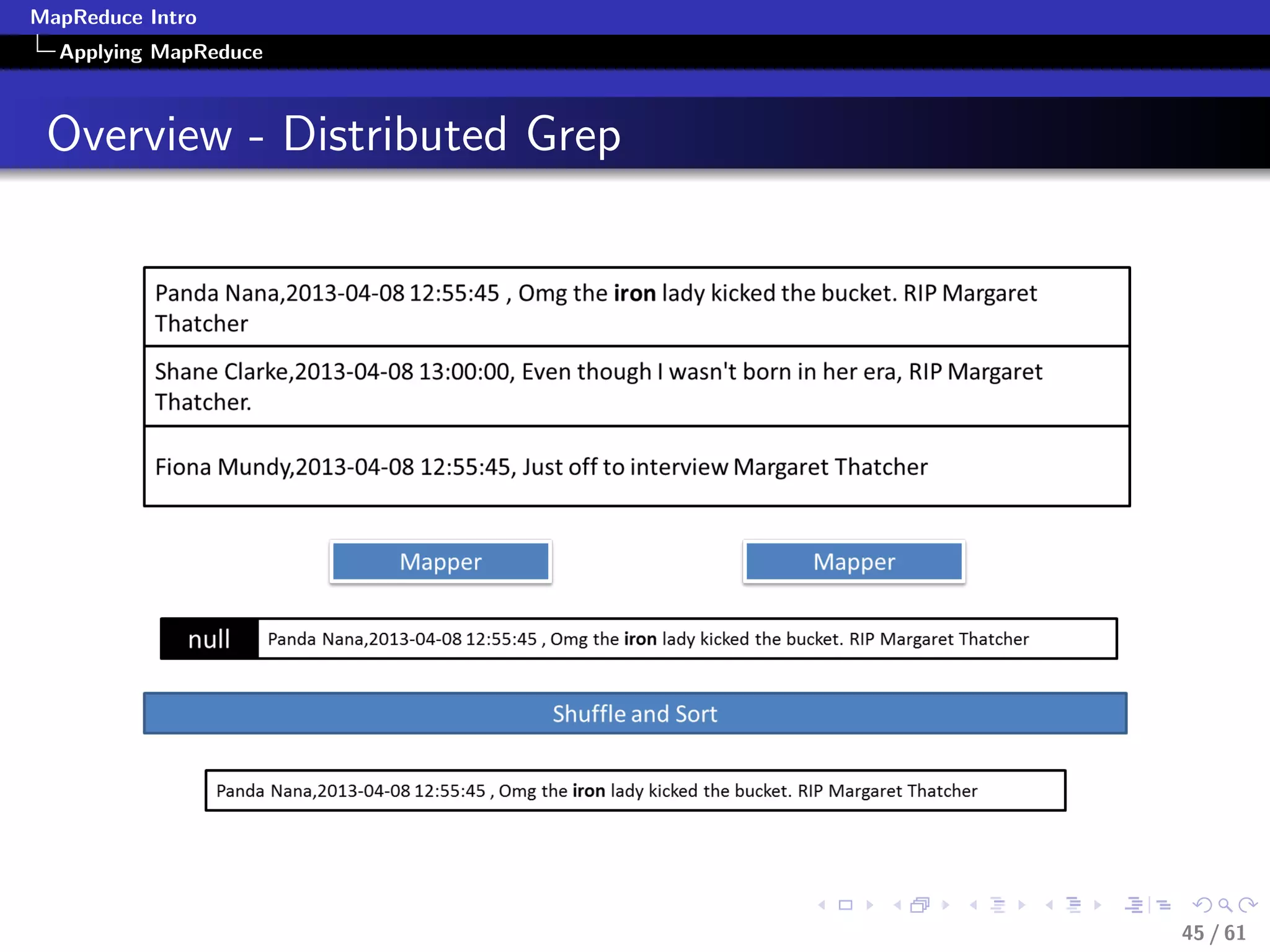
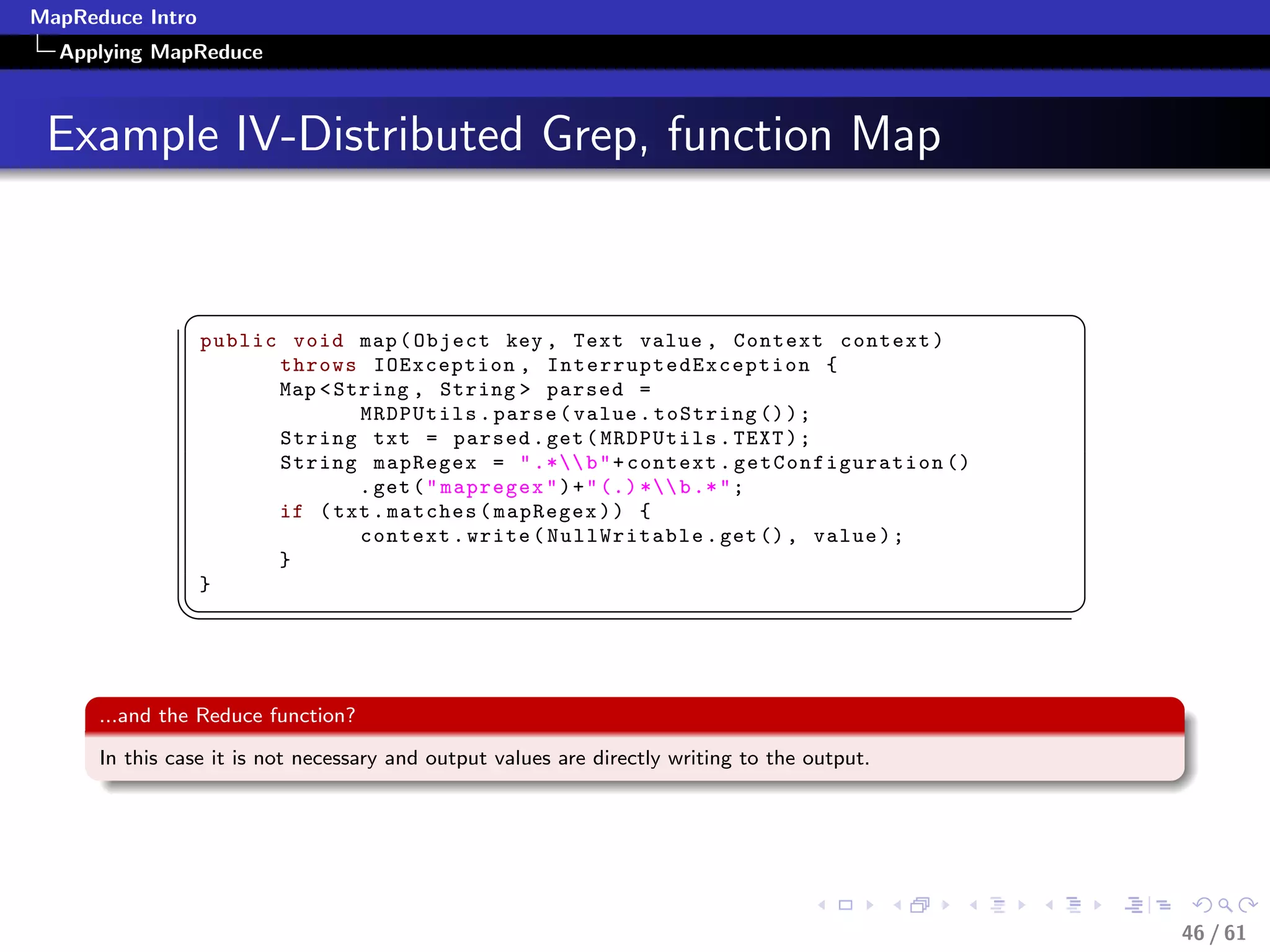




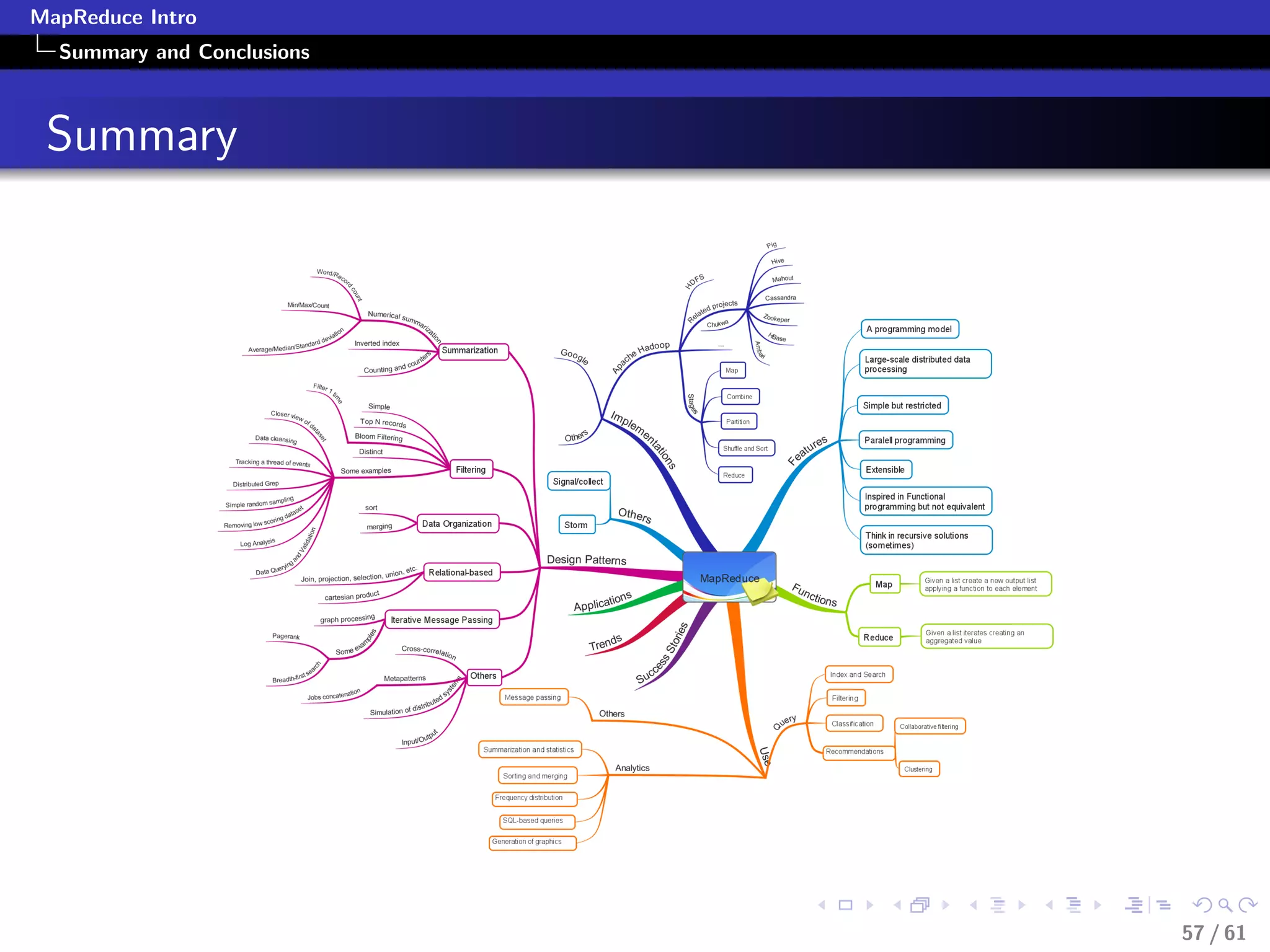




The document provides an introduction to the MapReduce programming model, focusing on its application for large-scale data processing. It explains the Map and Reduce functions, when to use MapReduce, and provides practical examples of its application in various contexts like querying, filtering, and summarizing data. Additionally, it discusses how Google uses MapReduce for significant operations, and illustrates data processing patterns using pseudocode and real-world examples.

































![[150824]symposium v4](https://cdn.slidesharecdn.com/ss_thumbnails/150824symposiumv4-150828061419-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)









































































