






















































![YANG (Yet Another Next Generation)
• YANG organizational constructs include defining lists of
nodes with the same names and identifying the keys which
distinguish list members from each other.
• Such lists may be defined as either sorted by user or
automatically sorted by the system.
• For user-sorted lists, operations are defined for
manipulating the order of the nodes.
• YANG modules can be translated into an XML format called
YIN, allowing applications using XML parsers and XSLT
scripts to operate on the models.
• XML Schema [XSD] files can be generated from YANG
modules, giving a precise description of the XML
representation of the data modeled in YANG modules](https://image.slidesharecdn.com/ioemodule6-220415044047/75/IOE-MODULE-6-pptx-83-2048.jpg)

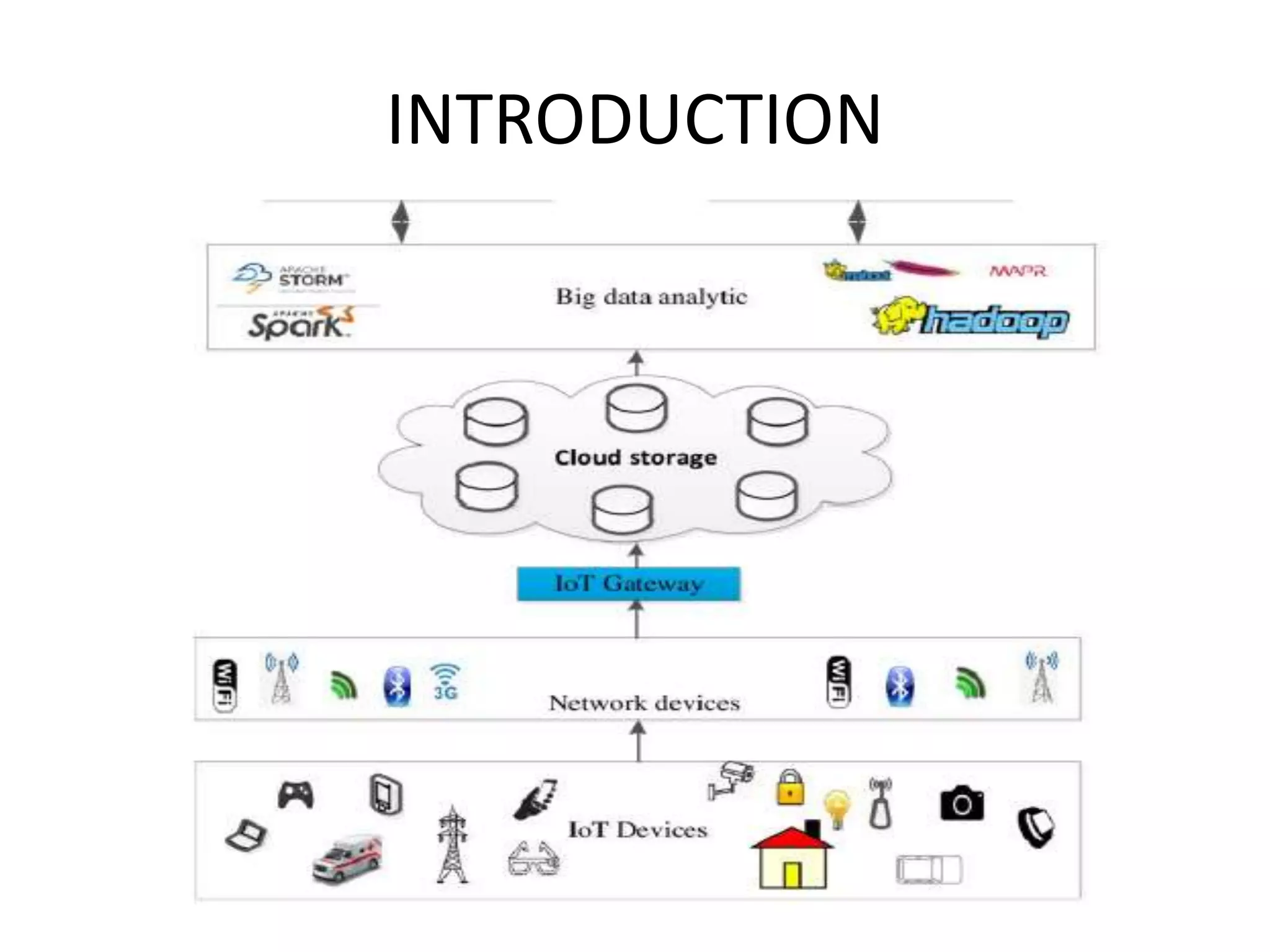
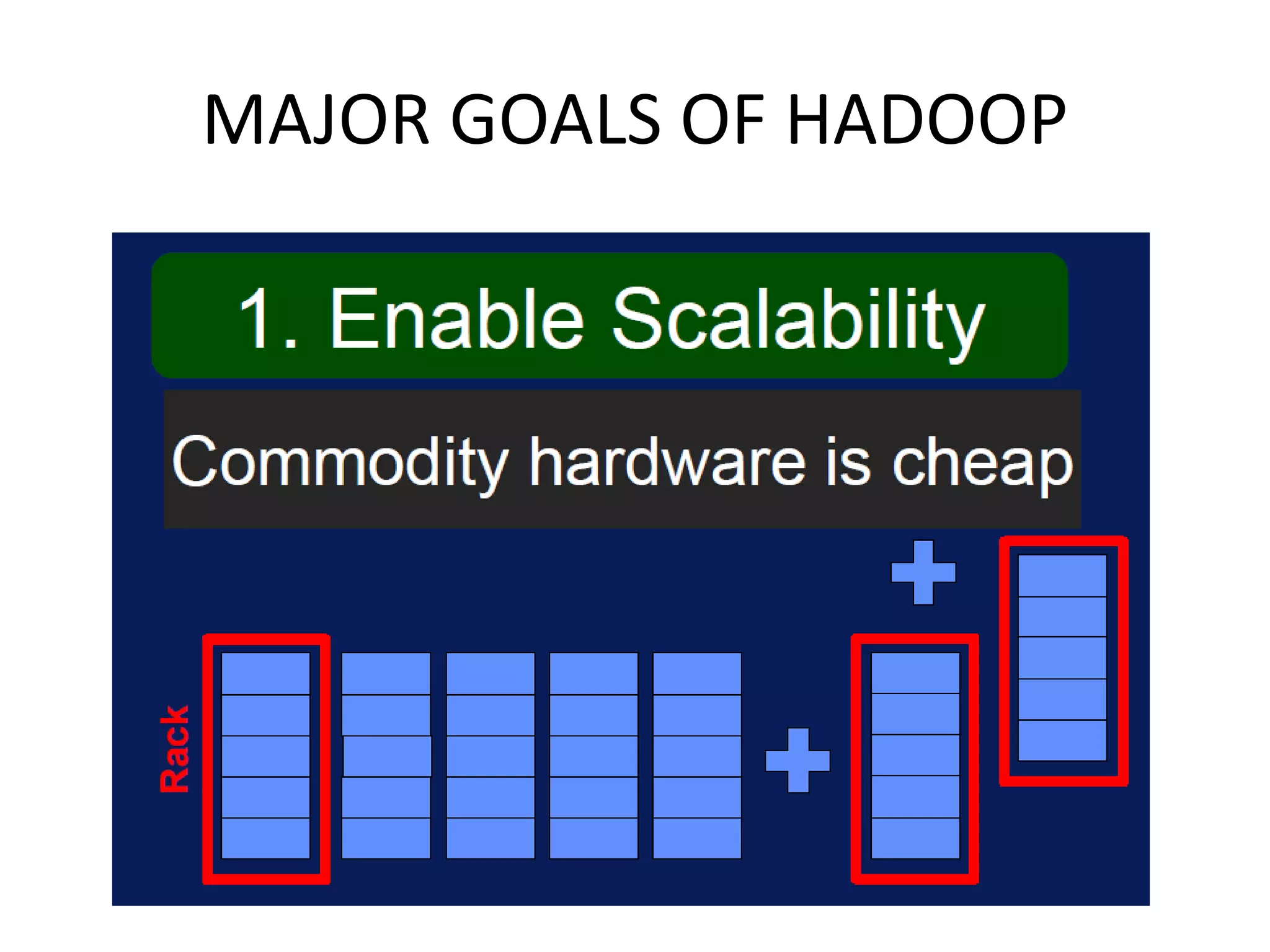
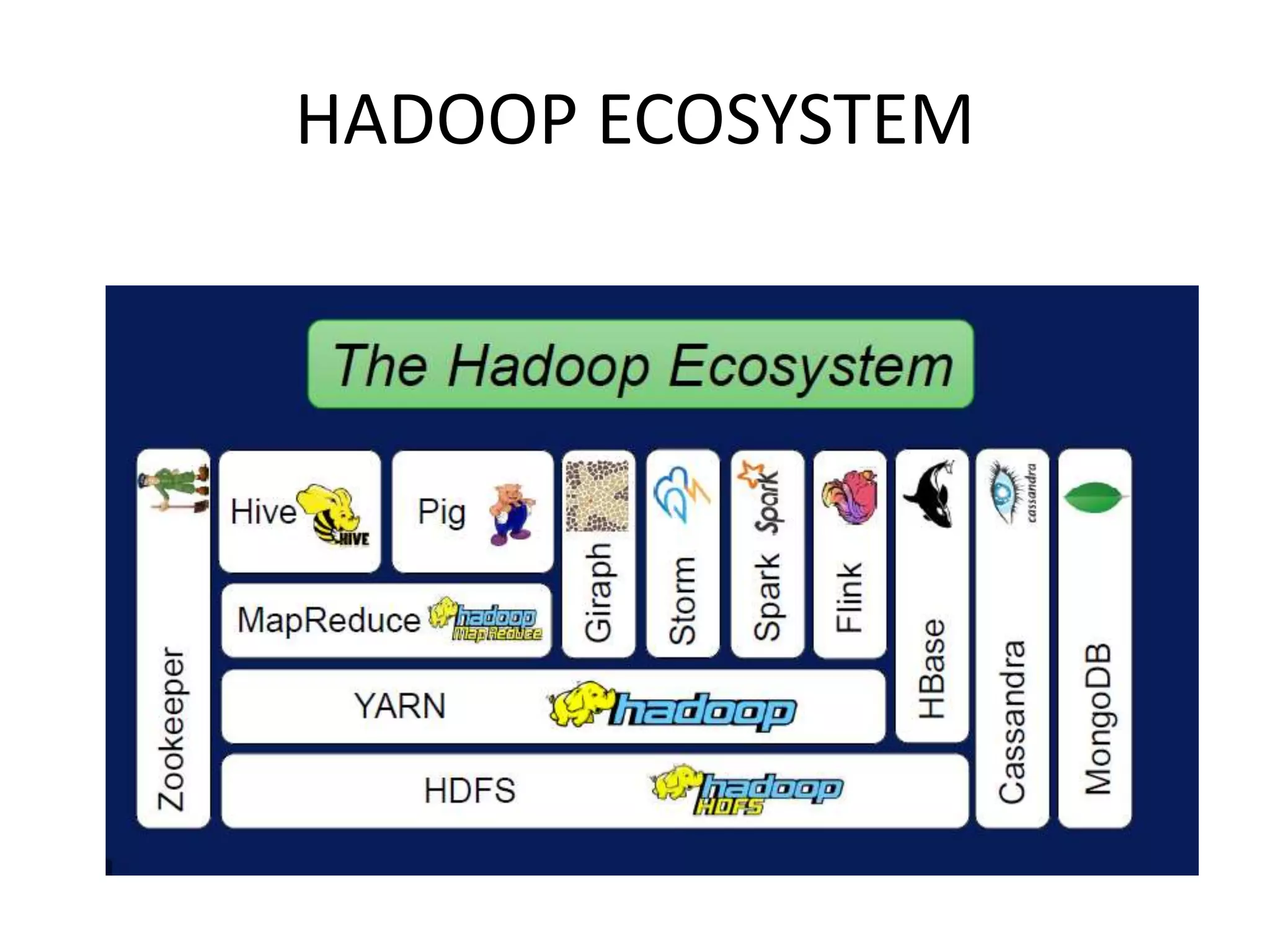
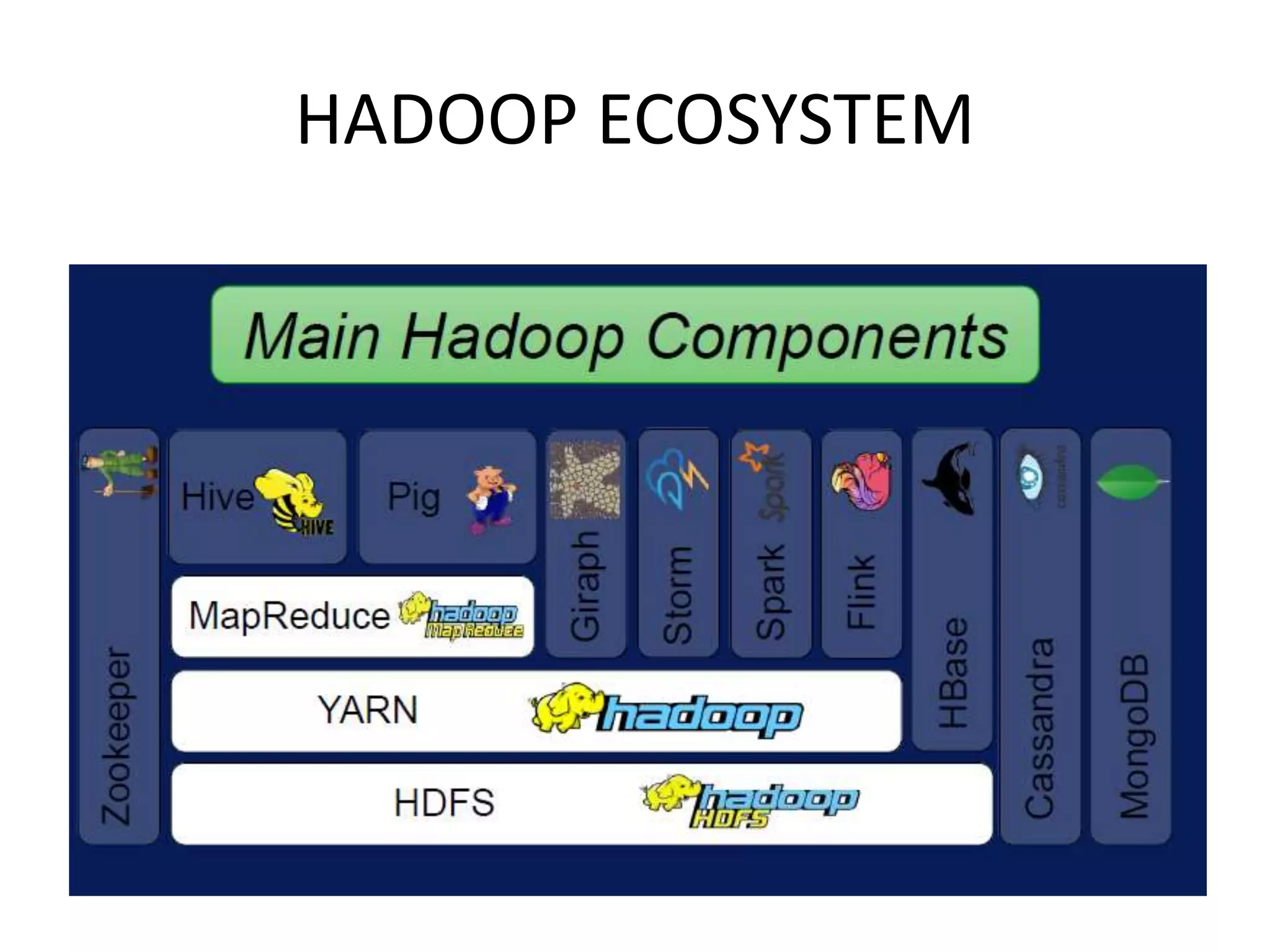
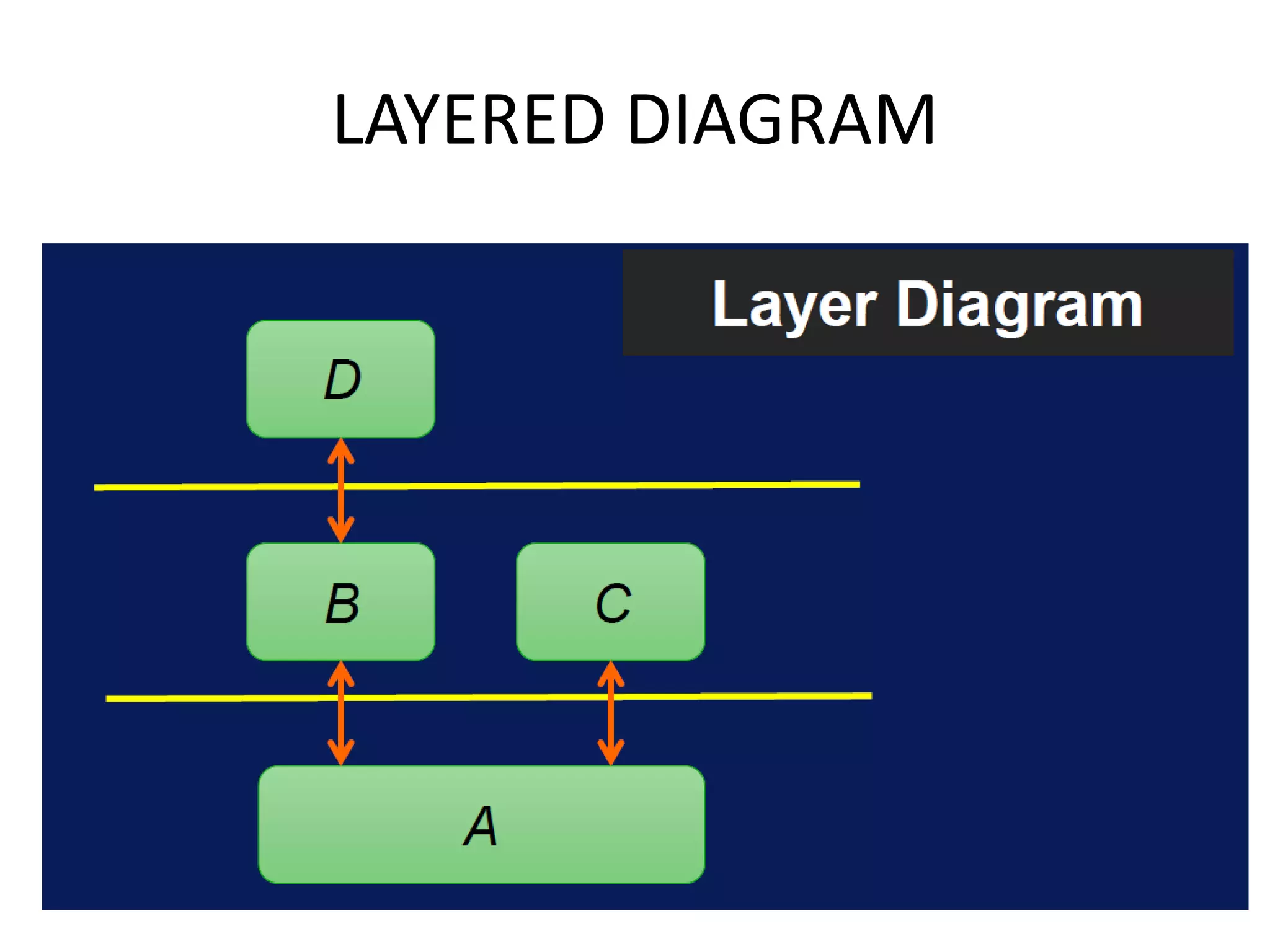
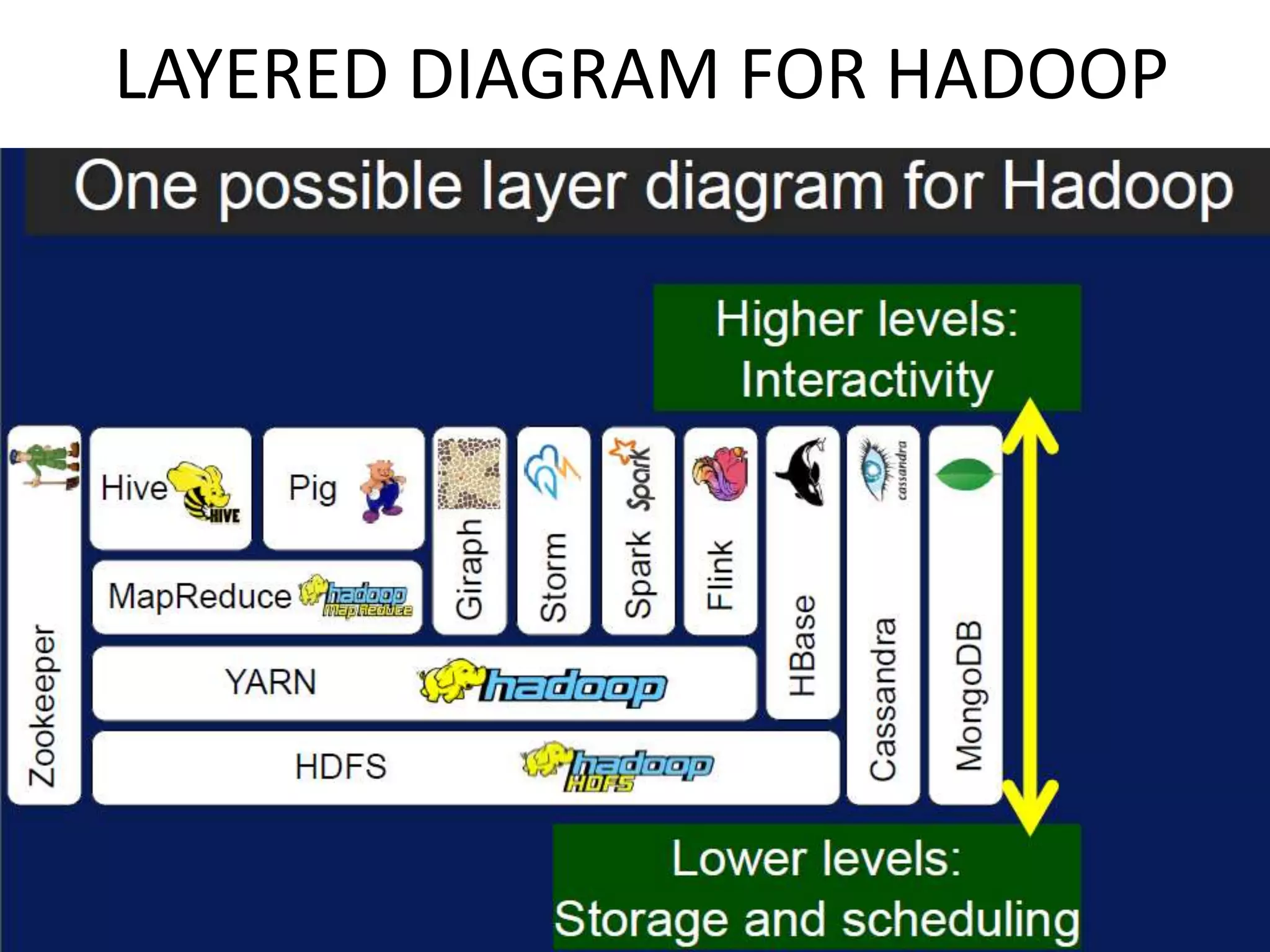
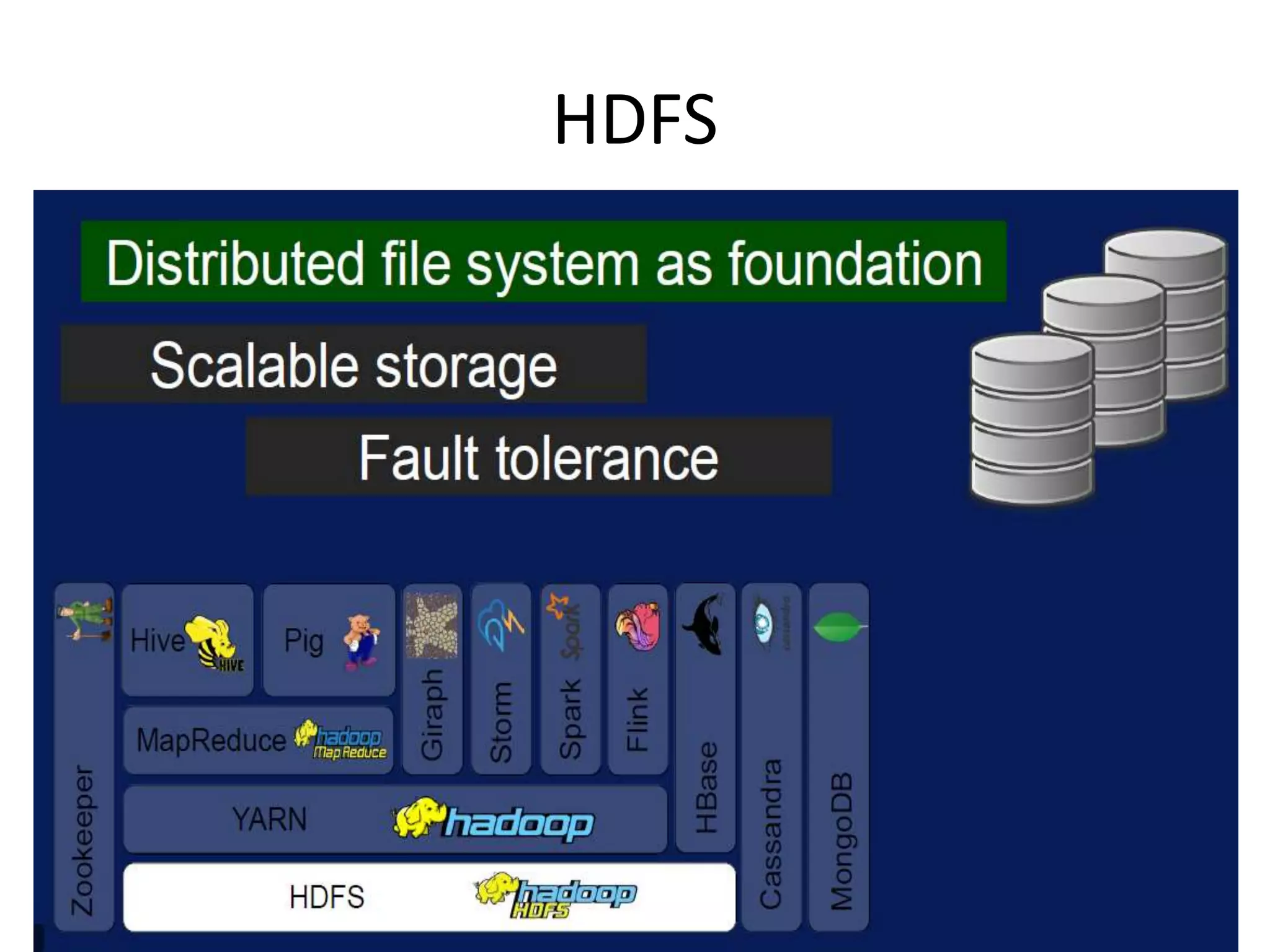
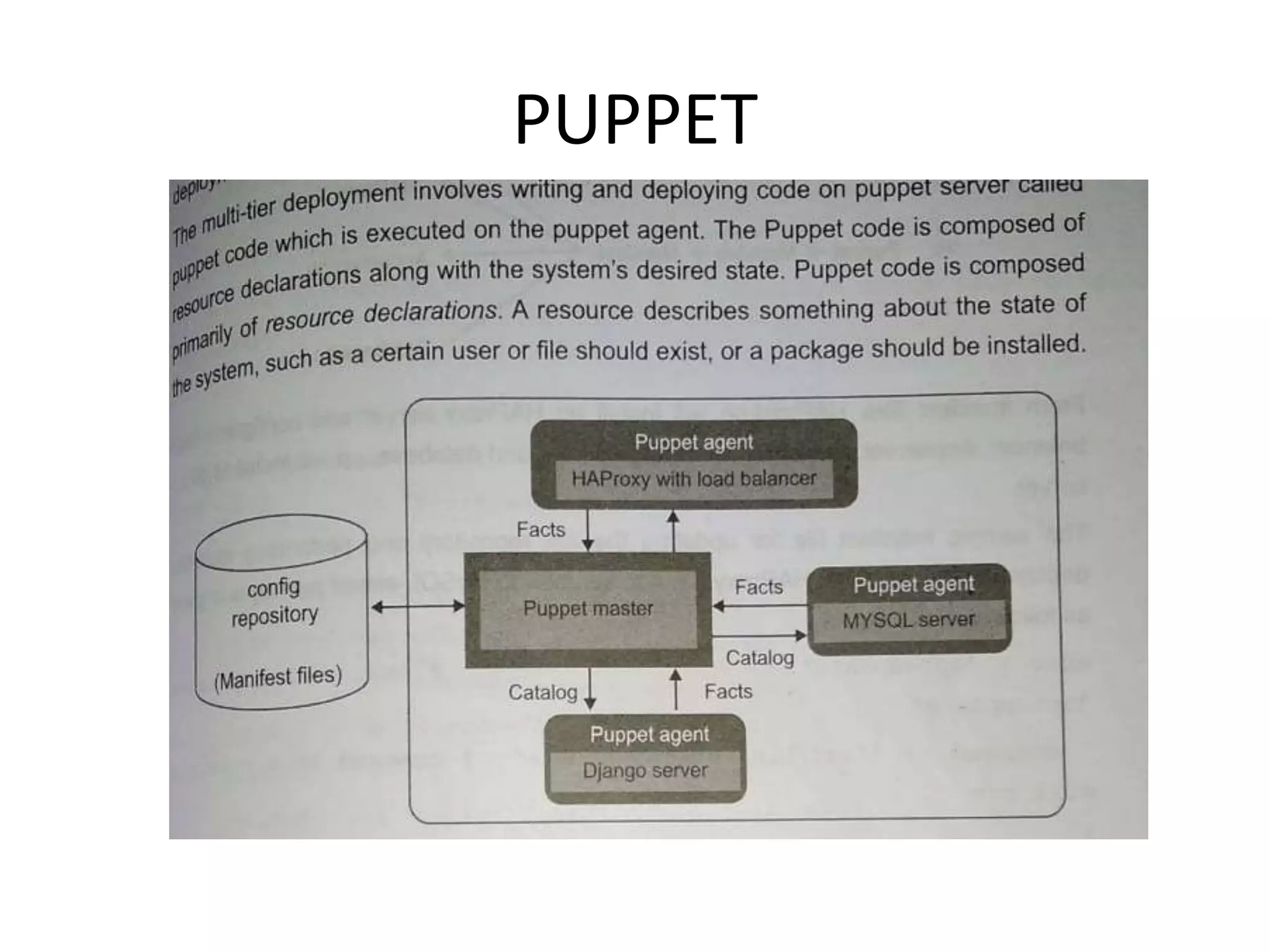
This document provides an overview of various data analytics tools and frameworks for IoT, including Apache Hadoop, Apache Spark, Apache Storm, and NETCONF-YANG. It discusses using Hadoop MapReduce for batch data analysis, Apache Oozie for workflow scheduling, Apache Spark for fast processing, and Apache Storm for real-time streaming data analysis. Tools for deploying IoT systems like Chef and Puppet are also mentioned. Case studies and structural health monitoring are provided as examples of applying these technologies.
Introduction to Data Analytics for IoE focusing on smart city design and data analysis through sensors.
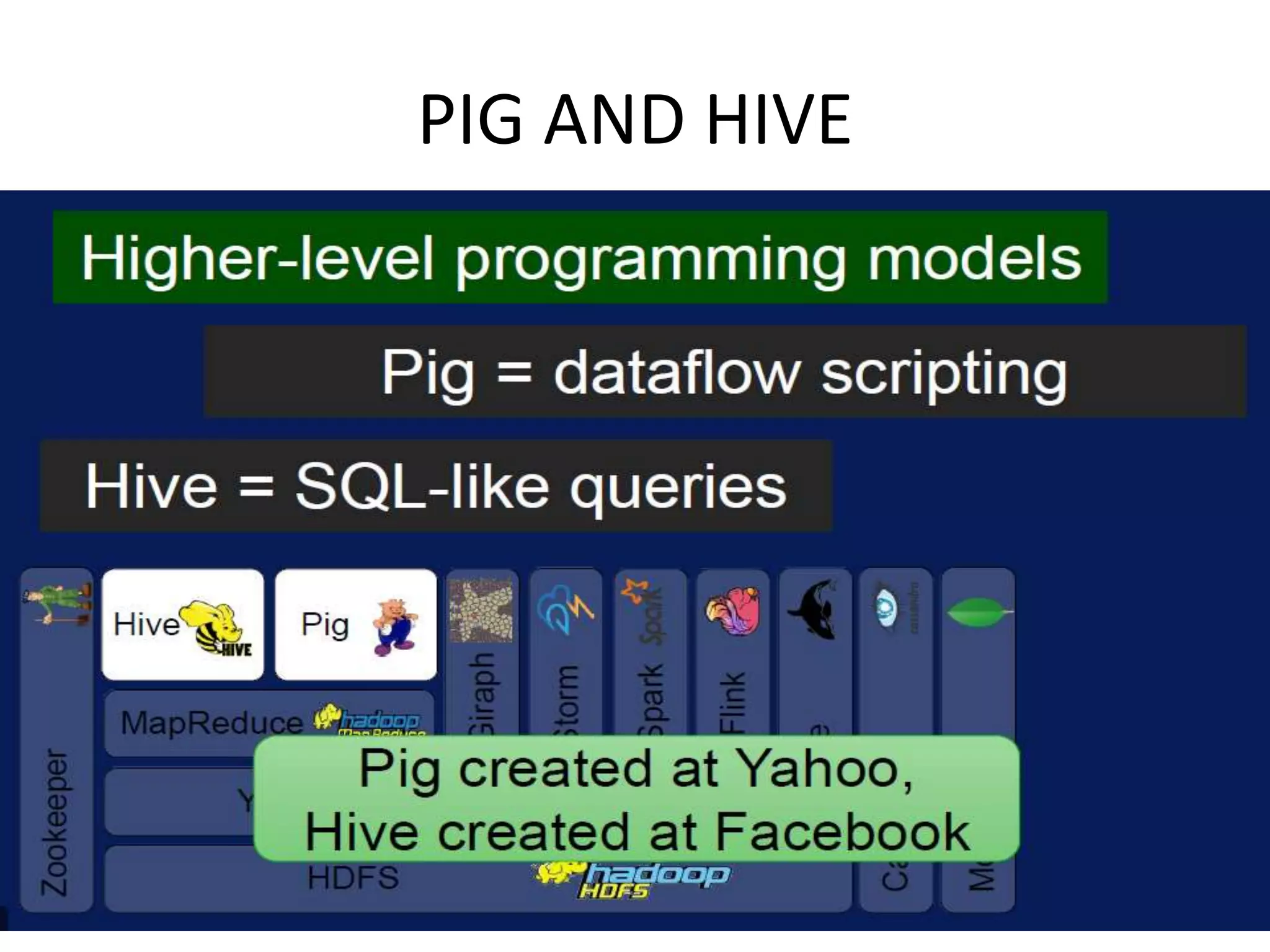
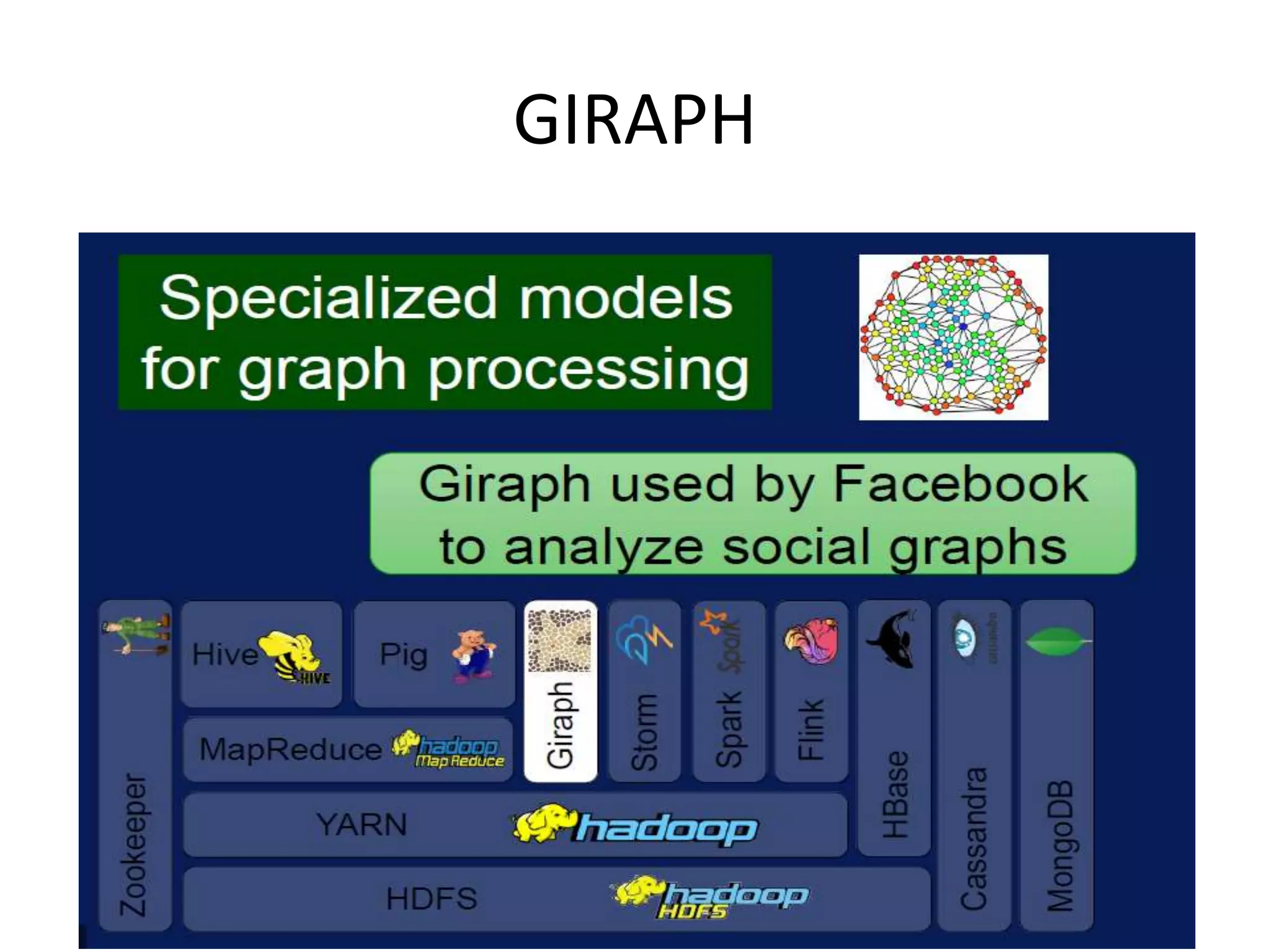
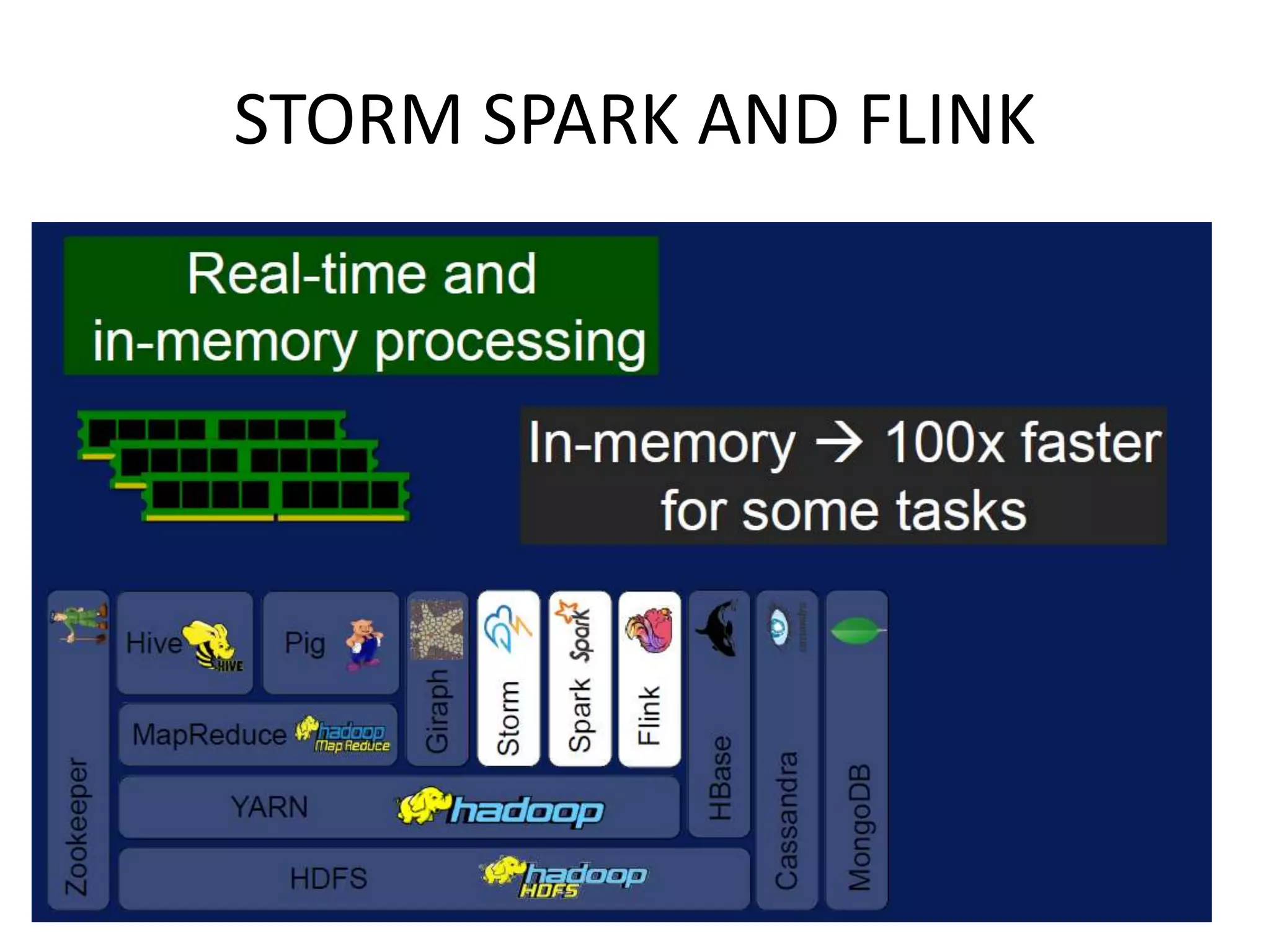
Discusses technologies like Hadoop, Spark, and Oozie for batch and real-time data analysis.
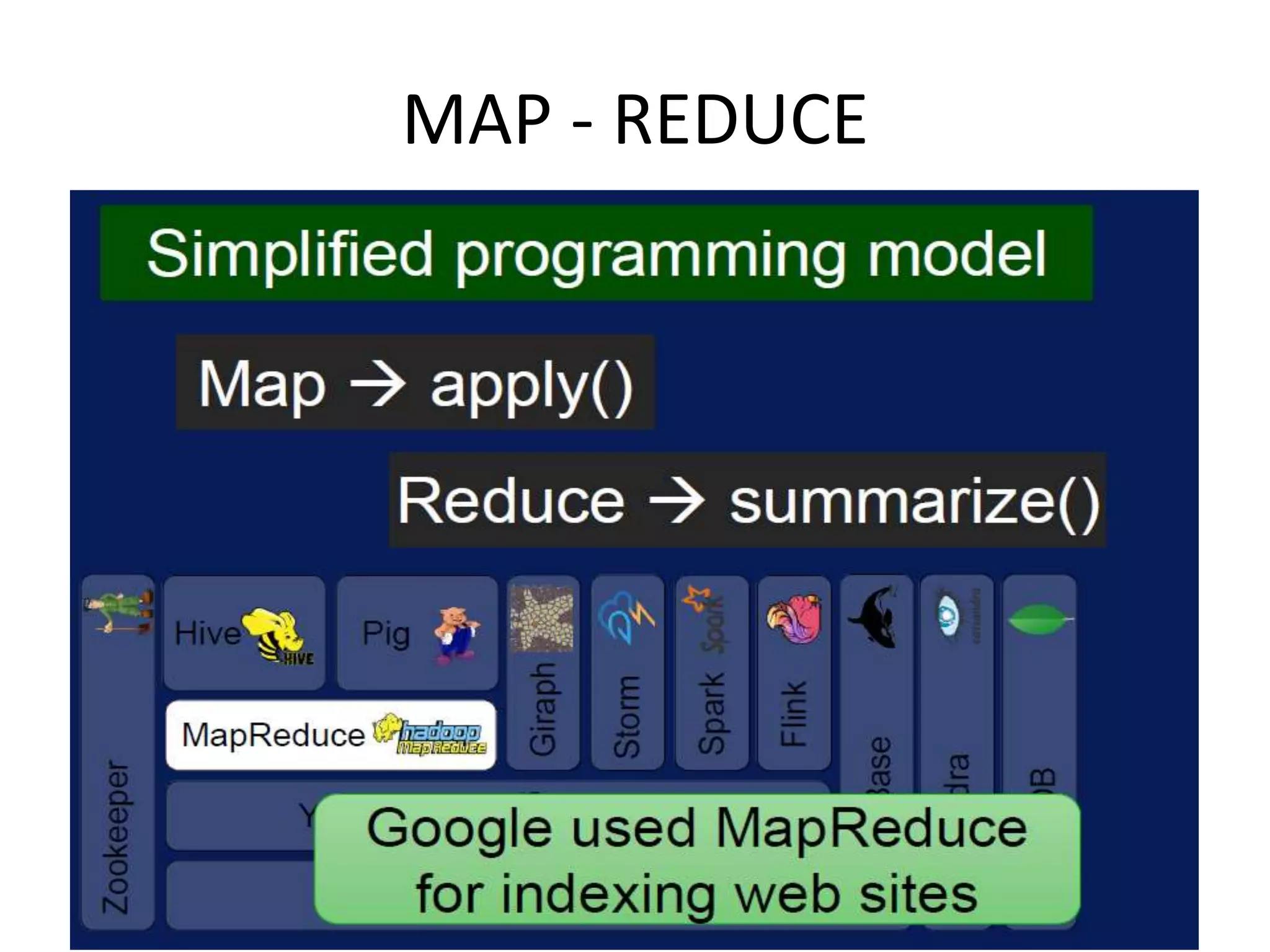
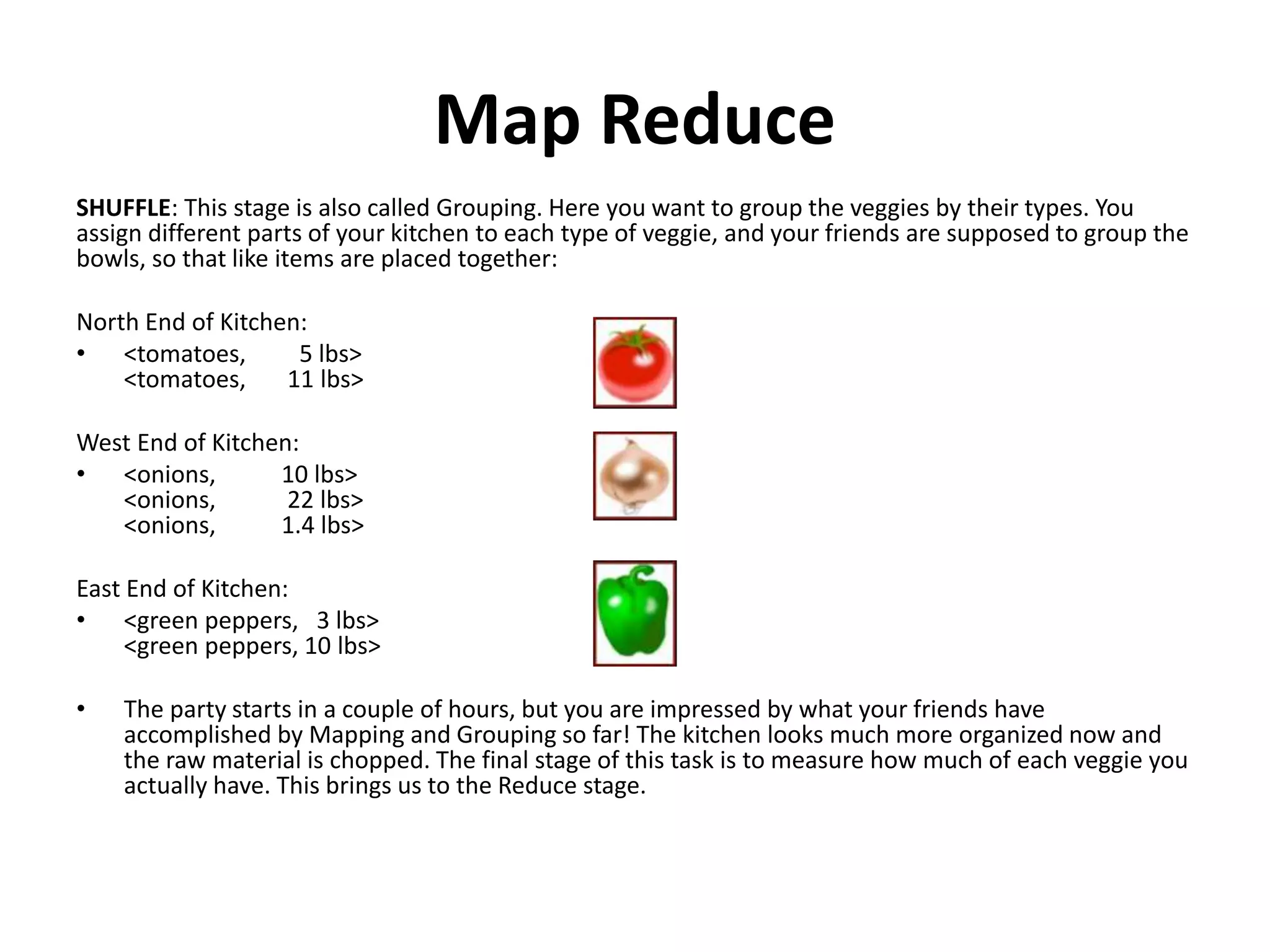
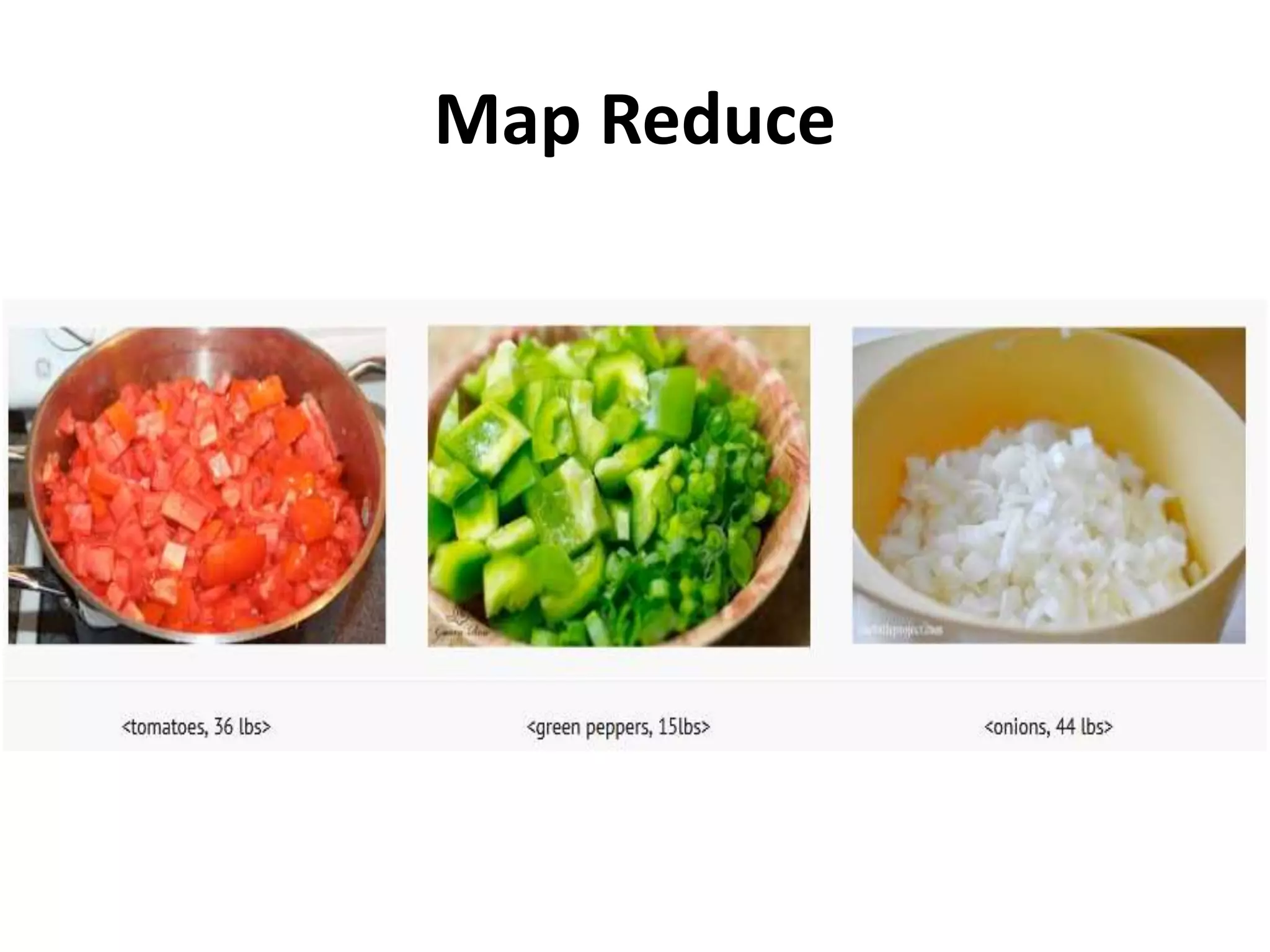
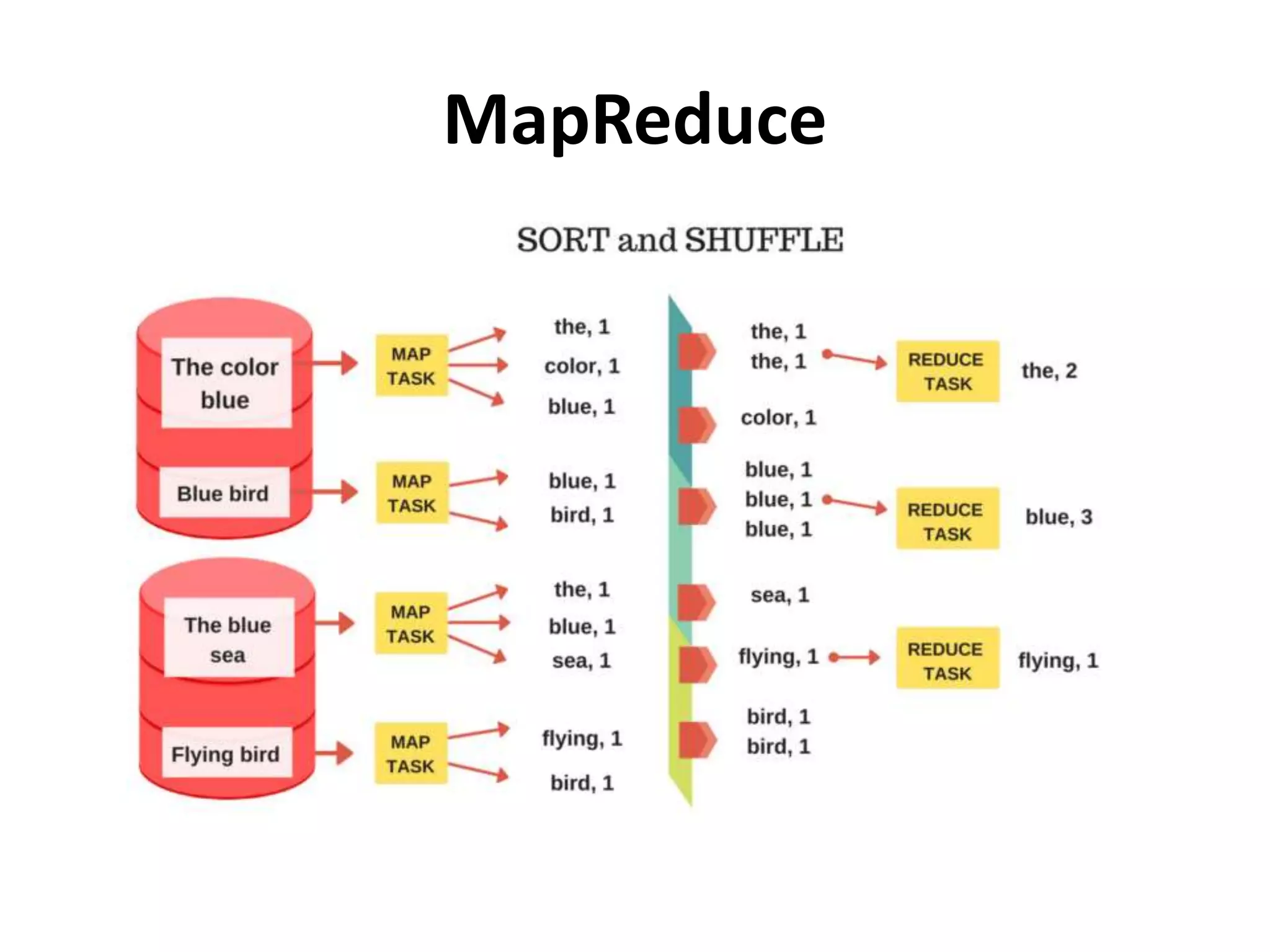
Explains the Map-Reduce framework, its process steps (Map, Shuffle, Reduce), and a practical example.
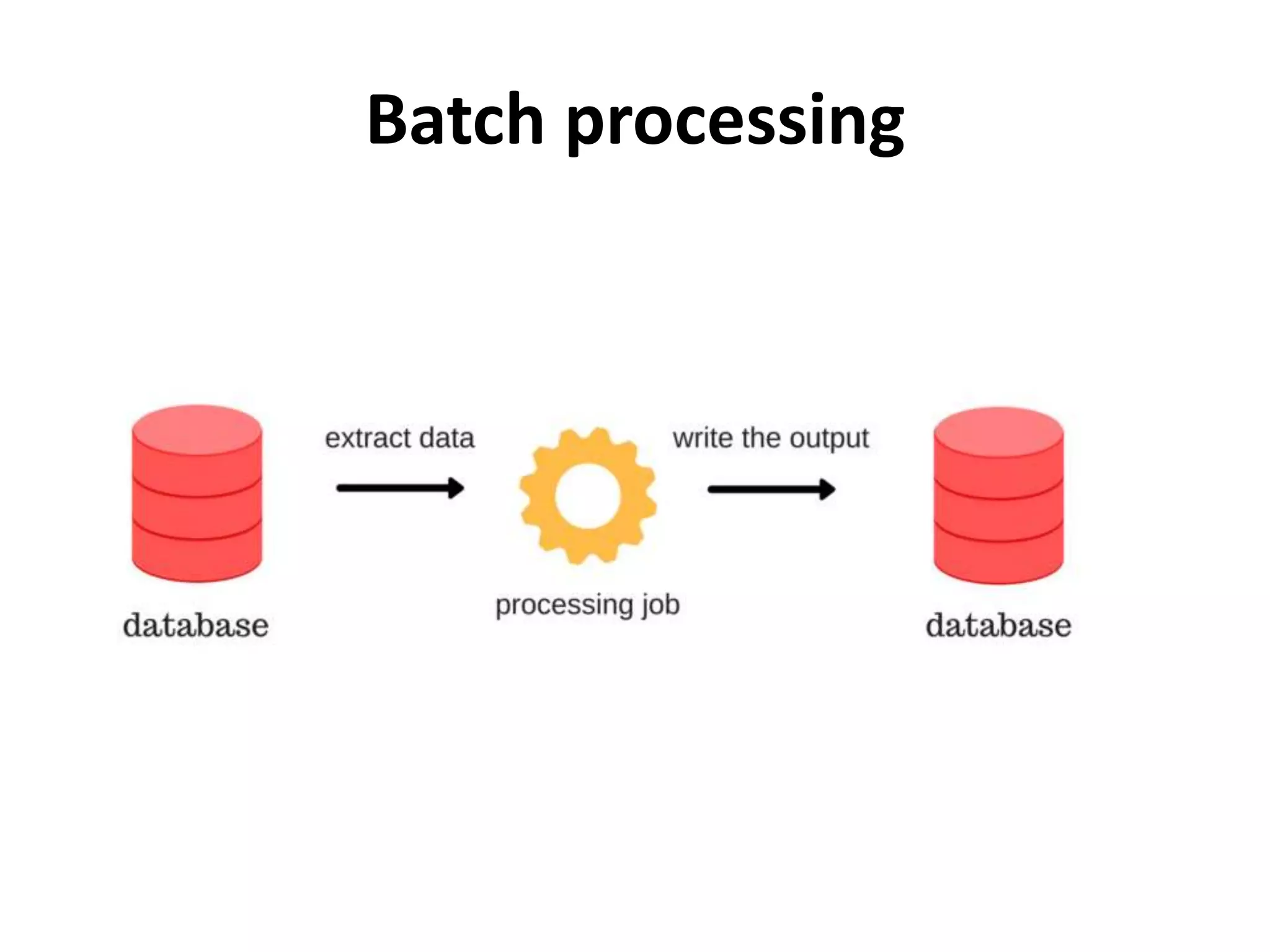
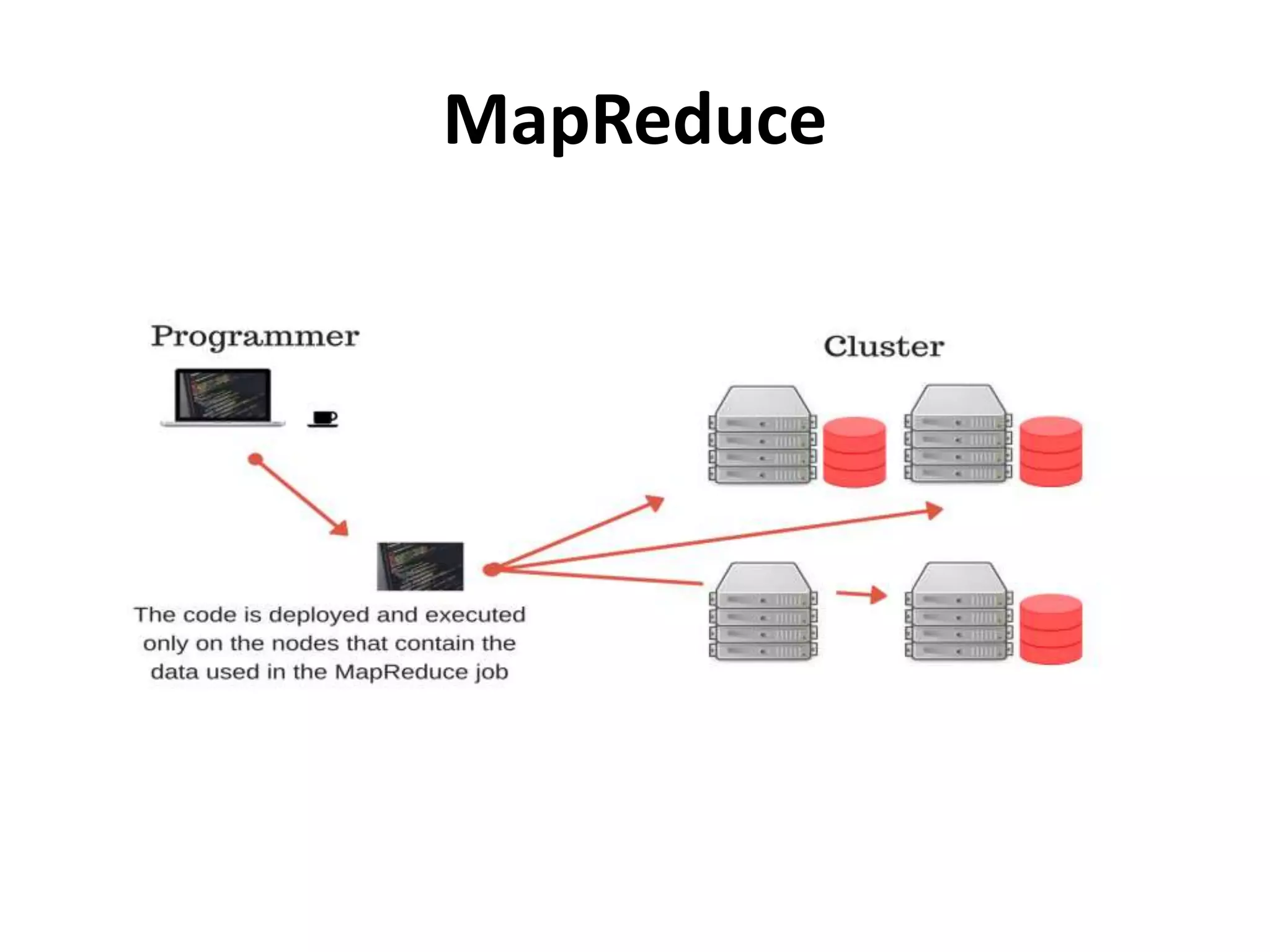
Describes batch processing and how Map-Reduce manages large data sets across multiple nodes.
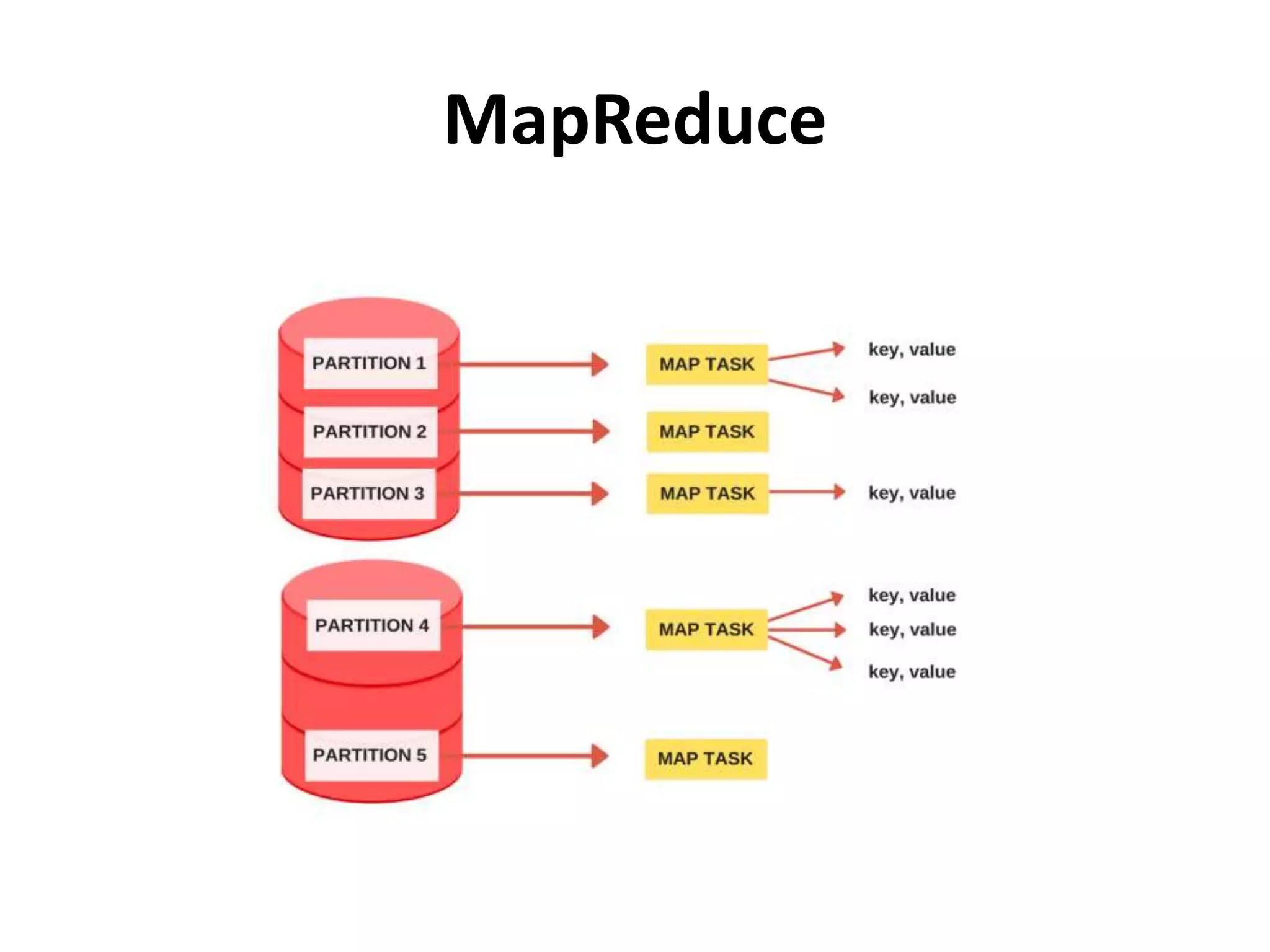
Details on Map-Reduce execution, partitioning, and the role of mapper and reducer tasks.
Explains how output from mappers is processed through reducers for distributed data analysis.
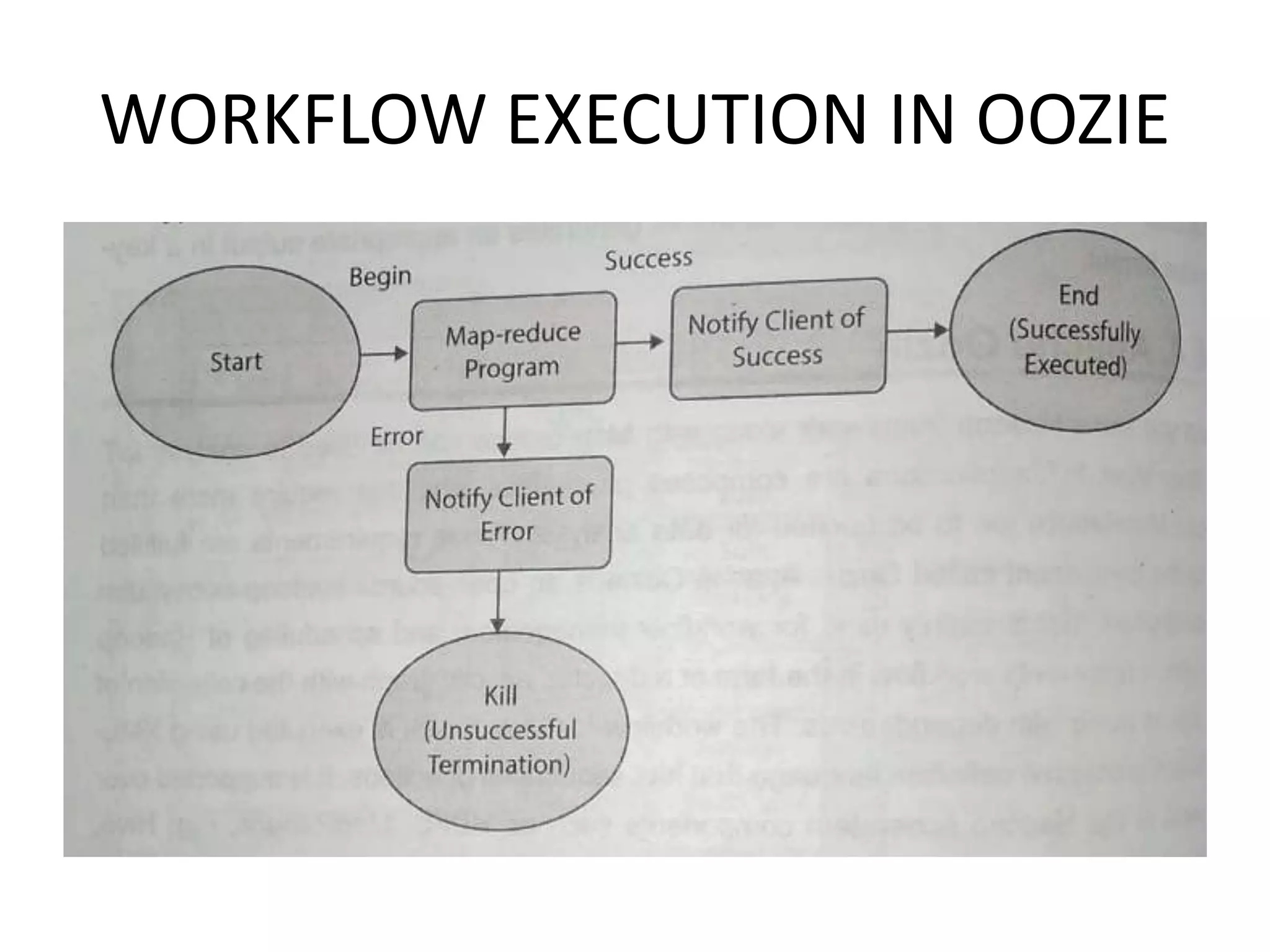
Overview of Apache Oozie as a scheduler for managing Hadoop jobs and its workflow capabilities.
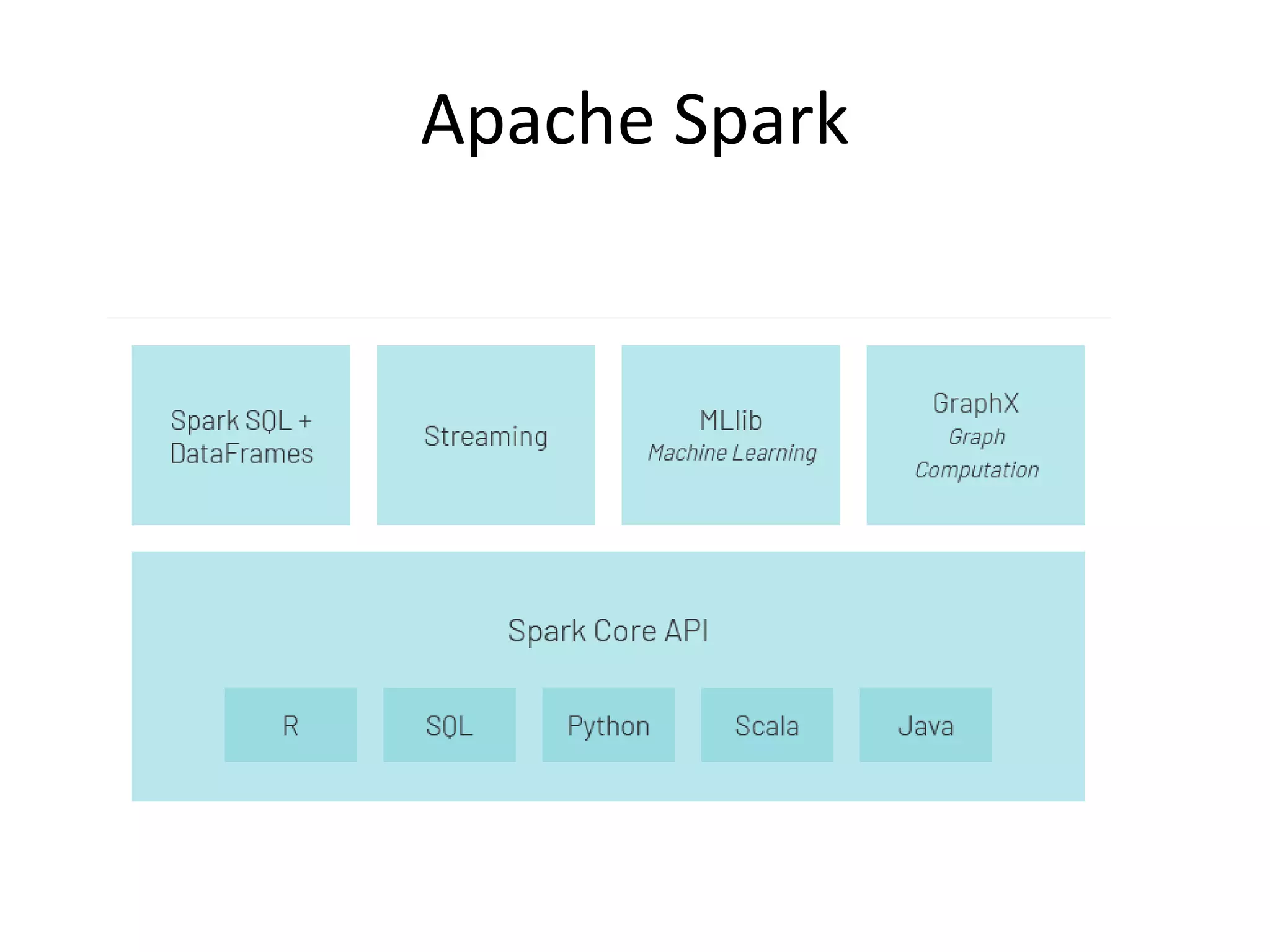
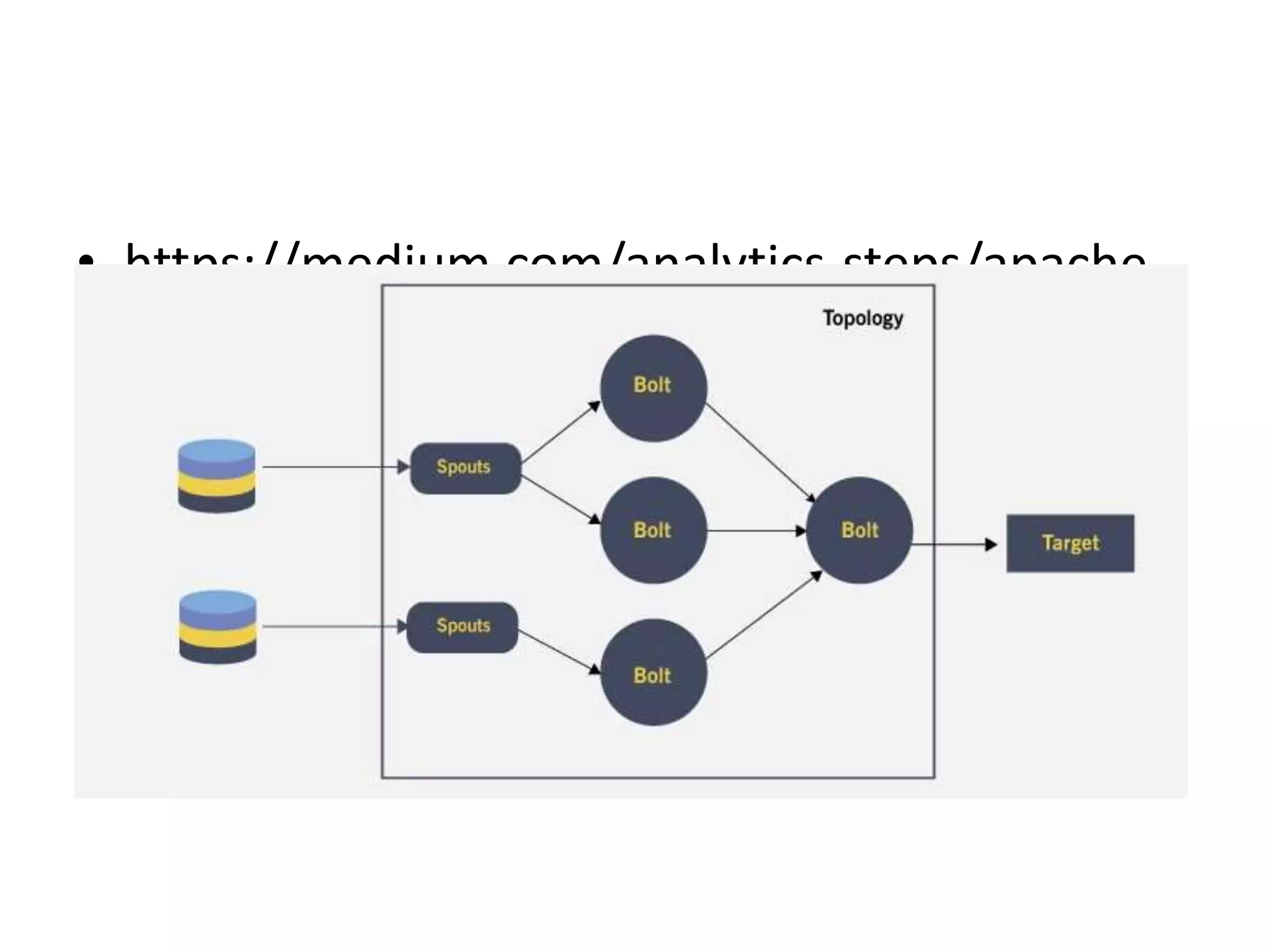
Introduction to Apache Spark, its high-speed processing, adoption in industry, and advantages.Apache Storm's architecture and capabilities for processing real-time data streams effectively.
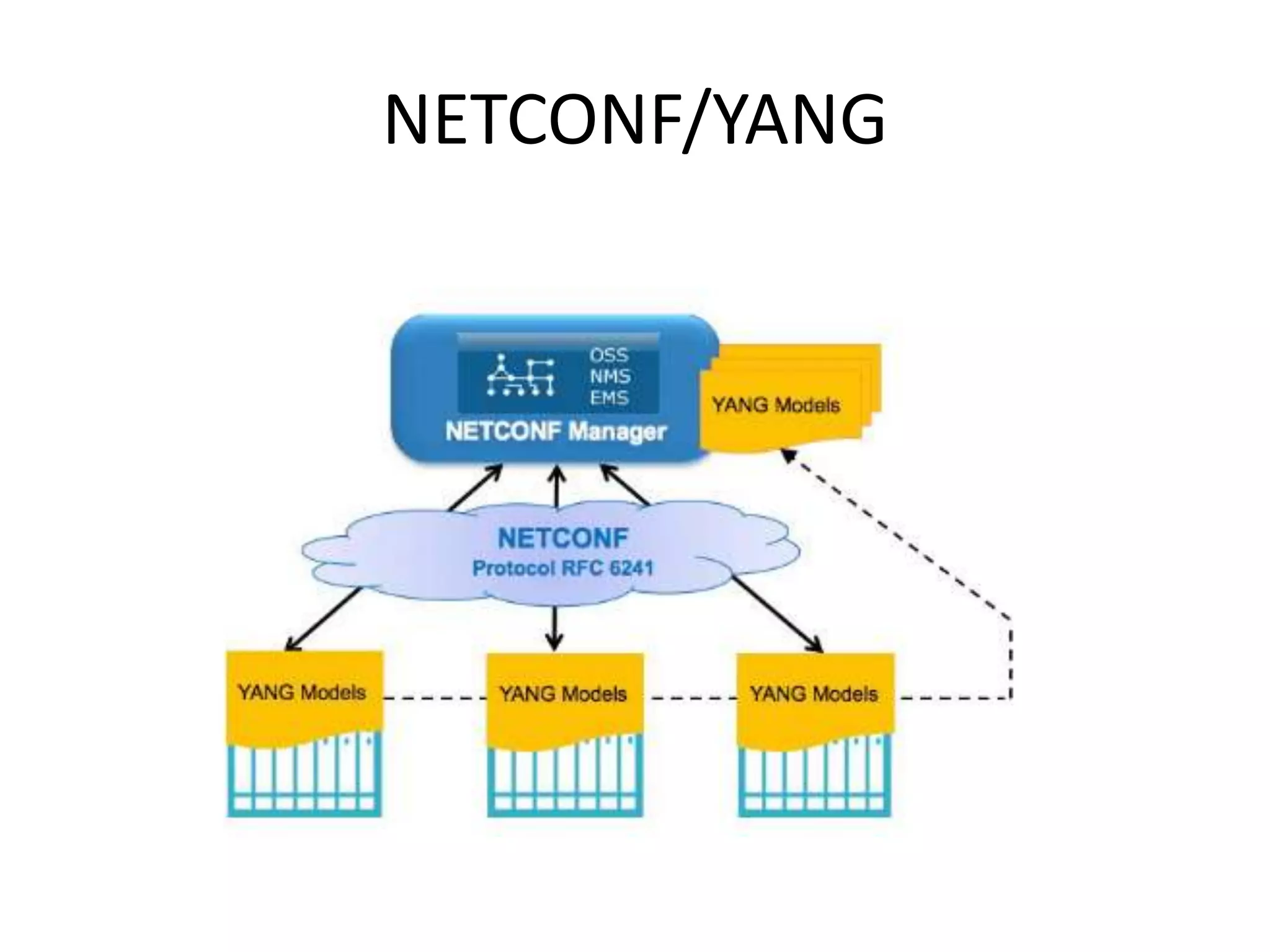
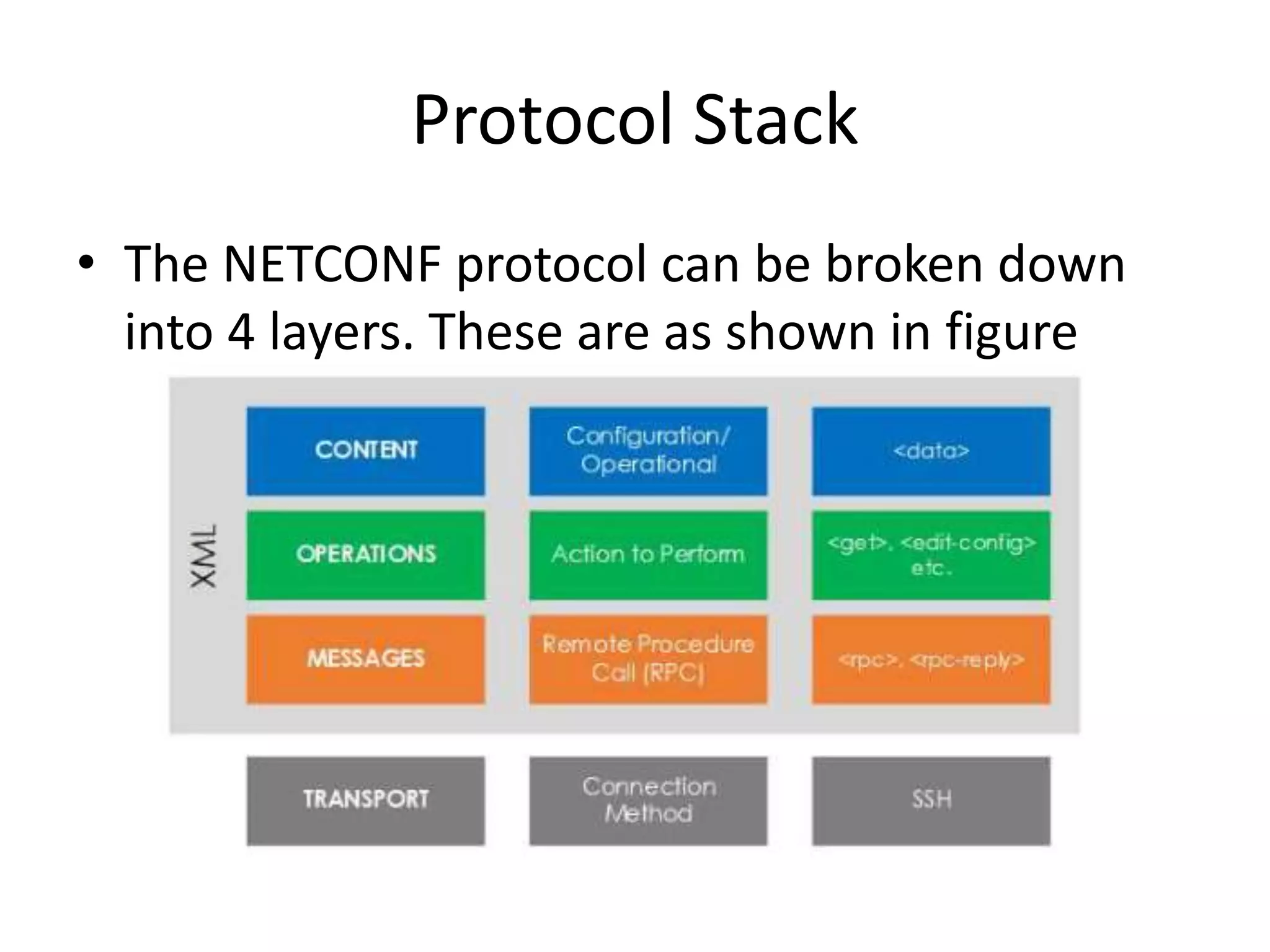
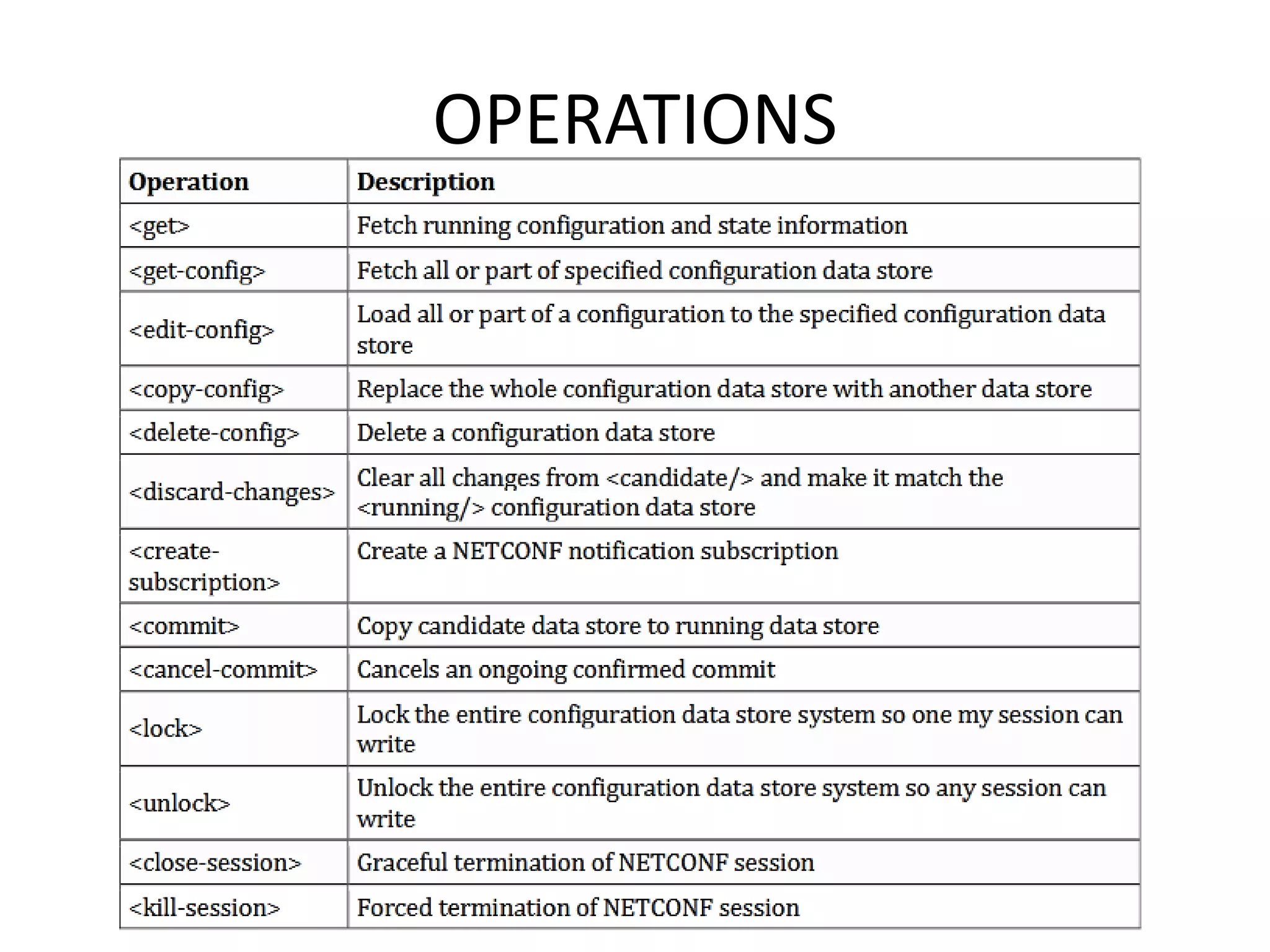
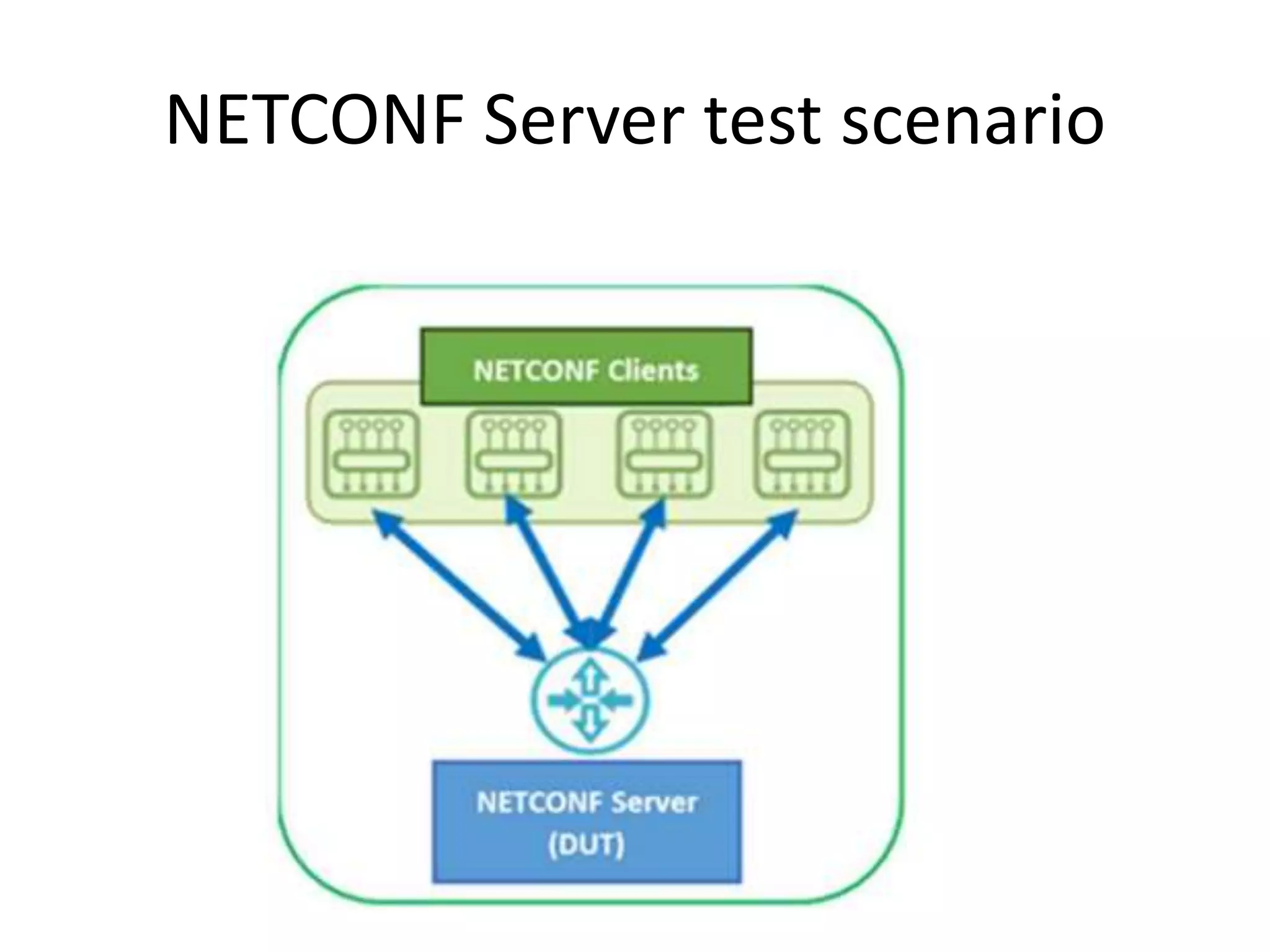
Explains NETCONF and YANG protocols for managing network configurations, including transactions and operations.
Discusses YANG's language for data modeling in NETCONF, including extensibility and organization of data.













































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)









