









![packages:
- puppet
# Send pre-generated ssh private keys to the server
ssh_keys:
rsa_private: | ${SSH_RSA_PRIVATE_KEY}
rsa_public: ${SSH_RSA_PUBLIC_KEY}
dsa_private: | ${SSH_DSA_PRIVATE_KEY}
dsa_public: ${SSH_DSA_PUBLIC_KEY}
# set up mount points
# remove default mount points
mounts:
- [ swap, null ]
- [ ephemeral0, null ]
# Additional YUM Repositories
repo_additions:
- source: "lovely-public"
name: "Lovely Systems, Public Repository for RHEL 6 compatible Distributions"
filename: lovely-public.repo
enabled: 1
gpgcheck: 1
key: "file:///etc/pki/rpm-gpg/RPM-GPG-KEY-lovely"
baseurl: "https://yum.lovelysystems.com/public/release"
runcmd:
- [ hostname, "${HOST}" ]
- [ sed, -i, -e, "s/^HOSTNAME=.*/HOSTNAME=${HOST}/", /etc/sysconfig/network ]
- [ wget, "http://169.254.169.254/latest/meta-data/local-ipv4", -O, /tmp/local-ipv4 ]
- [ sh, -c, echo "$(/bin/cat /tmp/local-ipv4) ${HOST} ${HOST_NAME}" >> /etc/hosts ]
- [ rpm, --import, "https://yum.lovelysystems.com/public/RPM-GPG-KEY-lovely"]
- [ mkdir, -p, /var/lib/puppet/ssl/private_keys ]
- [ mkdir, -p, /var/lib/puppet/ssl/public_keys ]
- [ mkdir, -p, /var/lib/puppet/ssl/certs ]
${PUPPET_PRIVATE_KEY}
- [ mv, /tmp/puppet_private_key.pem, /var/lib/puppet/ssl/private_keys/${HOST}.pem ]
${PUPPET_PUBLIC_KEY}
- [ mv, /tmp/puppet_public_key.pem, /var/lib/puppet/ssl/public_keys/${HOST}.pem ]
${PUPPET_CERT}
- [ mv, /tmp/puppet_cert.pem, /var/lib/puppet/ssl/certs/${HOST}.pem ]
- [ sh, -c, echo " server = ${PUPPET_MASTER}" >> /etc/puppet/puppet.conf ]
- [ sh, -c, echo " certname = ${HOST}" >> /etc/puppet/puppet.conf ]
- [ /etc/init.d/puppet, start ]](https://image.slidesharecdn.com/buzz-120607144143-phpapp02/75/You-know-for-search-Querying-24-Billion-Documents-in-900ms-22-2048.jpg)

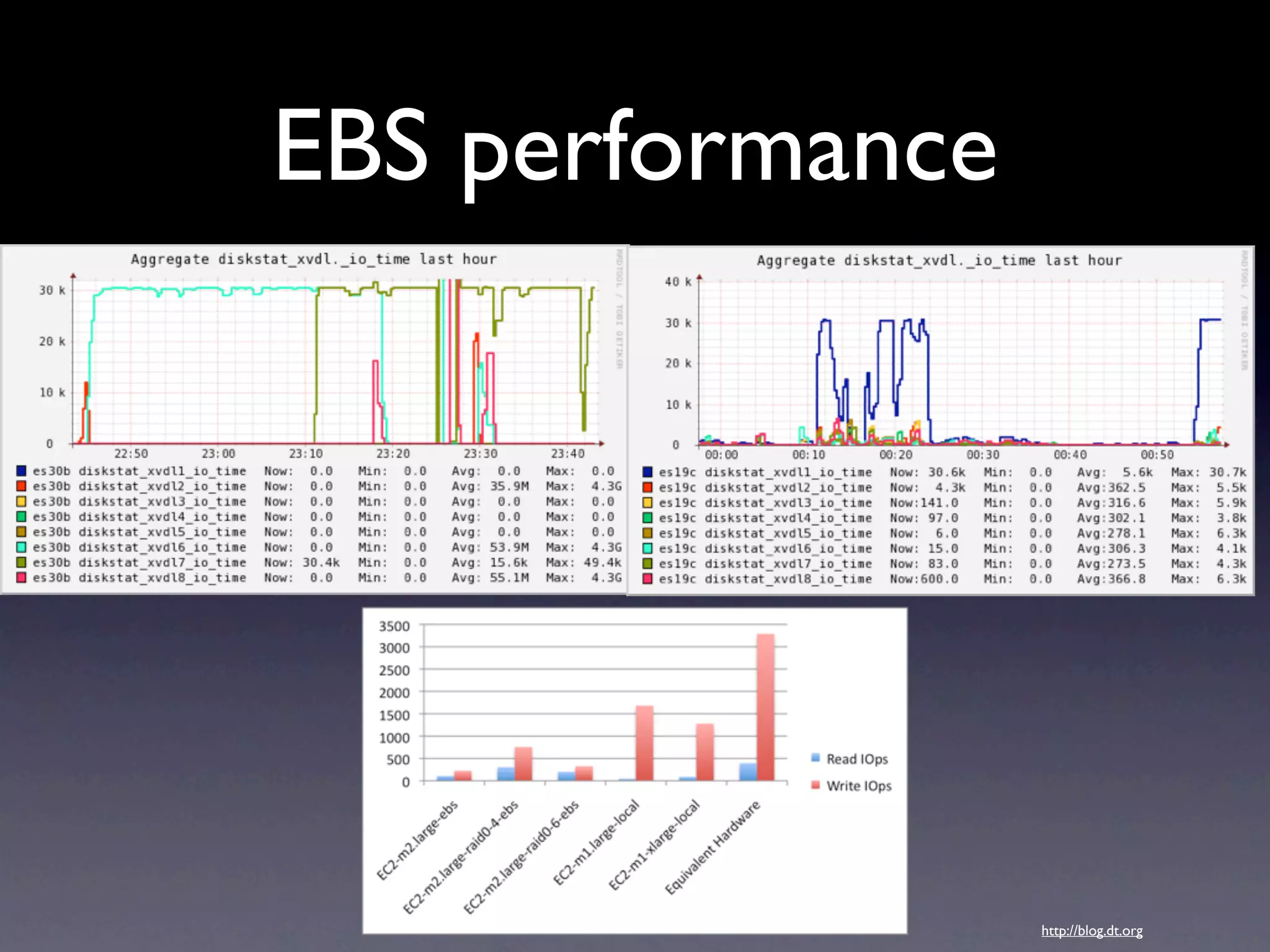
![• Shard allocation
• Avoid rebalancing (Discovery Timeout)
• Uncached Facets
https://github.com/lovelysystems/elasticsearch-ls-plugins
• LUCENE-2205
Rework of the TermInfosReader class to remove the
Terms[], TermInfos[], and the index pointer long[] and create
a more memory efficient data structure.](https://image.slidesharecdn.com/buzz-120607144143-phpapp02/75/You-know-for-search-Querying-24-Billion-Documents-in-900ms-25-2048.jpg)
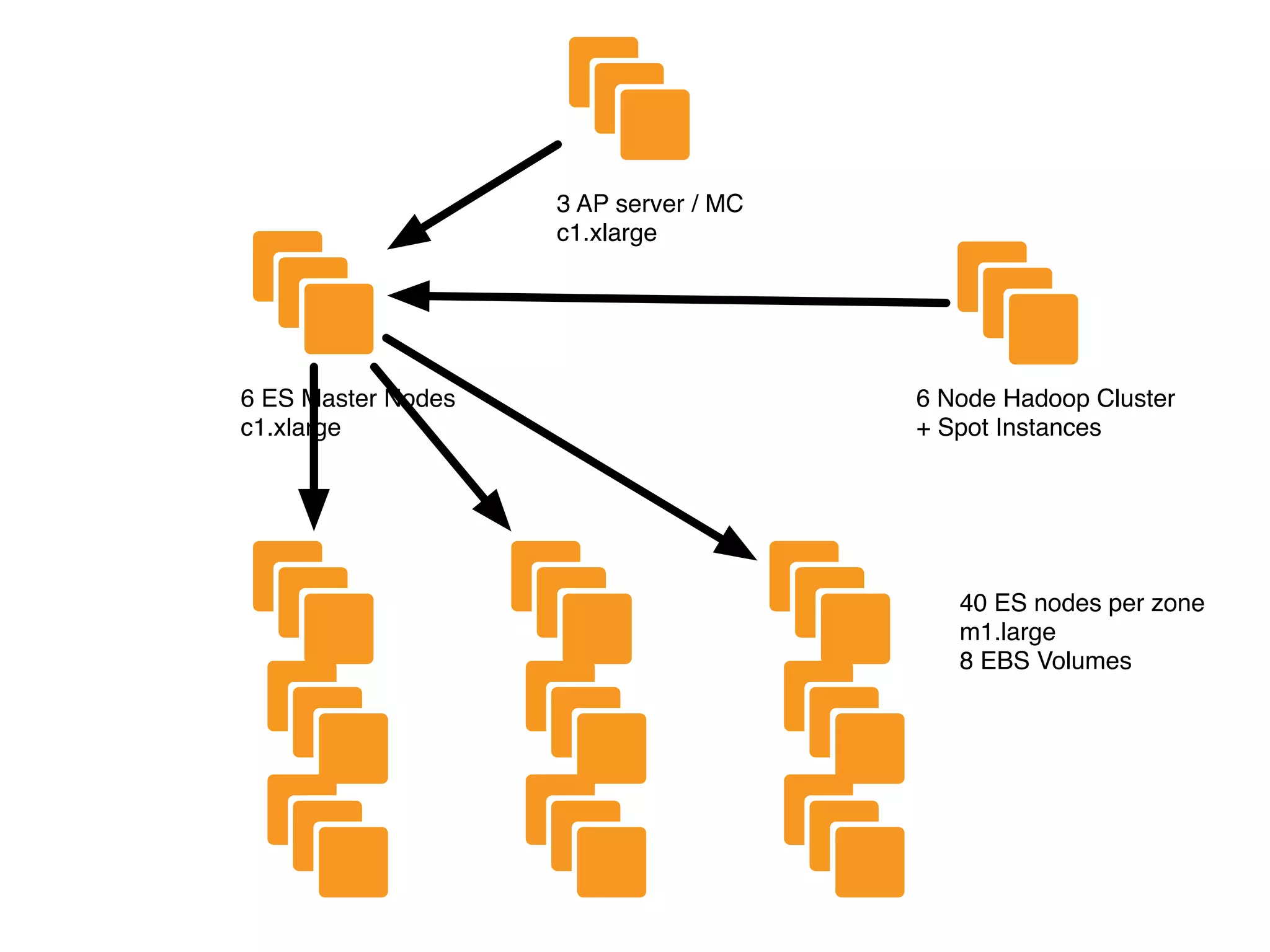
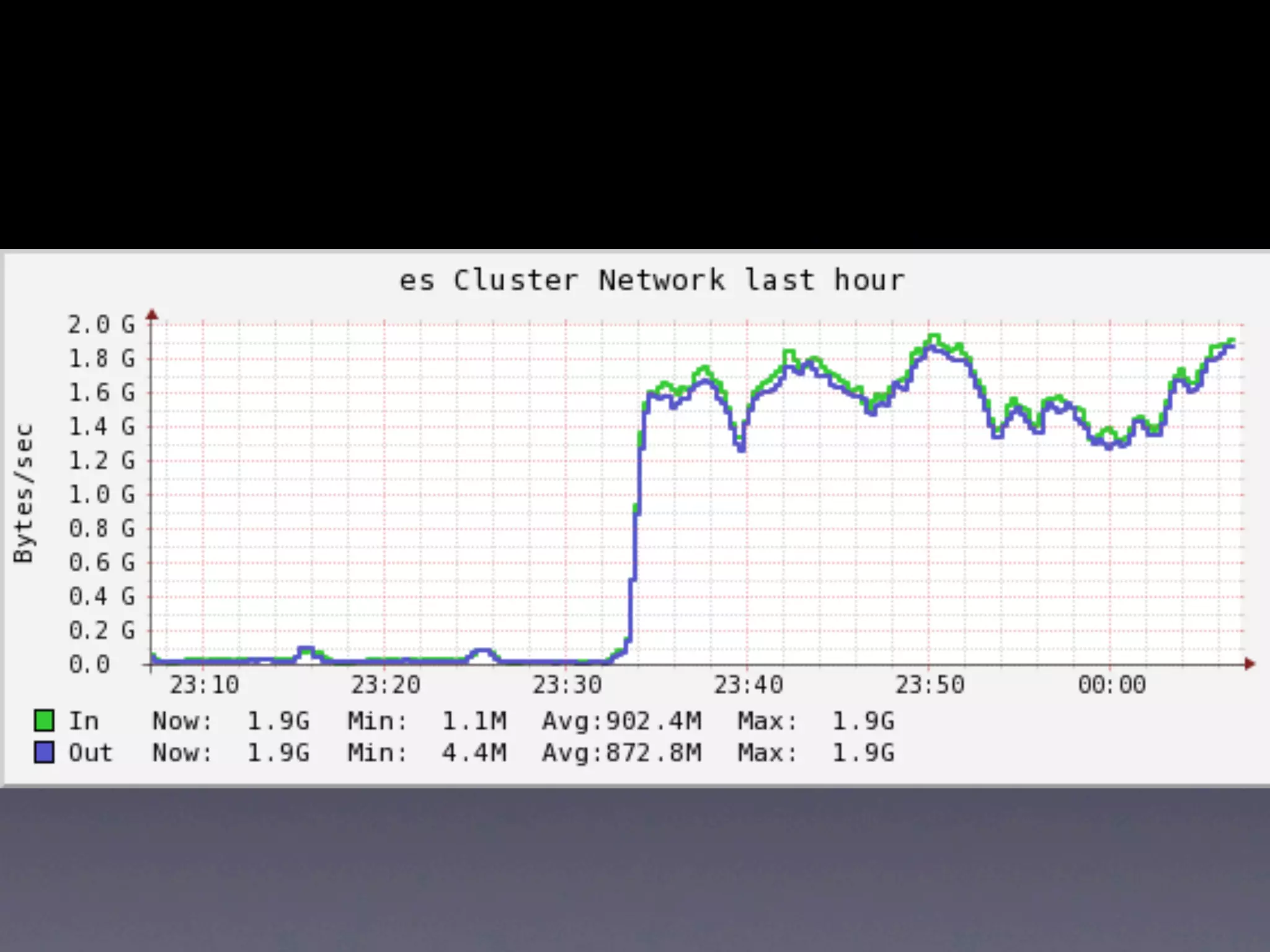
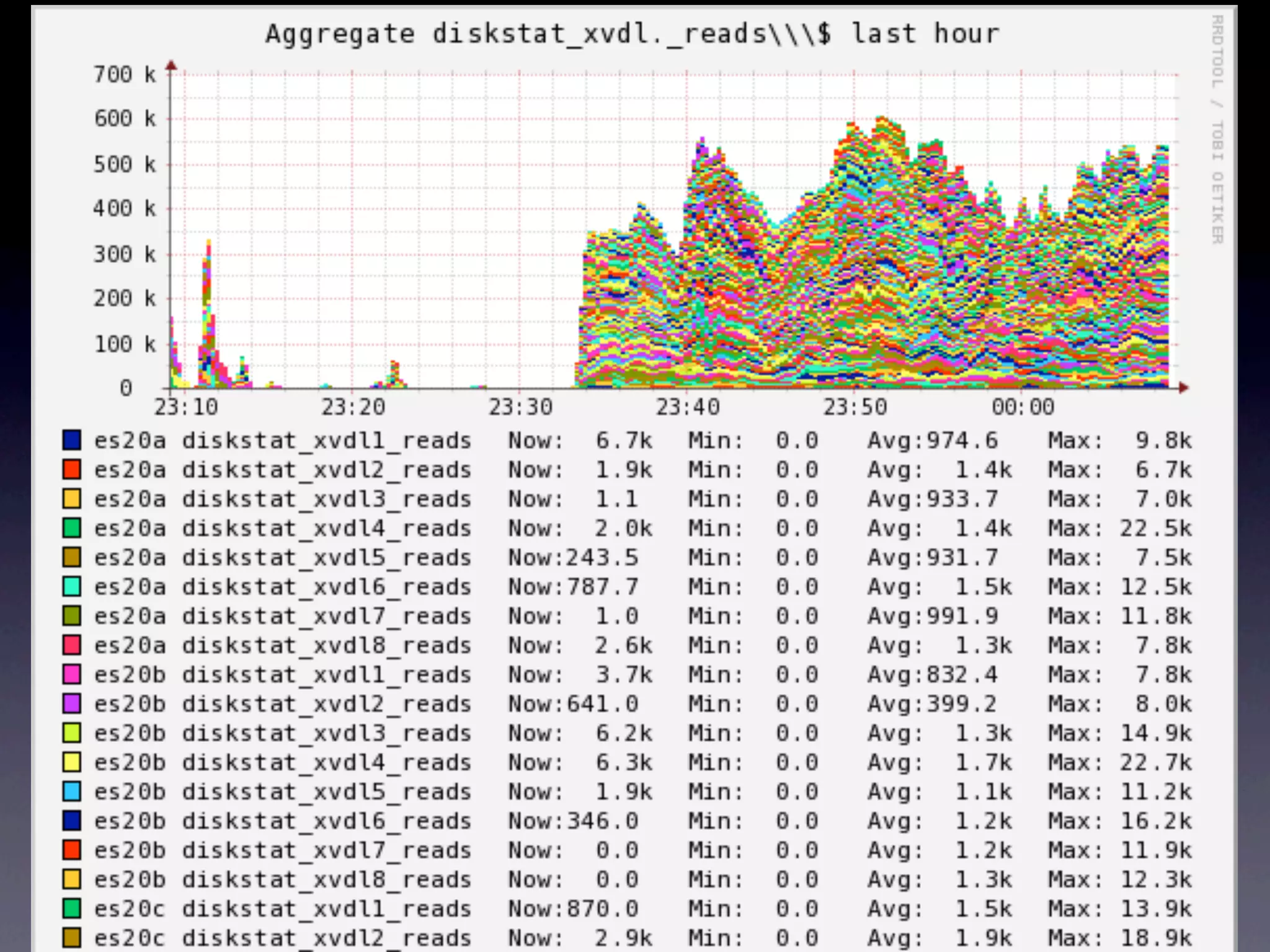
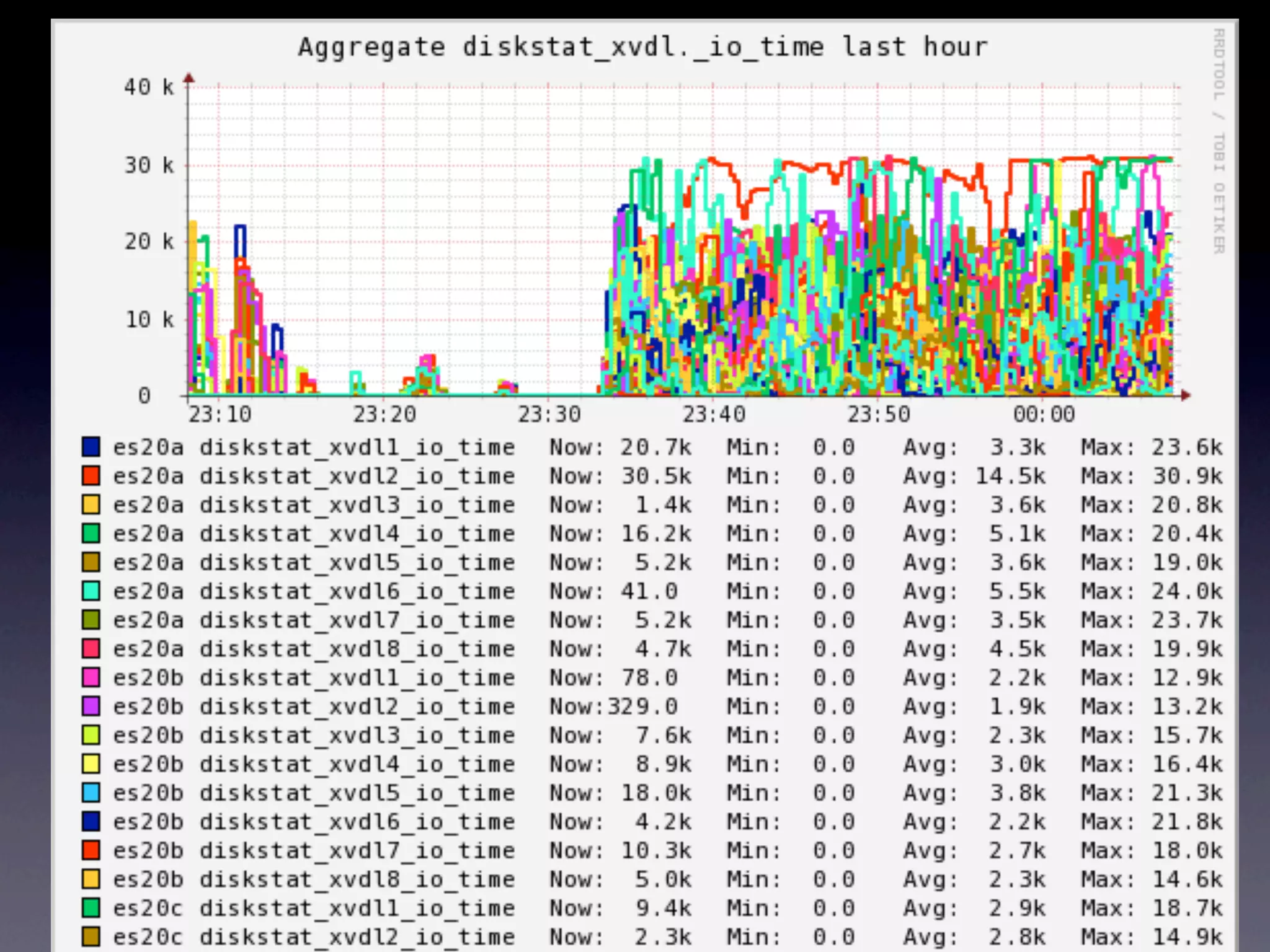
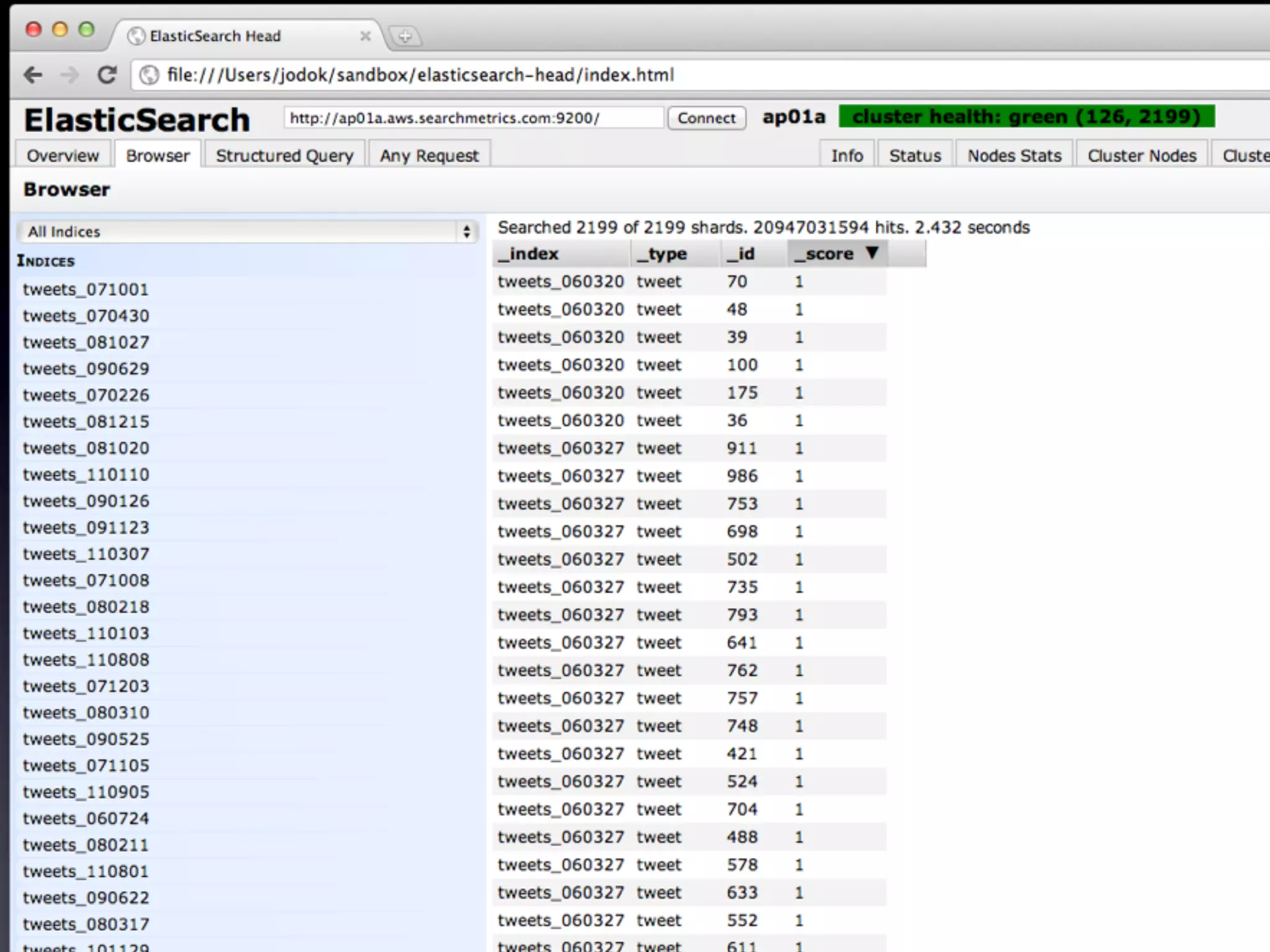



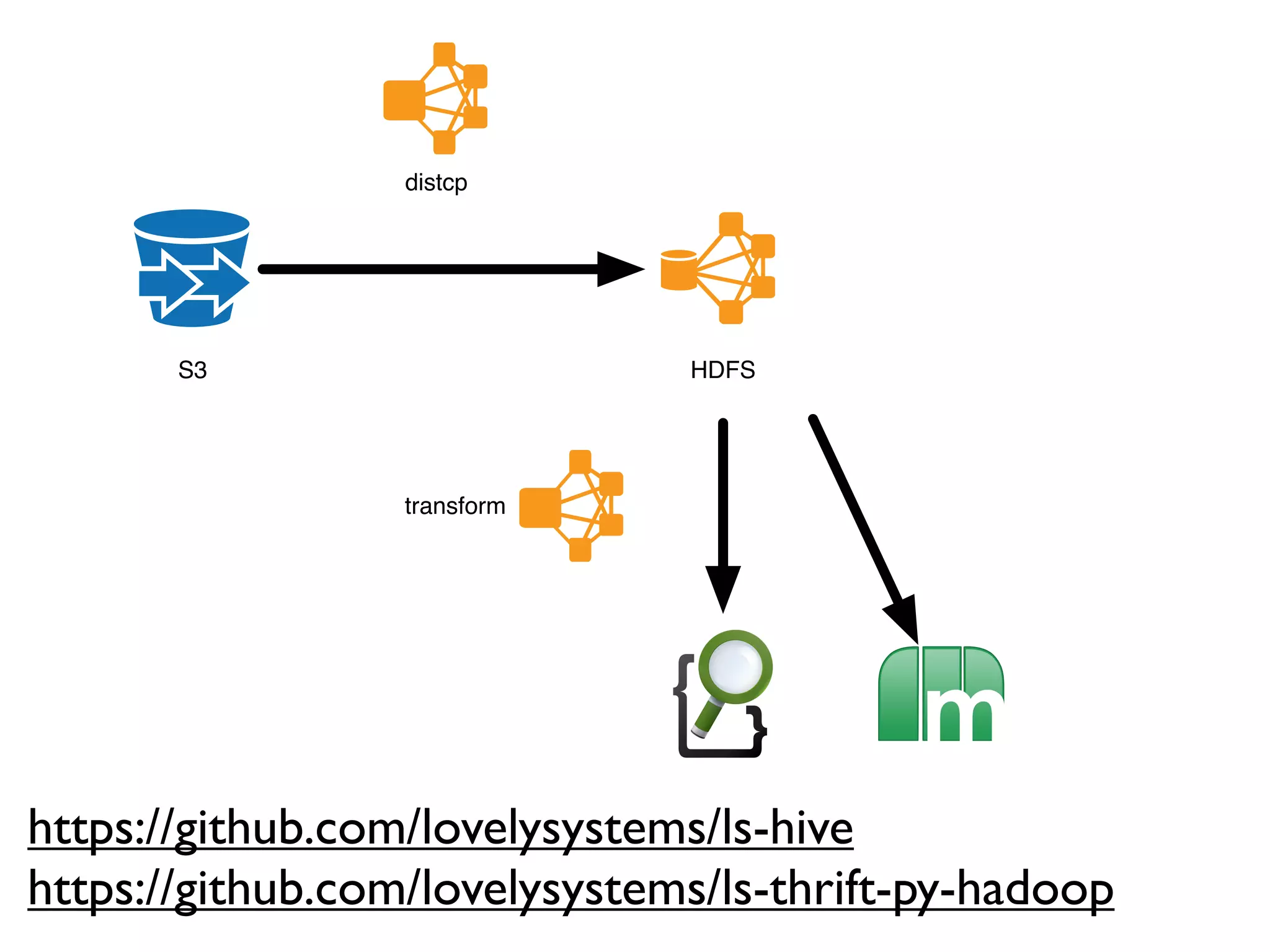
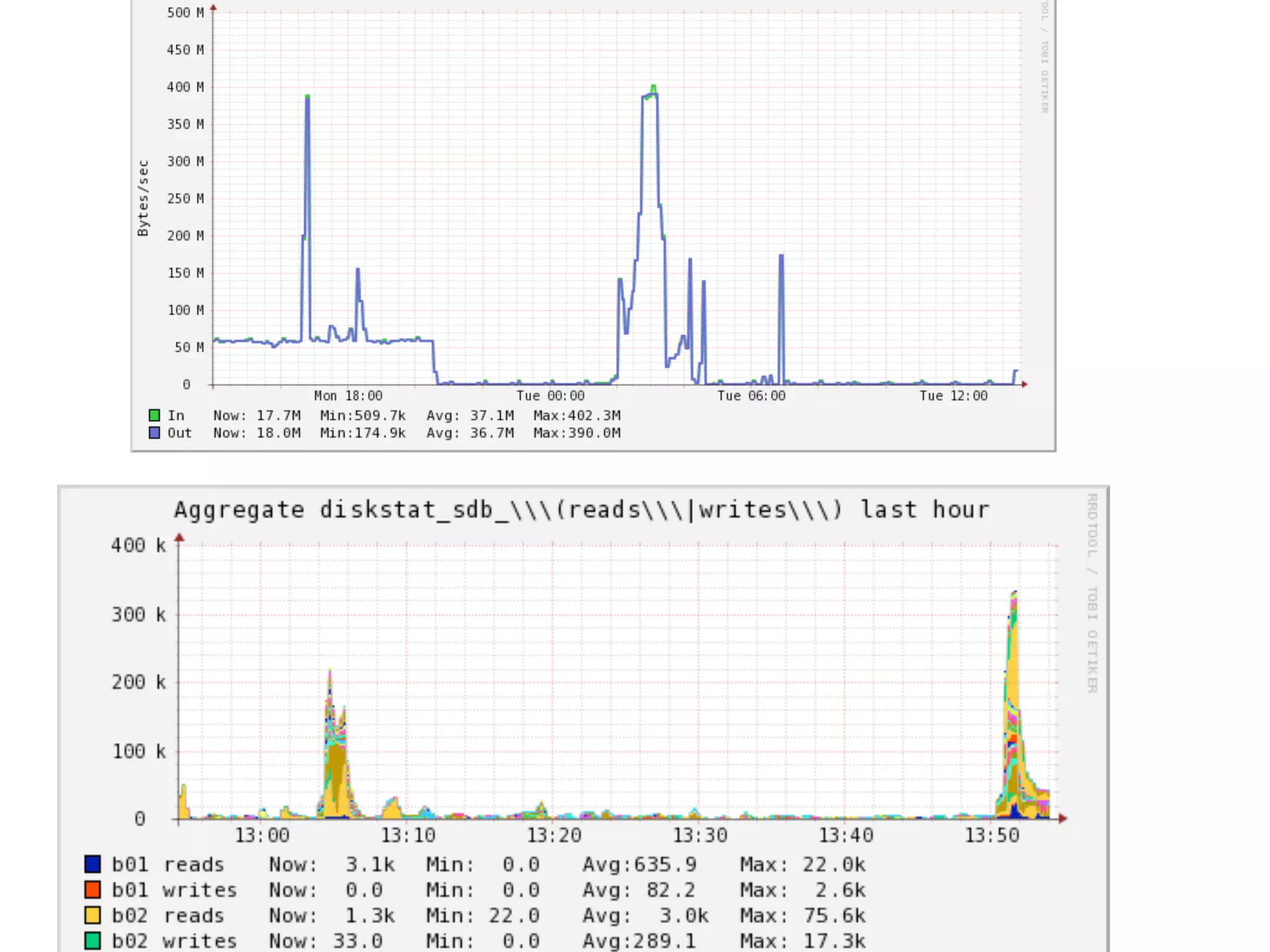
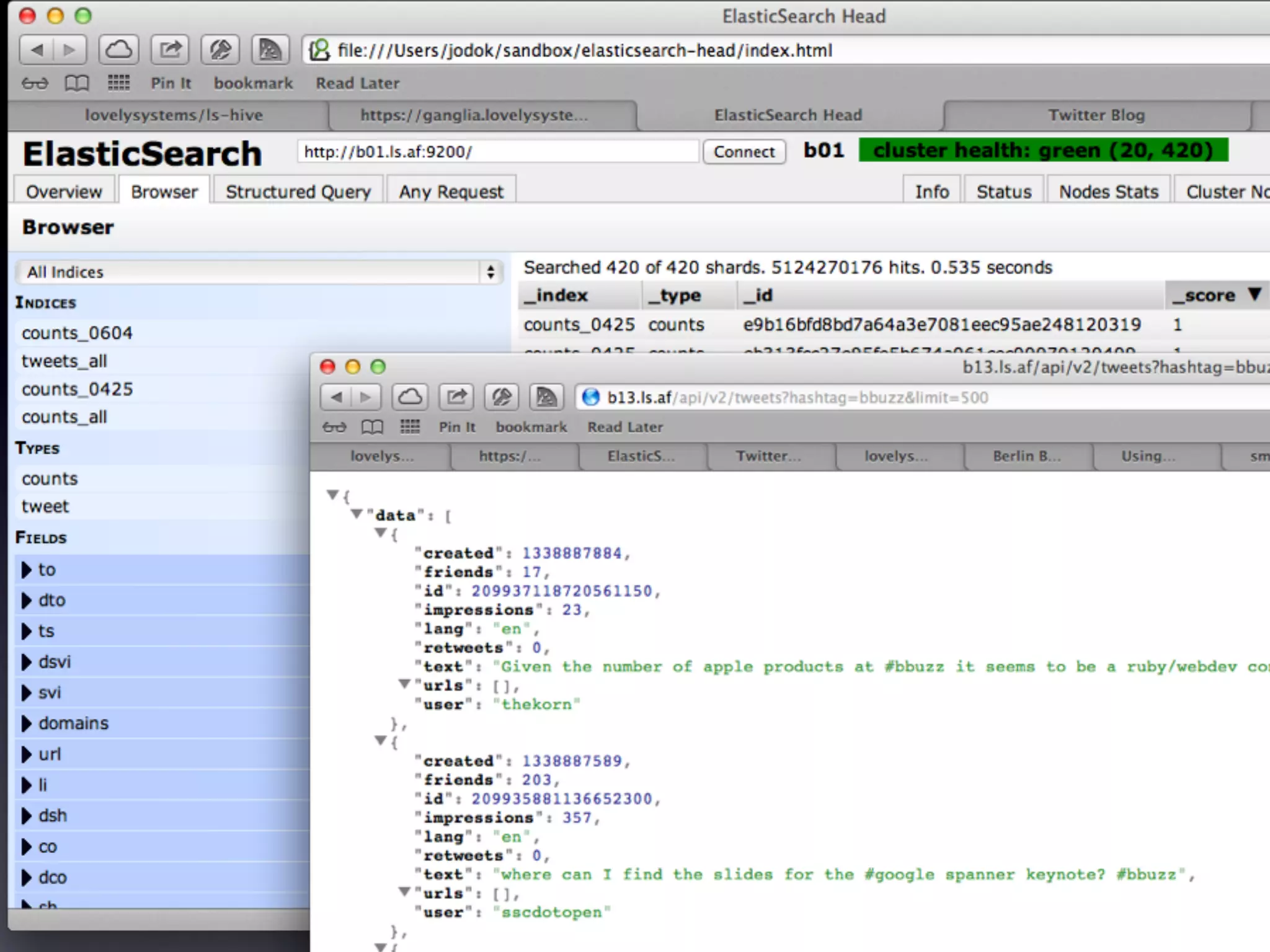


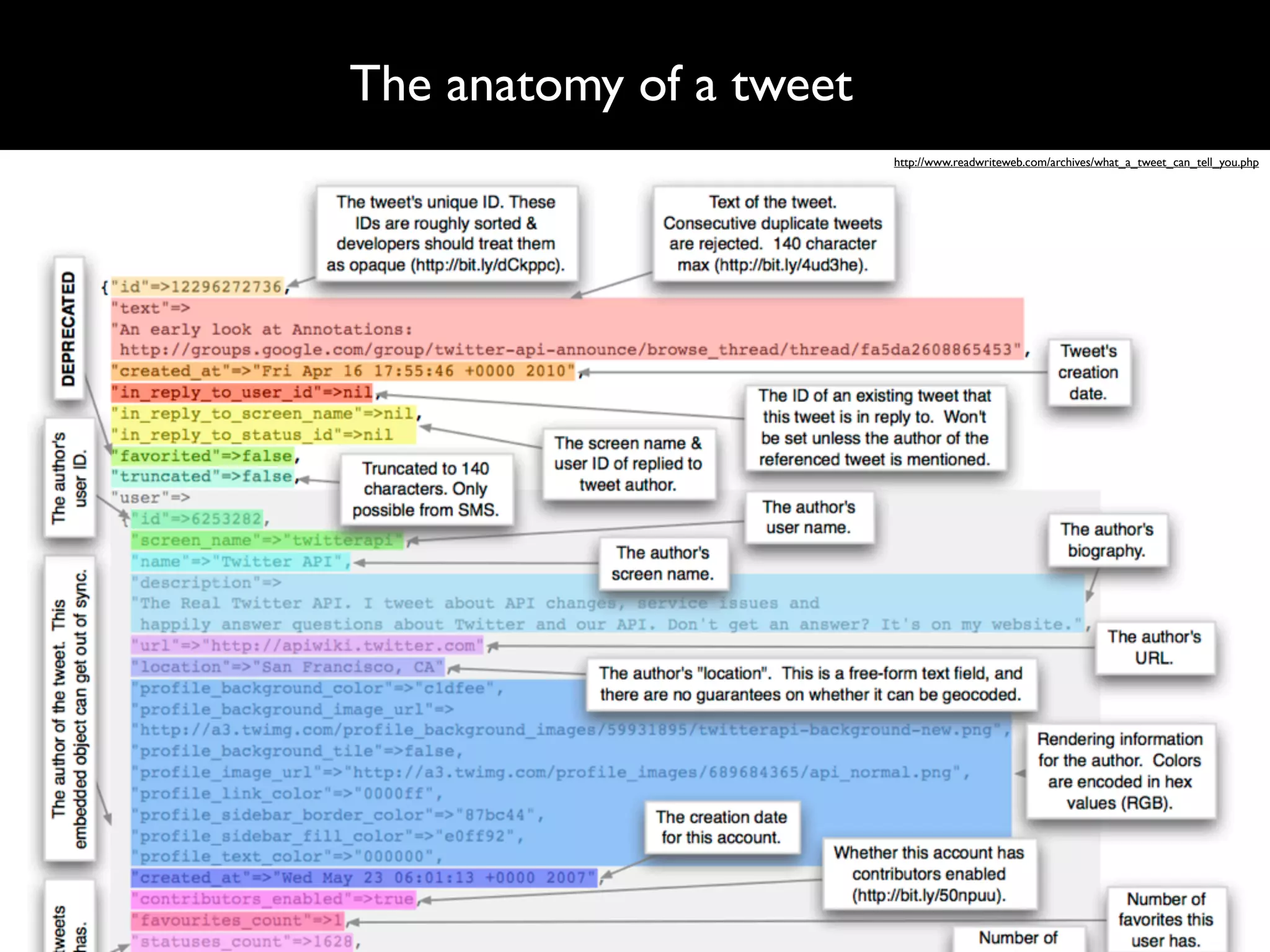
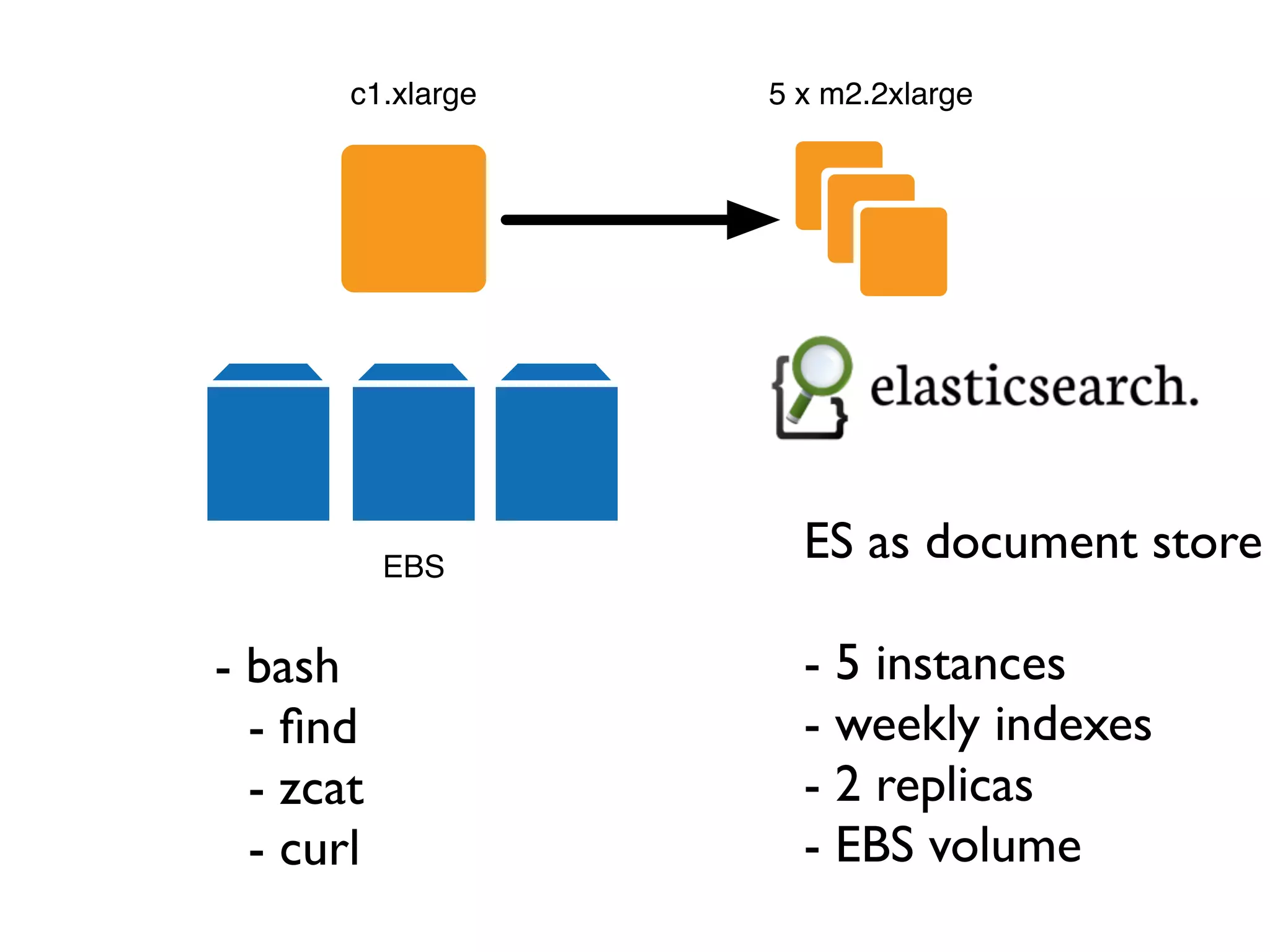
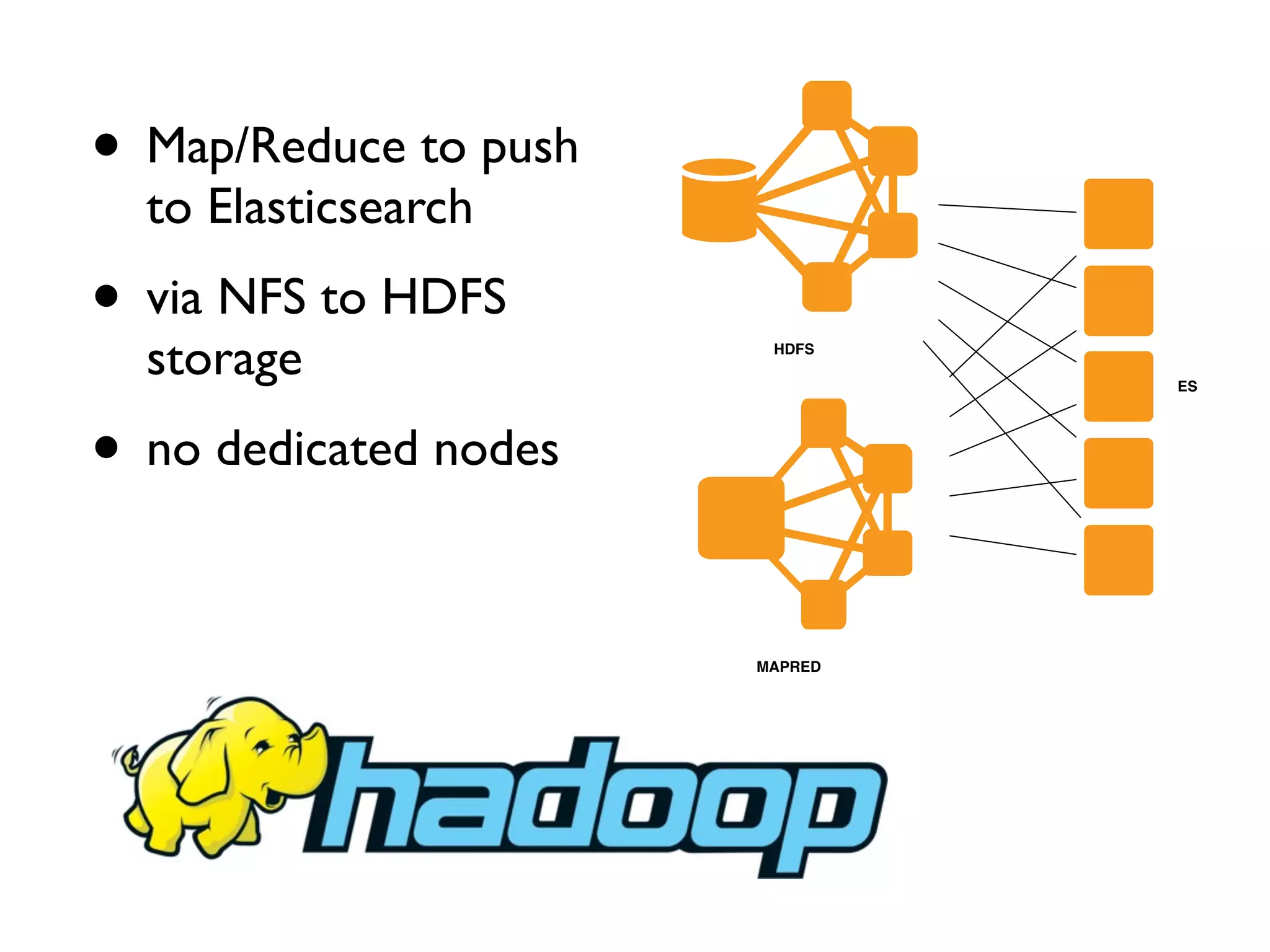
The document details a complex infrastructure for handling large-scale search querying across billions of records using technologies like Hadoop, Elasticsearch, and Apache Hive. It discusses the setup of nodes, data storage strategies, and various commands to manage the system, including the use of spot instances and optimizing costs through hardware sharing and data reduction strategies. Additionally, it outlines configurations for server setup including package management and SSH key handling.














































![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































