Download as PDF, PPTX





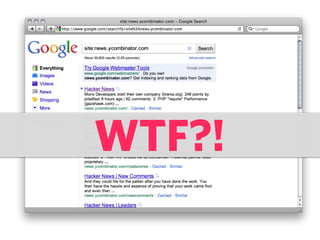

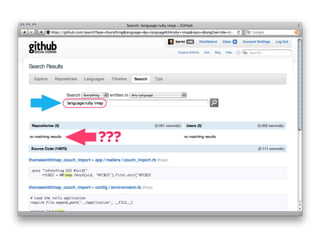


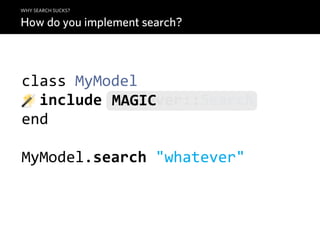
![WHY SEARCH SUCKS?
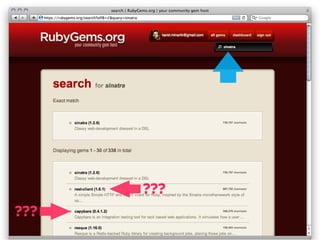
How do you implement search?
Query Results Result
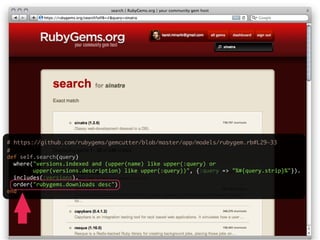
def search
@results = MyModel.search params[:q]
respond_with @results
end](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-19-320.jpg)
![WHY SEARCH SUCKS?
How do you implement search?
Query Results Result
MAGIC
def search
@results = MyModel.search params[:q]
respond_with @results
end](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-20-320.jpg)
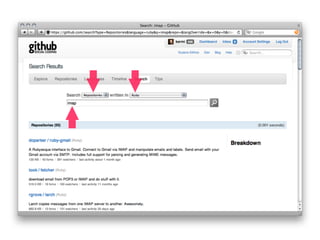
![WHY SEARCH SUCKS?
How do you implement search?
Query Results Result
MAGIC +
def search
@results = MyModel.search params[:q]
respond_with @results
end](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-21-320.jpg)
![WHY SEARCH SUCKS?
Compare your search library with your ORM library
MyModel.search "(this OR that) AND NOT whatever"
Arel::Table.new(:articles).
where(articles[:title].eq('On Search')).
where(["published_on => ?", Time.now]).
join(comments).
on(article[:id].eq(comments[:article_id]))
take(5).
skip(4).
to_sql](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-23-320.jpg)


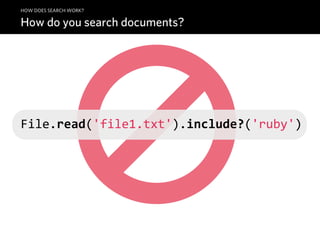



![module SimpleSearch
def index document, content
tokens = analyze content
store document, tokens
puts "Indexed document #{document} with tokens:", tokens.inspect, "n"
end
def analyze content
# >>> Split content by words into "tokens"
content.split(/W/).
# >>> Downcase every word
map { |word| word.downcase }.
# >>> Reject stop words, digits and whitespace
reject { |word| STOPWORDS.include?(word) || word =~ /^d+/ || word == '' }
end
def store document_id, tokens
tokens.each do |token|
# >>> Save the "posting"
( (INDEX[token] ||= []) << document_id ).uniq!
end
end
def search token
puts "Results for token '#{token}':"
# >>> Print documents stored in index for this token
INDEX[token].each { |document| " * #{document}" }
end
INDEX = {}
STOPWORDS = %w|a an and are as at but by for if in is it no not of on or that the then there t
extend self
end
A naïve Ruby implementation](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-30-320.jpg)
![HOW DOES SEARCH WORK?
Indexing documents
SimpleSearch.index "file1", "Ruby is a language. Java is also a language.
SimpleSearch.index "file2", "Ruby is a song."
SimpleSearch.index "file3", "Ruby is a stone."
SimpleSearch.index "file4", "Java is a language."
Indexed document file1 with tokens:
["ruby", "language", "java", "also", "language"]
Indexed document file2 with tokens:
["ruby", "song"] Words downcased,
stopwords removed.
Indexed document file3 with tokens:
["ruby", "stone"]
Indexed document file4 with tokens:
["java", "language"]](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-31-320.jpg)
![HOW DOES SEARCH WORK?
The index
puts "What's in our index?"
p SimpleSearch::INDEX
{
"ruby" => ["file1", "file2", "file3"],
"language" => ["file1", "file4"],
"java" => ["file1", "file4"],
"also" => ["file1"],
"stone" => ["file3"],
"song" => ["file2"]
}](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-32-320.jpg)

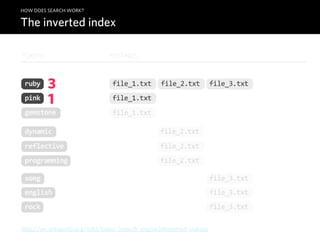

![module SimpleSearch
def index document, content
tokens = analyze content
store document, tokens
puts "Indexed document #{document} with tokens:", tokens.inspect, "n"
end
def analyze content
# >>> Split content by words into "tokens"
content.split(/W/).
# >>> Downcase every word
map { |word| word.downcase }.
# >>> Reject stop words, digits and whitespace
reject { |word| STOPWORDS.include?(word) || word =~ /^d+/ || word == '' }
end
def store document_id, tokens
tokens.each do |token|
# >>> Save the "posting"
( (INDEX[token] ||= []) << document_id ).uniq!
end
end
def search token
puts "Results for token '#{token}':"
# >>> Print documents stored in index for this token
INDEX[token].each { |document| " * #{document}" }
end
INDEX = {}
STOPWORDS = %w|a an and are as at but by for if in is it no not of on or that the then there t
extend self
end
A naïve Ruby implementation](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-36-320.jpg)




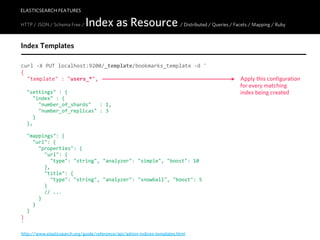
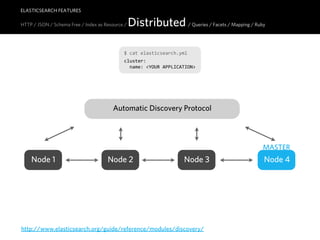
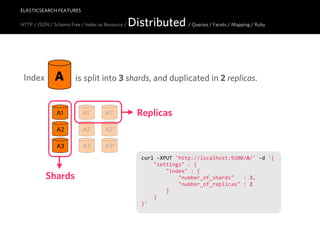
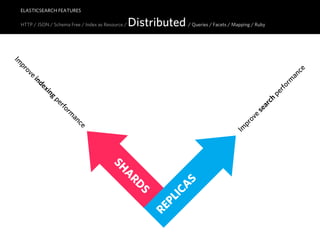
![ELASTICSEARCH FEATURES
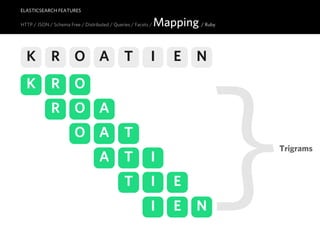
HTTP JSON / Schema-free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
# Add document
curl -‐X POST "http://localhost:9200/articles/article/1" -‐d '{ "title" : "One" }'
# Query
curl -‐X GET "http://localhost:9200/articles/_search?q=One"
curl -‐X POST "http://localhost:9200/articles/_search" -‐d '{
INDEX TYPE ID
"query" : { "terms" : { "tags" : ["ruby", "python"], "minimum_match" : 2 } }
}'
# Delete index
curl -‐X DELETE "http://localhost:9200/articles"
# Create index with settings and mapping
curl -‐X PUT "http://localhost:9200/articles" -‐d '
{ "settings" : { "index" : "number_of_shards" : 3, "number_of_replicas" : 2 }},
{ "mappings" : { "document" : {
"properties" : {
"body" : { "type" : "string", "analyzer" : "snowball" }
}
} }
}'](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-41-320.jpg)
![ELASTICSEARCH FEATURES
HTTP JSON / Schema-free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
# Add document
curl -‐X POST "http://localhost:9200/articles/article/1" -‐d '{ "title" : "One" }'
# Query
curl -‐X GET "http://localhost:9200/articles/_search?q=One"
curl -‐X POST "http://localhost:9200/articles/_search" -‐d '{
"query" : { "terms" : { "tags" : ["ruby", "python"], "minimum_match" : 2 } }
}'
# Delete index
curl -‐X DELETE "http://localhost:9200/articles"
# Create index with settings and mapping
curl -‐X PUT "http://localhost:9200/articles" -‐d '
{ "settings" : { "index" : "number_of_shards" : 3, "number_of_replicas" : 2 }},
{ "mappings" : { "document" : {
"properties" : {
"body" : { "type" : "string", "analyzer" : "snowball" }
}
} }
}'](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-42-320.jpg)
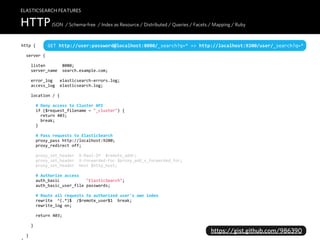
![ELASTICSEARCH FEATURES
JSON / Schema-free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
ON
HTTP /
JS
{
"id" : "abc123",
"title" : "ElasticSearch Understands JSON!",
"body" : "ElasticSearch not only “works” with JSON, it understands it! Let’s first .
"published_on" : "2011/05/27 10:00:00",
"tags" : ["search", "json"],
"author" : {
"first_name" : "Clara",
"last_name" : "Rice",
"email" : "clara@rice.org"
}
}](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-44-320.jpg)
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema-free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
curl -‐X DELETE "http://localhost:9200/articles"; sleep 1
curl -‐X POST "http://localhost:9200/articles/article" -‐d '
{
"id" : "abc123",
"title" : "ElasticSearch Understands JSON!",
"body" : "ElasticSearch not only “works” with JSON, it understands it! Let’s first .
"published_on" : "2011/05/27 10:00:00",
"tags" : ["search", "json"],
"author" : {
"first_name" : "Clara",
"last_name" : "Rice",
"email" : "clara@rice.org"
}
}'
curl -‐X POST "http://localhost:9200/articles/_refresh"
curl -‐X GET
"http://localhost:9200/articles/article/_search?q=author.first_name:clara"](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-45-320.jpg)



![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
curl -‐X DELETE "http://localhost:9200/articles"; sleep 1
curl -‐X POST "http://localhost:9200/articles/article" -‐d '
{
"id" : "abc123",
"title" : "ElasticSearch Understands JSON!",
"body" : "ElasticSearch not only “works” with JSON, it understands it! Let’s first ...",
"published_on" : "2011/05/27 10:00:00",
"tags" : ["search", "json"],
"author" : {
"first_name" : "Clara",
"last_name" : "Rice",
"email" : "clara@rice.org"
}
}'
curl -‐X POST "http://localhost:9200/articles/_refresh"
curl -‐X GET "http://localhost:9200/articles/article/1"](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-49-320.jpg)
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
{"_index":"articles","_type":"article","_id":"1","_version":1, "_source" :
{
"id" : "1",
"title" : "ElasticSearch Understands JSON!",
"body" : "ElasticSearch not only “works” with JSON, it understands it! Let’s
"published_on" : "2011/05/27 10:00:00",
"tags" : ["search", "json"],
"author" : {
"first_name" : "Clara",
"last_name" : "Rice",
"email" : "clara@rice.org"
}
}}
The Index Is Your Database.](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-50-320.jpg)
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Index as Resource / Distributed / Queries / Facets / Mapping / Ruby
Index Aliases
curl -‐X POST 'http://localhost:9200/_aliases' -‐d '
{
"actions" : [
{ "add" : {
index_A "index" : "index_1",
"alias" : "myalias"
my_alias }
},
{ "add" : {
"index" : "index_2",
"alias" : "myalias"
index_B }
}
]
}'
http://www.elasticsearch.org/guide/reference/api/admin-indices-aliases.html](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-51-320.jpg)
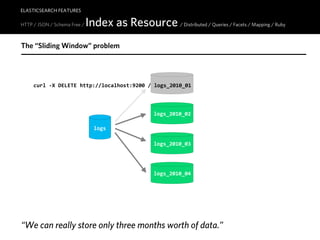
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
$ curl -‐X GET "http://localhost:9200/_search?q=<YOUR QUERY>"
apple
Terms
apple iphone
Phrases "apple iphone"
Proximity "apple safari"~5
Fuzzy apple~0.8
app*
Wildcards
*pp*
Boosting apple^10 safari
[2011/05/01 TO 2011/05/31]
Range
[java TO json]
apple AND NOT iphone
+apple -‐iphone
Boolean
(apple OR iphone) AND NOT review
title:iphone^15 OR body:iphone
Fields published_on:[2011/05/01 TO "2011/05/27 10:00:00"]
http://lucene.apache.org/java/3_1_0/queryparsersyntax.html](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-57-320.jpg)
![ELASTICSEARCH FEATURES
Queries / Facets / Mapping / Ruby
ON
HTTP / JSON / Schema Free / Distributed /
JS
Query DSL
curl -‐X POST "http://localhost:9200/articles/_search?pretty=true" -‐d '
{
"query" : {
"terms" : {
"tags" : [ "ruby", "python" ],
"minimum_match" : 2
}
}
}'
http://www.elasticsearch.org/guide/reference/query-dsl/](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-58-320.jpg)
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
Geo Search
curl -‐X POST "http://localhost:9200/venues/venue" -‐d '
{ Accepted formats for Geo:
"name": "Pizzeria",
"pin": { [lon, lat] # Array
"location": {
"lat": 50.071712,
"lat,lon" # String
"lon": 14.386832 drm3btev3e86 # Geohash
}
}
}'
curl -‐X POST "http://localhost:9200/venues/_search?pretty=true" -‐d '
{
"query" : {
"filtered" : {
"query" : { "query_string" : { "query" : "pizzeria" } },
"filter" : {
"geo_distance" : {
"distance" : "0.5km",
"pin.location" : { "lat" : 50.071481, "lon" : 14.387284 }
}
}
}
}
}'
http://www.elasticsearch.org/guide/reference/query-dsl/geo-distance-filter.html](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-59-320.jpg)
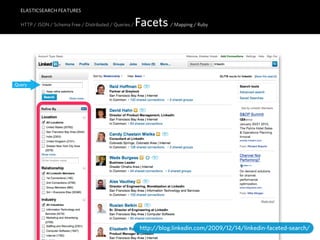
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
curl -‐X POST "http://localhost:9200/articles/_search?pretty=true" -‐d '
{
"query" : {
"query_string" : { "query" : "title:T*"} User query
},
"filter" : {
"terms" : { "tags" : ["ruby"] } “Checkboxes”
},
"facets" : {
"tags" : {
"terms" : { Facets
"field" : "tags",
"size" : 10
}
}
}
}'
# facets" : {
# "tags" : {
# "terms" : [ {
# "term" : "ruby",
# "count" : 2
# }, {
# "term" : "python",
# "count" : 1
# }, {
# "term" : "java",
# "count" : 1
# } ]
# }
# }
http://www.elasticsearch.org/guide/reference/api/search/facets/index.html](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-61-320.jpg)
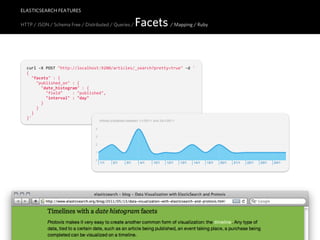
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
Geo Distance Facets
curl -‐X POST "http://localhost:9200/venues/_search?pretty=true" -‐d '
{
"query" : { "query_string" : { "query" : "pizzeria" } },
"facets" : {
"distance_count" : {
"geo_distance" : {
"pin.location" : {
"lat" : 50.071712,
"lon" : 14.386832
},
"ranges" : [
{ "to" : 1 },
{ "from" : 1, "to" : 5 },
{ "from" : 5, "to" : 10 }
]
}
}
}
}'
http://www.elasticsearch.org/guide/reference/api/search/facets/geo-distance-facet.html](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-63-320.jpg)
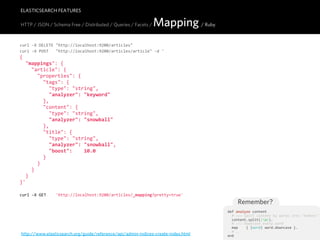
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
curl -‐X DELETE "http://localhost:9200/urls"
curl -‐X POST "http://localhost:9200/urls/url" -‐d '
{
"settings" : {
"index" : {
"analysis" : {
"analyzer" : {
"url_analyzer" : {
"type" : "custom",
"tokenizer" : "lowercase",
"filter" : ["stop", "url_stop", "url_ngram"]
}
},
"filter" : {
"url_stop" : {
"type" : "stop",
"stopwords" : ["http", "https", "www"]
},
"url_ngram" : {
"type" : "nGram",
"min_gram" : 3,
"max_gram" : 5
}
}
}
}
}
}'
https://gist.github.com/988923](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-65-320.jpg)
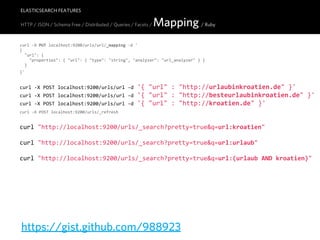
![ELASTICSEARCH FEATURES
HTTP / JSON / Schema Free / Distributed / Queries / Facets / Mapping / Ruby
Tire.index 'articles' do
delete
create
store :title => 'One', :tags => ['ruby'], :published_on => '2011-‐01-‐01'
store :title => 'Two', :tags => ['ruby', 'python'], :published_on => '2011-‐01-‐02'
store :title => 'Three', :tags => ['java'], :published_on => '2011-‐01-‐02'
store :title => 'Four', :tags => ['ruby', 'php'], :published_on => '2011-‐01-‐03'
refresh
end
s = Tire.search 'articles' do
query { string 'title:T*' }
filter :terms, :tags => ['ruby']
sort { title 'desc' }
http://github.com/karmi/tire
facet 'global-‐tags' { terms :tags, :global => true }
facet 'current-‐tags' { terms :tags }
end](https://image.slidesharecdn.com/elasticsearch-karelminarik-euruko2011-110529082825-phpapp01/85/Your-Data-Your-Search-ElasticSearch-EURUKO-2011-68-320.jpg)


The document discusses search implementation and ElasticSearch. It begins with an overview of how search works by indexing documents into an inverted index of tokens and associated document postings. It then provides a Ruby implementation of a basic search index and demonstrates indexing documents and searching the index. The document concludes by describing features of ElasticSearch like its use of HTTP and JSON, schema-free indexing, distributed search capabilities, and Ruby integration.













































![Realtime Analytics With Elasticsearch [New Media Inspiration 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/realtimeanalyticselasticsearch-karelminarik-nmi2013-130119084635-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Vizualizace dat a D3.js [EUROPEN 2014]](https://cdn.slidesharecdn.com/ss_thumbnails/d3js-karelminarik-europen2014-141008052546-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


![Elasticsearch And Ruby [RuPy2012]](https://cdn.slidesharecdn.com/ss_thumbnails/elasticsearchandruby-karelminarik-rupy2012-121118065224-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![Představení Ruby on Rails [Junior Internet]](https://cdn.slidesharecdn.com/ss_thumbnails/juniorinternet-rubyonrails-karelminarik-090929105516-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























