

















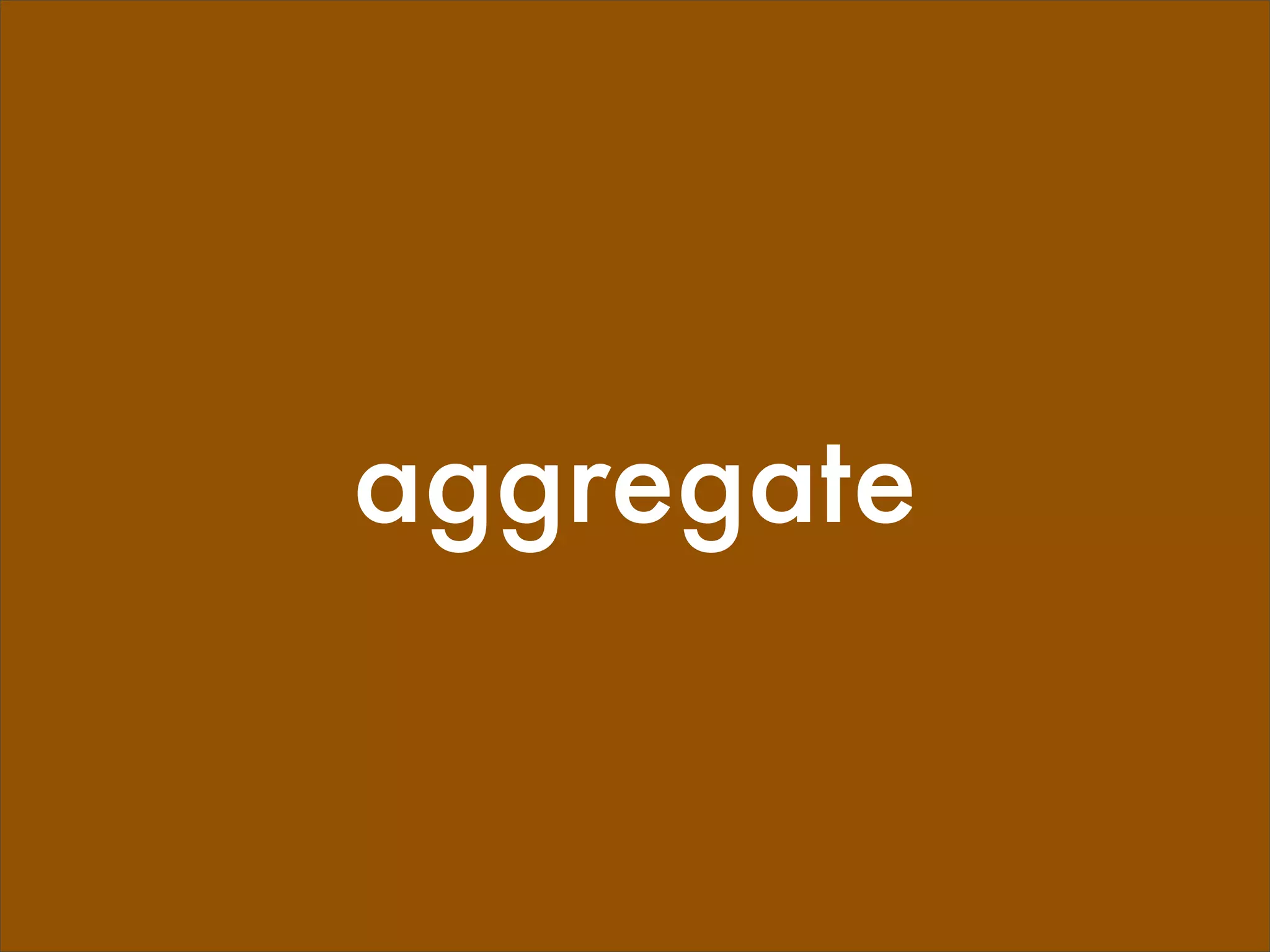






























![include_recipe "packages"
include_recipe "ruby"
include_recipe "apache2"
if platform?("centos","redhat")
if dist_only?
# just the gem, we'll install the apache module within apache2
package "rubygem-passenger"
return
else
package "httpd-devel"
end
else
%w{ apache2-prefork-dev libapr1-dev }.each do |pkg|
package pkg do
action :upgrade
end
end
end
gem_package "passenger" do
version node[:passenger][:version]
end
execute "passenger_module" do
command 'echo -en "nnnn" | passenger-install-apache2-module'
creates node[:passenger][:module_path]
end](https://image.slidesharecdn.com/systemsbioinformatics-110523225655-phpapp02/75/Systems-Bioinformatics-Workshop-Keynote-53-2048.jpg)
![import boto
import boto.emr
from boto.emr.step import StreamingStep
Connect to Elastic MapReduce
from boto.emr.bootstrap_action import BootstrapAction
import time
# set your aws keys and S3 bucket, e.g. from environment or .boto
AWSKEY=
SECRETKEY=
S3_BUCKET=
NUM_INSTANCES = 1
conn = boto.connect_emr(AWSKEY,SECRETKEY)
bootstrap_step = BootstrapAction("download.tst",
"s3://elasticmapreduce/bootstrap-actions/download.sh",None)
Install packages
step = StreamingStep(name='Wordcount',
mapper='s3n://elasticmapreduce/samples/wordcount/wordSplitter.py',
cache_files = ["s3n://" + S3_BUCKET + "/boto.mod#boto.mod"],
reducer='aggregate',
input='s3n://elasticmapreduce/samples/wordcount/input',
output='s3n://' + S3_BUCKET + '/output/wordcount_output')
Set up mappers &
jobid = conn.run_jobflow(
name="testbootstrap",
reduces
log_uri="s3://" + S3_BUCKET + "/logs",
steps = [step],
bootstrap_actions=[bootstrap_step],
num_instances=NUM_INSTANCES)
print "finished spawning job (note: starting still takes time)"
state = conn.describe_jobflow(jobid).state
print "job state = ", state
print "job id = ", jobid
while state != u'COMPLETED':
print time.localtime() job state
time.sleep(30)
state = conn.describe_jobflow(jobid).state
print "job state = ", state
print "job id = ", jobid
print "final output can be found in s3://" + S3_BUCKET + "/output" + TIMESTAMP
print "try: $ s3cmd sync s3://" + S3_BUCKET + "/output" + TIMESTAMP + " ."](https://image.slidesharecdn.com/systemsbioinformatics-110523225655-phpapp02/75/Systems-Bioinformatics-Workshop-Keynote-54-2048.jpg)






















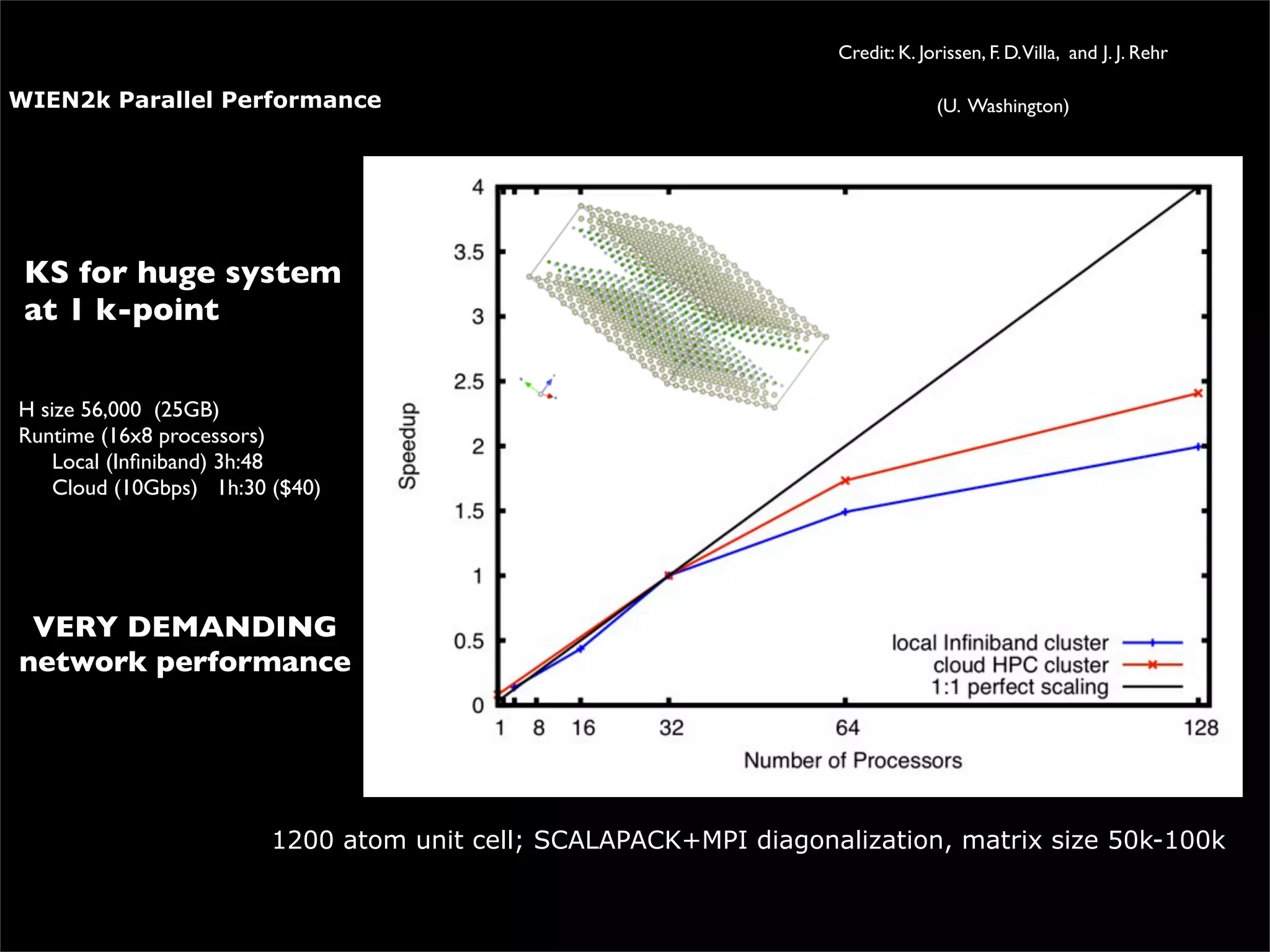

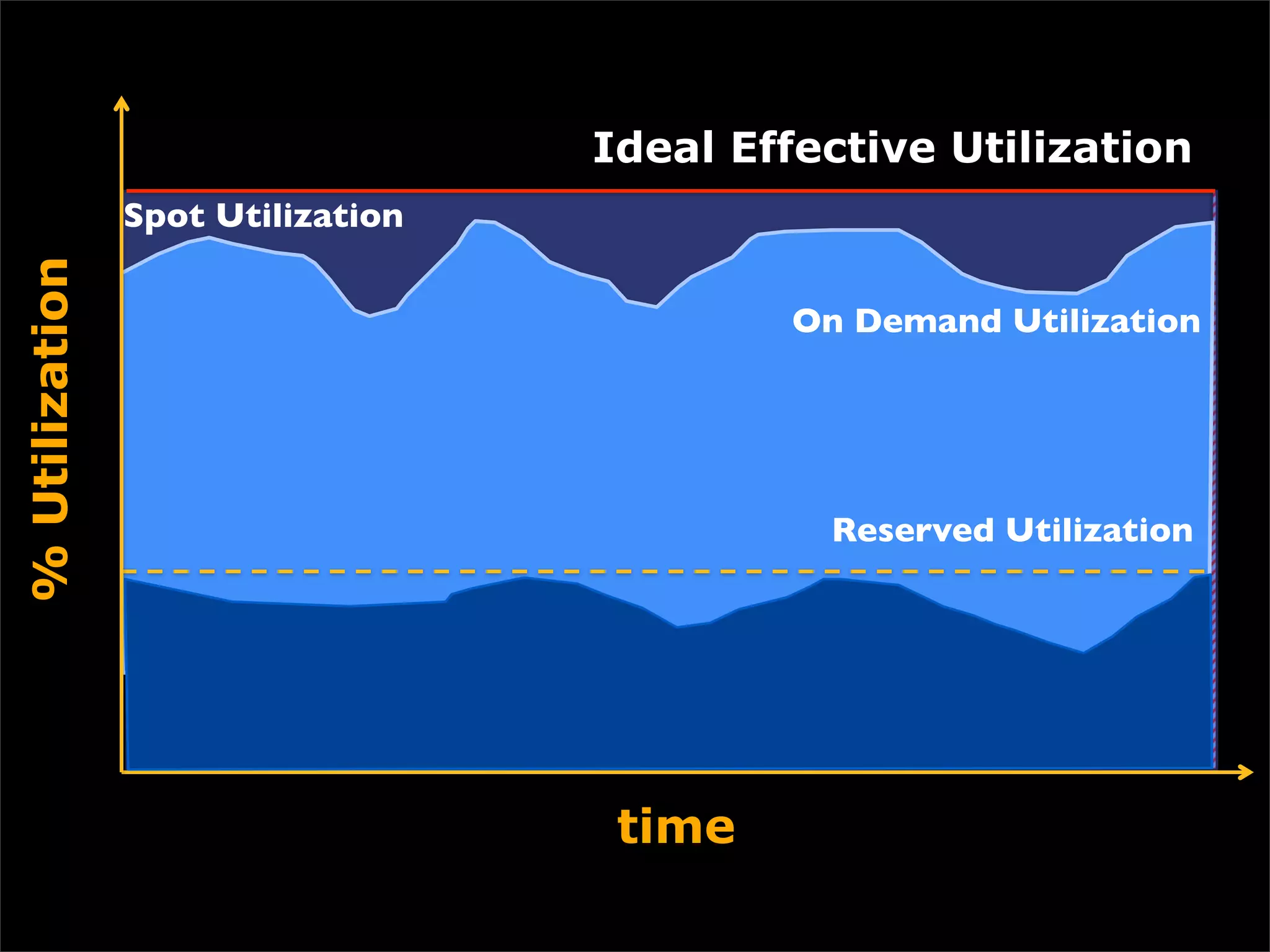

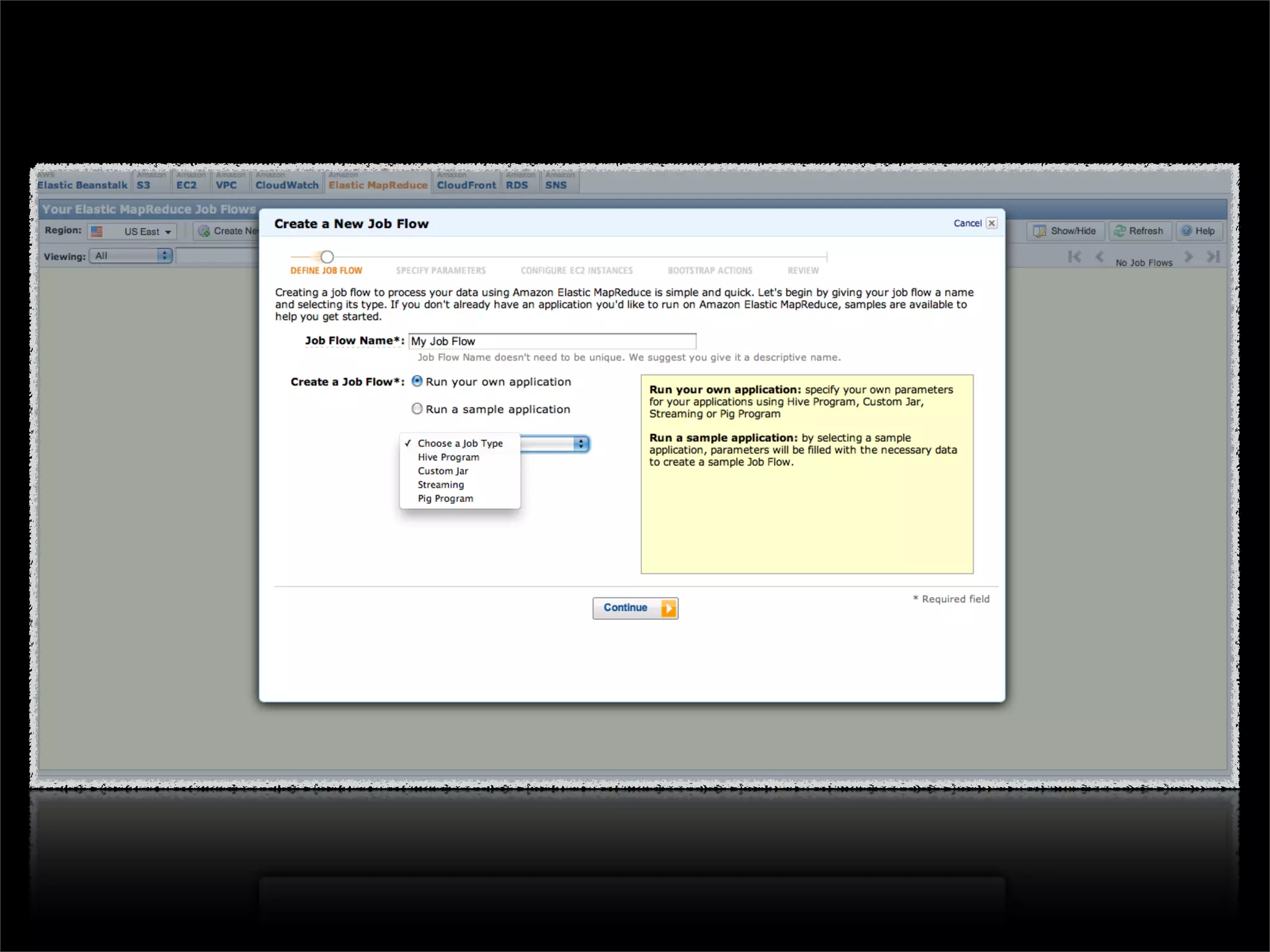

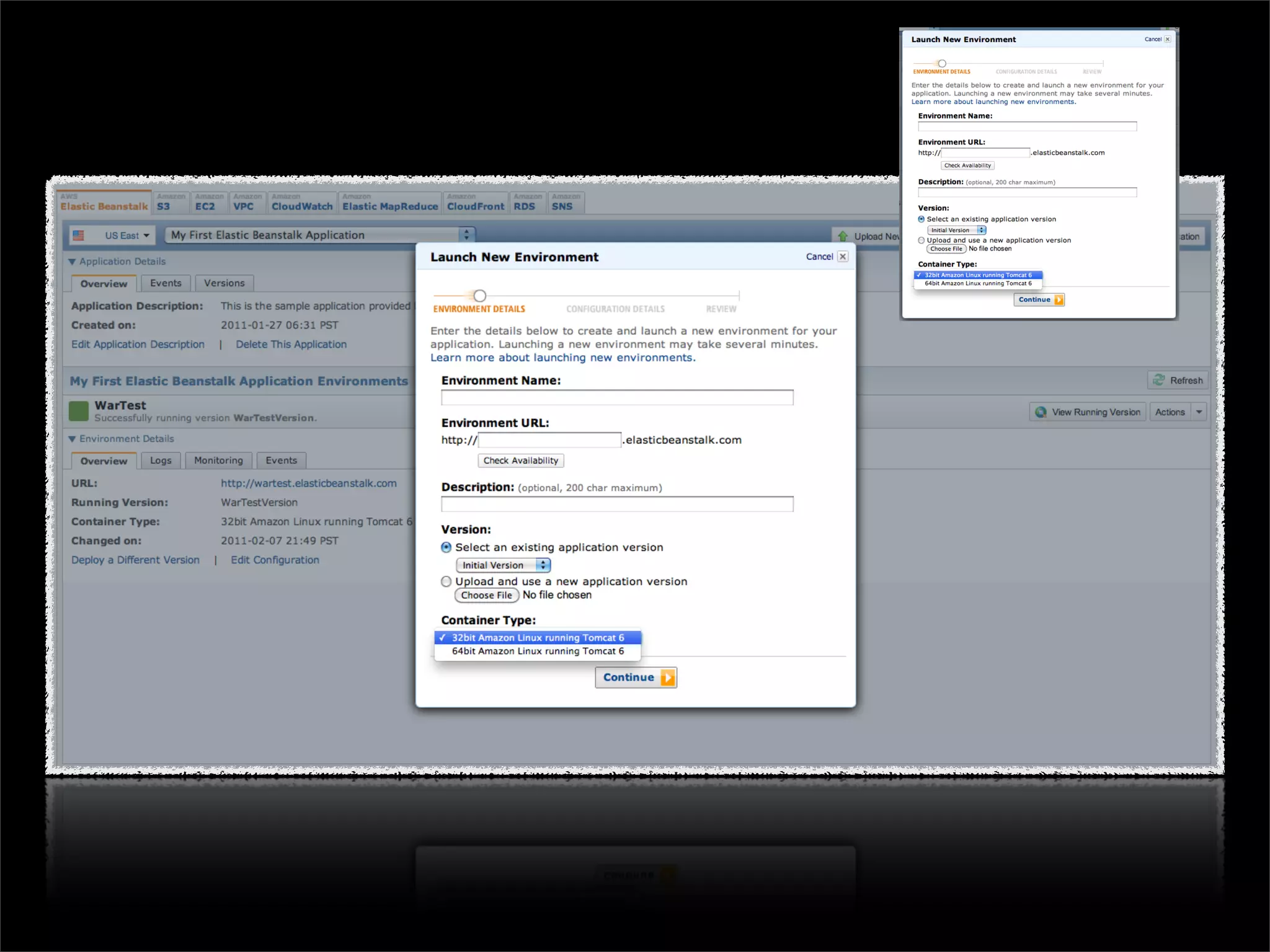
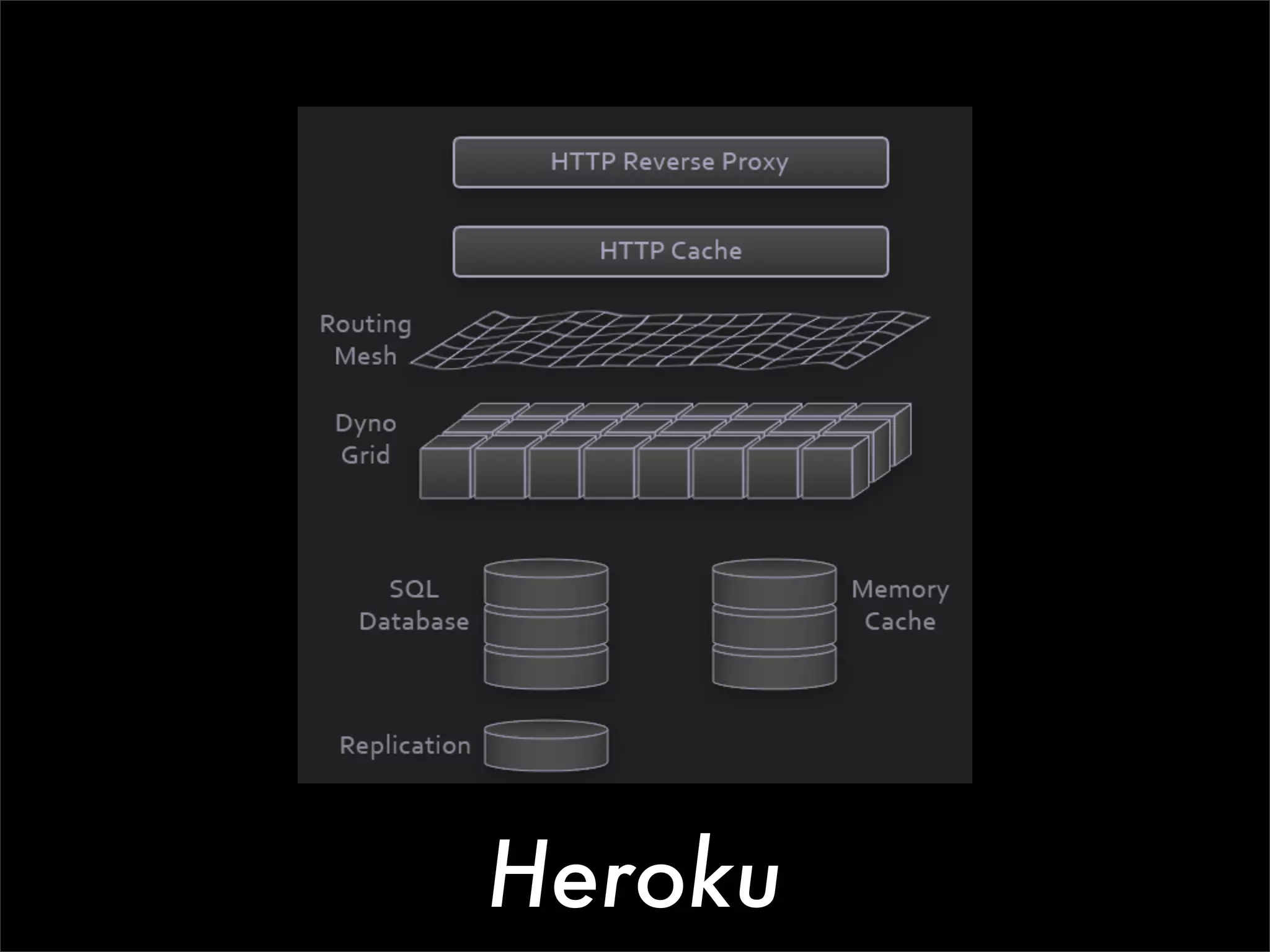
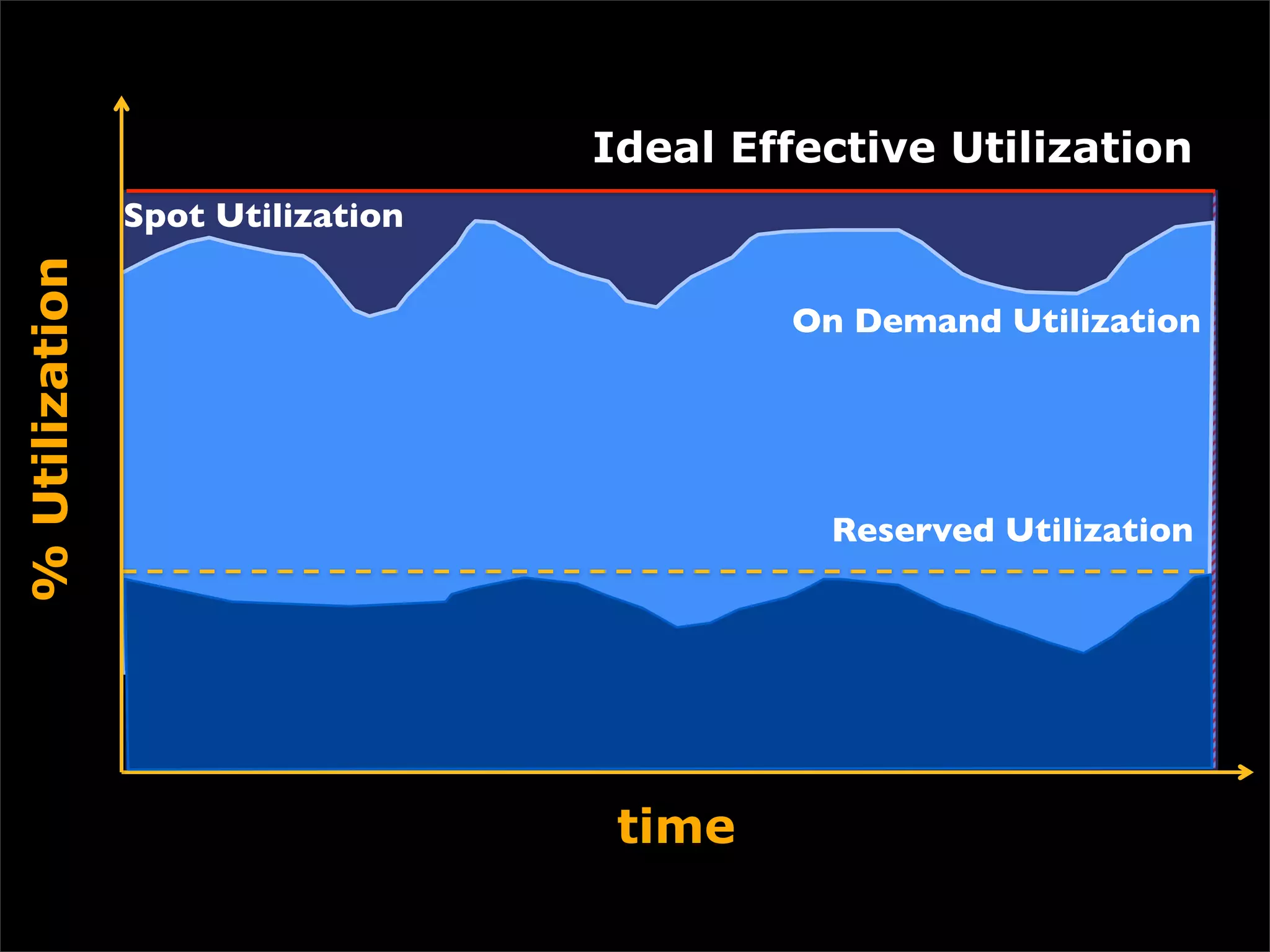







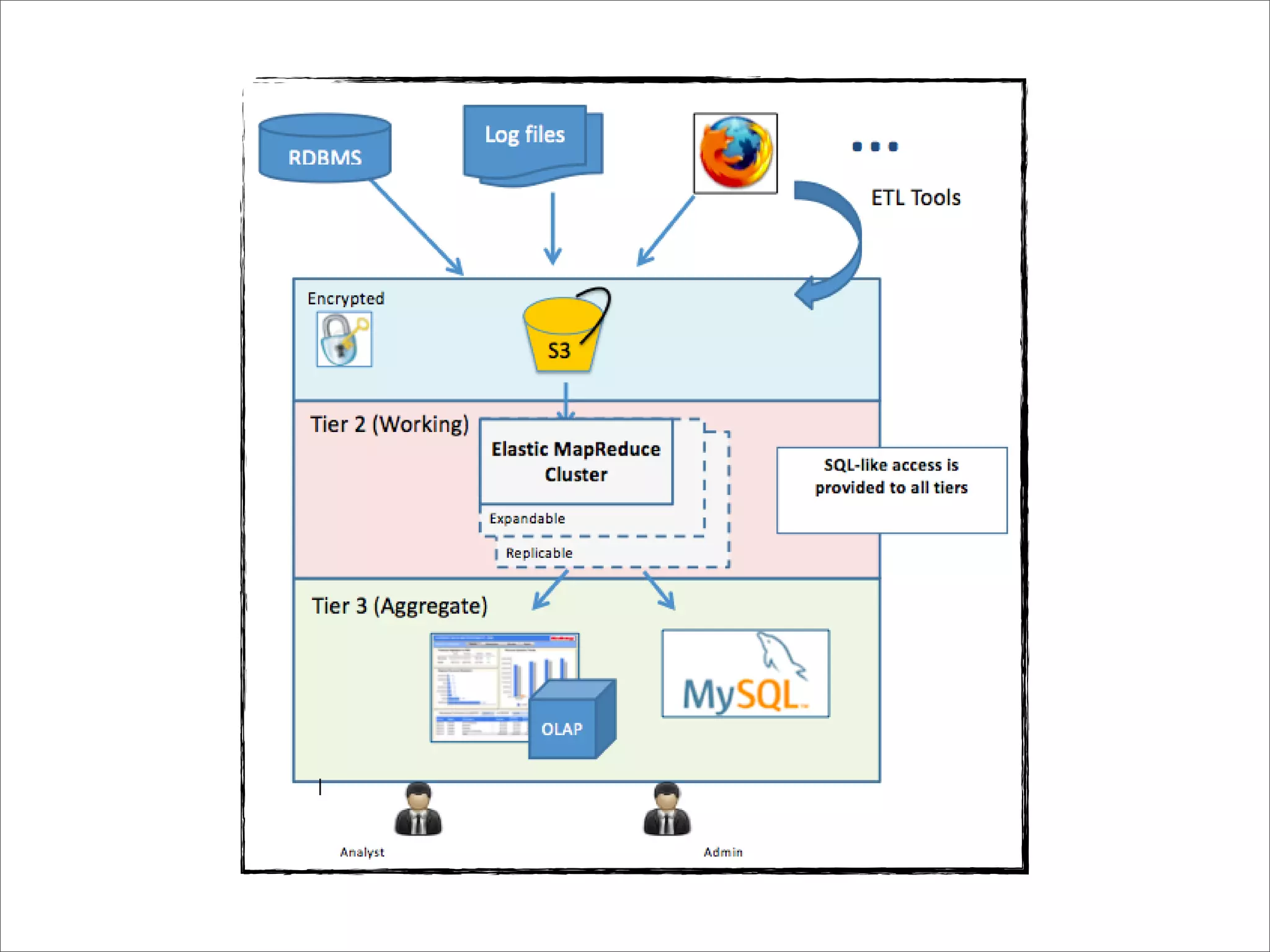



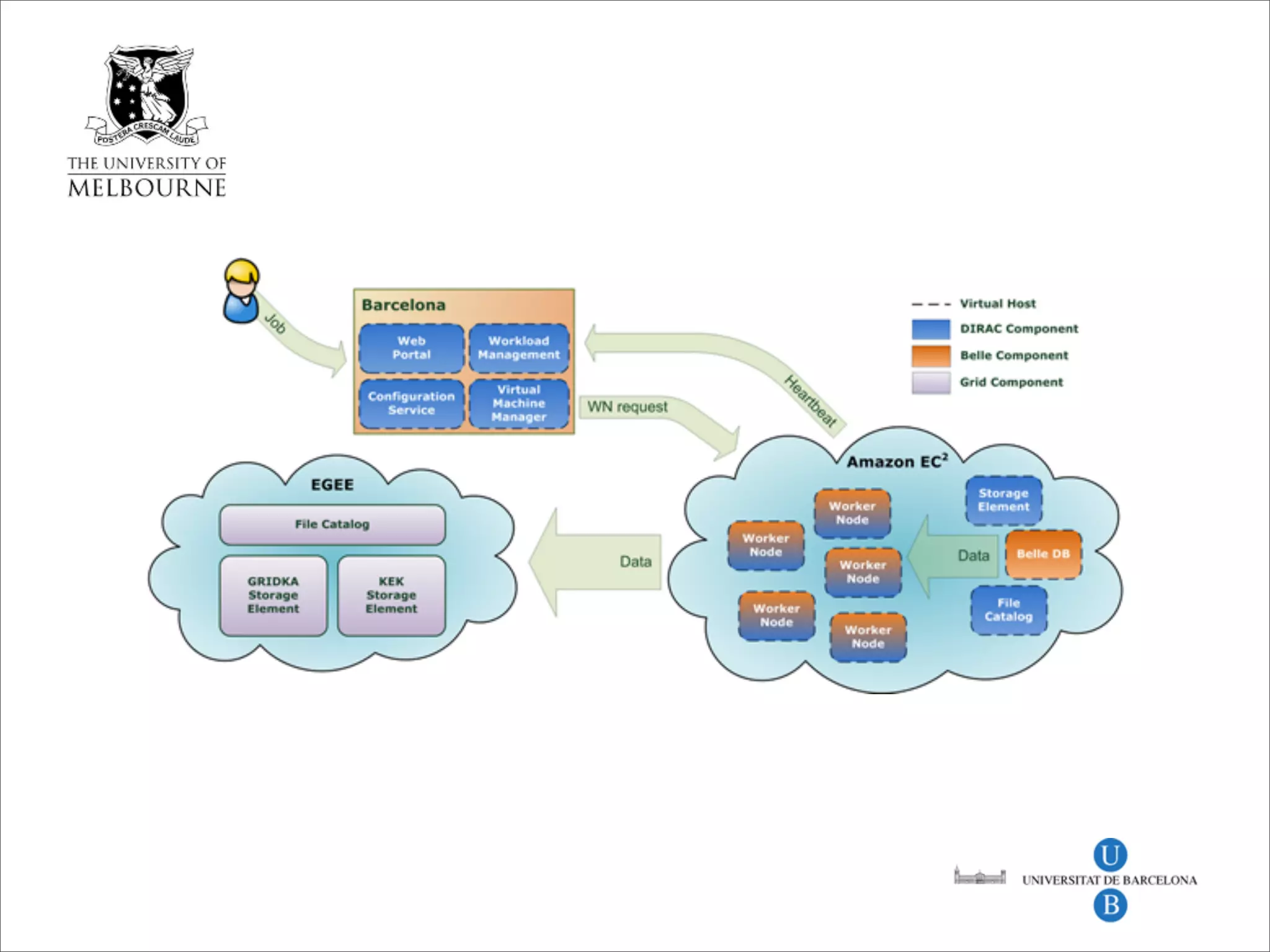

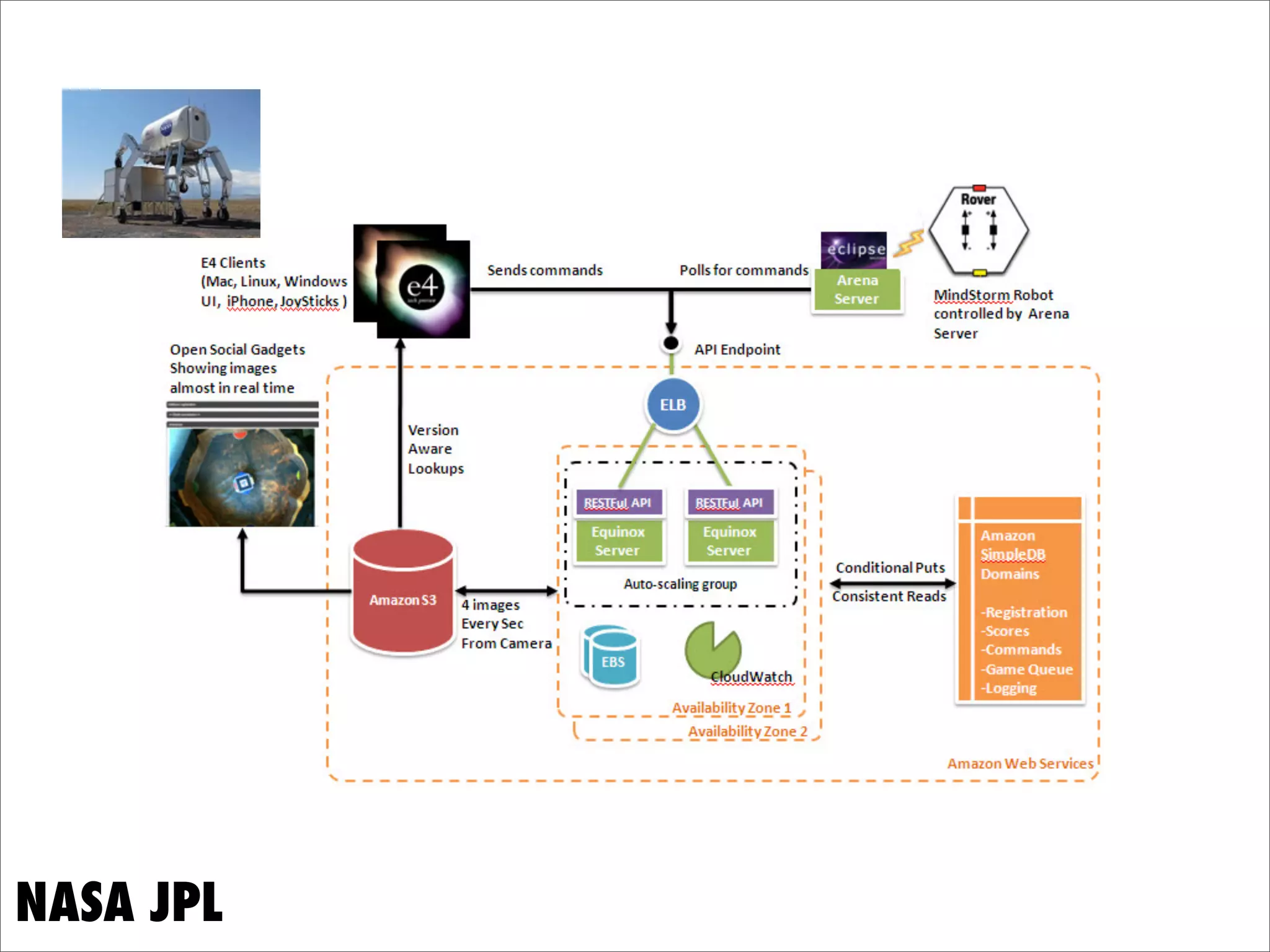
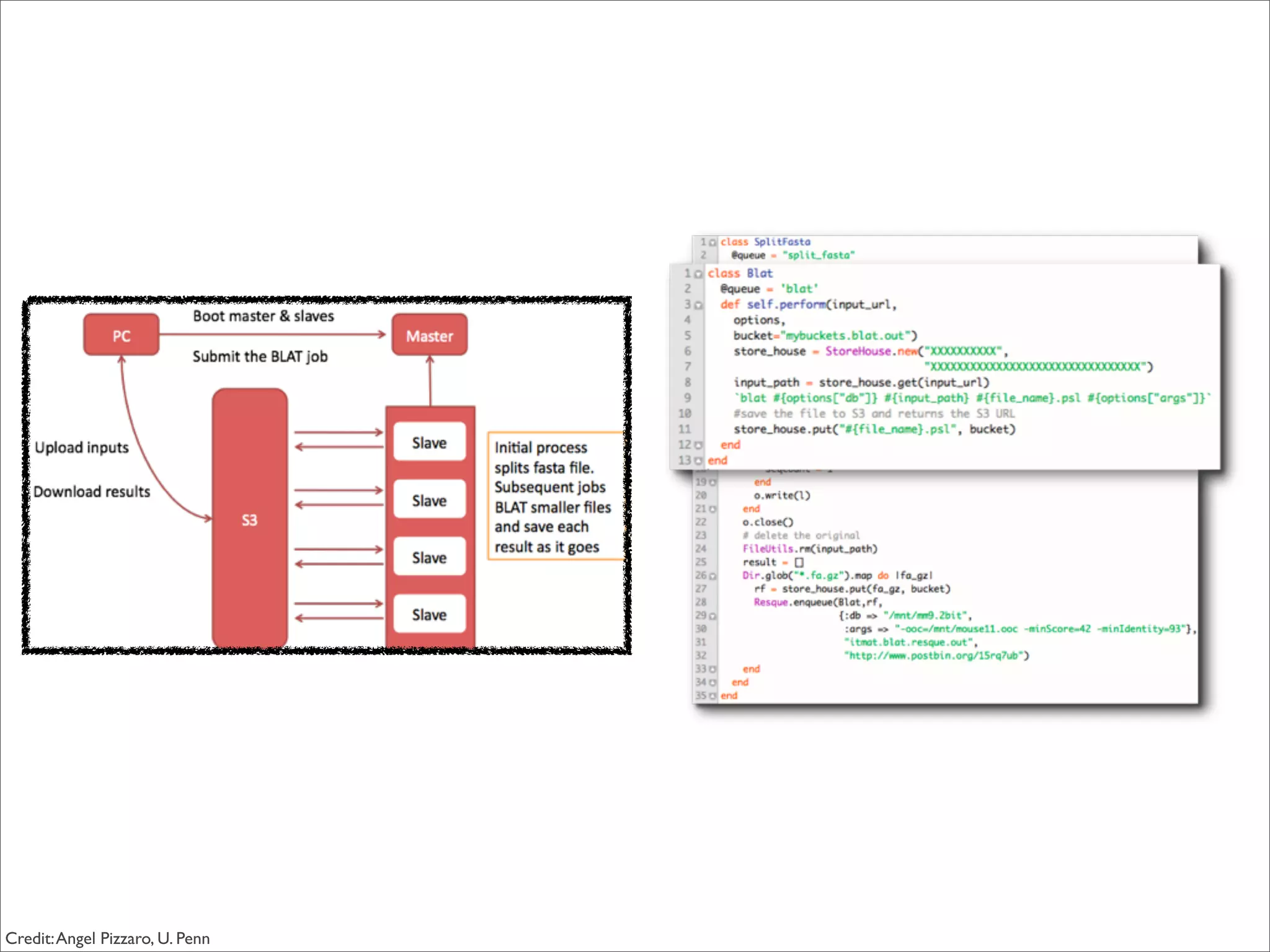

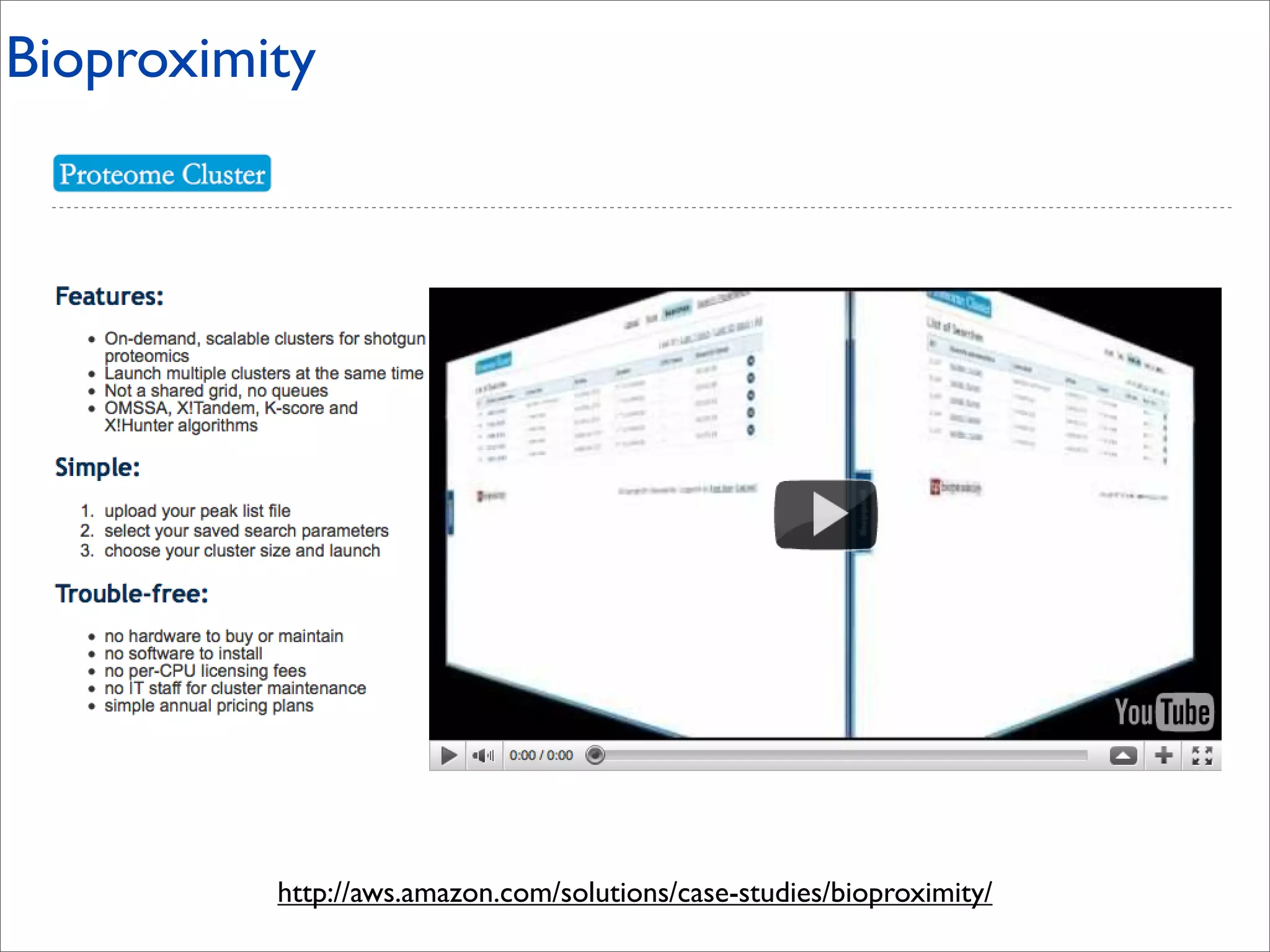
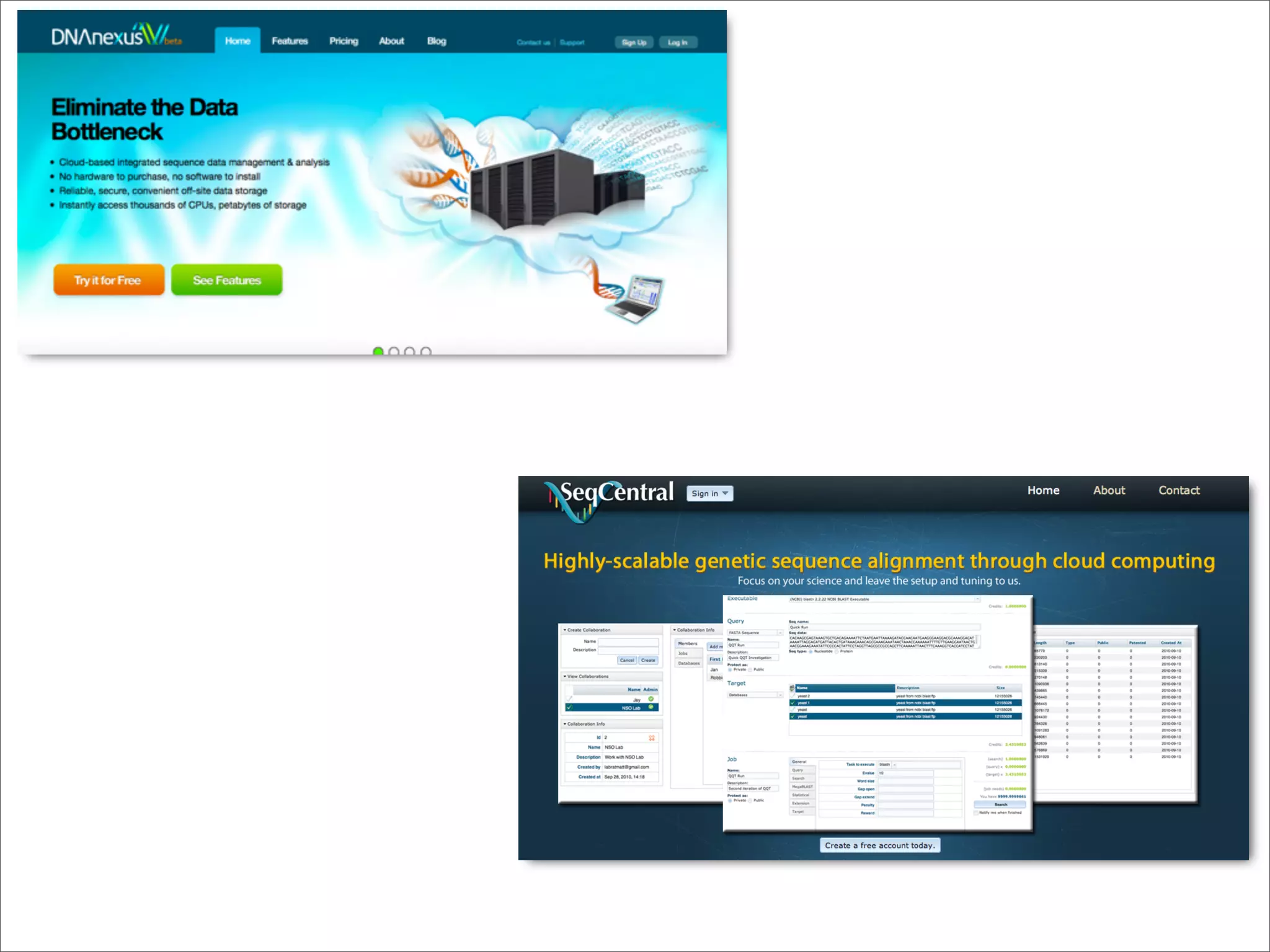
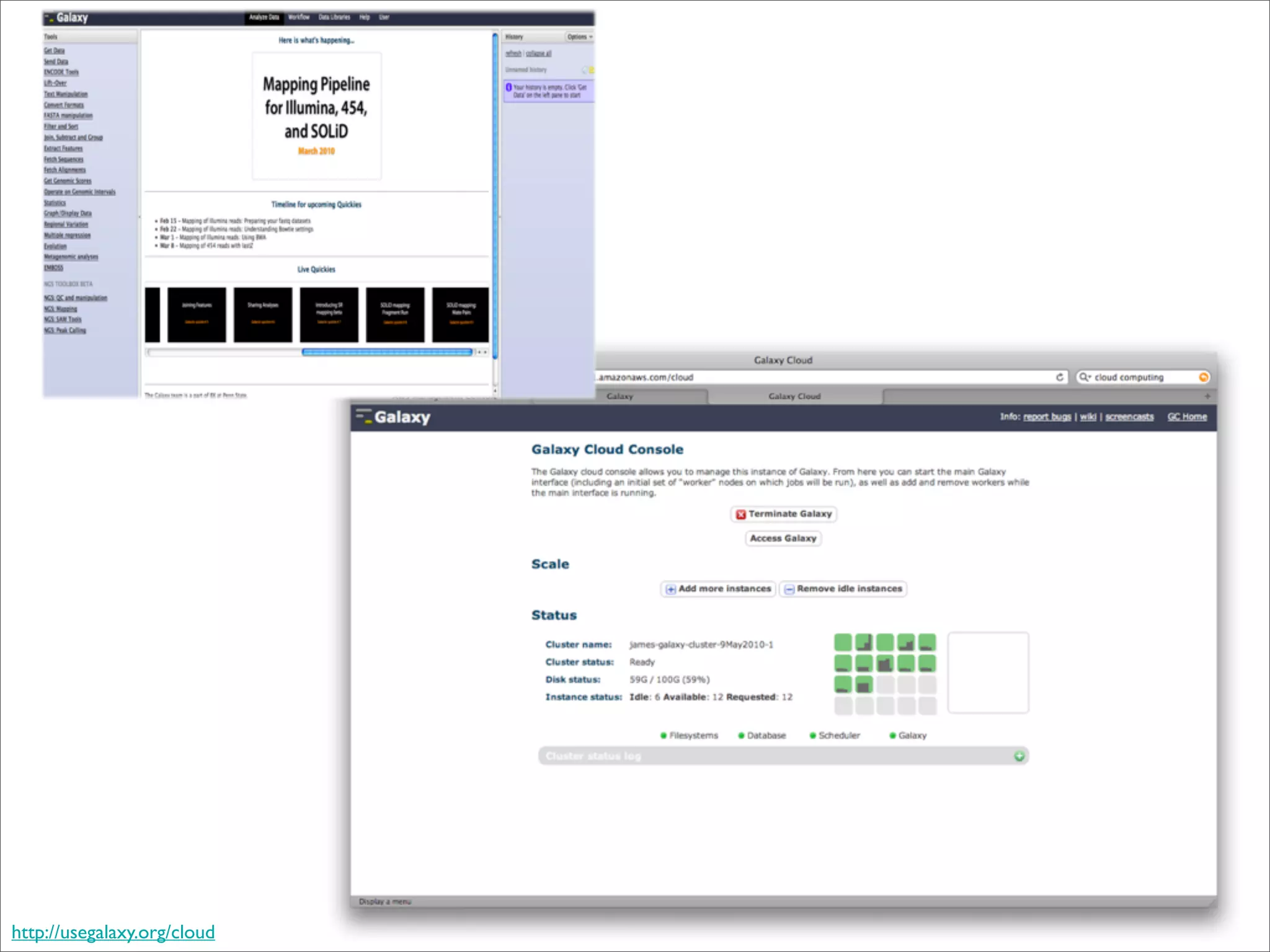



















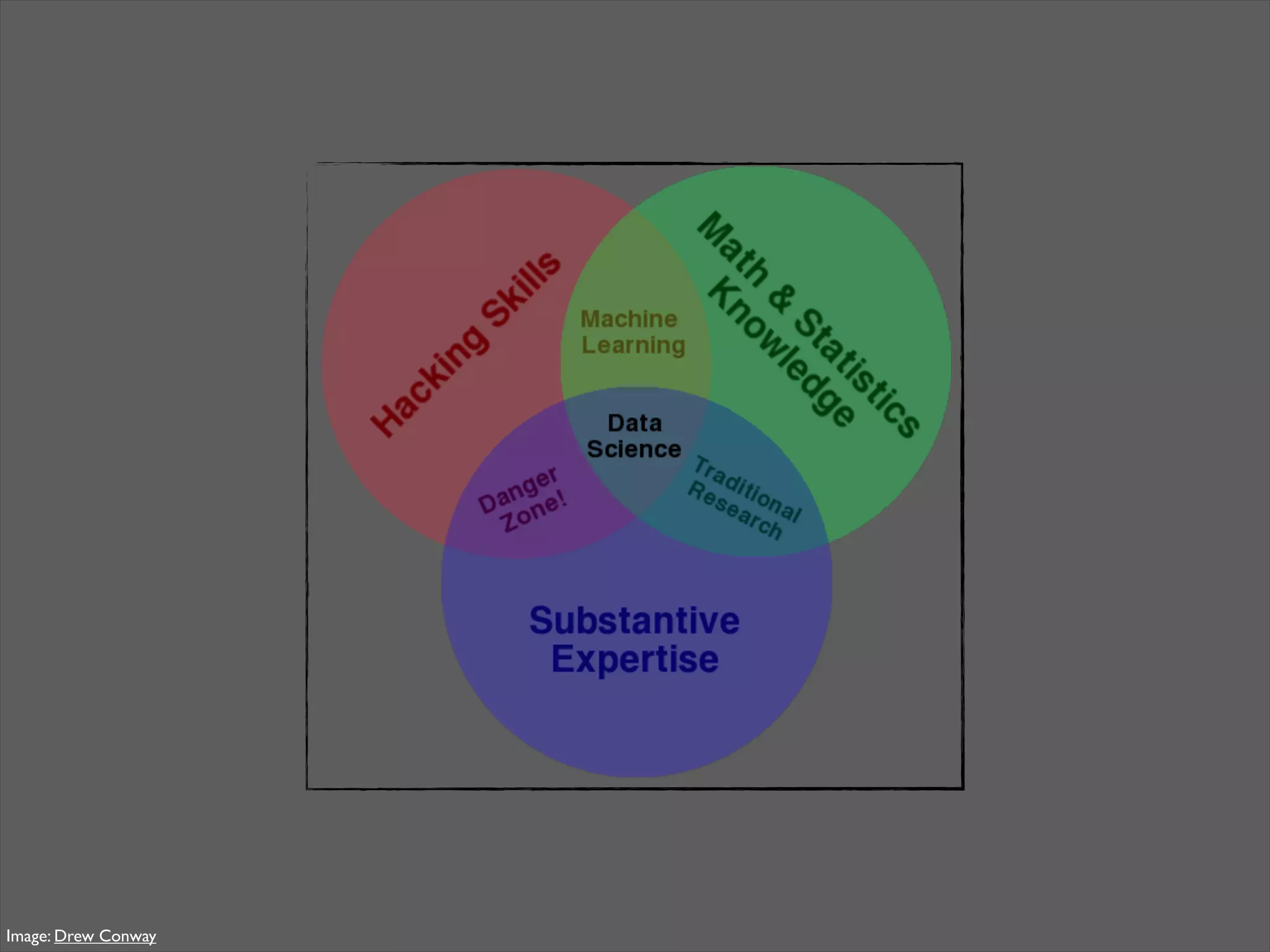
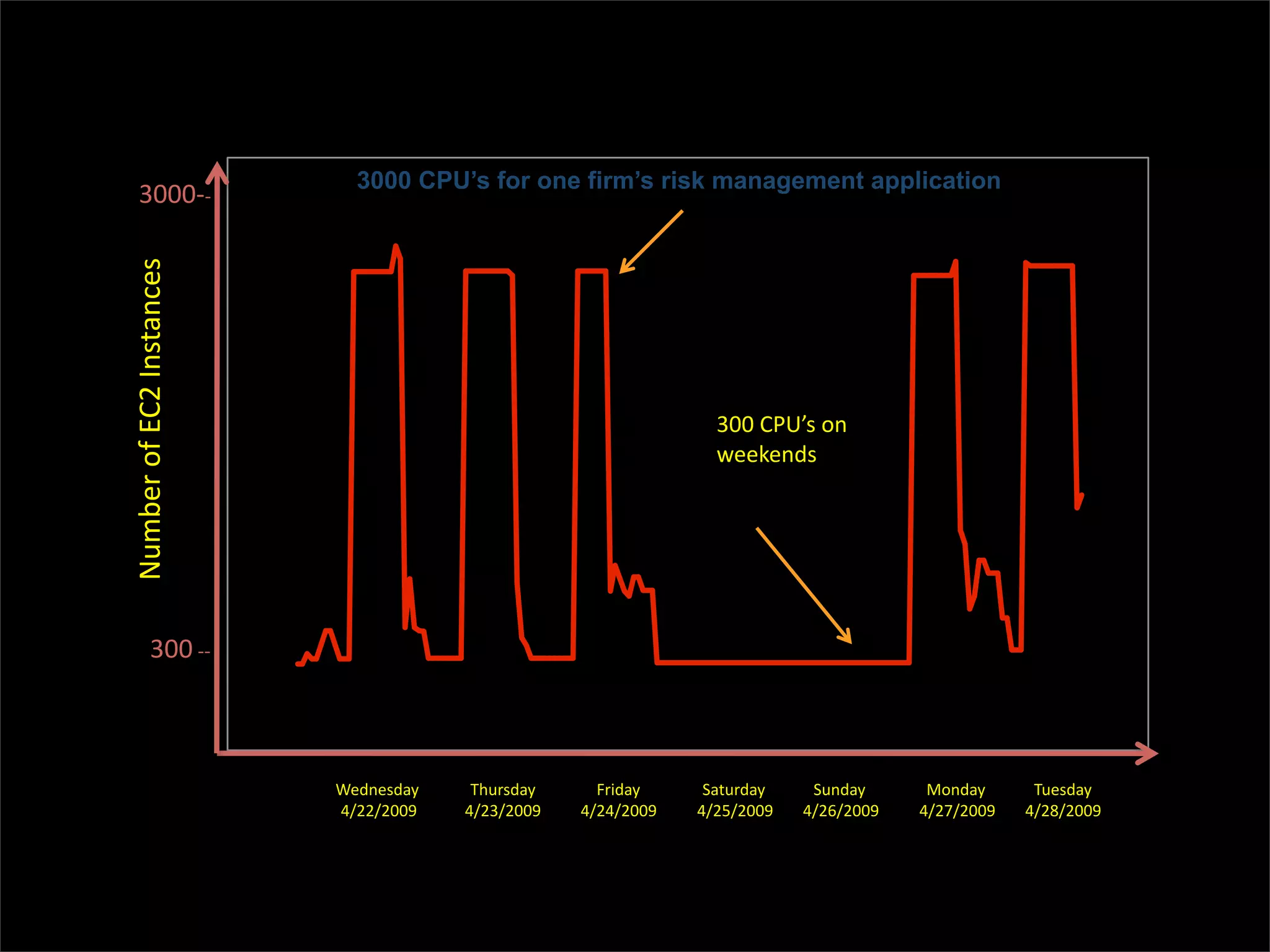
This document discusses how data science platforms can be built on cloud computing infrastructure like Amazon Web Services (AWS). It highlights how AWS provides scalable, on-demand computing and storage resources that allow data and compute needs to scale rapidly. Example applications and customer case studies are presented to show how various organizations are using AWS for large-scale data analysis, including genomics, computational fluid dynamics, and more. The document argues that distributed, programmable cloud infrastructure can support new types of data-driven science by providing massive, rapidly scaling resources.









![[Hatsune Miku] Shoot Frieza with Amazon Kinesis ! [EN]](https://cdn.slidesharecdn.com/ss_thumbnails/jawsdayslt20140315up3en-140321051150-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![Reproducible datascience [with Terraform]](https://cdn.slidesharecdn.com/ss_thumbnails/reproduceabledatascience1-180630074643-thumbnail.jpg?width=640&height=640&fit=bounds)
![[263] s2graph large-scale-graph-database-with-hbase-2](https://cdn.slidesharecdn.com/ss_thumbnails/236s2graph-large-scale-graph-database-with-hbase-2-150915055019-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[JSDC 2016] Codex: Conditional Modules Strike Back](https://cdn.slidesharecdn.com/ss_thumbnails/codex-conditionalmodulesstrikebackalexliujsdc2016-161023023432-thumbnail.jpg?width=640&height=640&fit=bounds)




























































