Downloaded 61 times



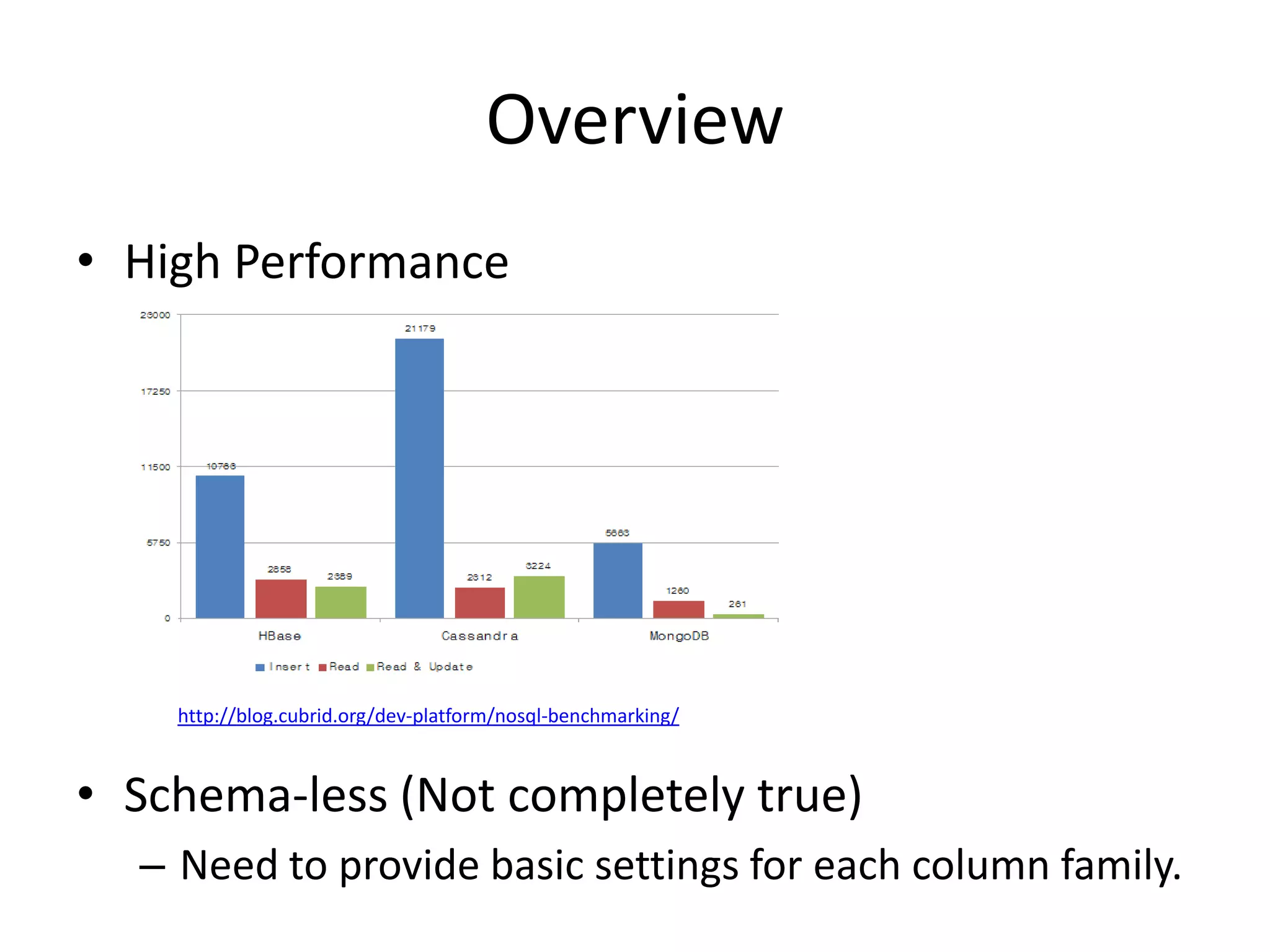

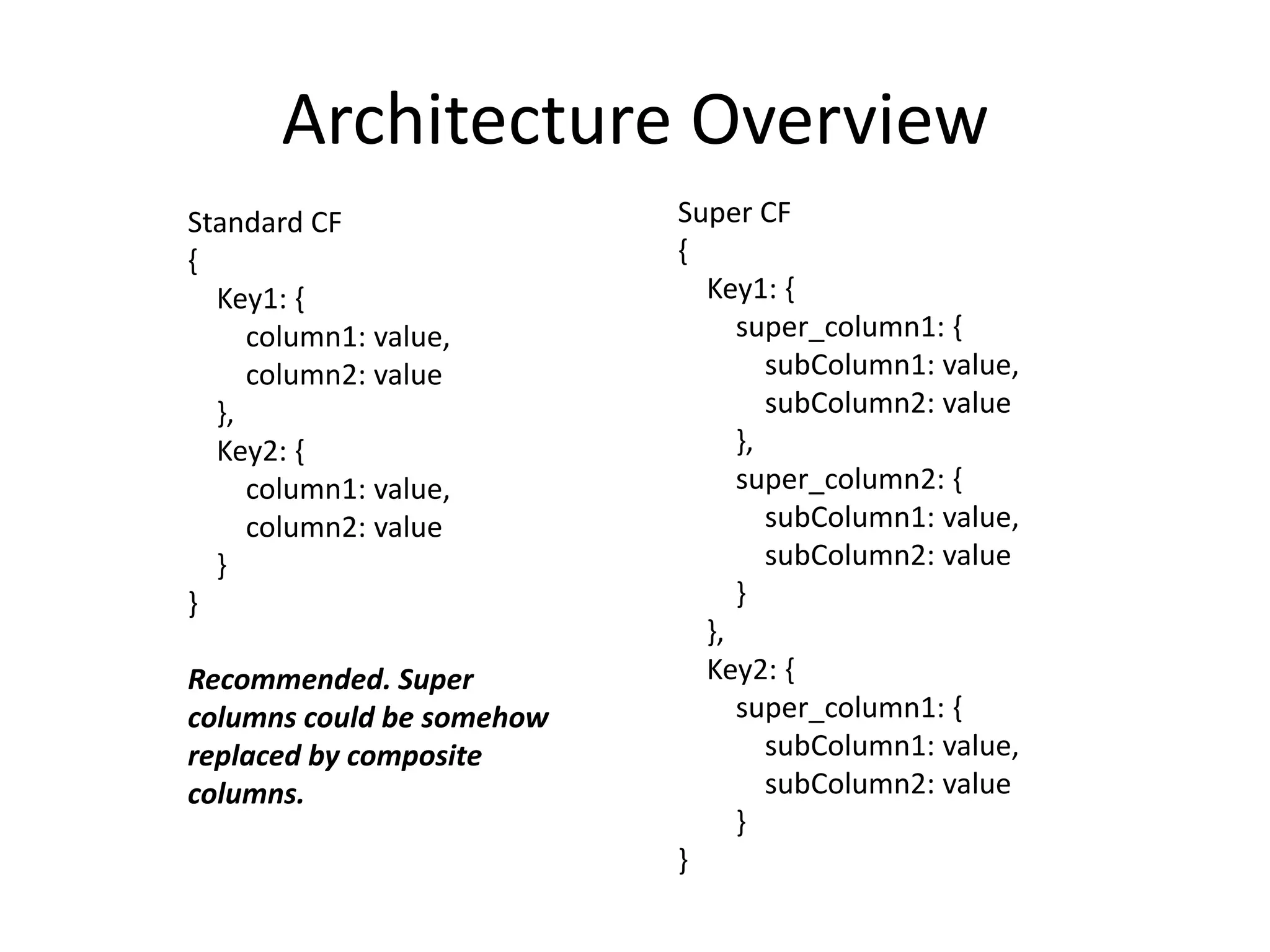

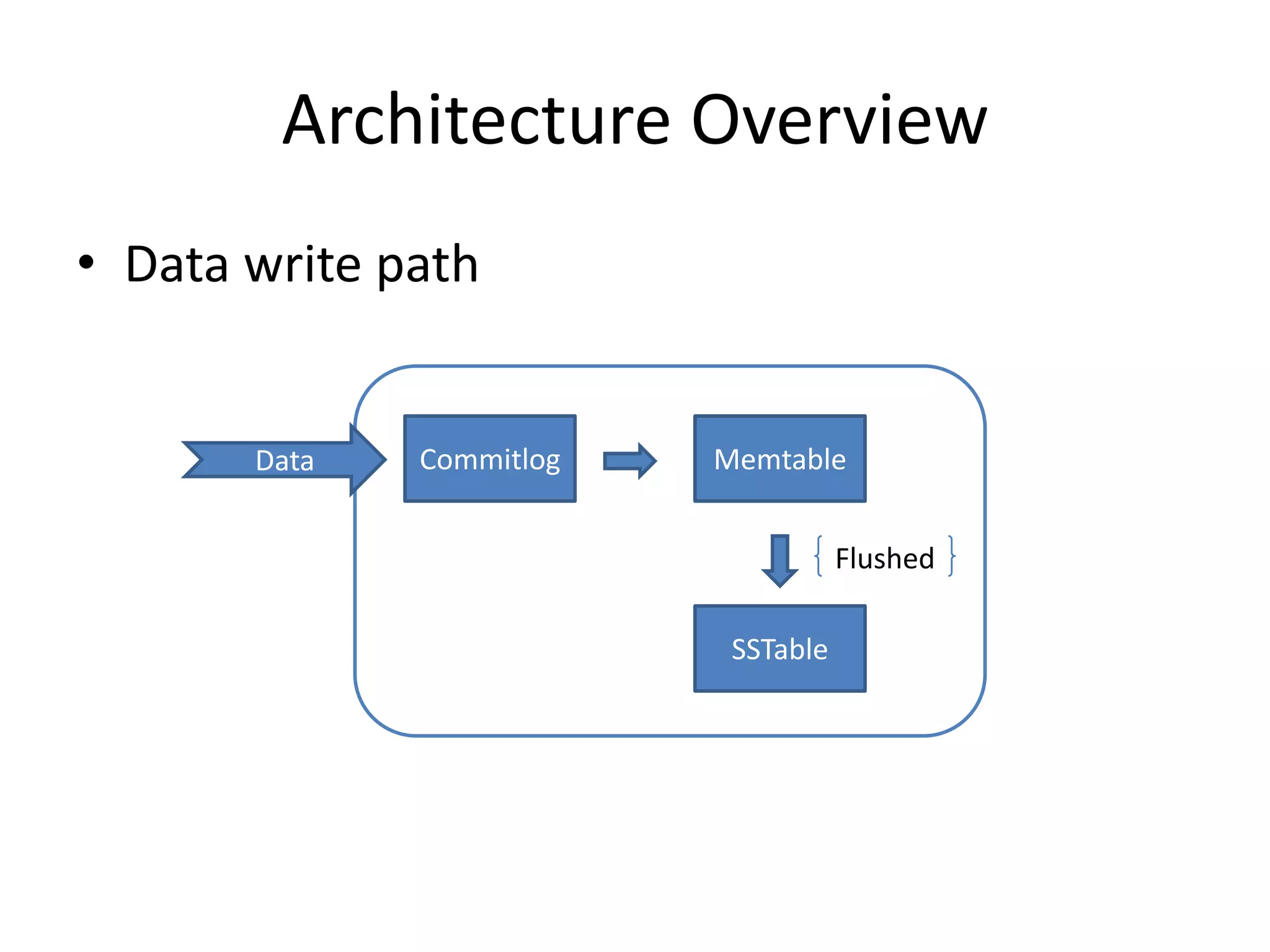


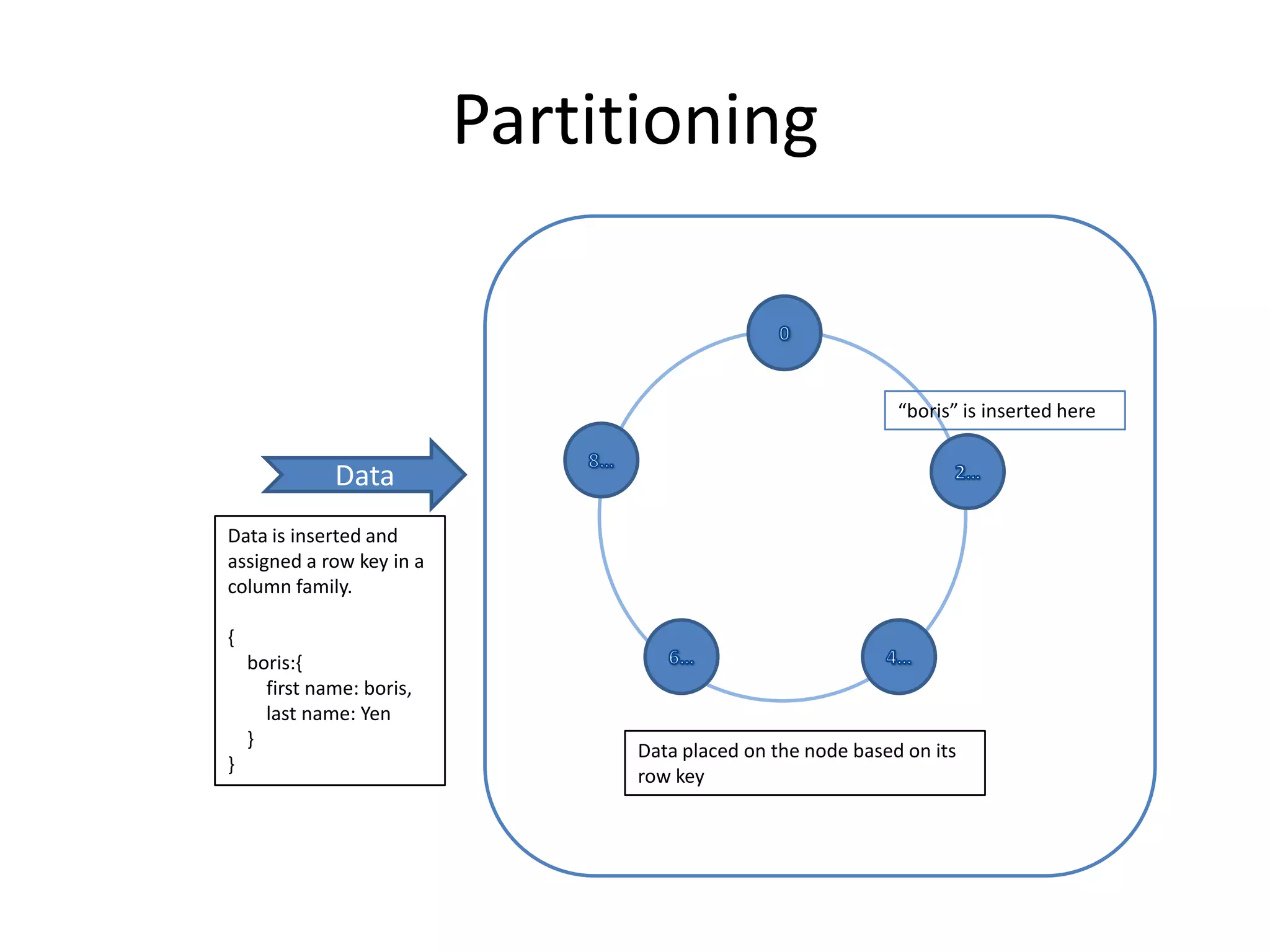



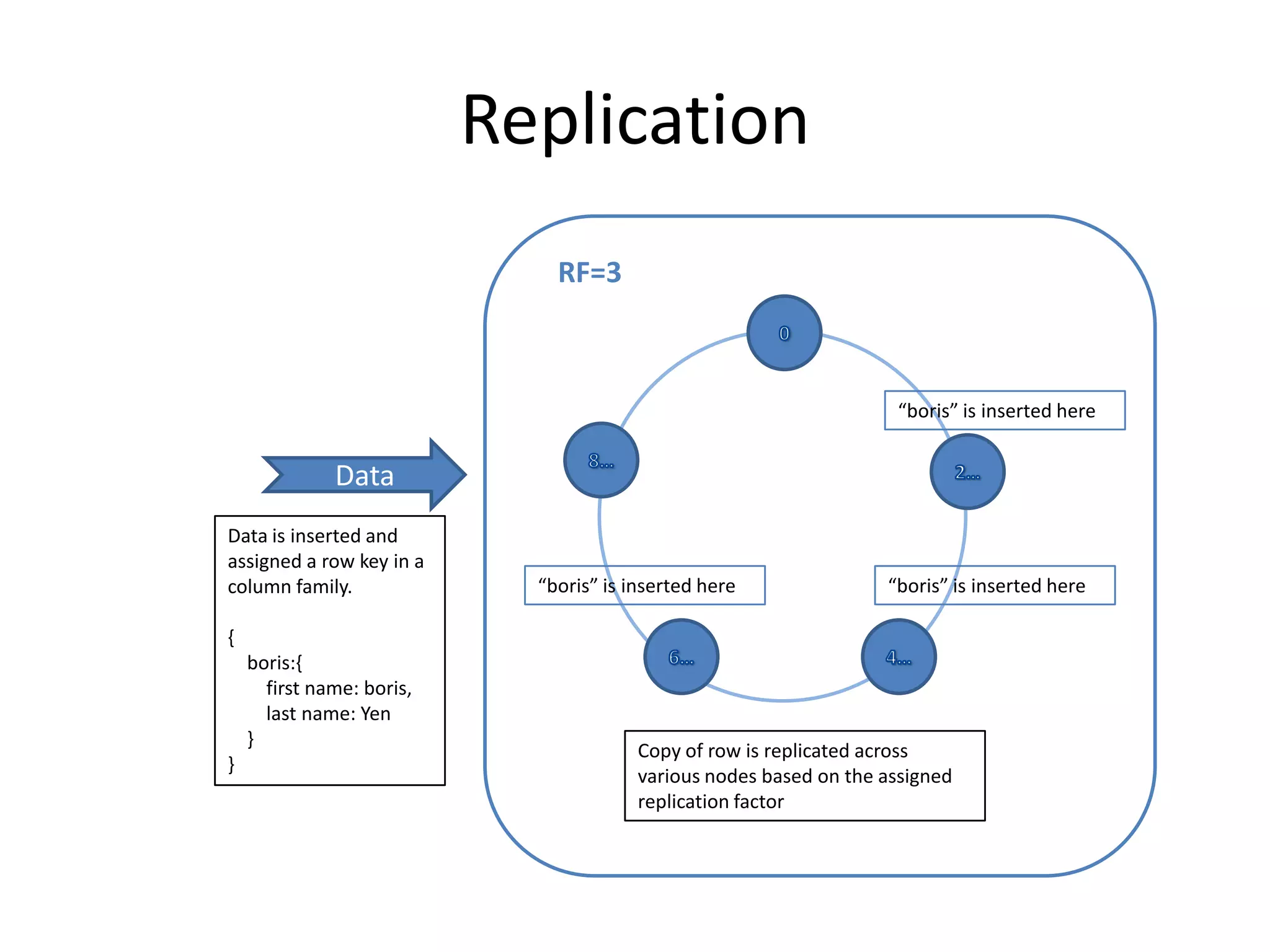

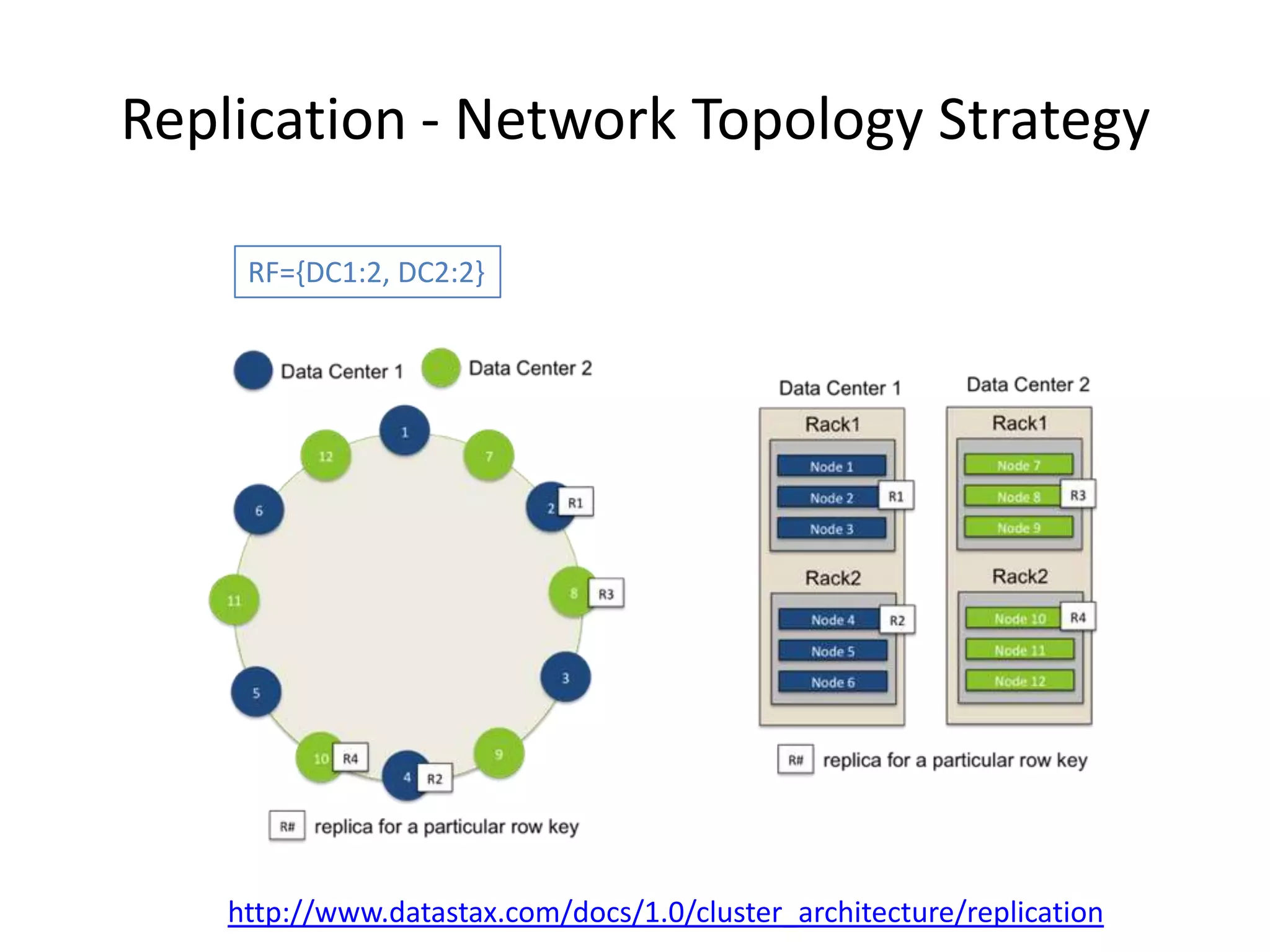















Cassandra is a highly scalable, distributed, and fault-tolerant NoSQL database. It partitions data across nodes through consistent hashing of row keys, and replicates data for fault tolerance based on a replication factor. Cassandra provides tunable consistency levels for reads and writes. It uses a gossip protocol for node discovery and a commit log for write durability.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















