Download as PDF, PPTX




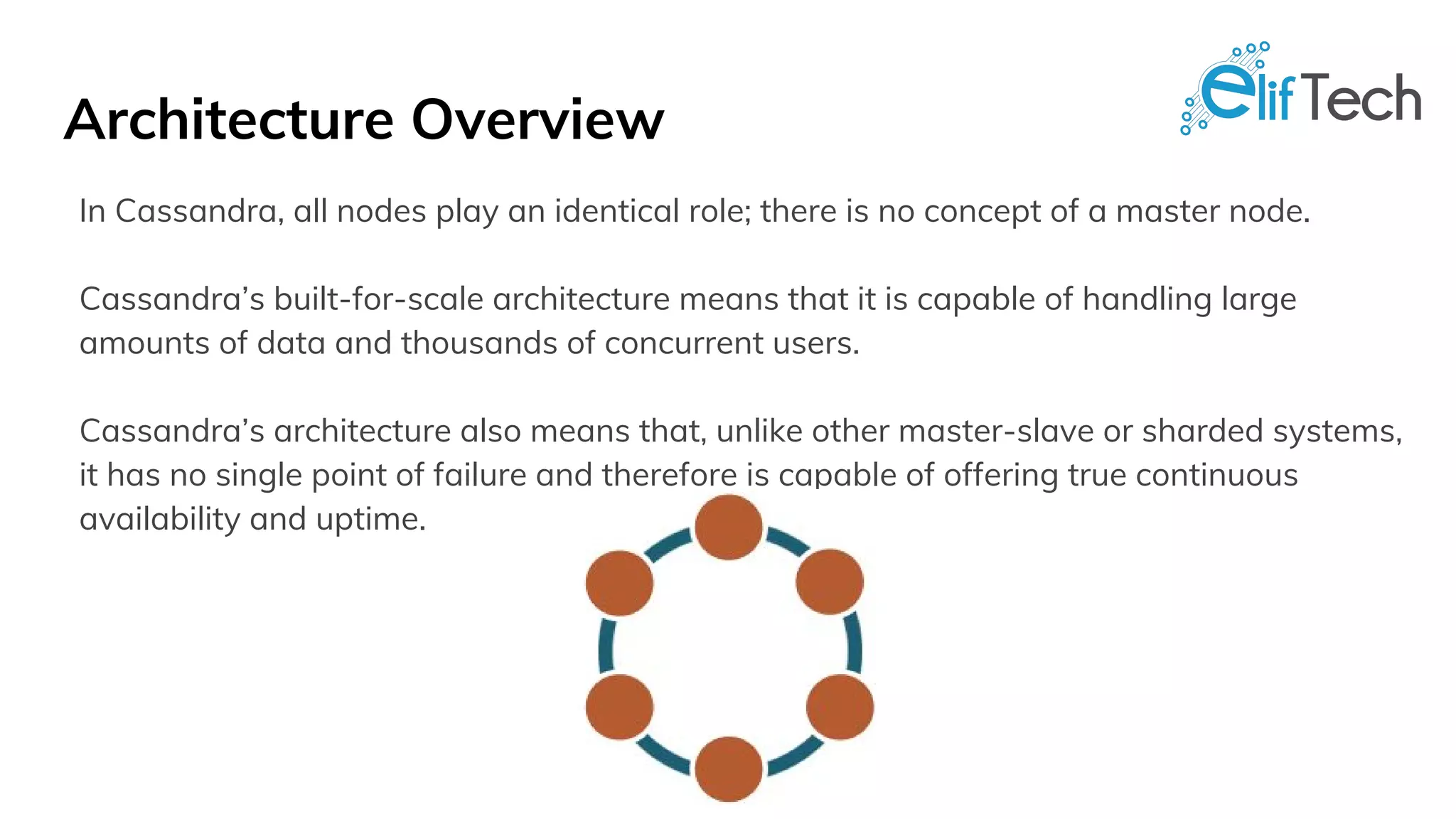

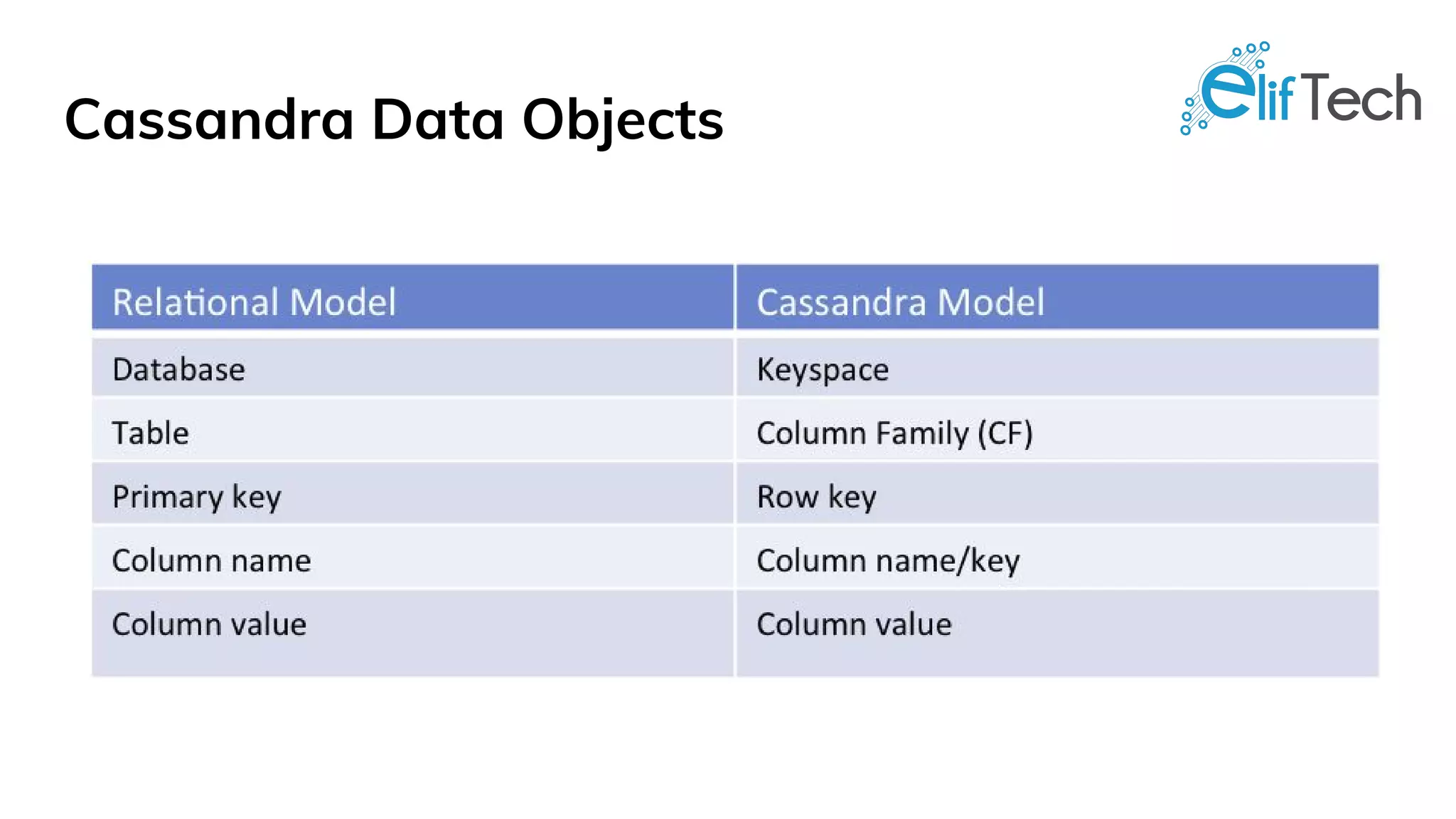

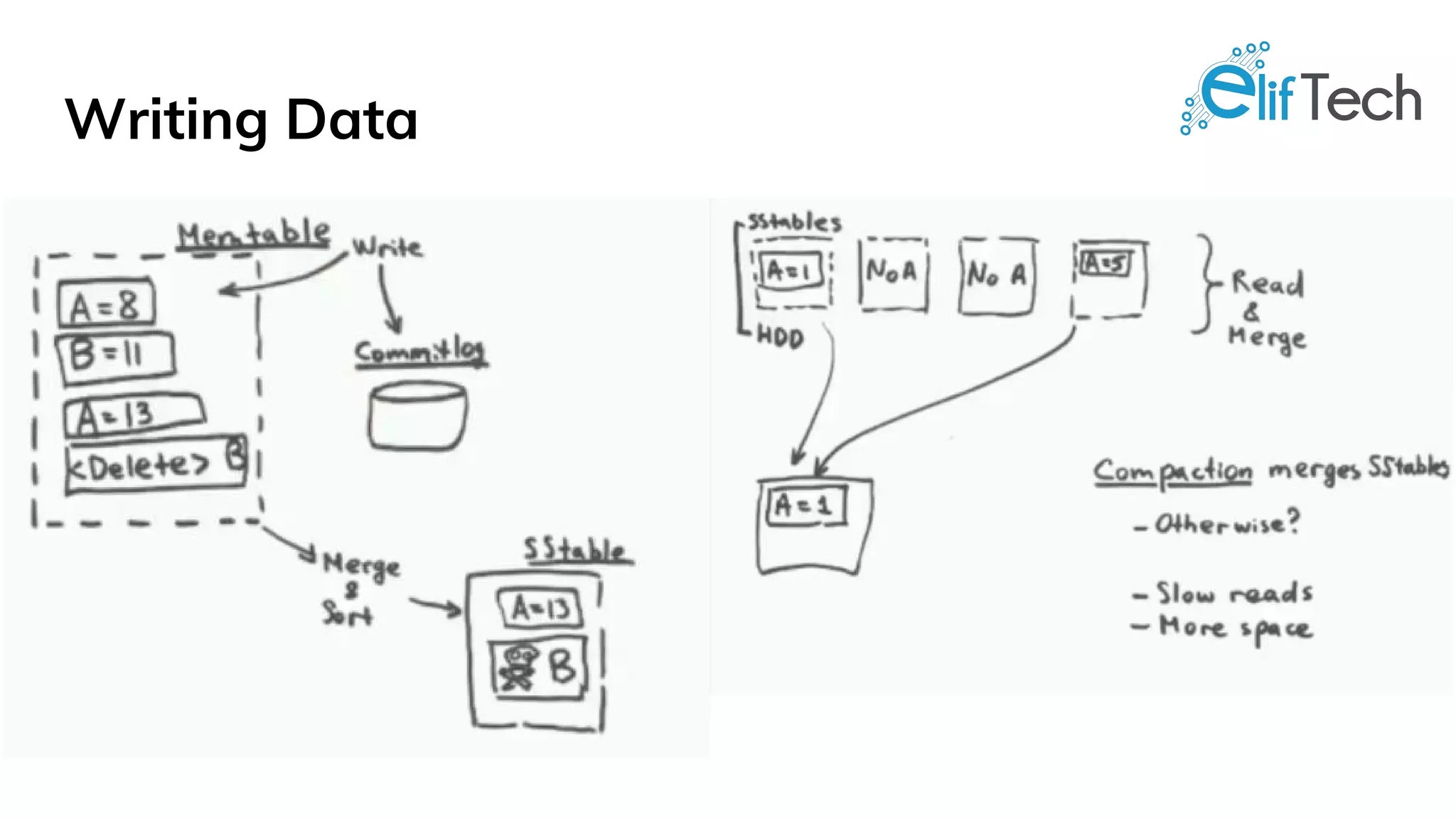
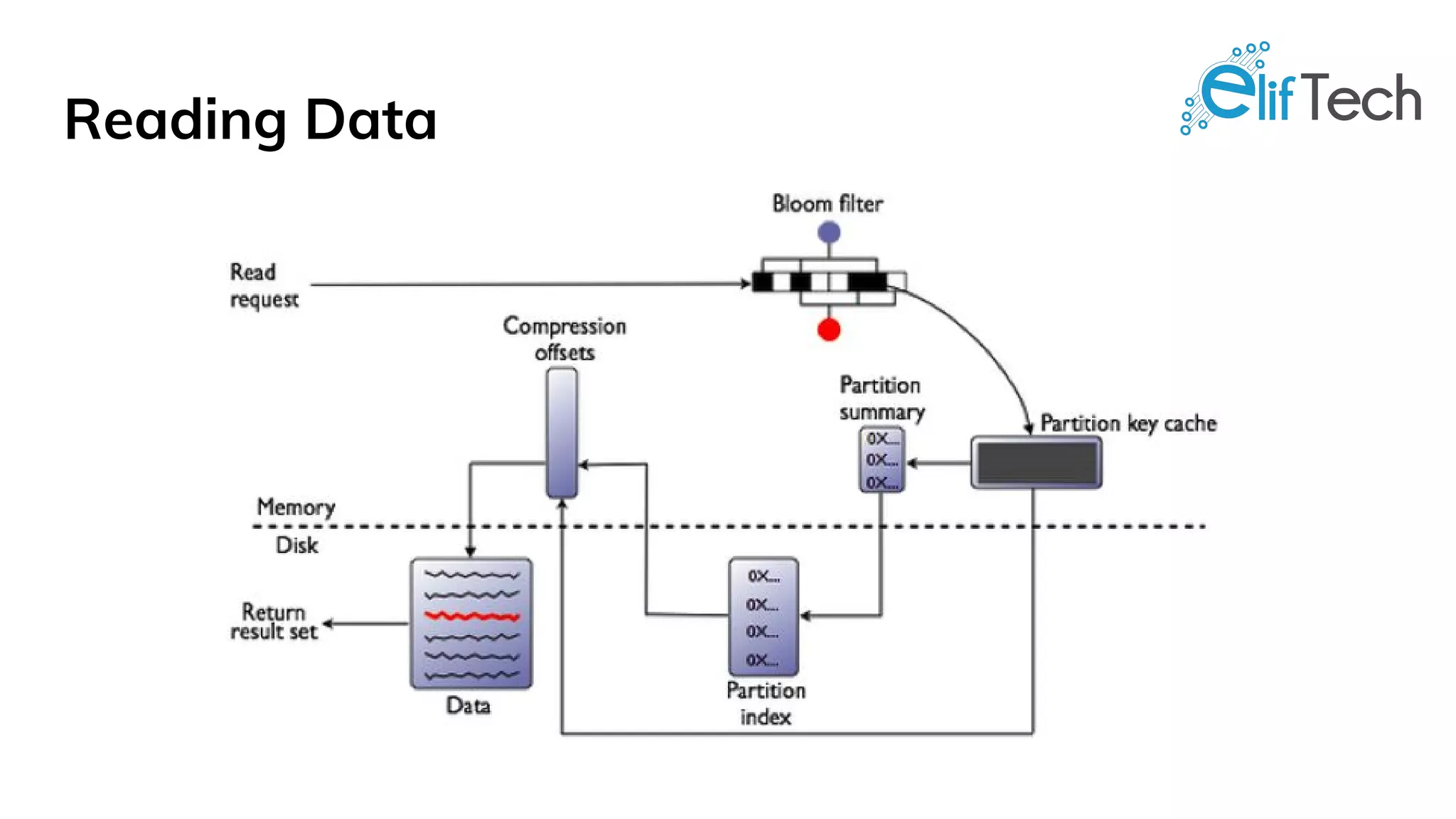



Apache Cassandra is a distributed, high-performance, and fault-tolerant post-relational database designed for scalability and continuous availability. It is ideal for various use cases including IoT applications, retail solutions, user activity monitoring, messaging, and social media analytics, thanks to its features like linear performance, easy replication, and tunable data consistency. All nodes in Cassandra play identical roles, eliminating single points of failure and enabling it to handle large data volumes effectively.











































































































