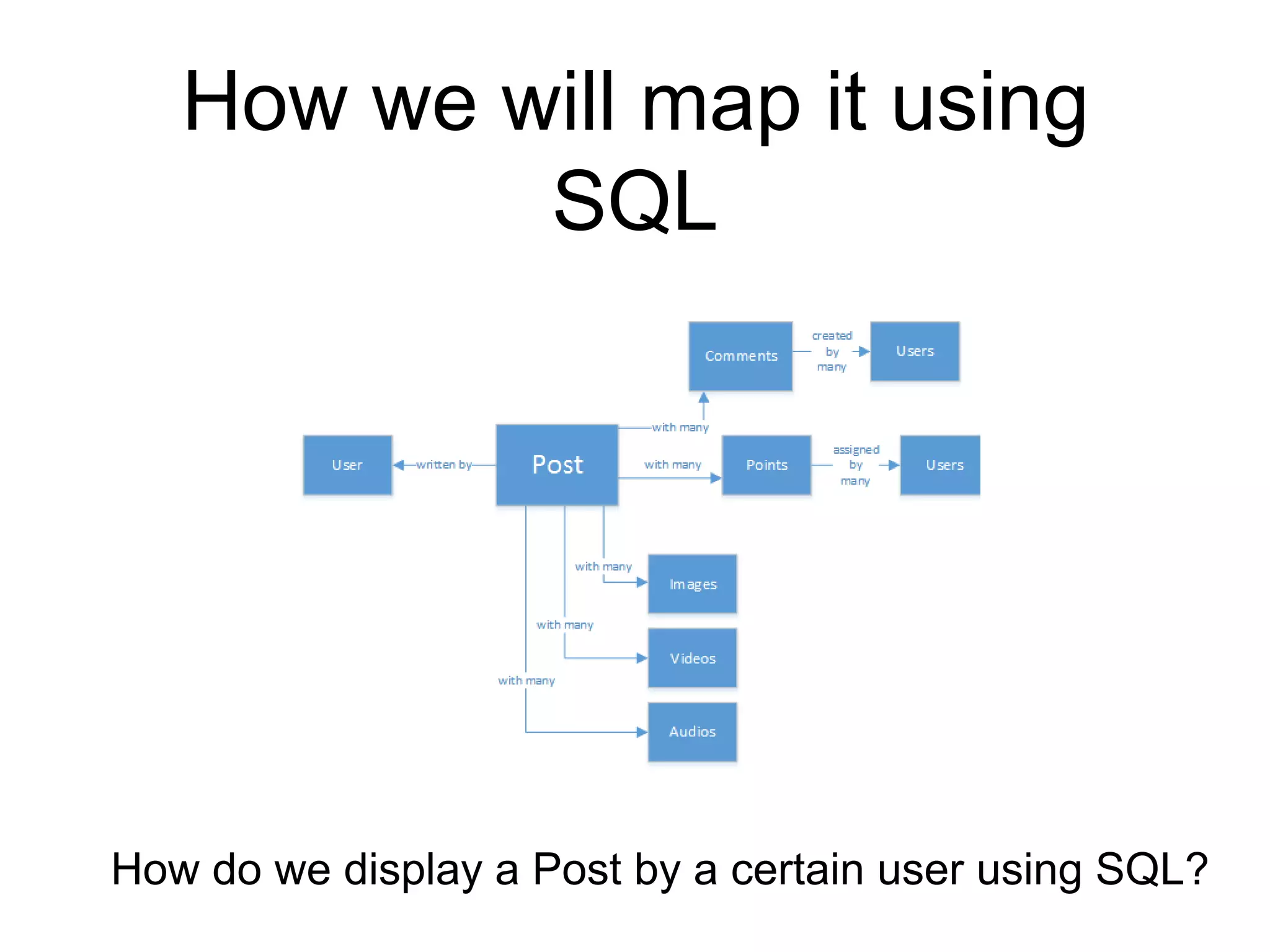
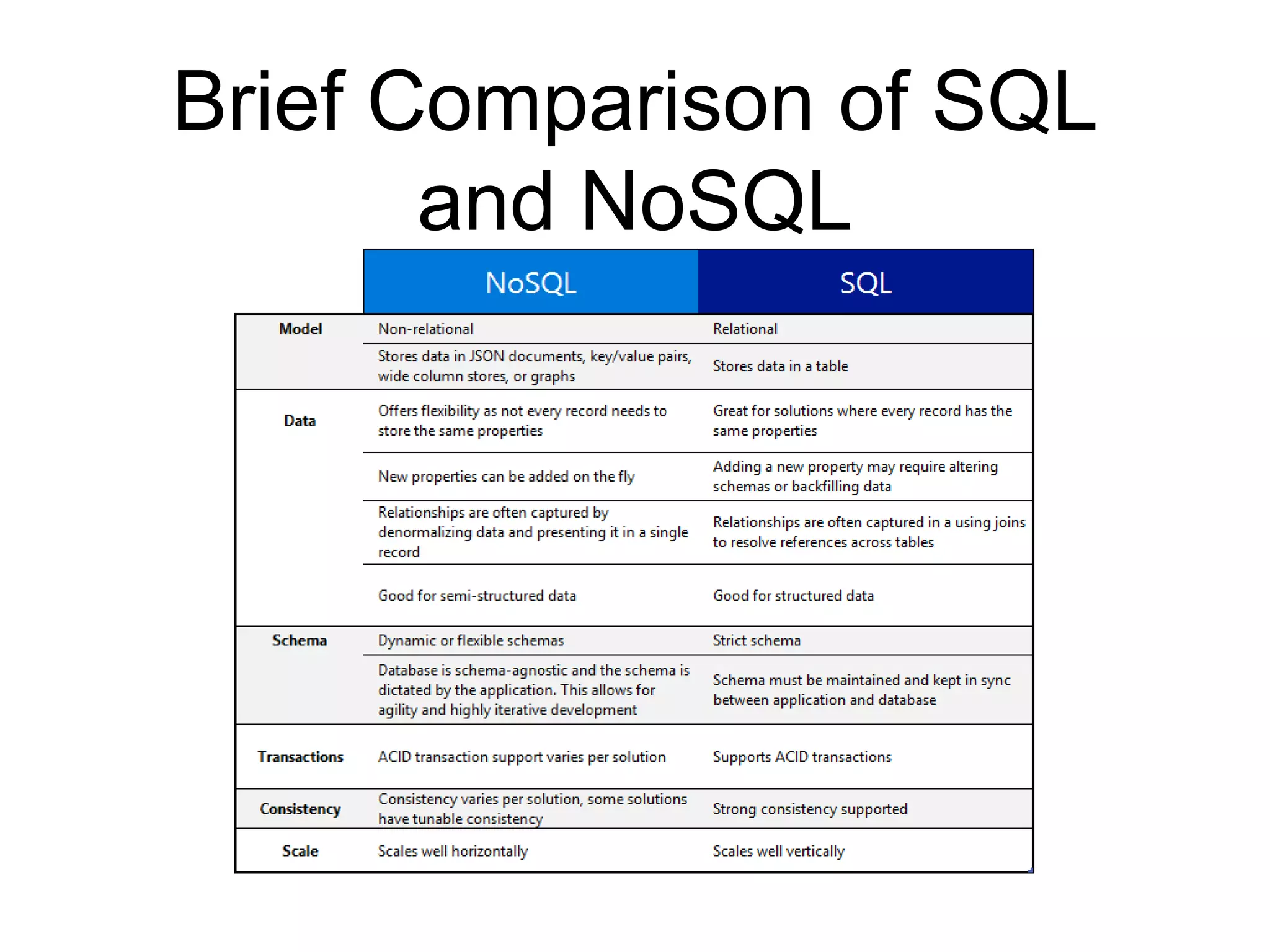
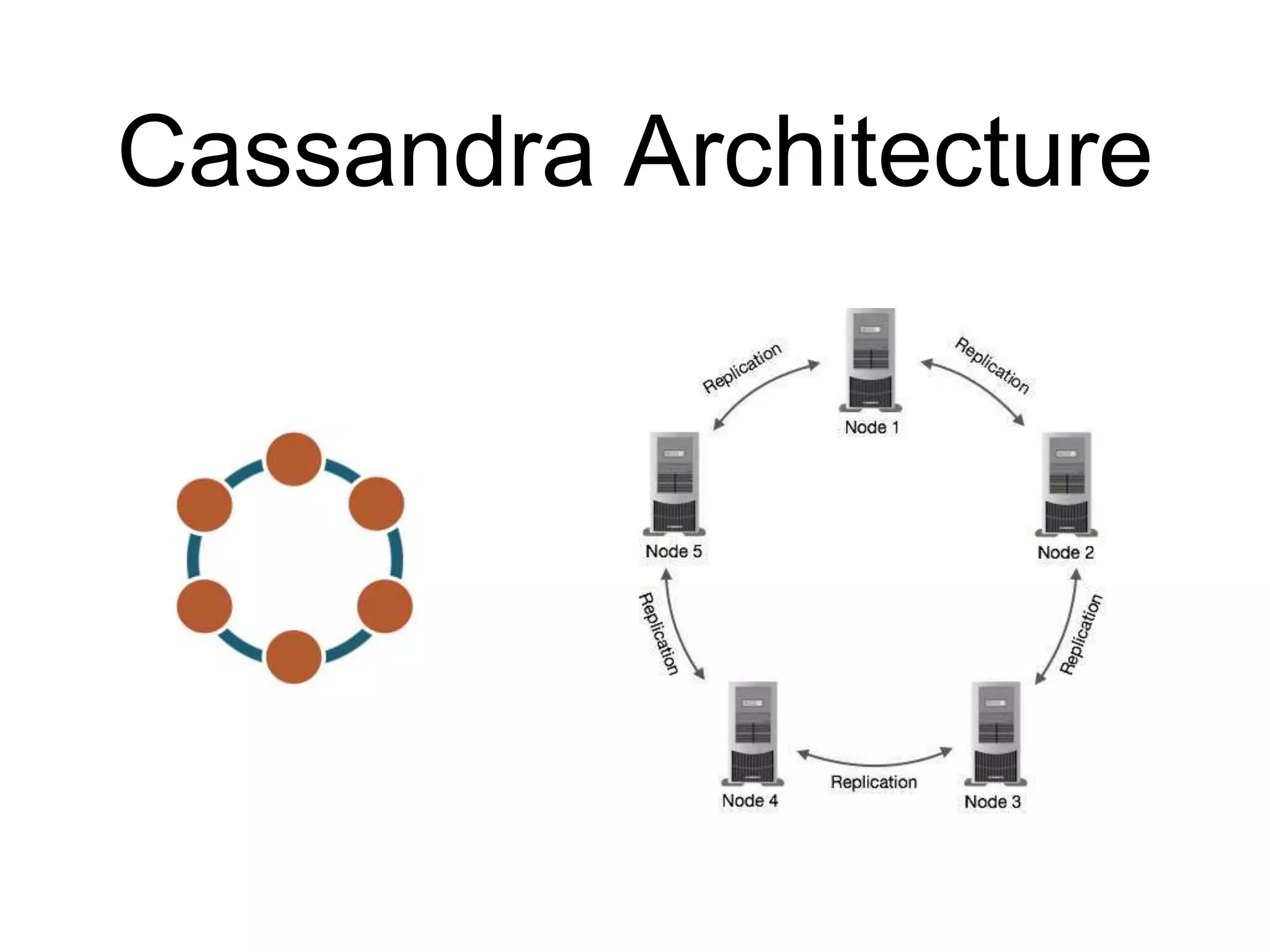
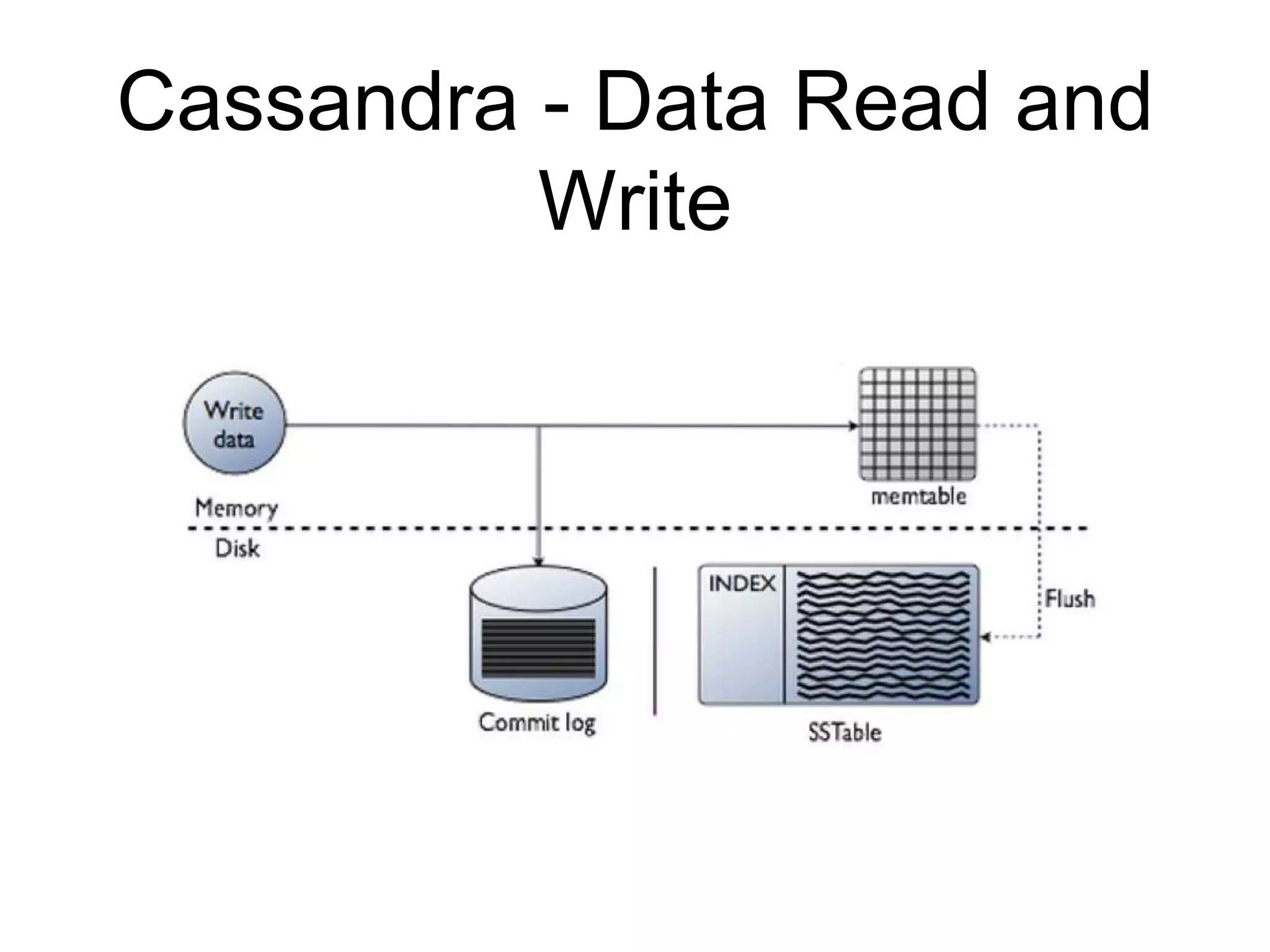
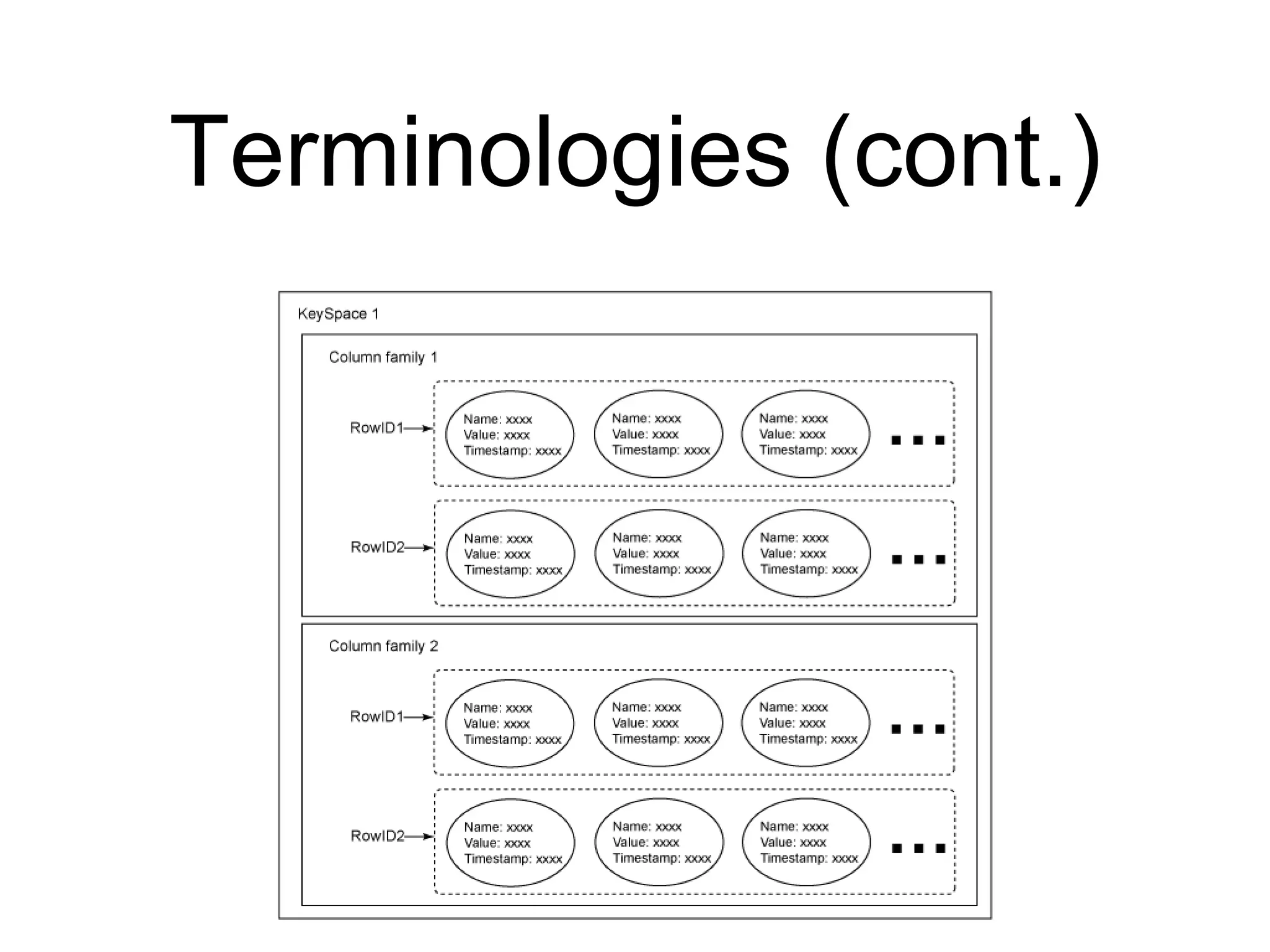
This document provides an introduction to NoSQL and Cassandra. It discusses what NoSQL is, provides a brief history of Cassandra, describes Cassandra's architecture and data model, and covers the Cassandra Query Language (CQL) and basic CRUD operations using CQL. The document also includes a comparison of SQL and NoSQL databases and references for further reading.