Download as PDF, PPTX



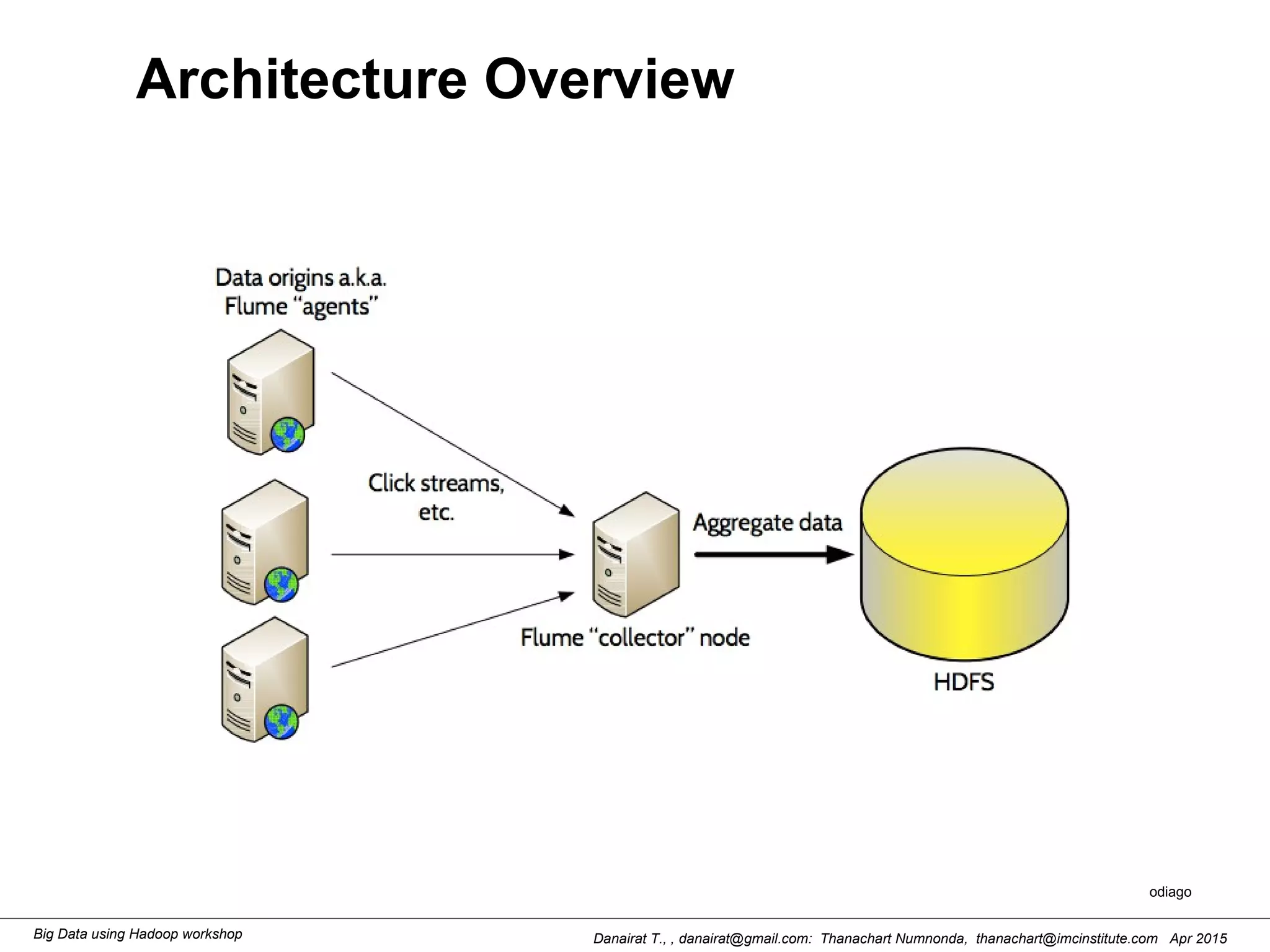

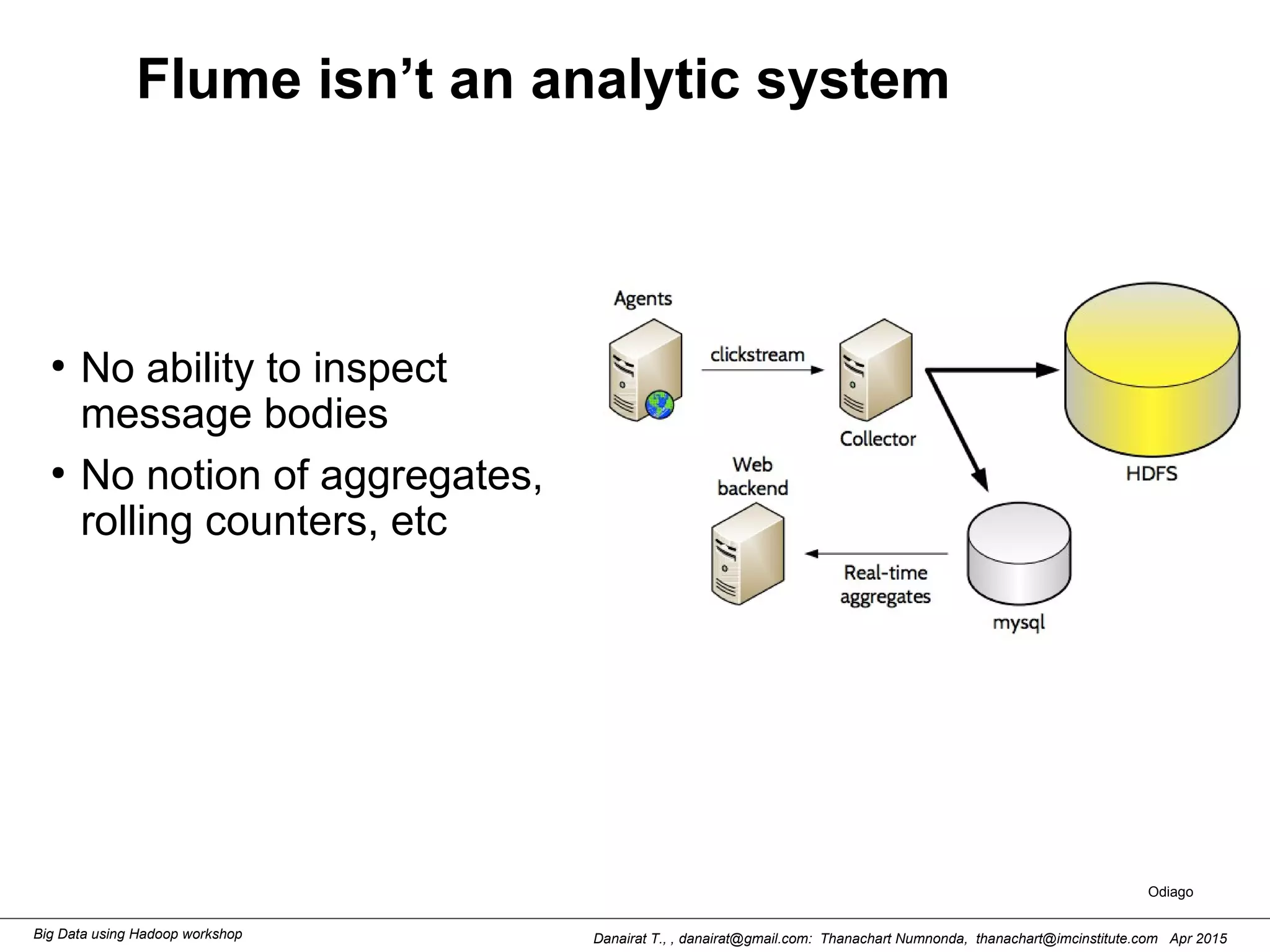

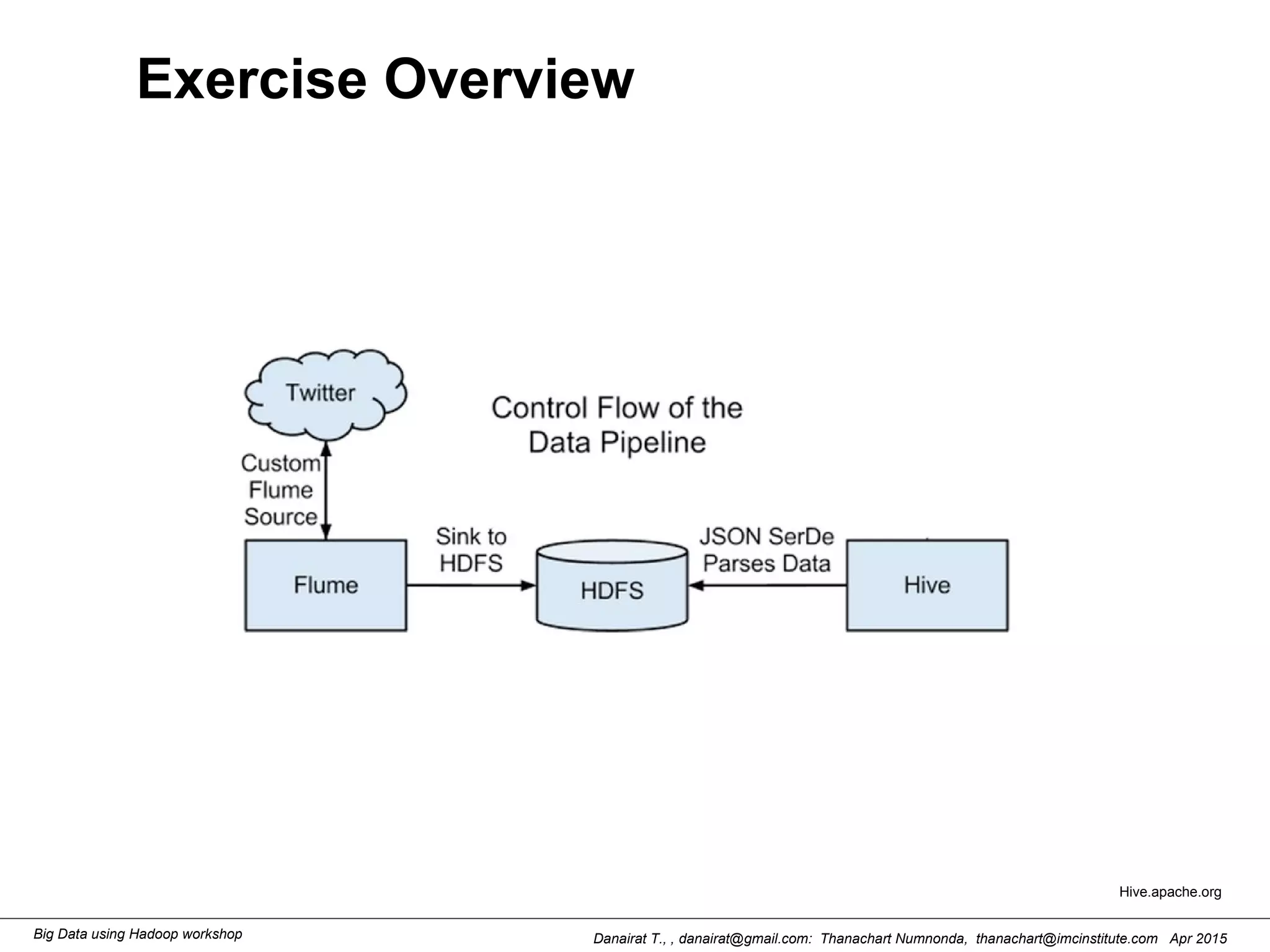


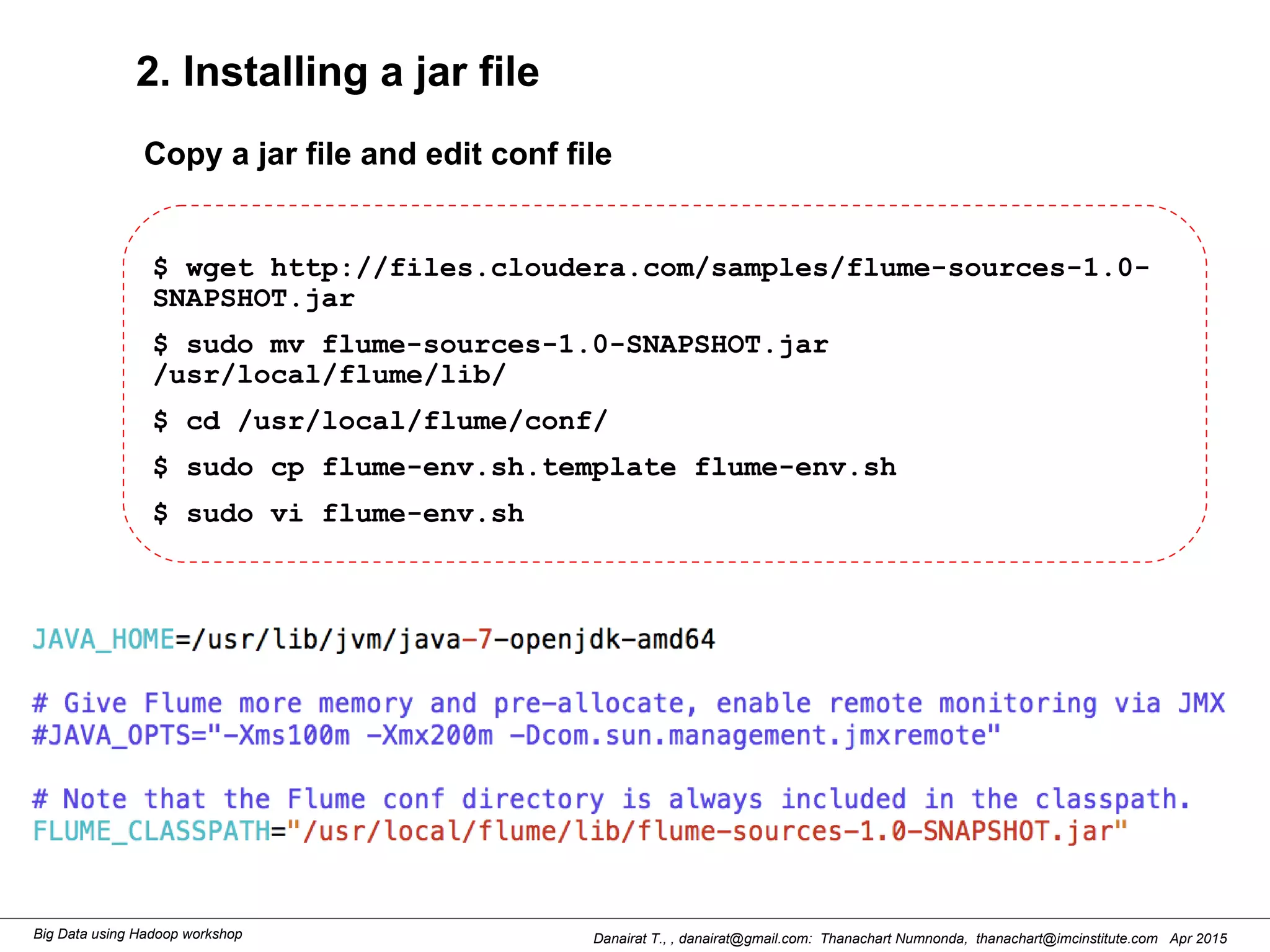
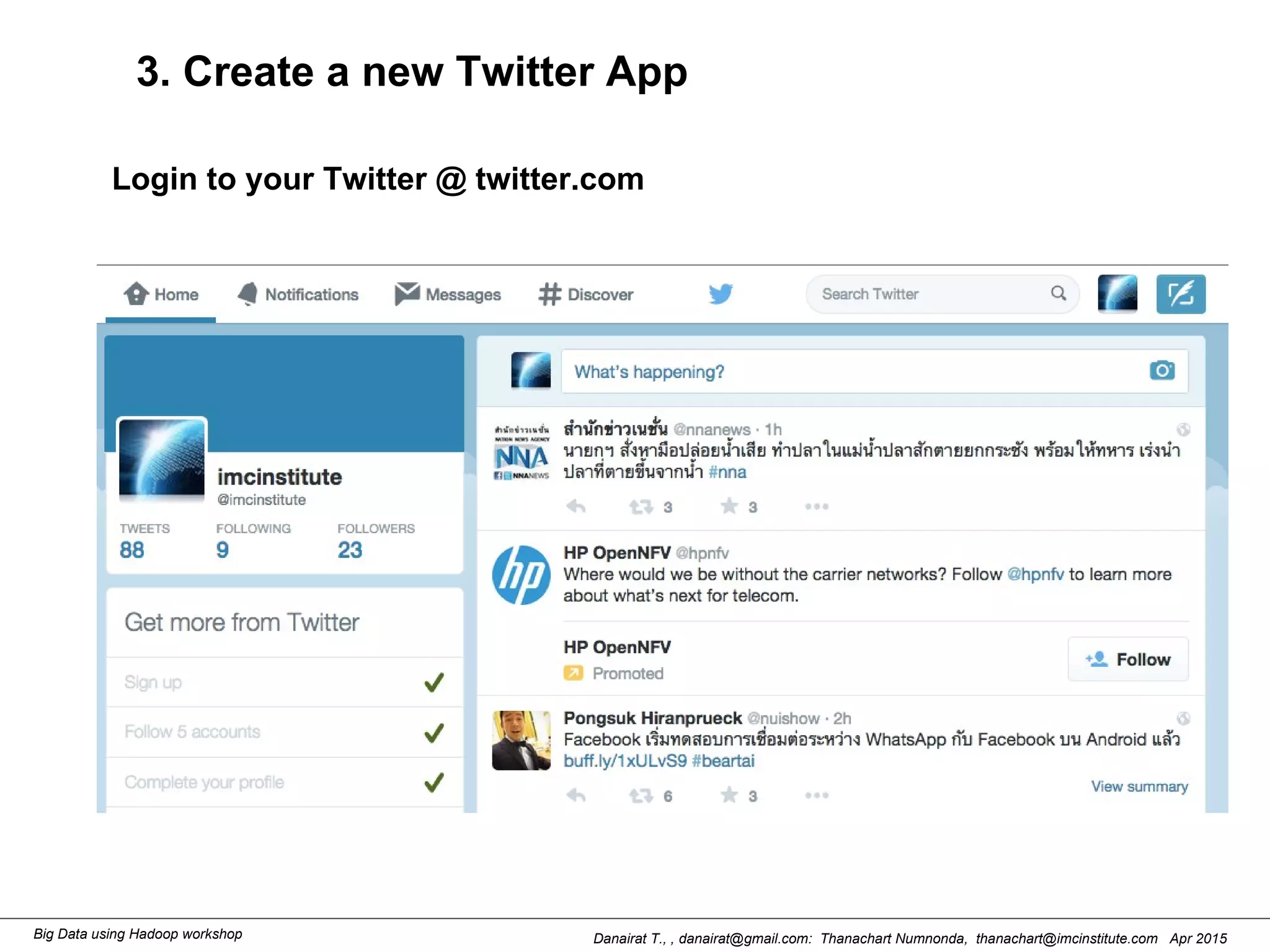
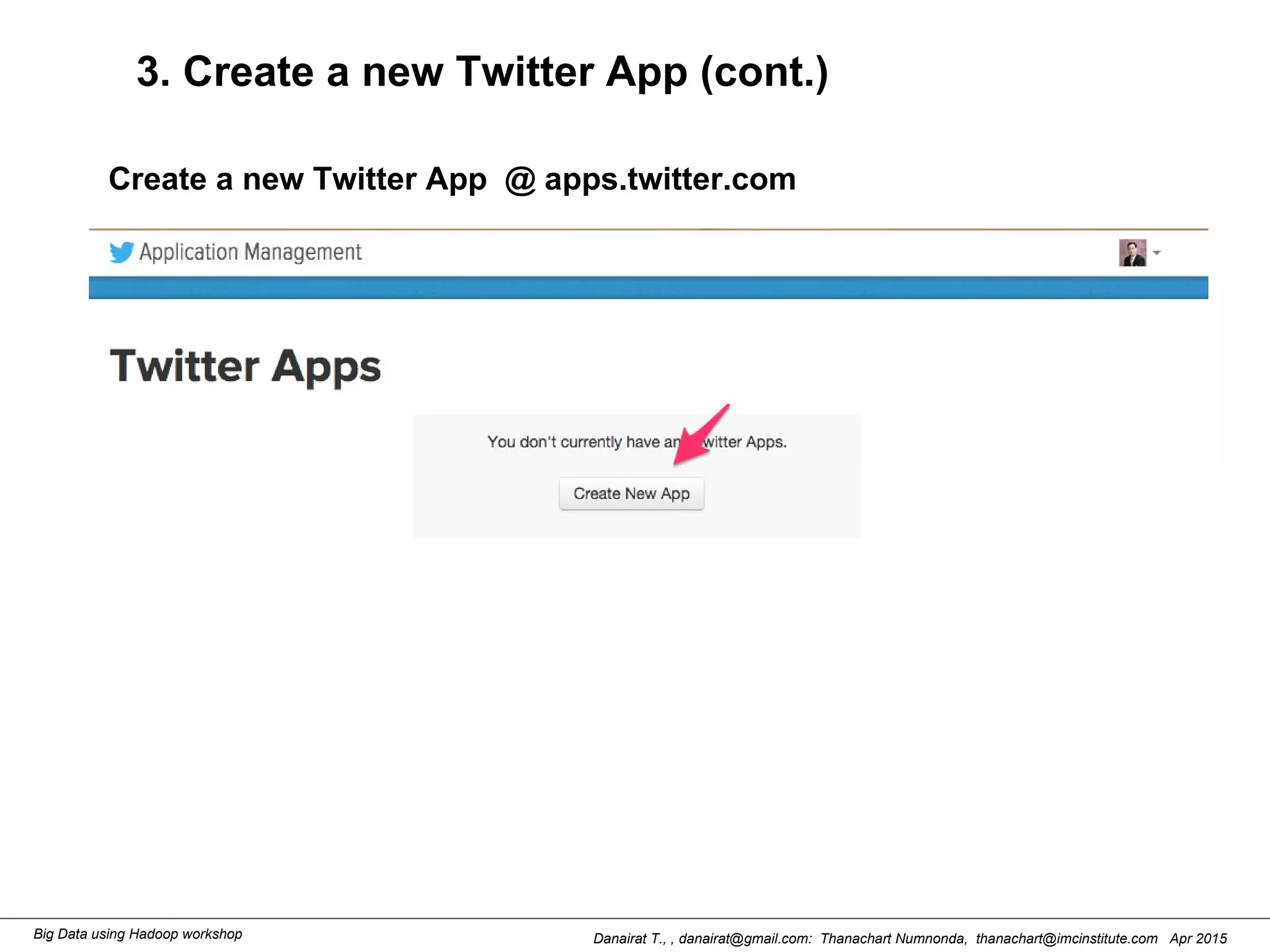
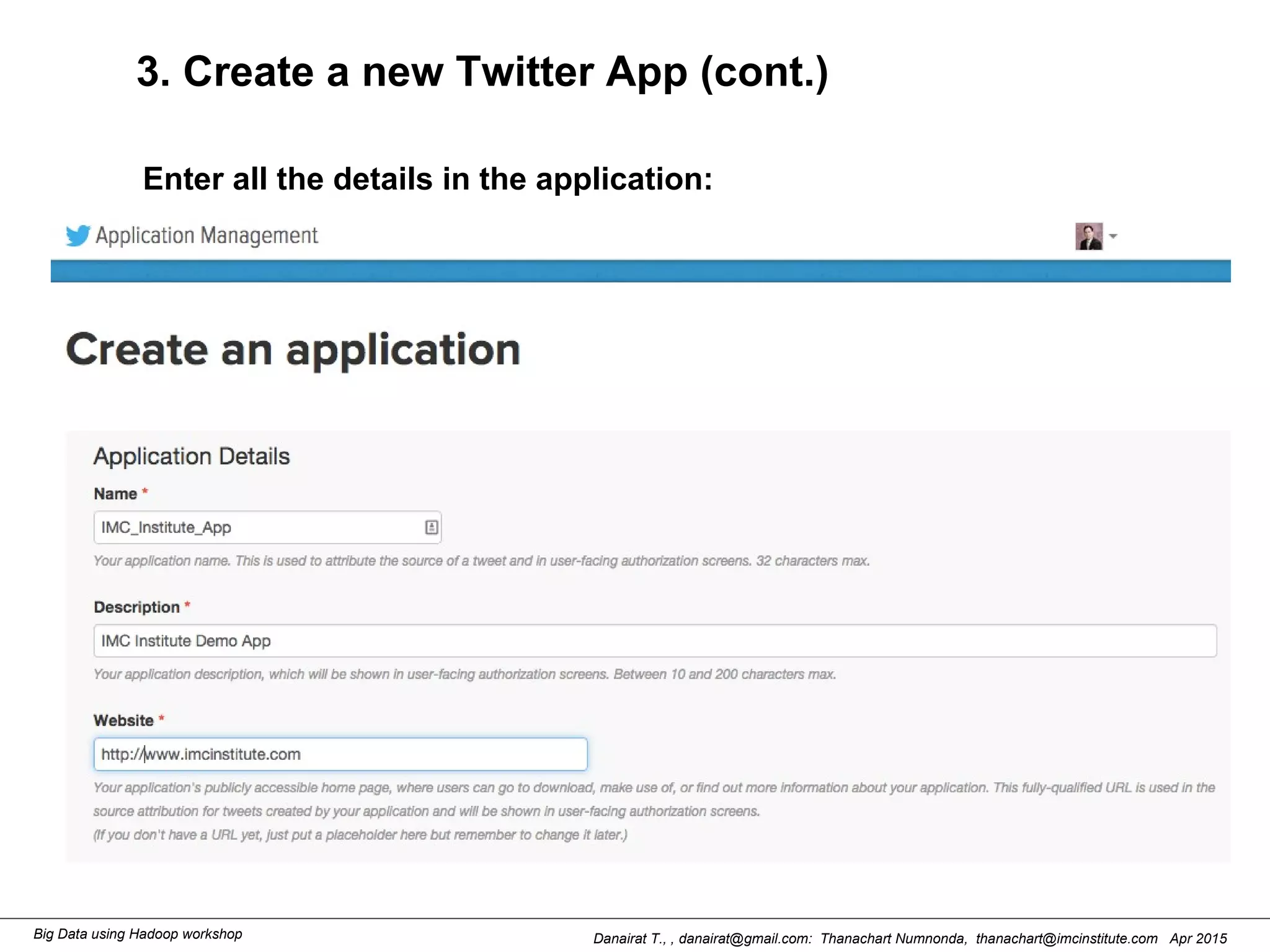
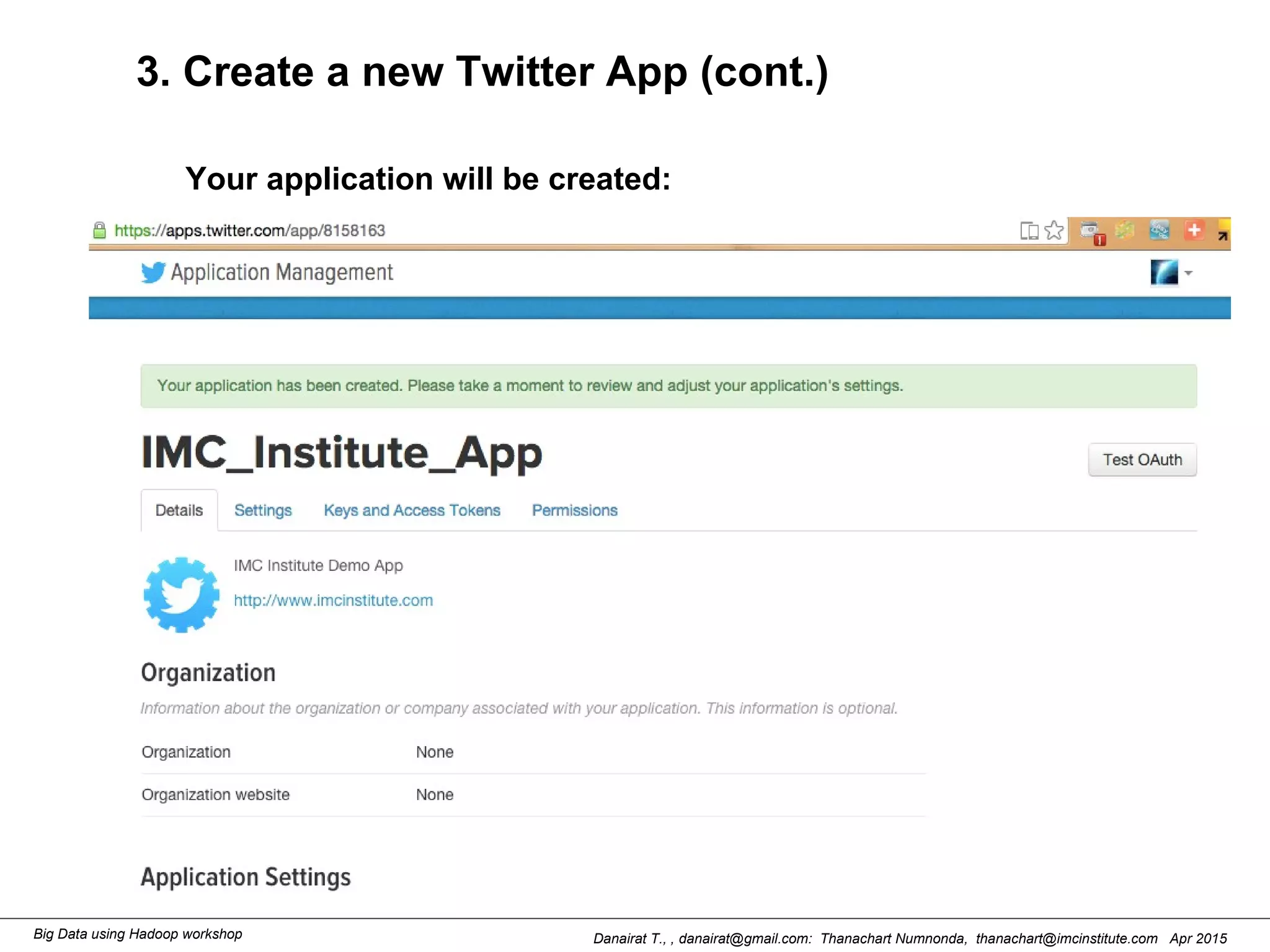
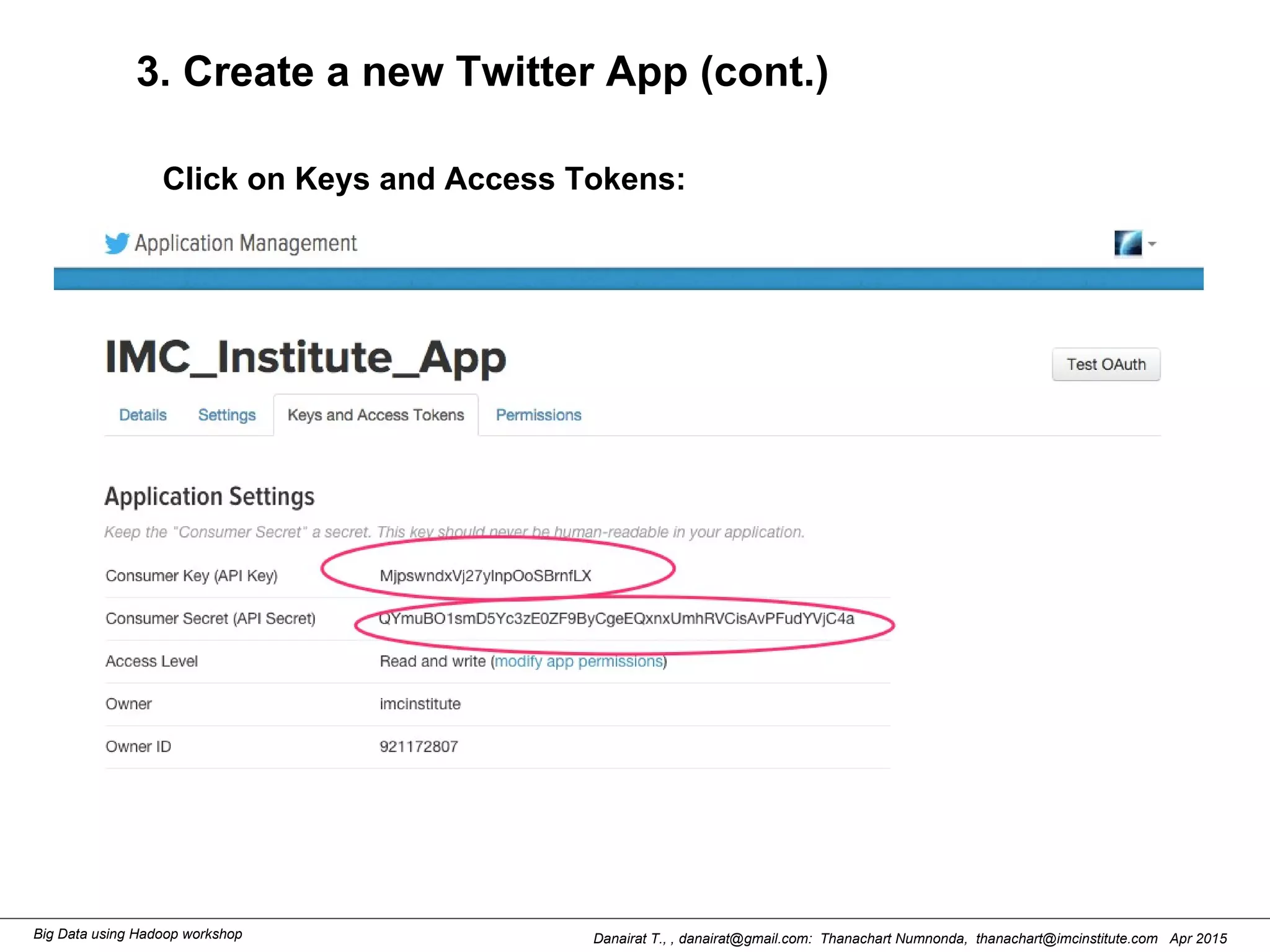
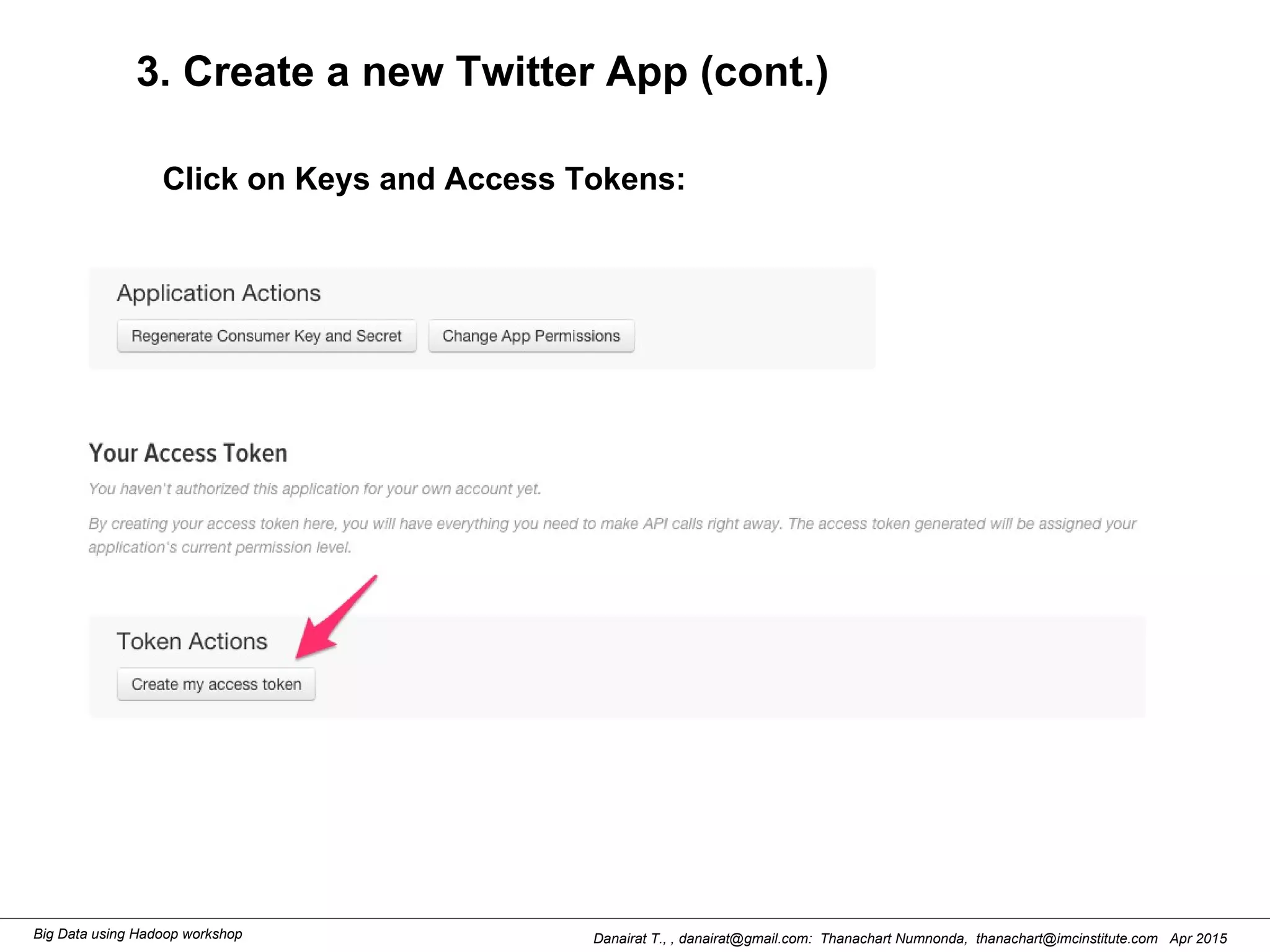
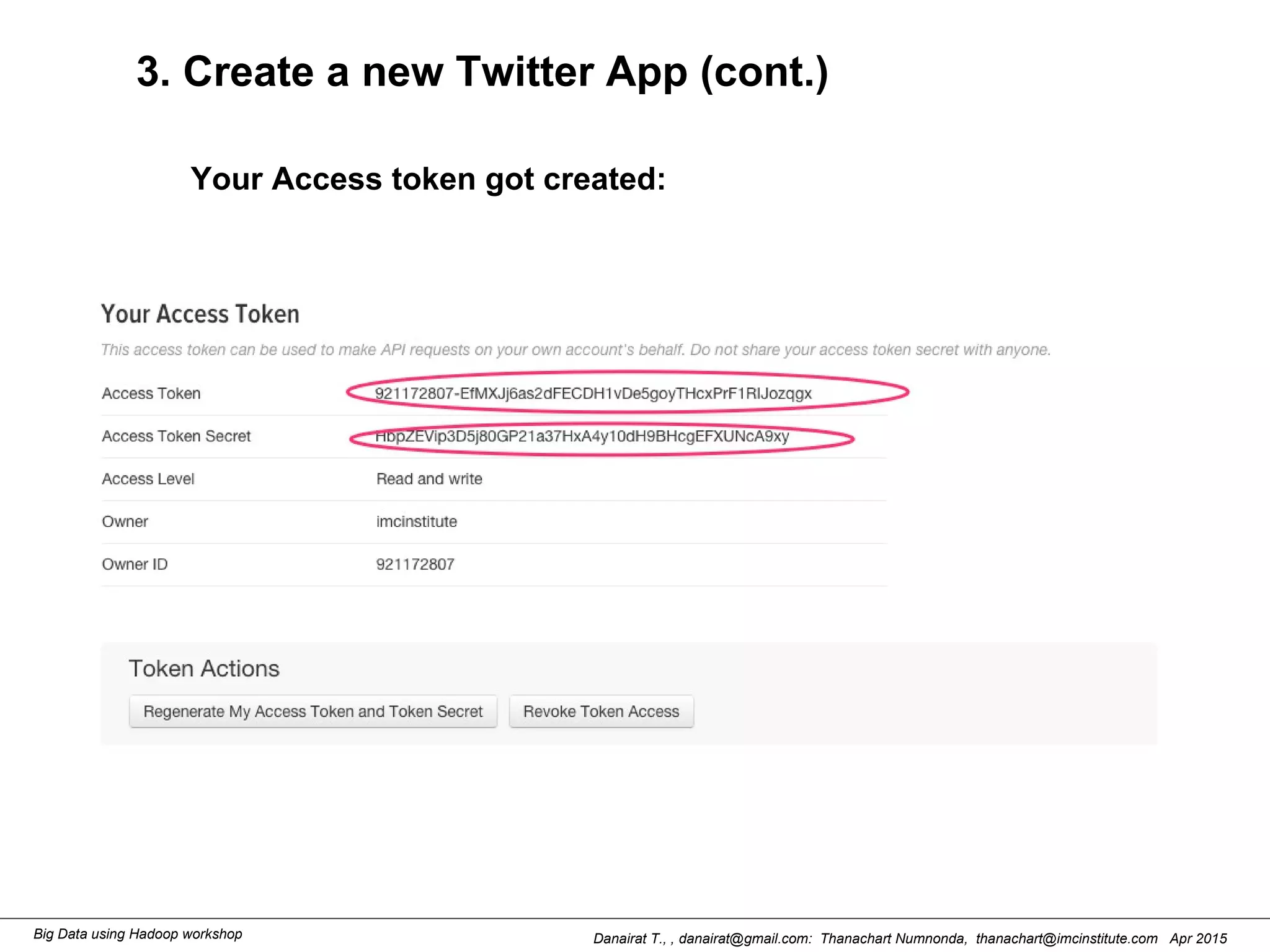



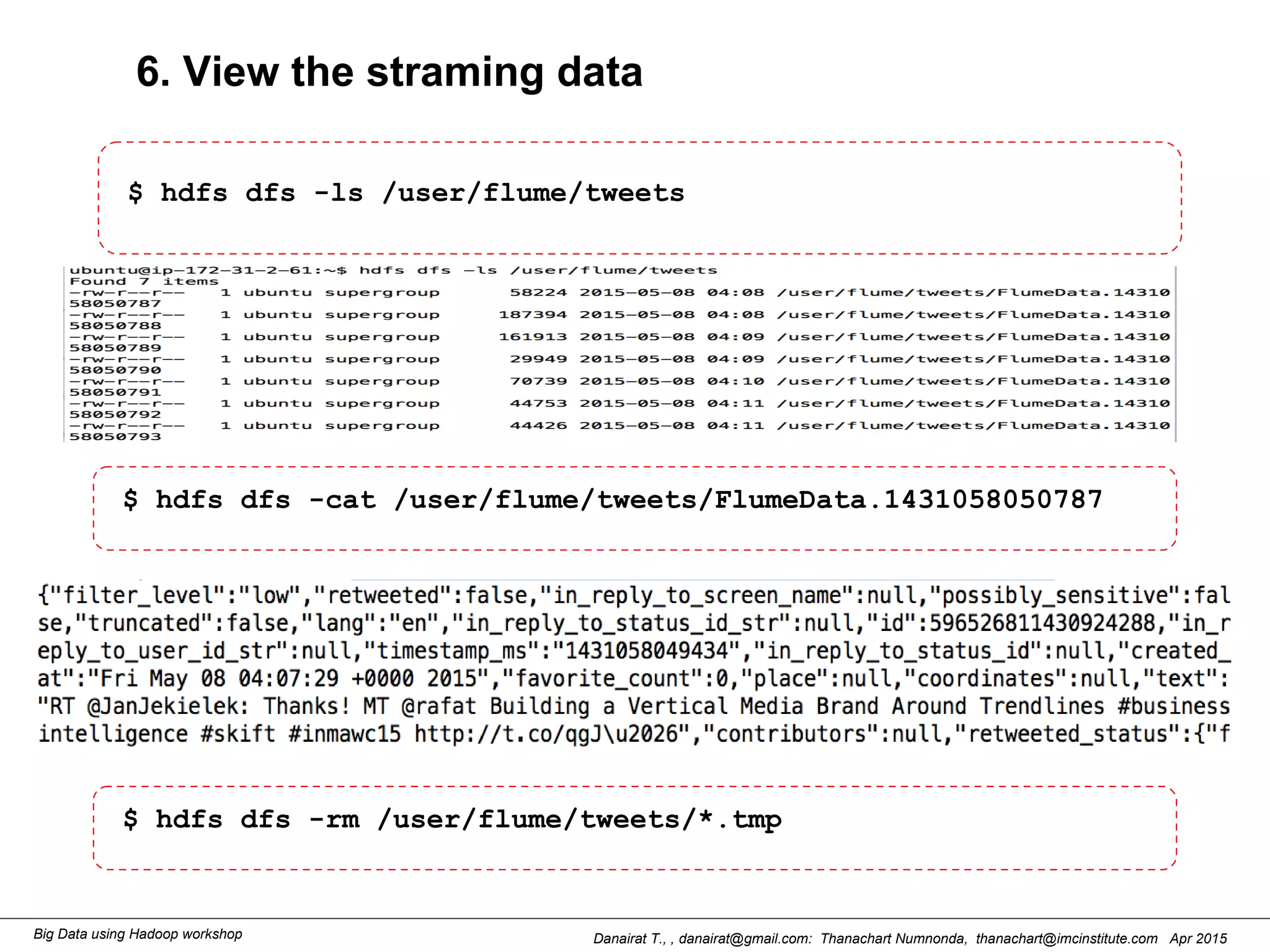

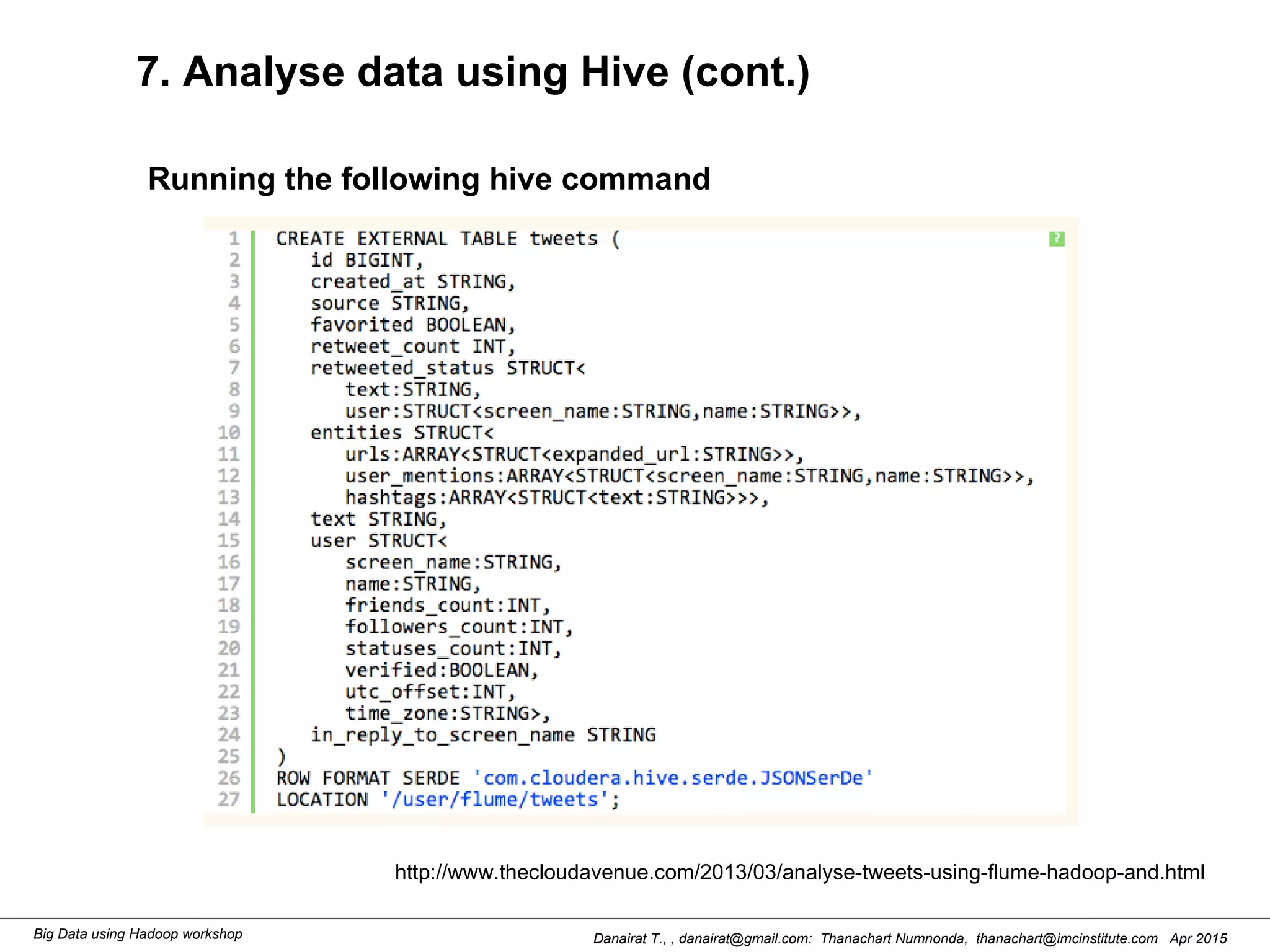
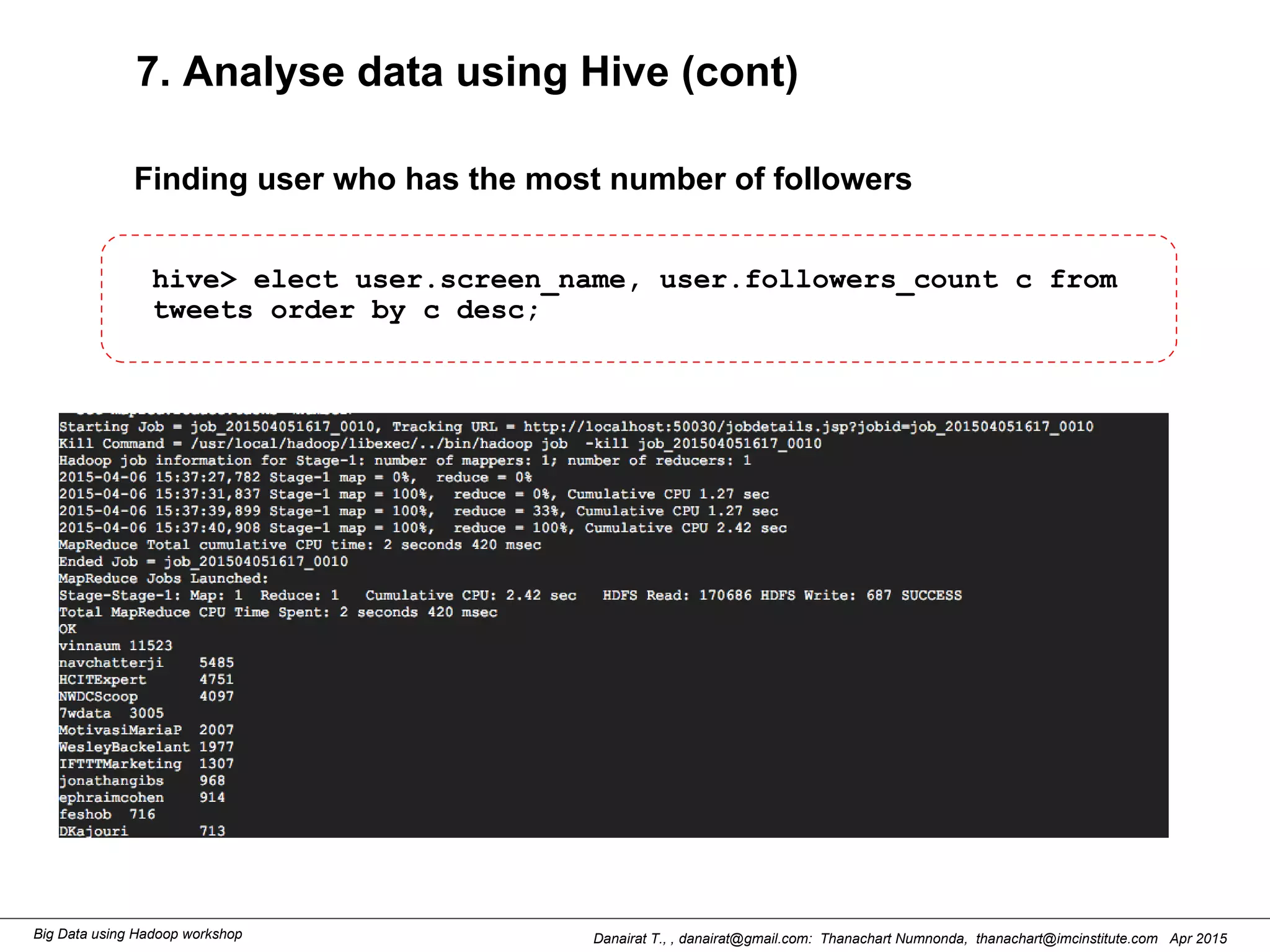


This document outlines steps to analyze tweets using Flume, Hadoop, and Hive. It describes installing Flume and a jar file, creating a Twitter application to get API keys, configuring an Flume agent to fetch tweets from Twitter and store in HDFS, and using Hive to analyze the tweets by user followers count. The workshop instructions provide commands to stream tweets from Twitter to HDFS using Flume, view the stored tweets files, and run queries in Hive to find the user with the most followers.
















![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![Reproducible datascience [with Terraform]](https://cdn.slidesharecdn.com/ss_thumbnails/reproduceabledatascience1-180630074643-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




