Downloaded 52 times



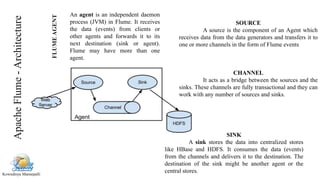


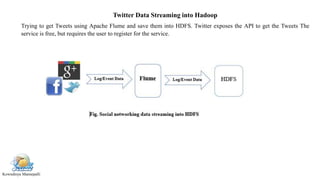







Apache Flume is a distributed system for efficiently collecting large streams of log data into Hadoop. It has a simple architecture based on streaming data flows between sources, sinks, and channels. An agent contains a source that collects data, a channel that buffers the data, and a sink that stores it. This document demonstrates how to install Flume, configure it to collect tweets from Twitter using the Twitter streaming API, and save the tweets to HDFS.



















































































