Downloaded 46 times




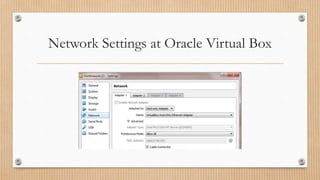
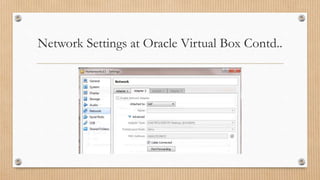

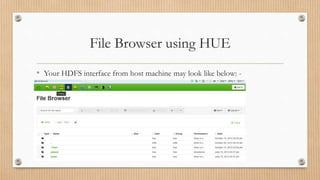






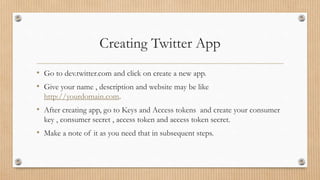








The document provides a comprehensive guide on extracting Twitter data using Apache Flume within a Hortonworks Hadoop cluster, detailing required tools and setup steps. It includes instructions on configuring Flume, creating necessary JAR files, and establishing a Twitter application for data access. The document also addresses troubleshooting common errors encountered during the Flume runtime process.























![OSSV [Open System SnapVault]](https://cdn.slidesharecdn.com/ss_thumbnails/opensystemsnapvault-130324172219-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































