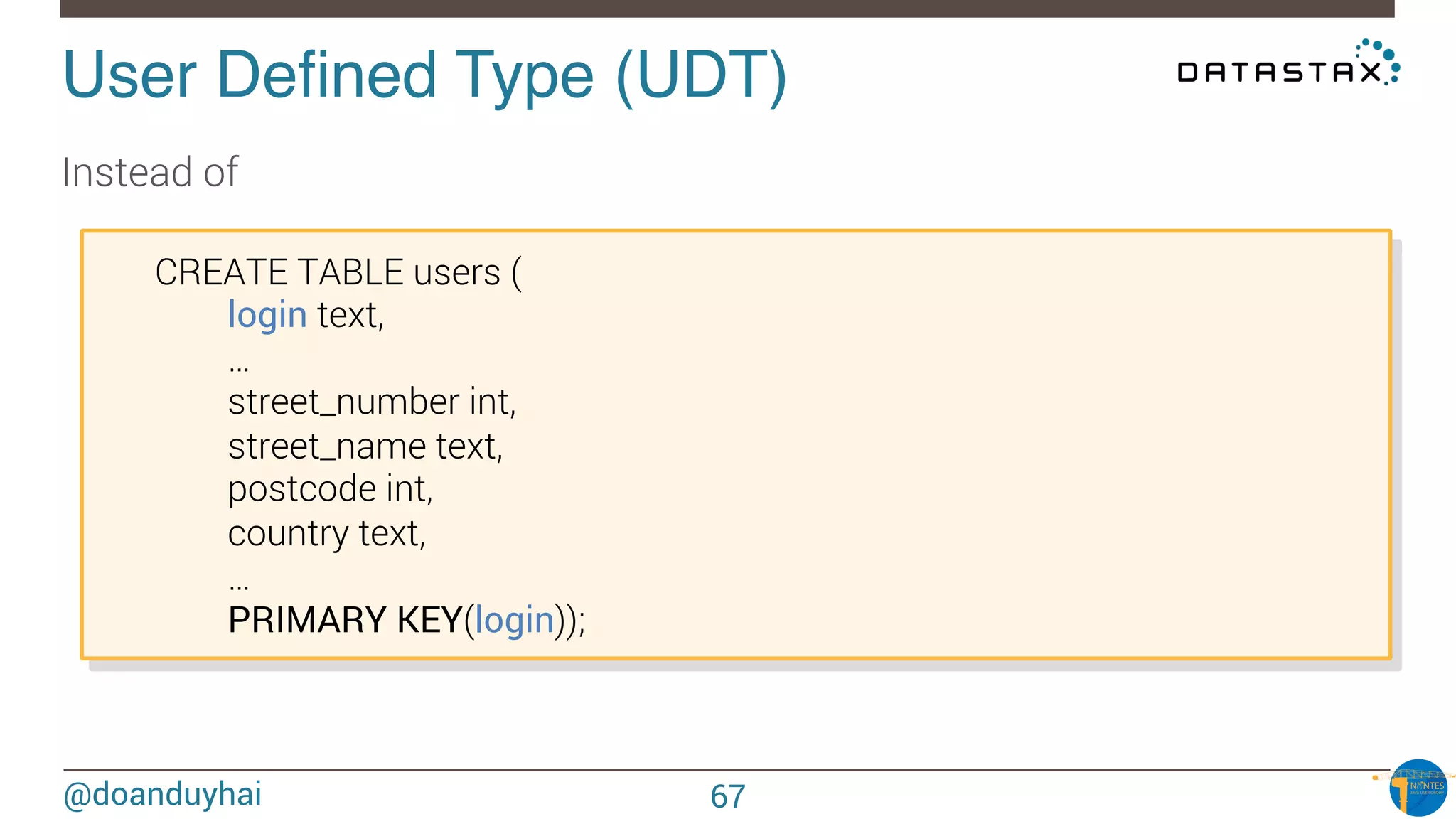
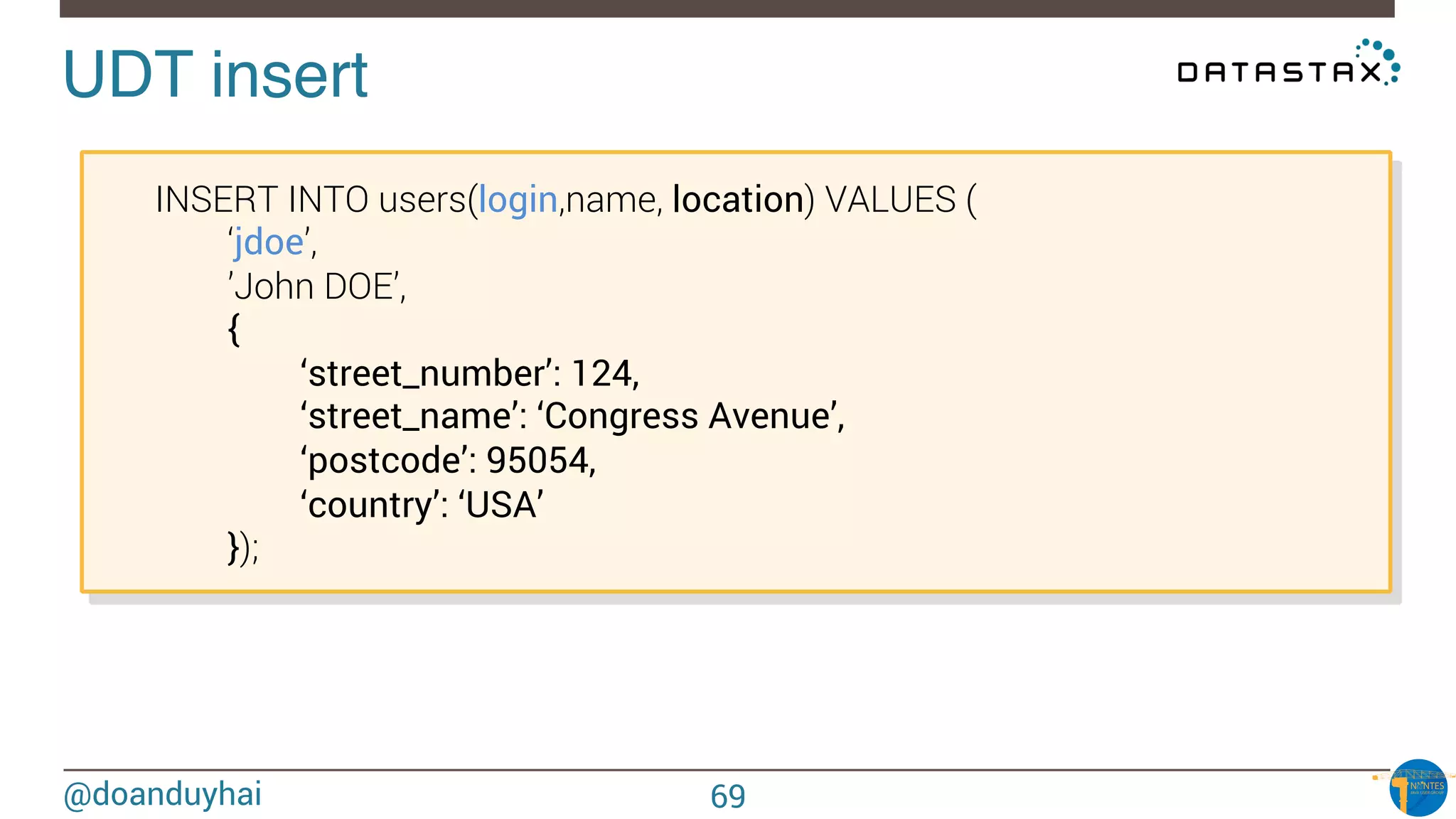
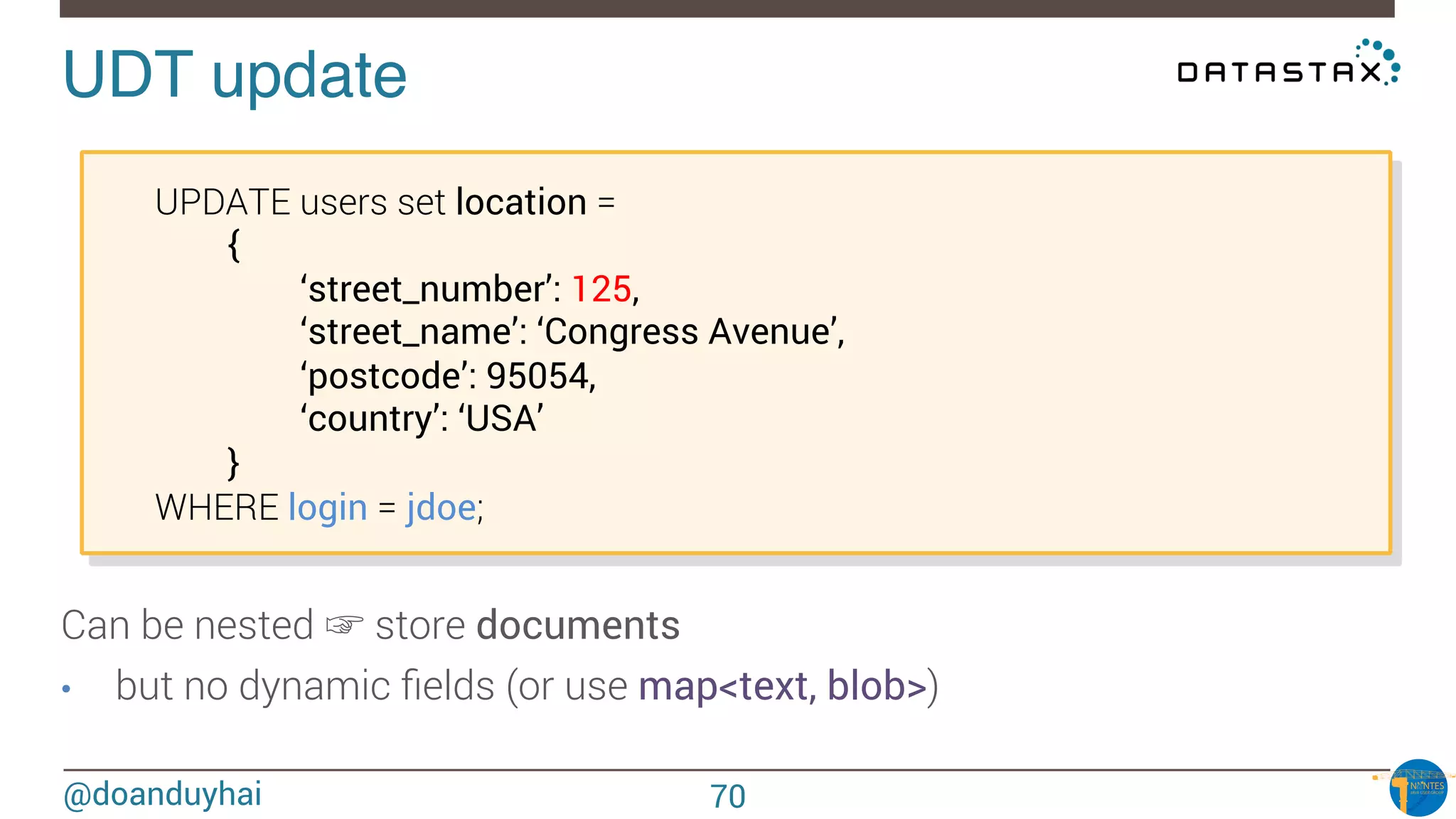
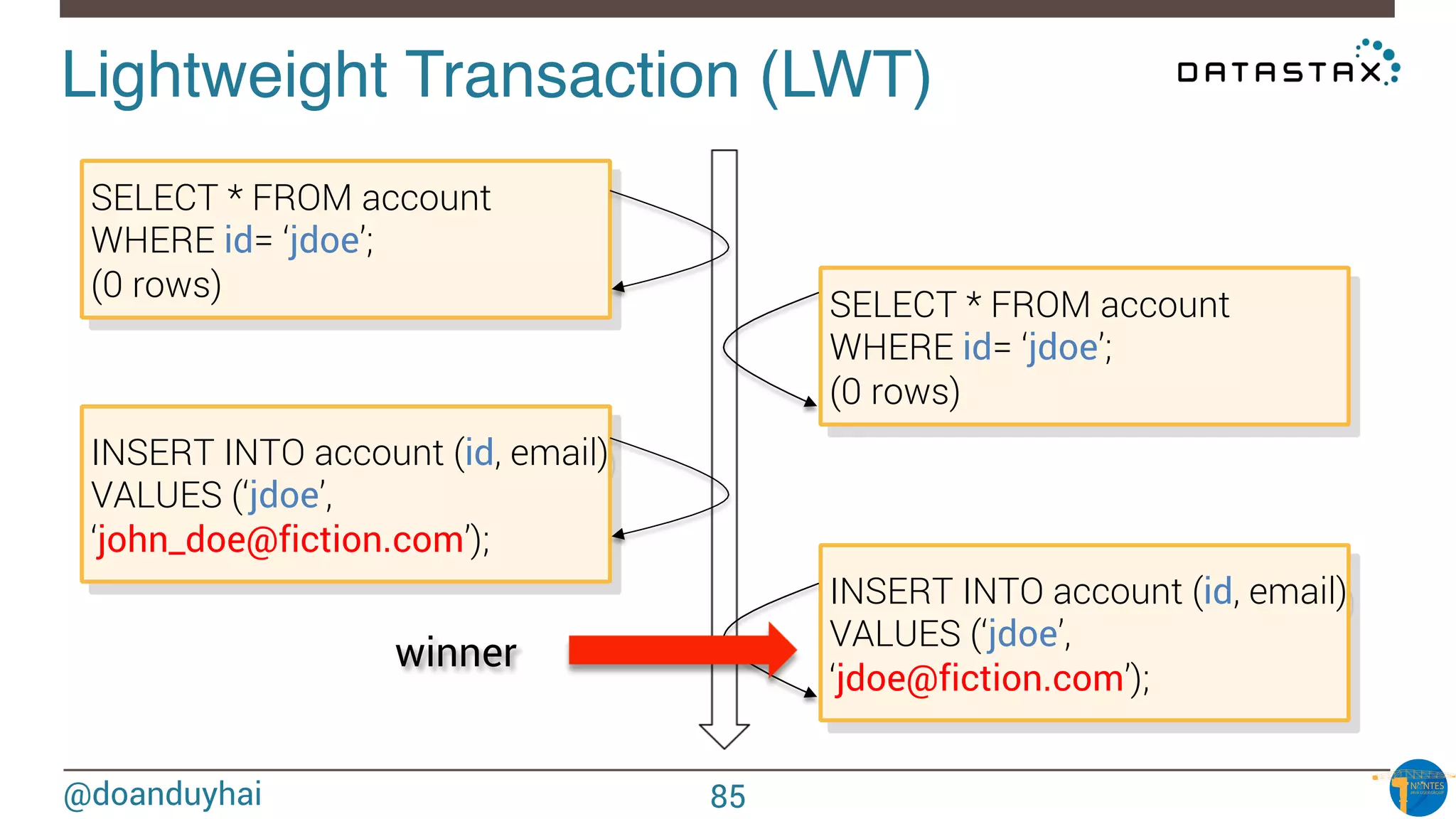
Downloaded 27 times










![@doanduyhai
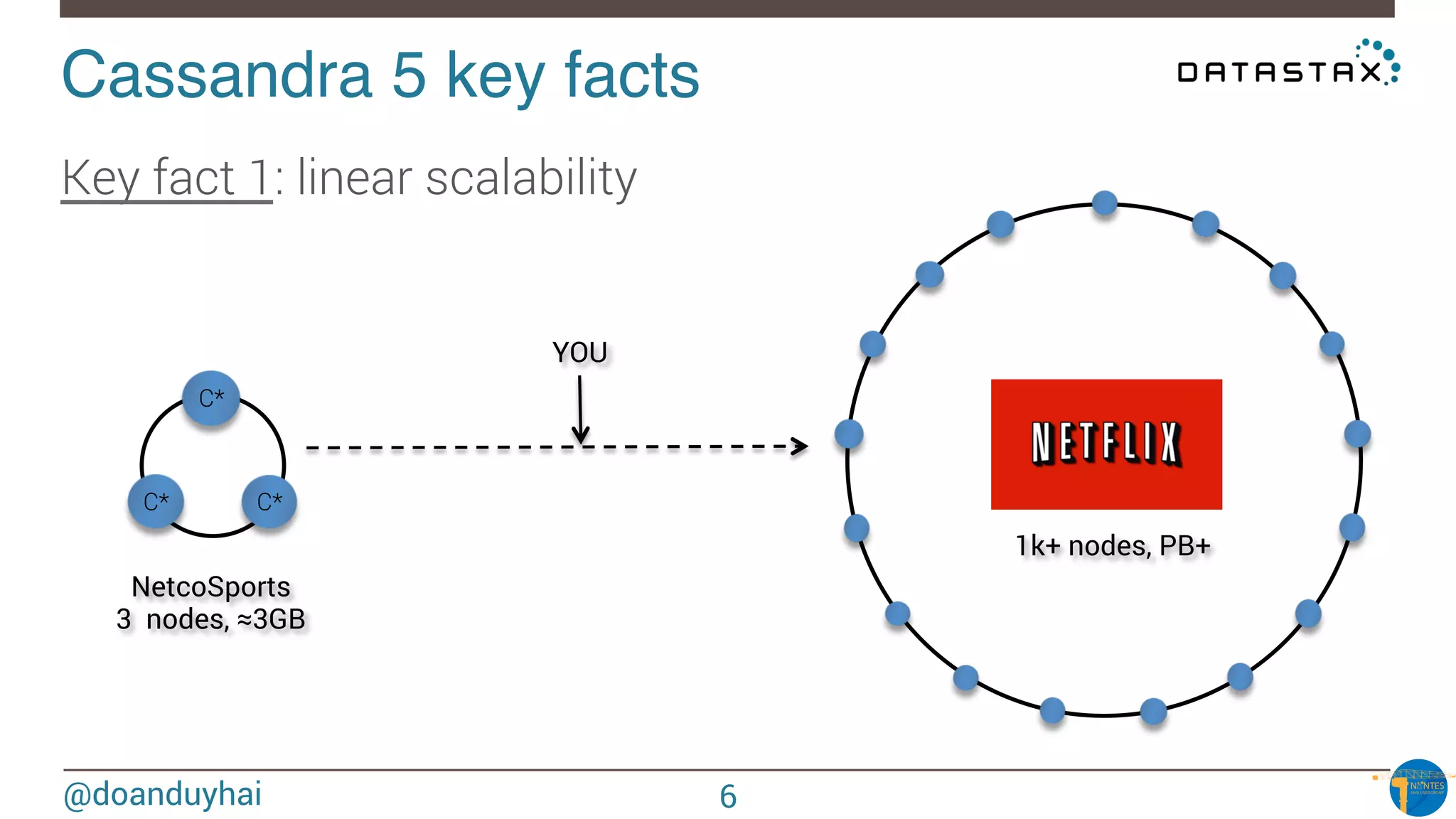
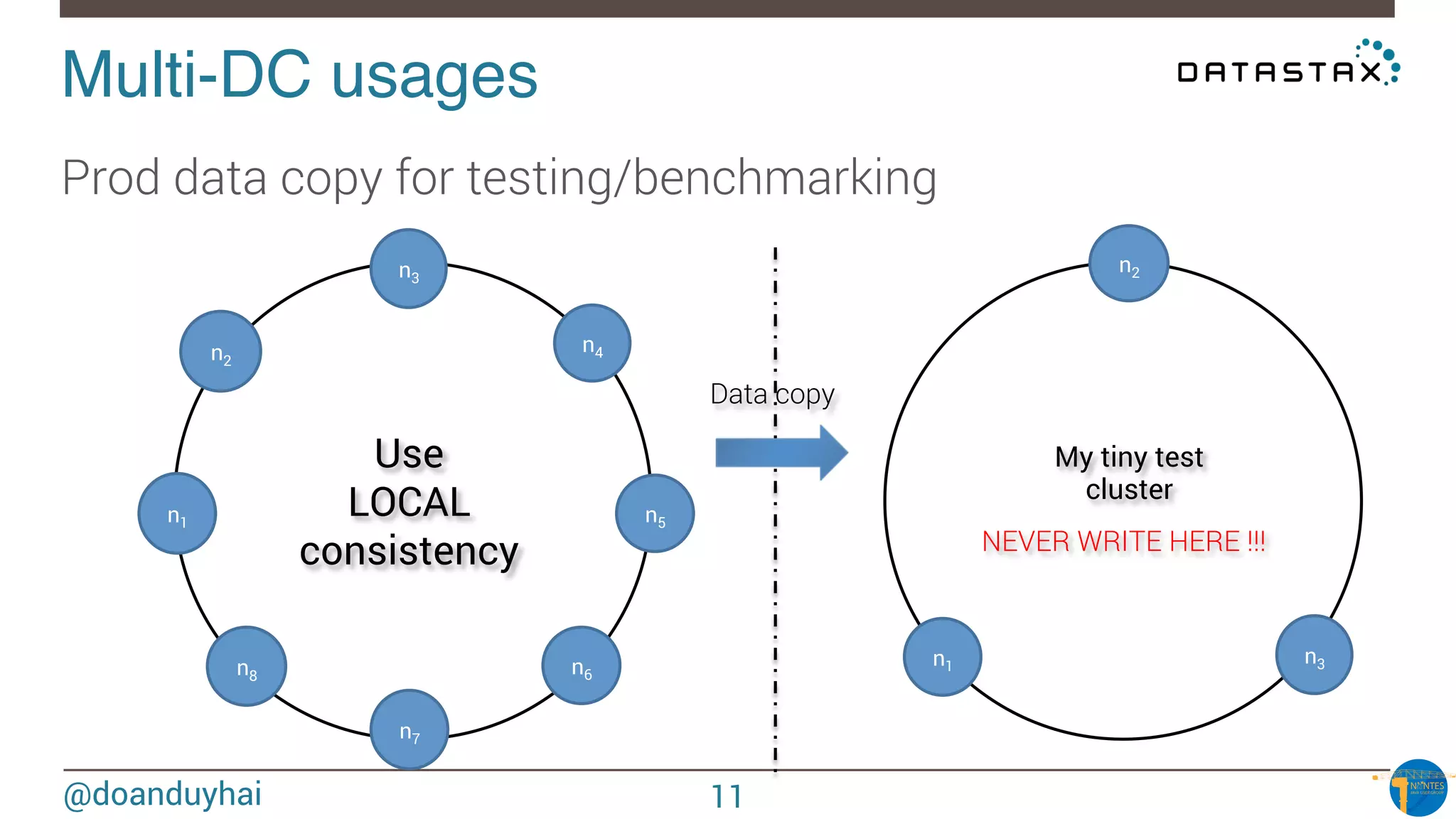
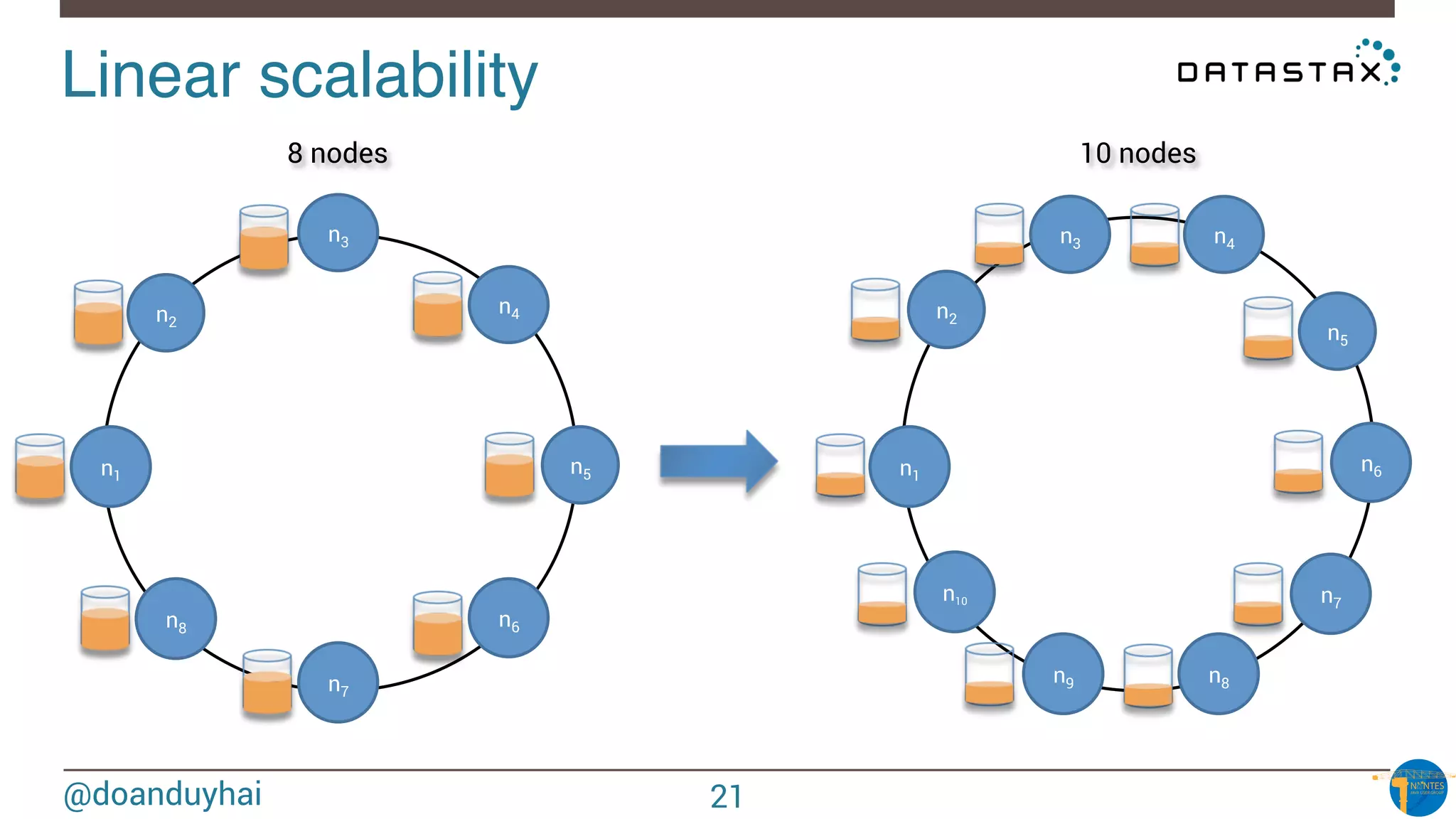
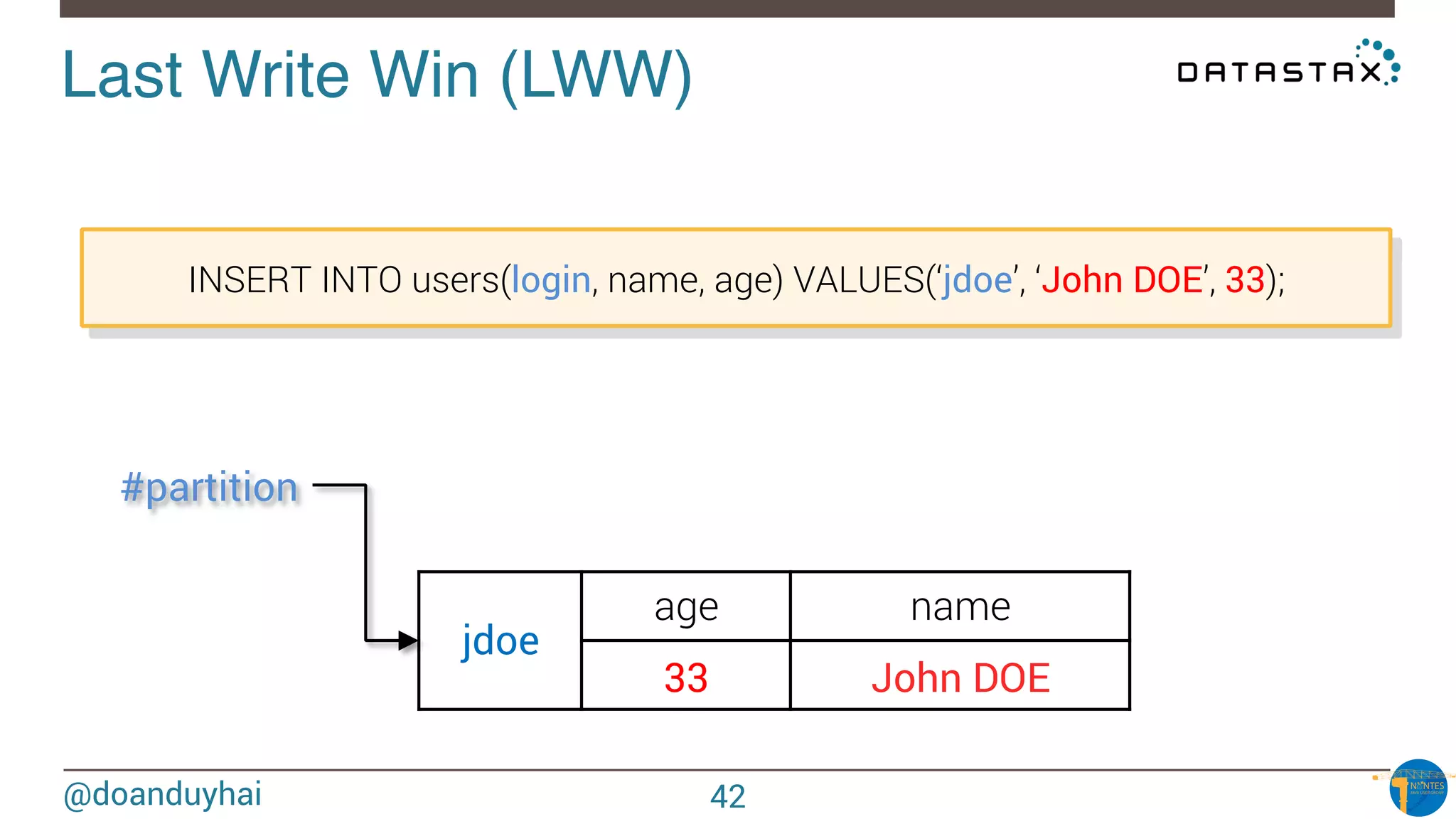
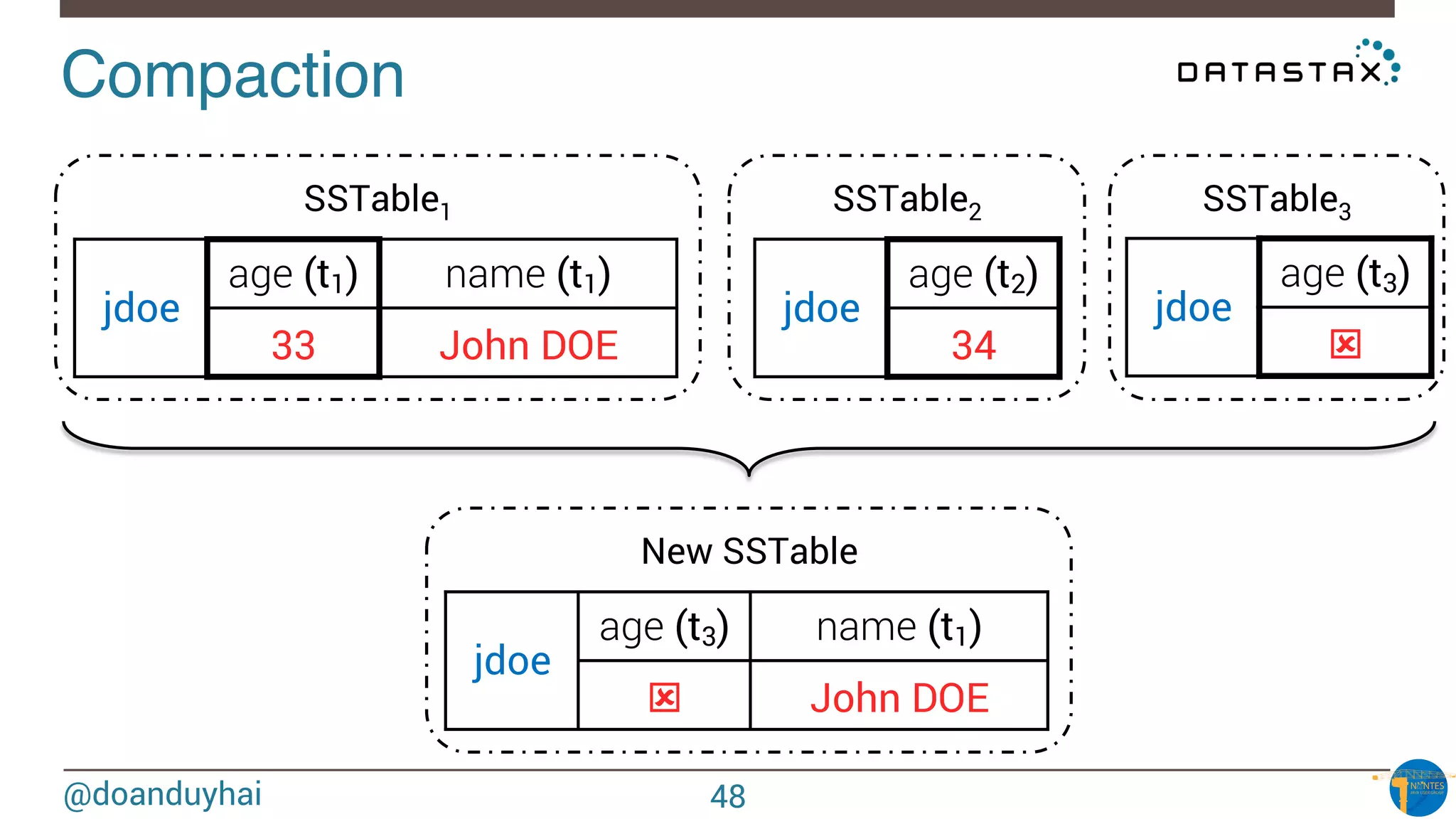
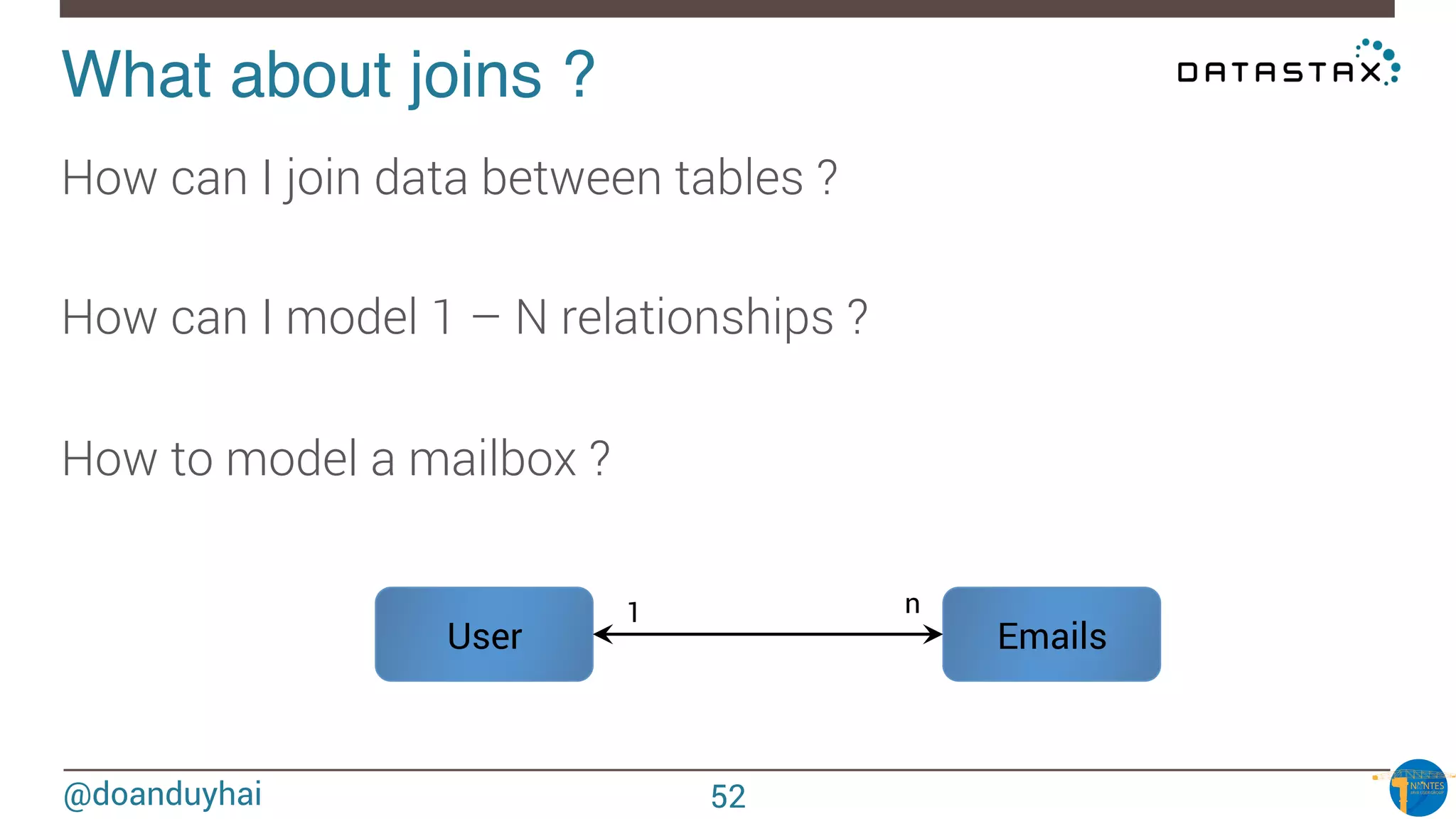
Data distribution!
Random: hash of #partition → token = hash(#p)
Hash: ]-X, X]
X = huge number (264/2)
n1
n2
n3
n4
n5
n6
n7
n8
17](https://image.slidesharecdn.com/cassandraintroductionnantesjug-150312103950-conversion-gate01/75/Cassandra-introduction-NantesJUG-17-2048.jpg)
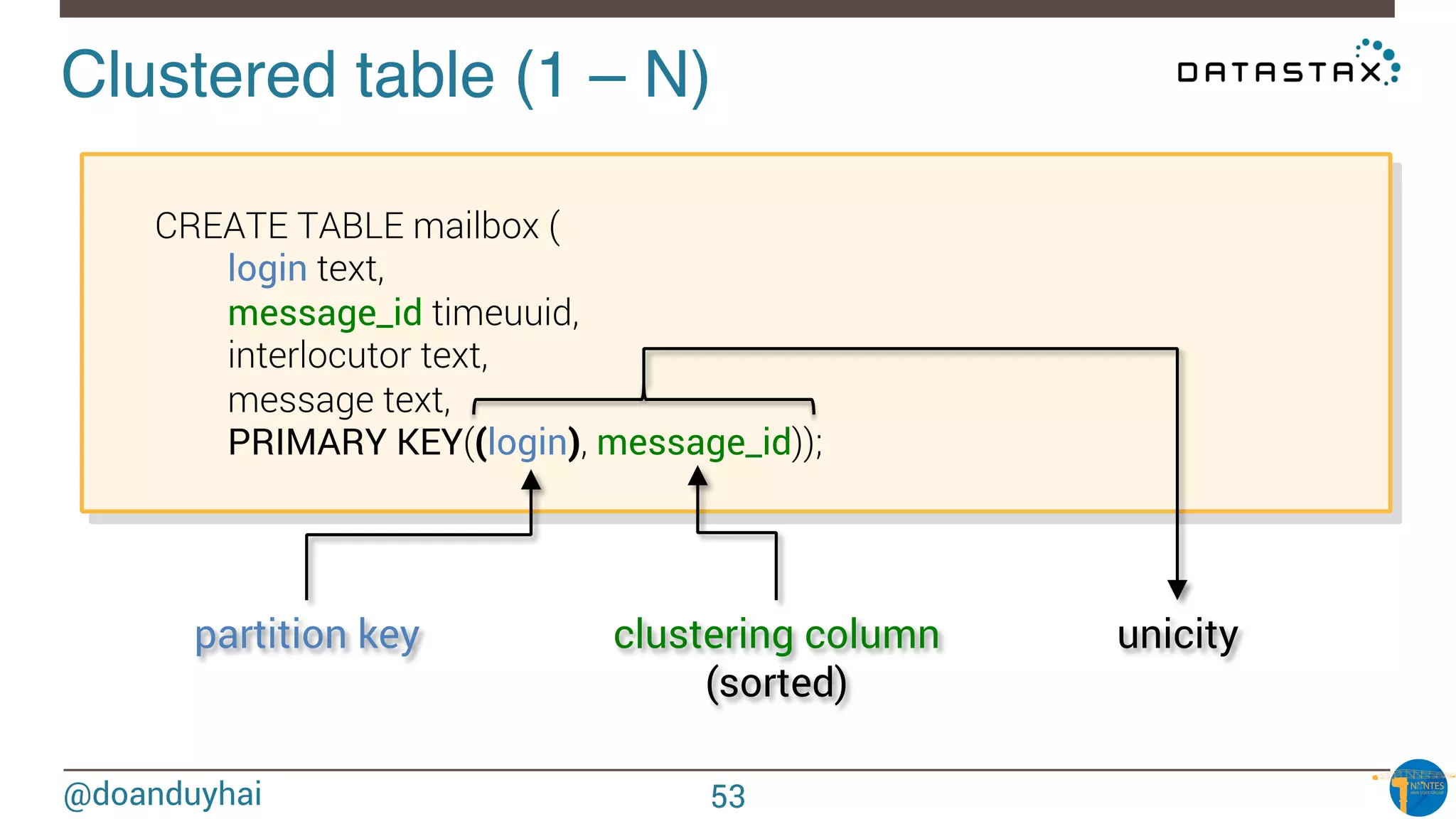
![@doanduyhai
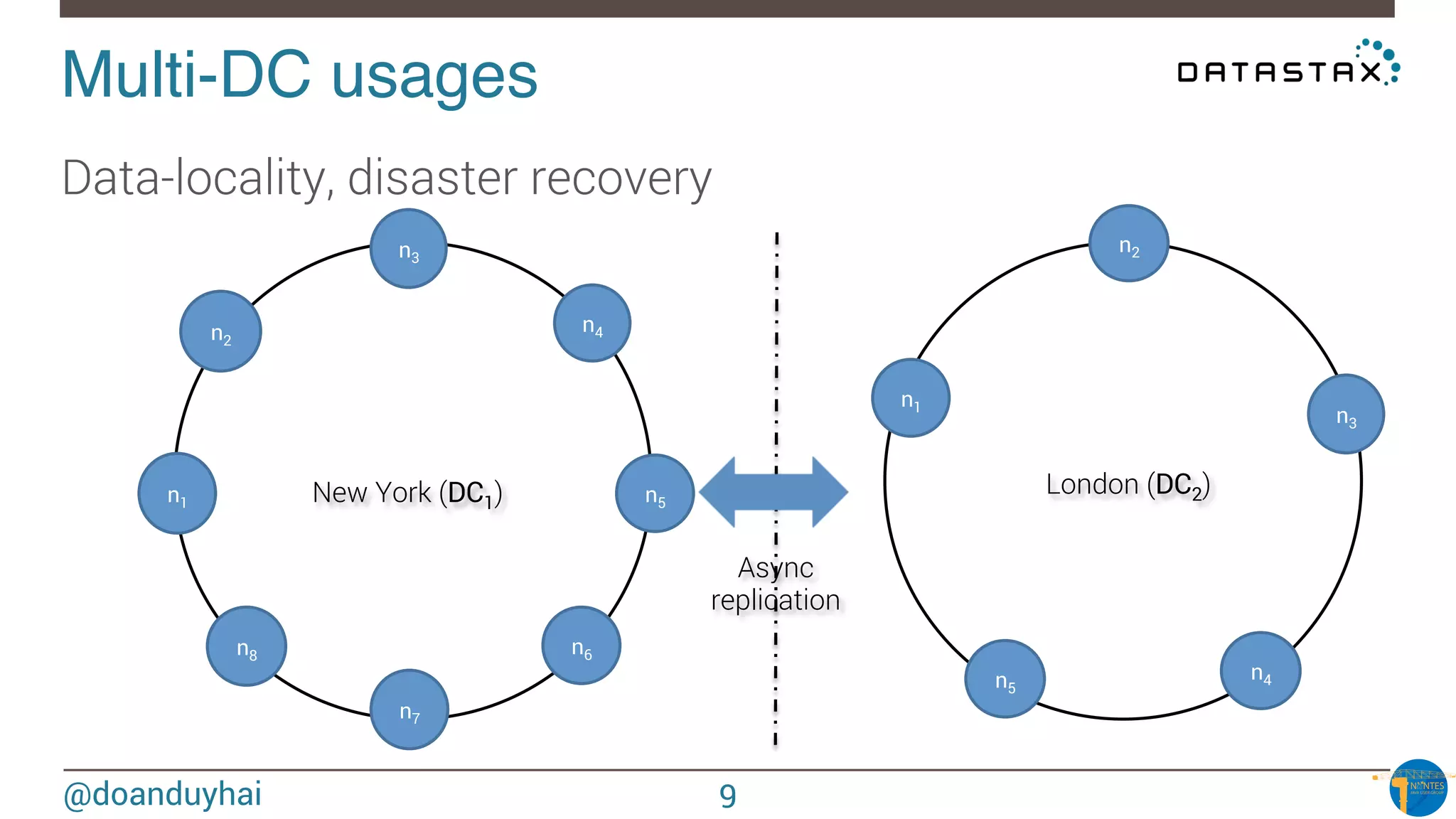
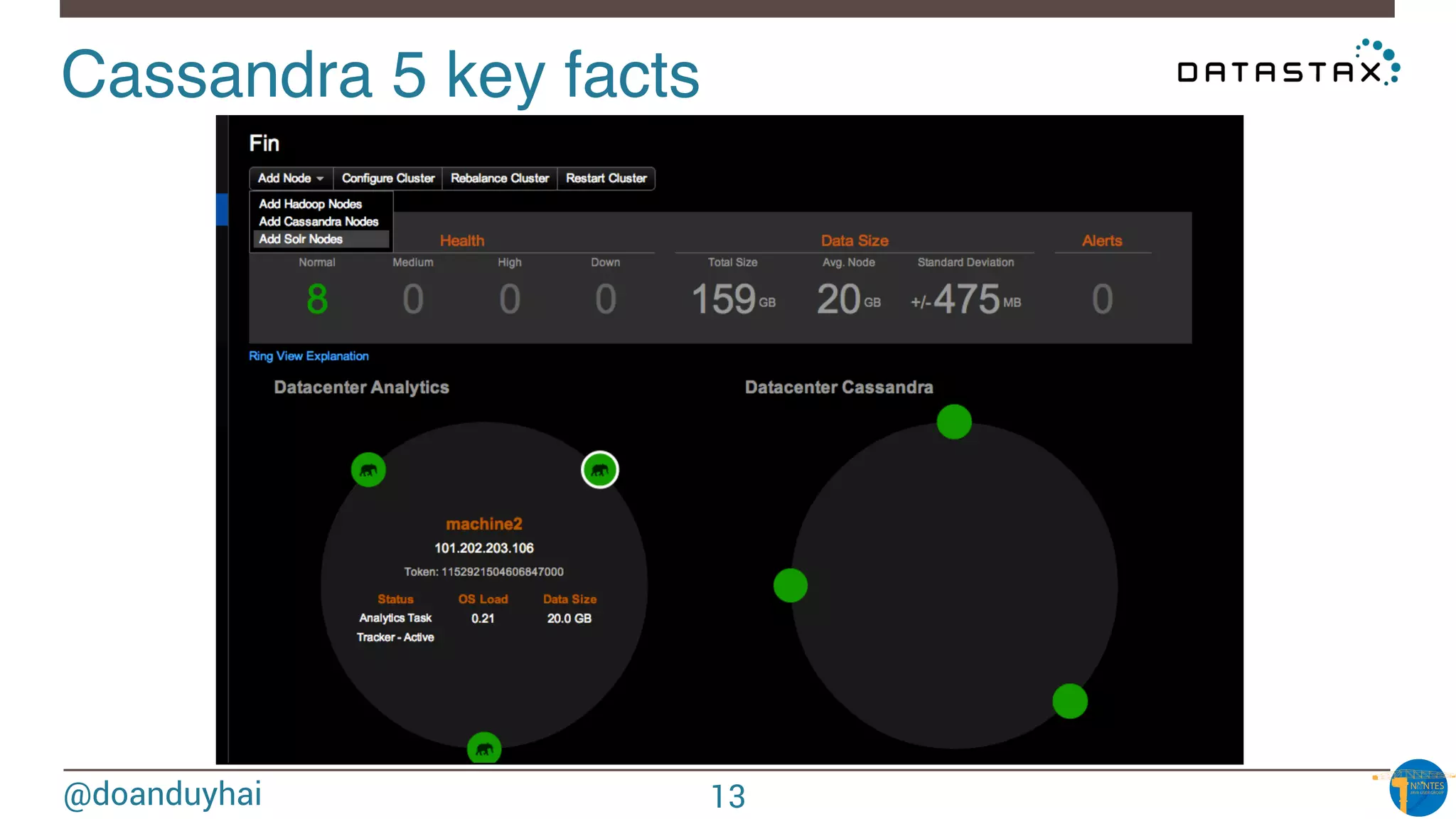
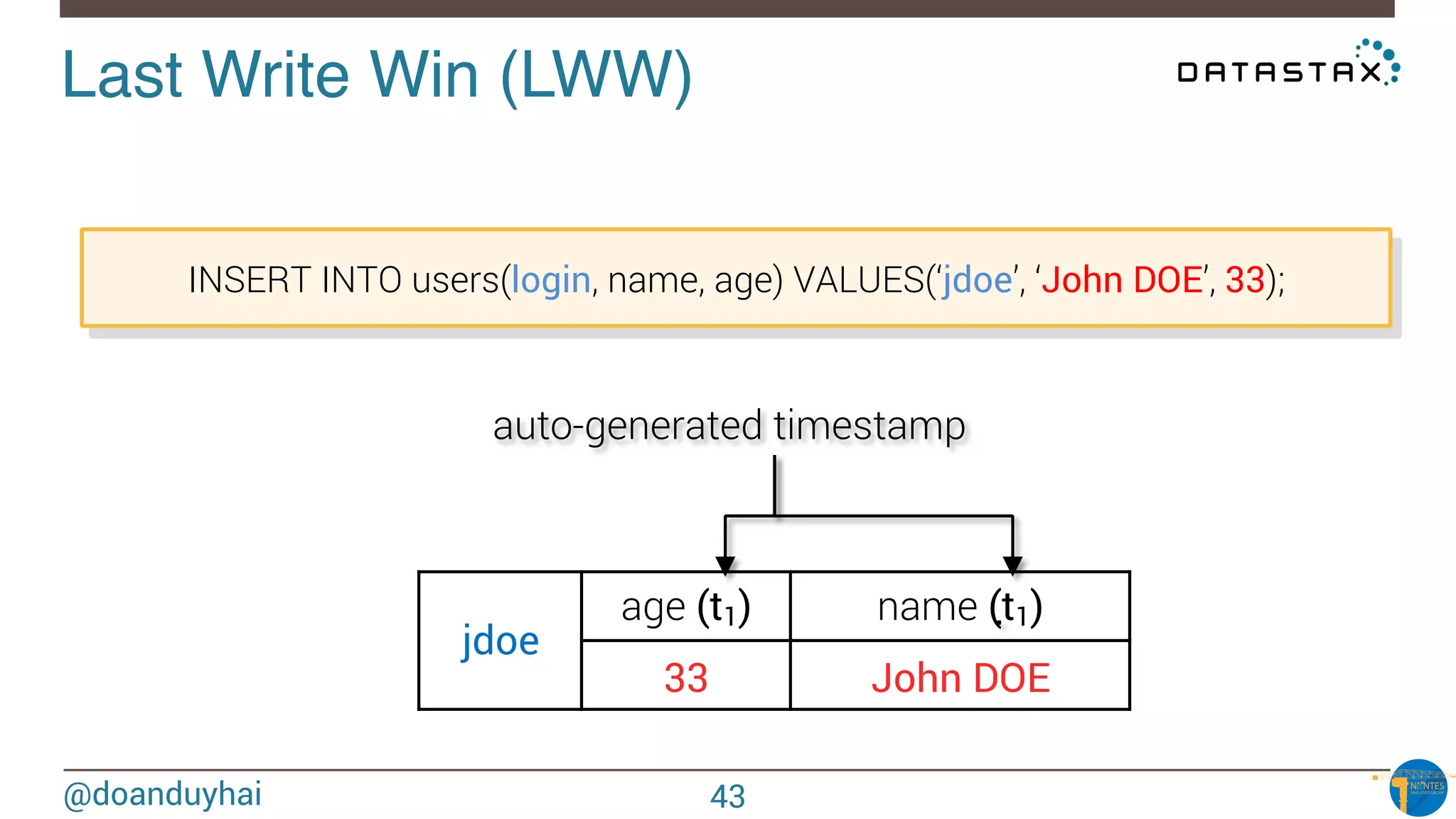
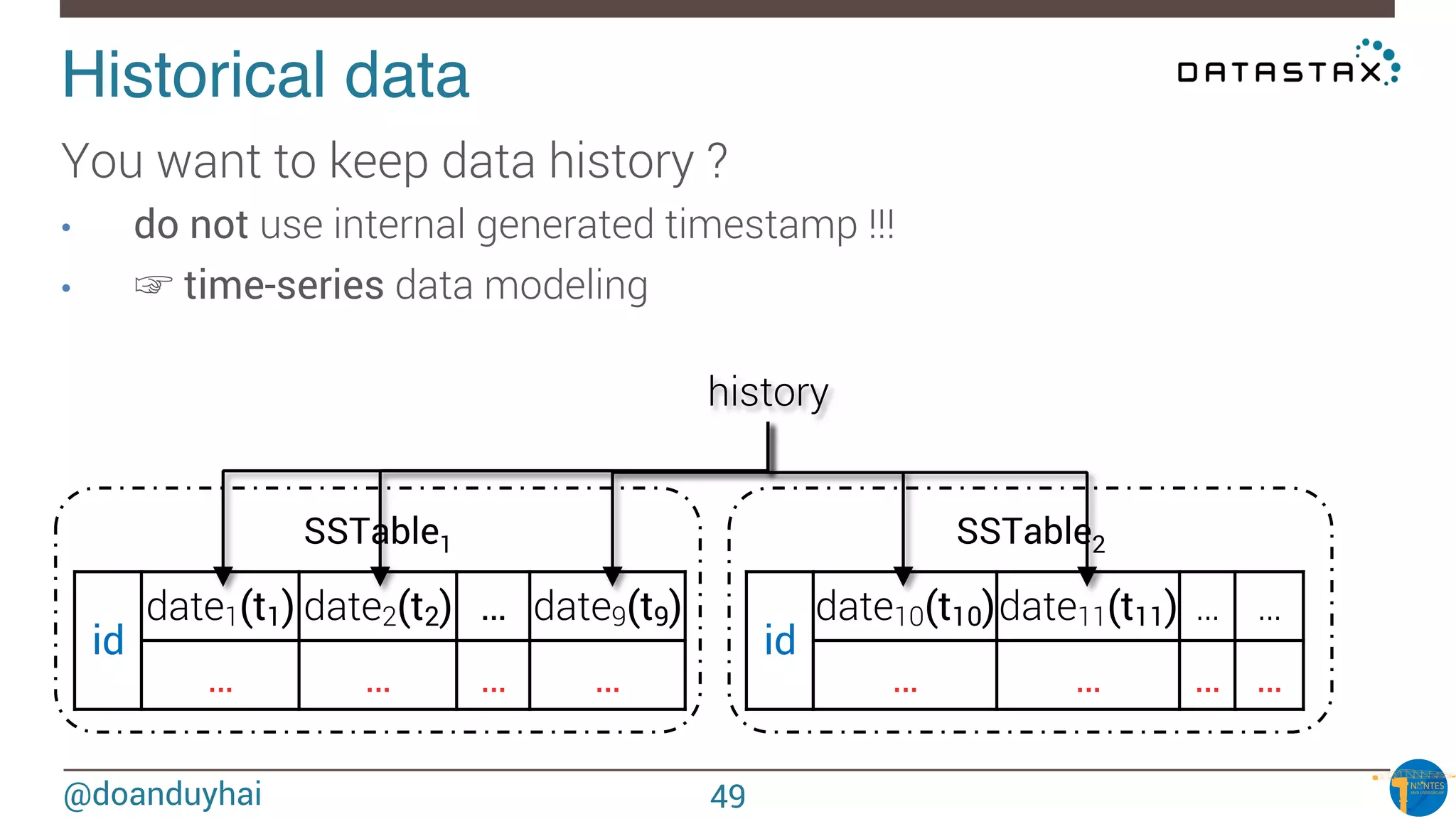
Token Ranges!
A: ]0, X/8]
B: ] X/8, 2X/8]
C: ] 2X/8, 3X/8]
D: ] 3X/8, 4X/8]
E: ] 4X/8, 5X/8]
F: ] 5X/8, 6X/8]
G: ] 6X/8, 7X/8]
H: ] 7X/8, X]
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
18](https://image.slidesharecdn.com/cassandraintroductionnantesjug-150312103950-conversion-gate01/75/Cassandra-introduction-NantesJUG-18-2048.jpg)

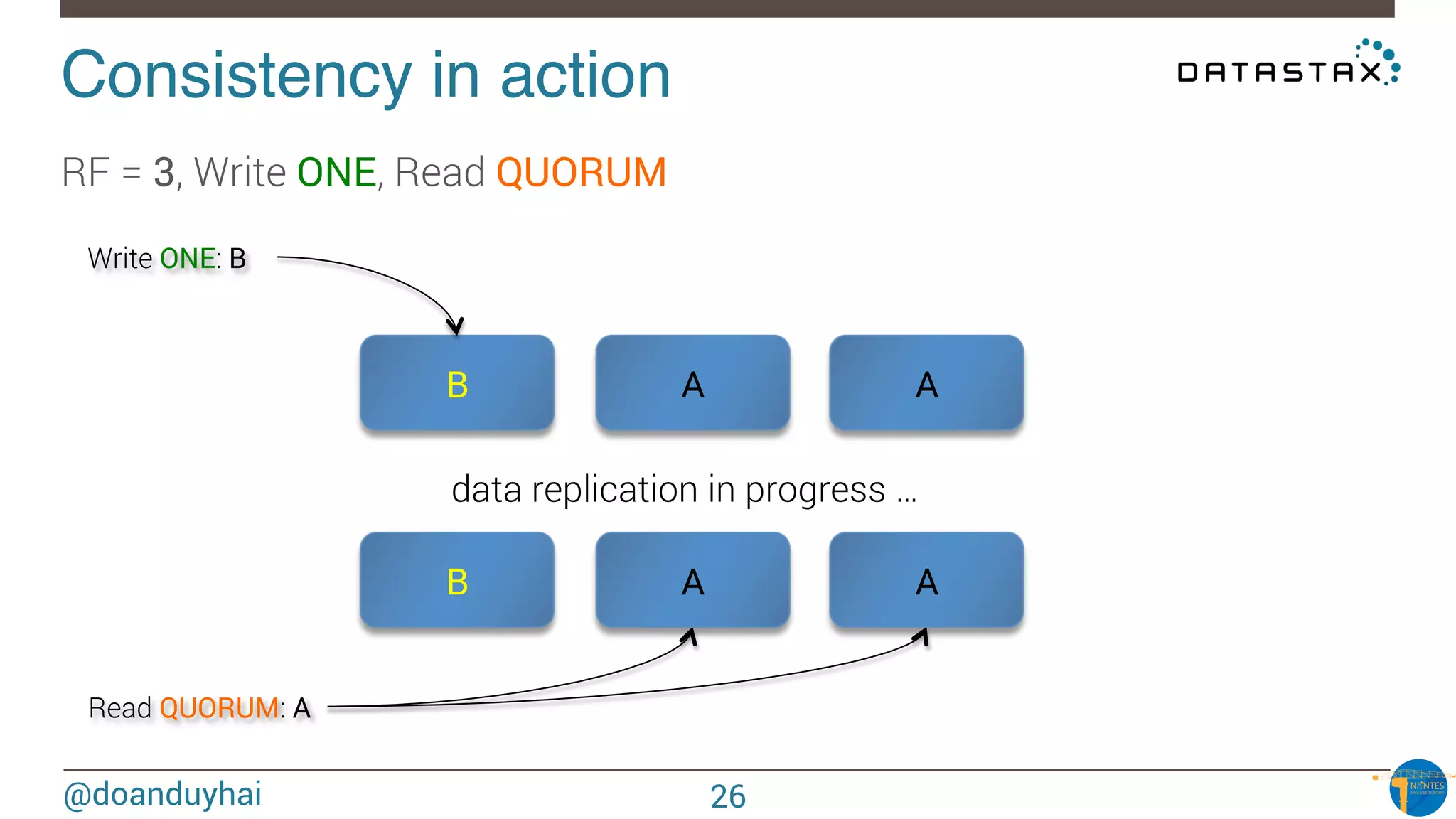
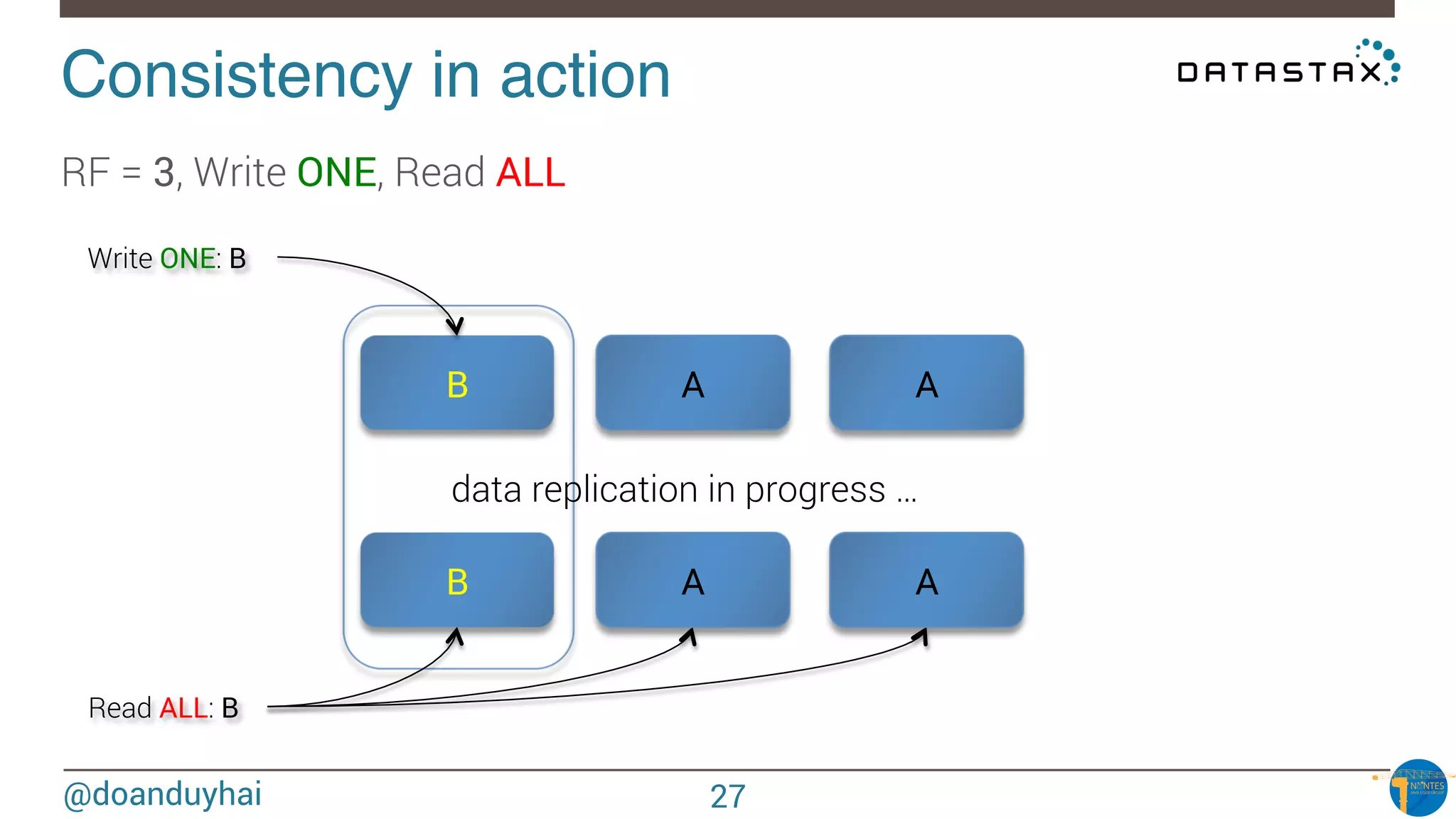
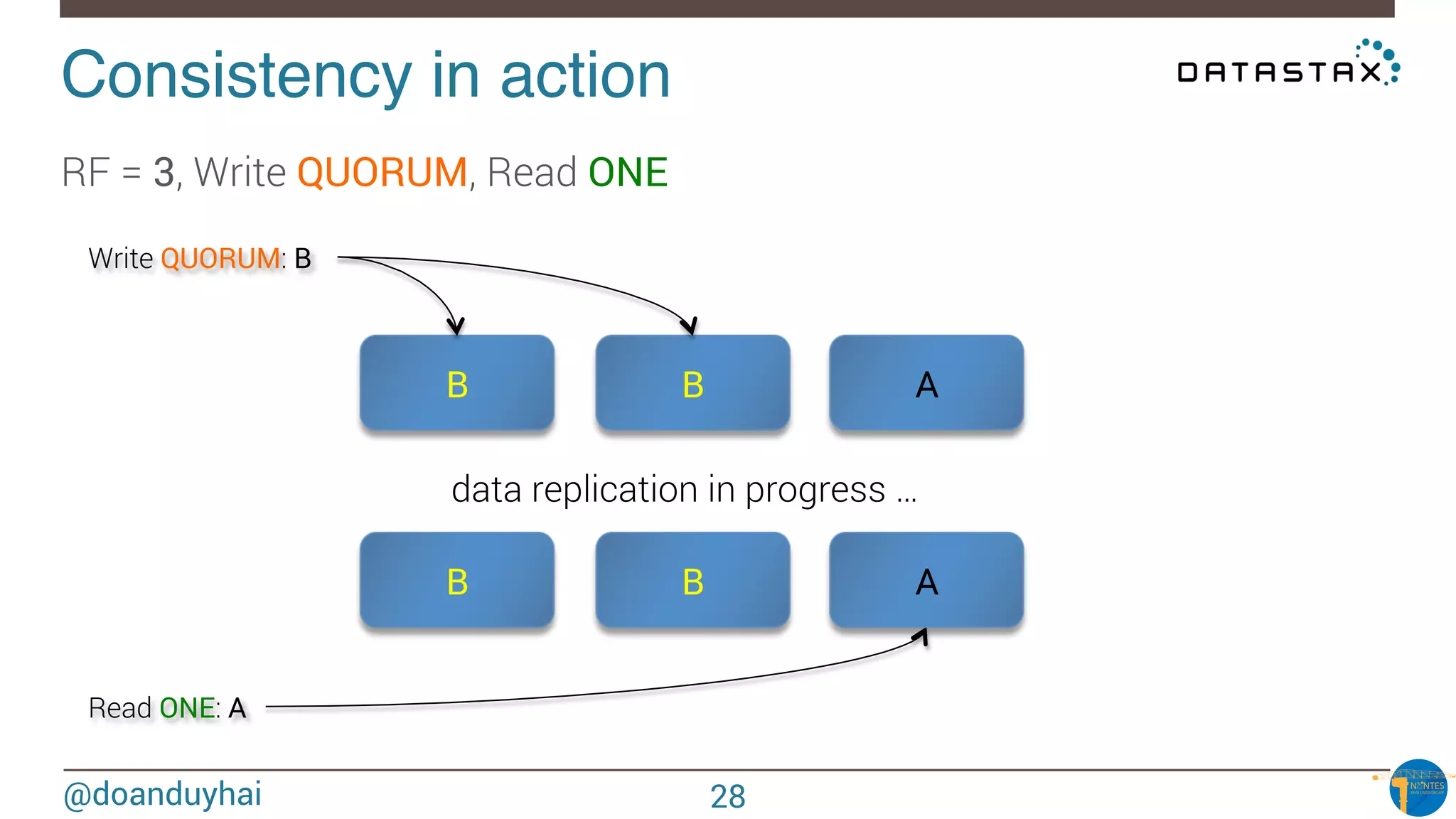
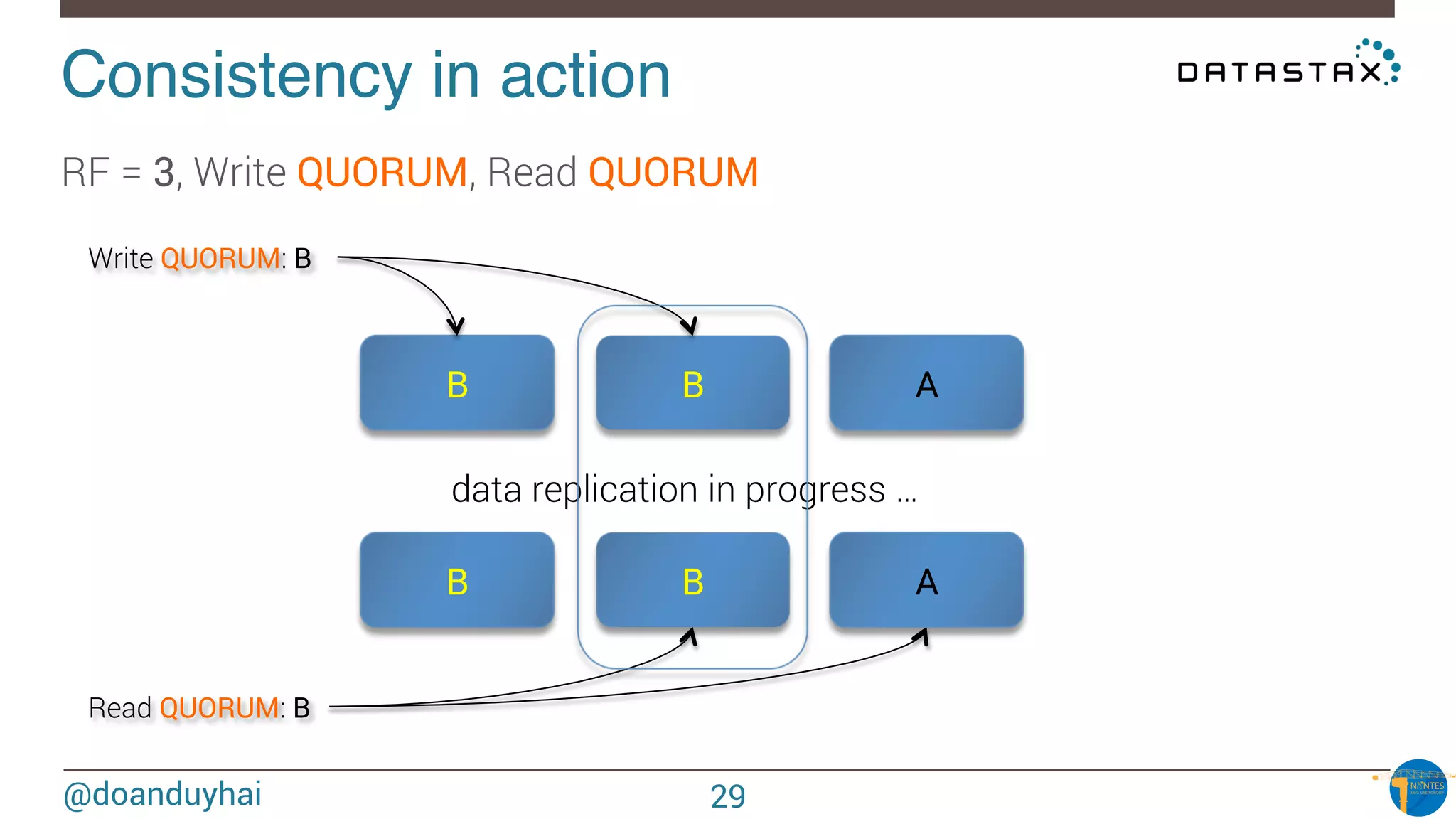
















![@doanduyhai
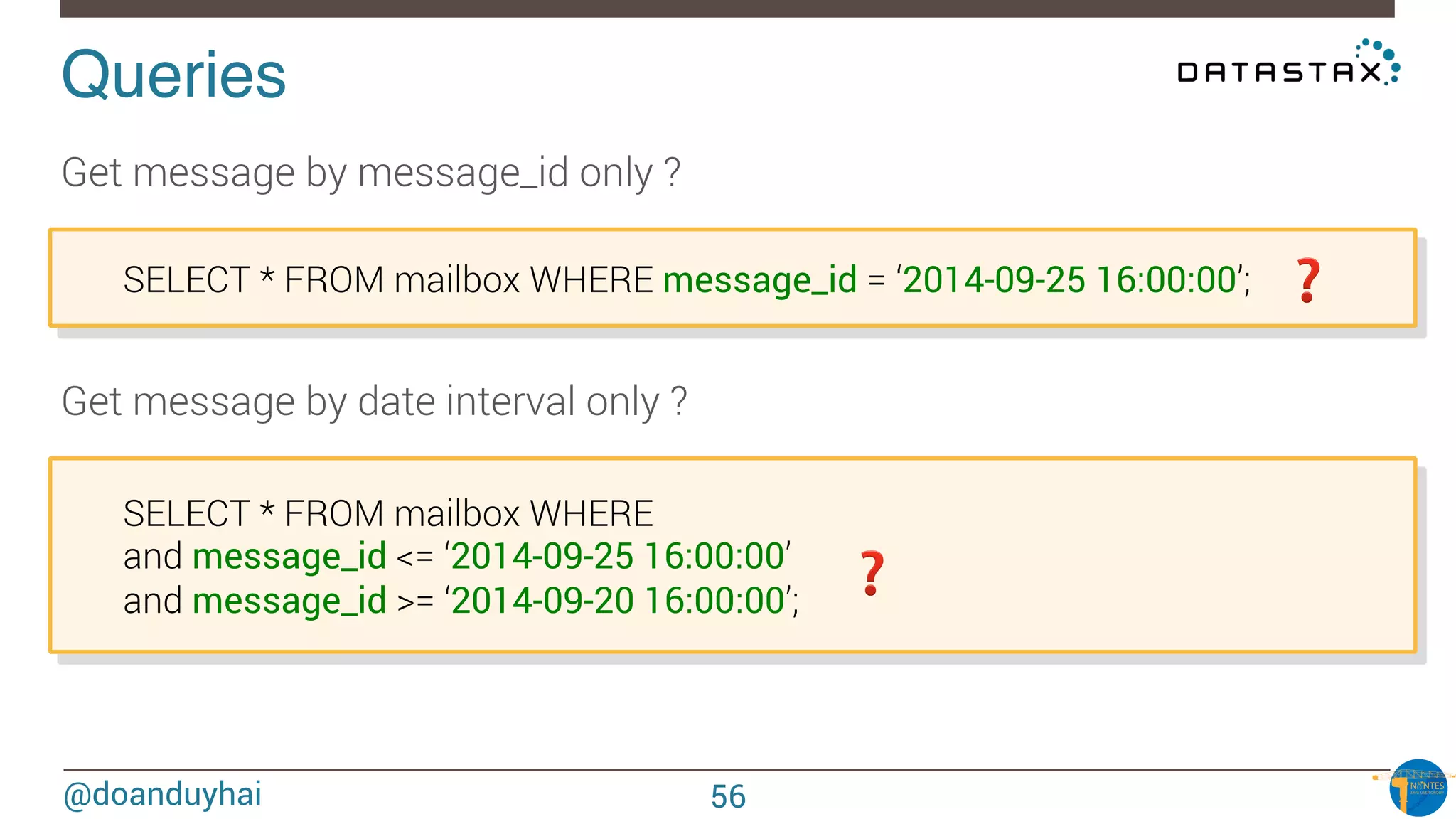
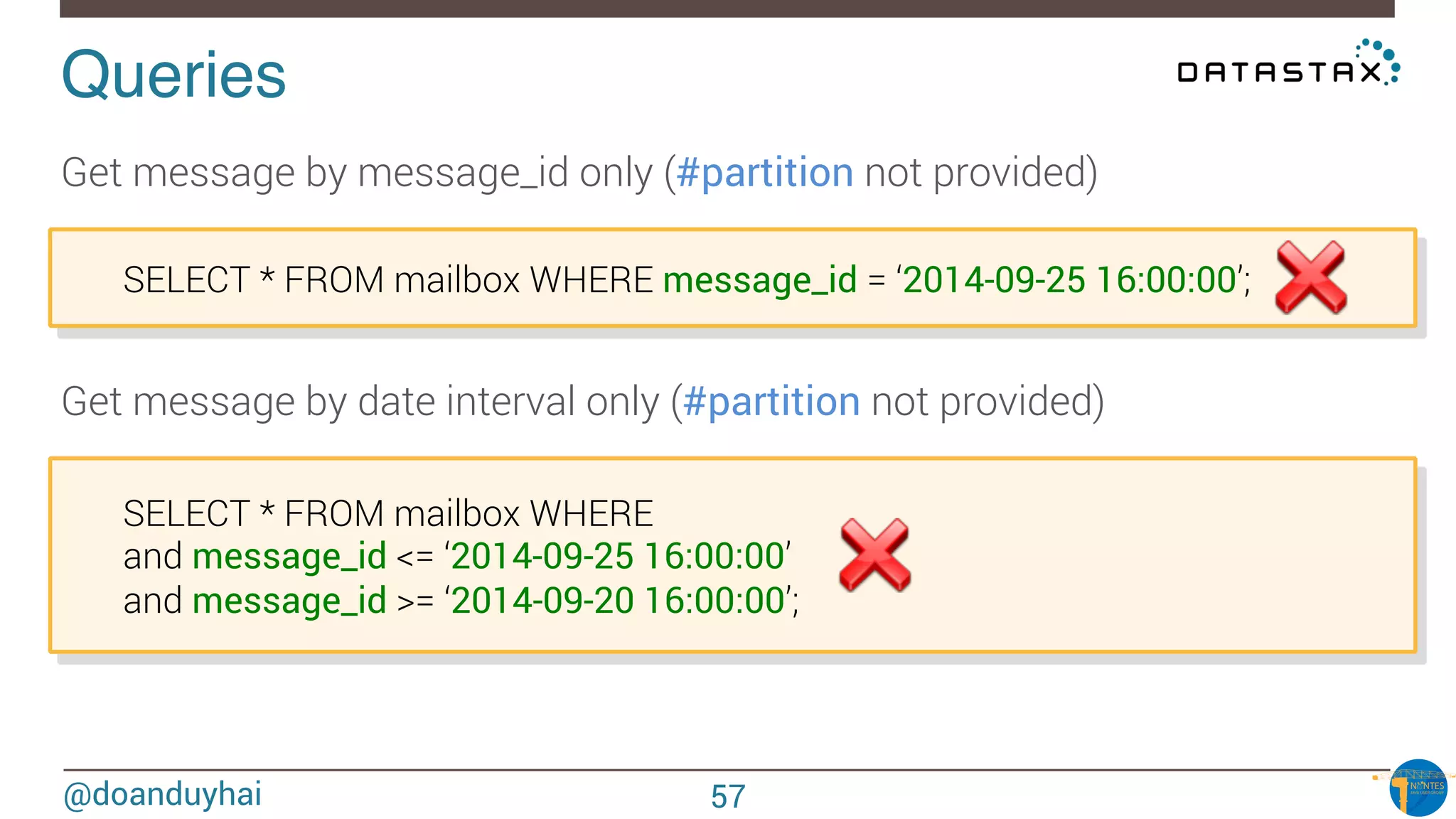
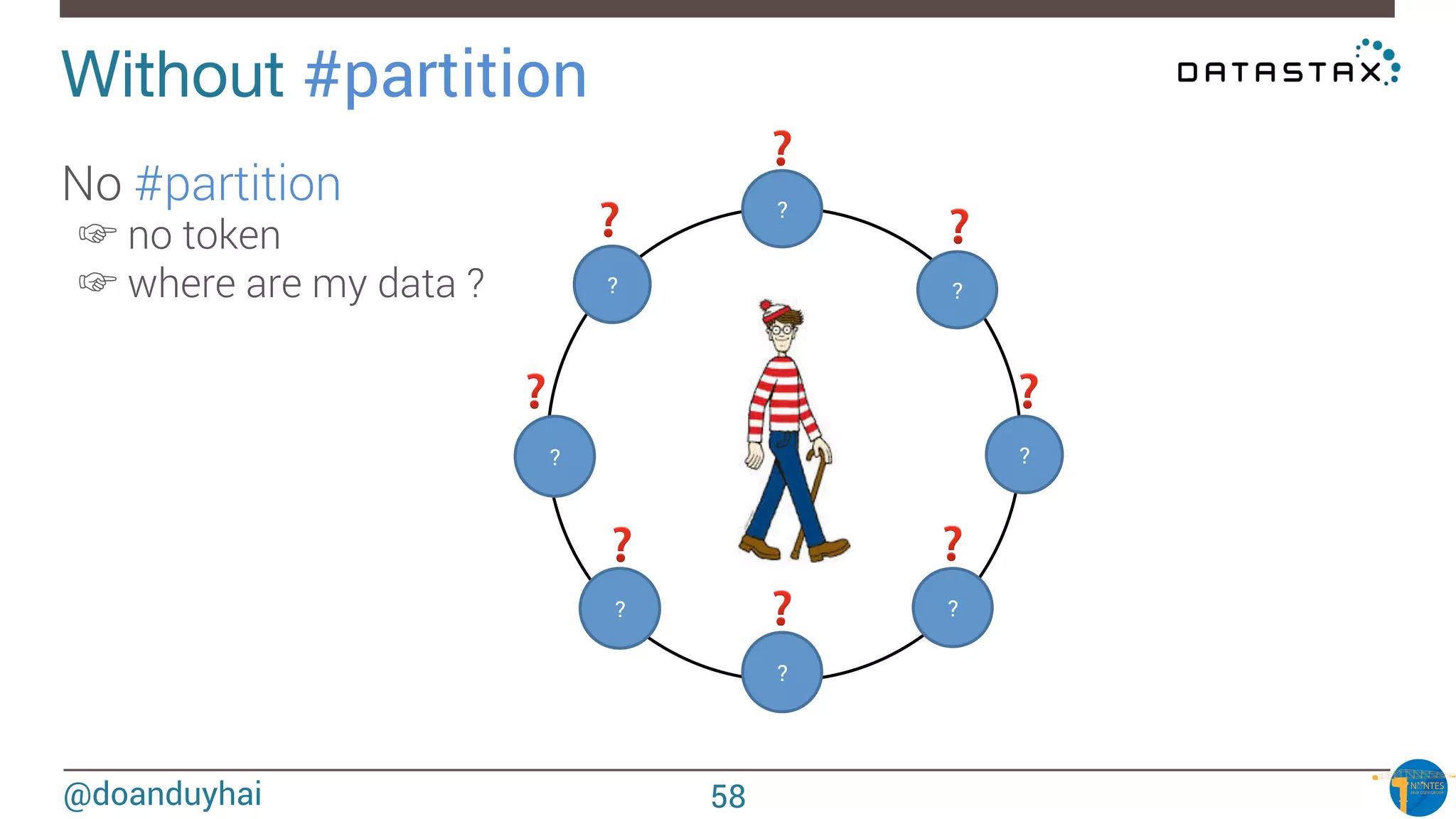
WHERE clause restrictions!
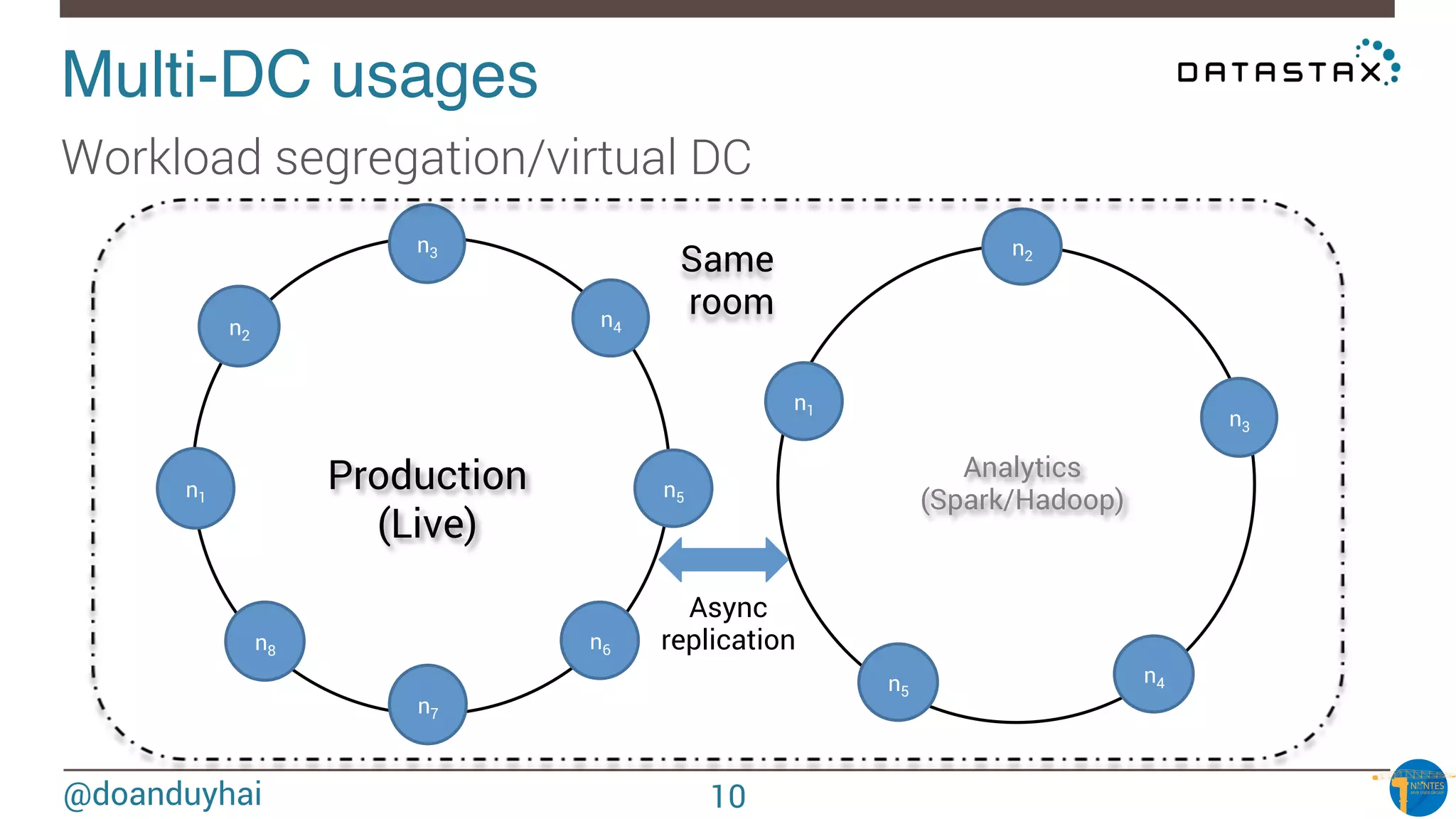
What if I want to perform « arbitrary » WHERE clause ?
• search form scenario, dynamic search fields
DO NOT RE-INVENT THE WHEEL !
☞ Apache Solr (Lucene) integration (Datastax Enterprise)
☞ Same JVM, 1-cluster-2-products (Solr & Cassandra)
SELECT * FROM users WHERE solr_query = ‘age:[33 TO *] AND gender:male’;
SELECT * FROM users WHERE solr_query = ‘lastname:*schwei?er’;
65](https://image.slidesharecdn.com/cassandraintroductionnantesjug-150312103950-conversion-gate01/75/Cassandra-introduction-NantesJUG-65-2048.jpg)


















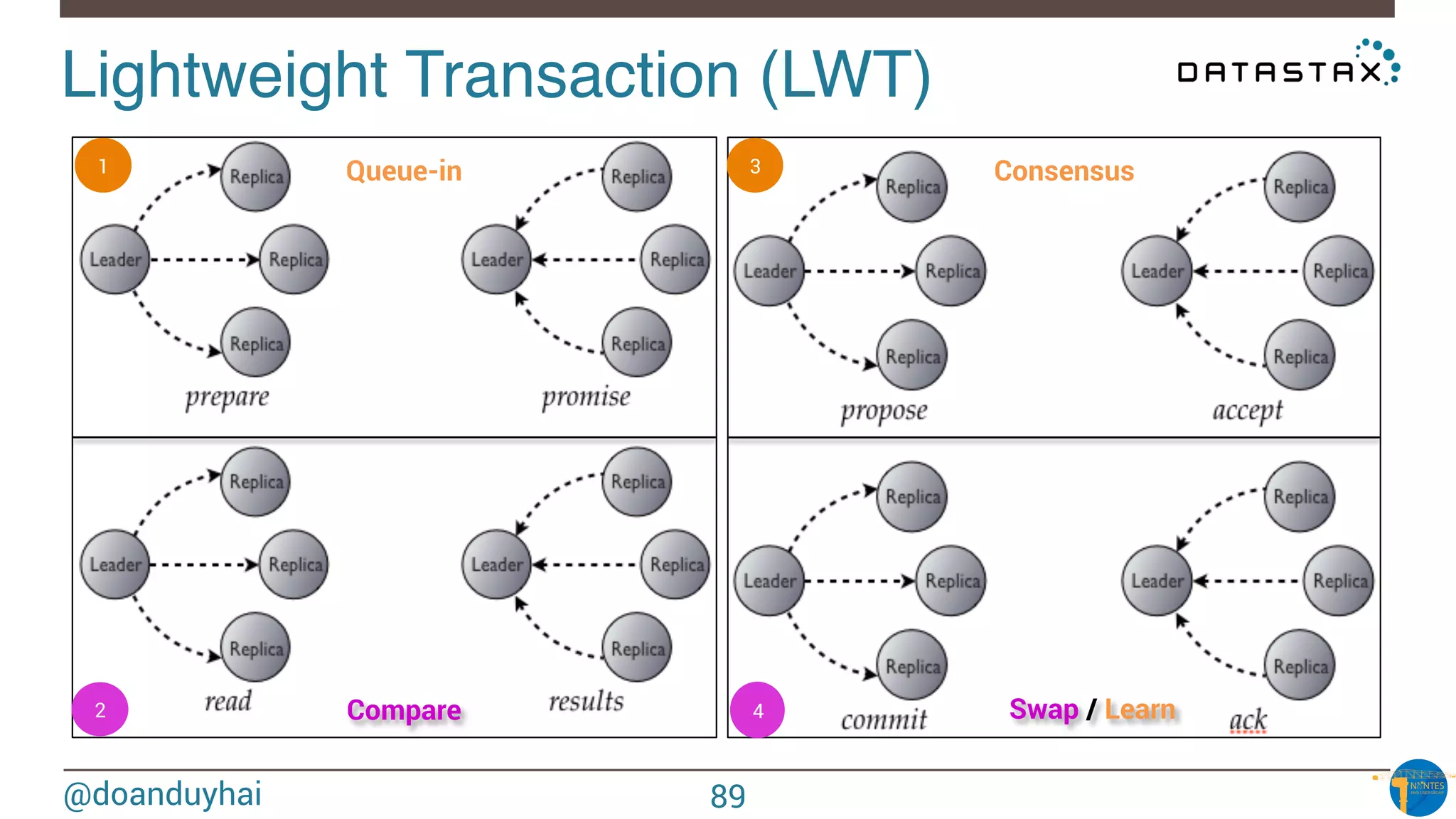

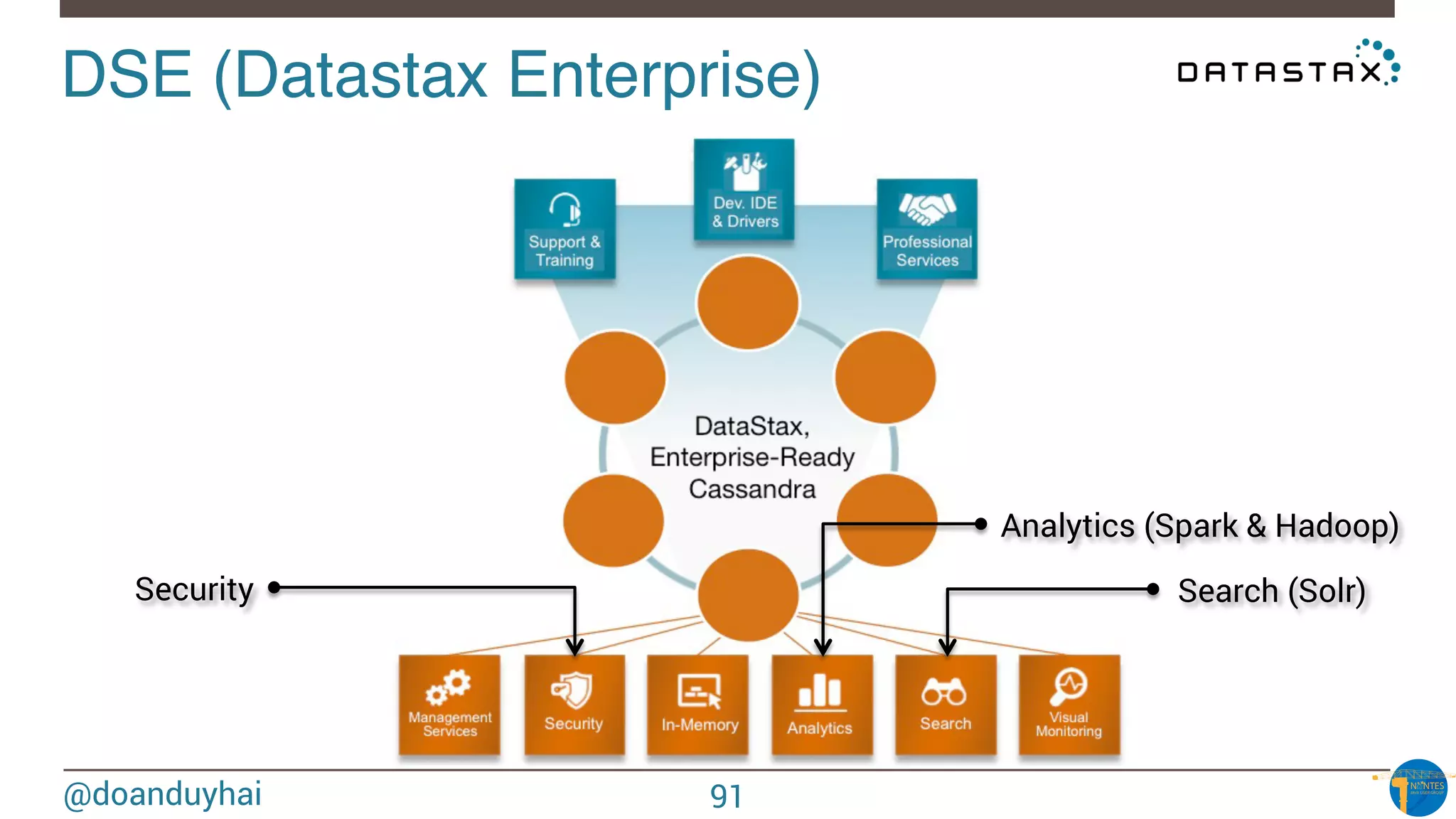



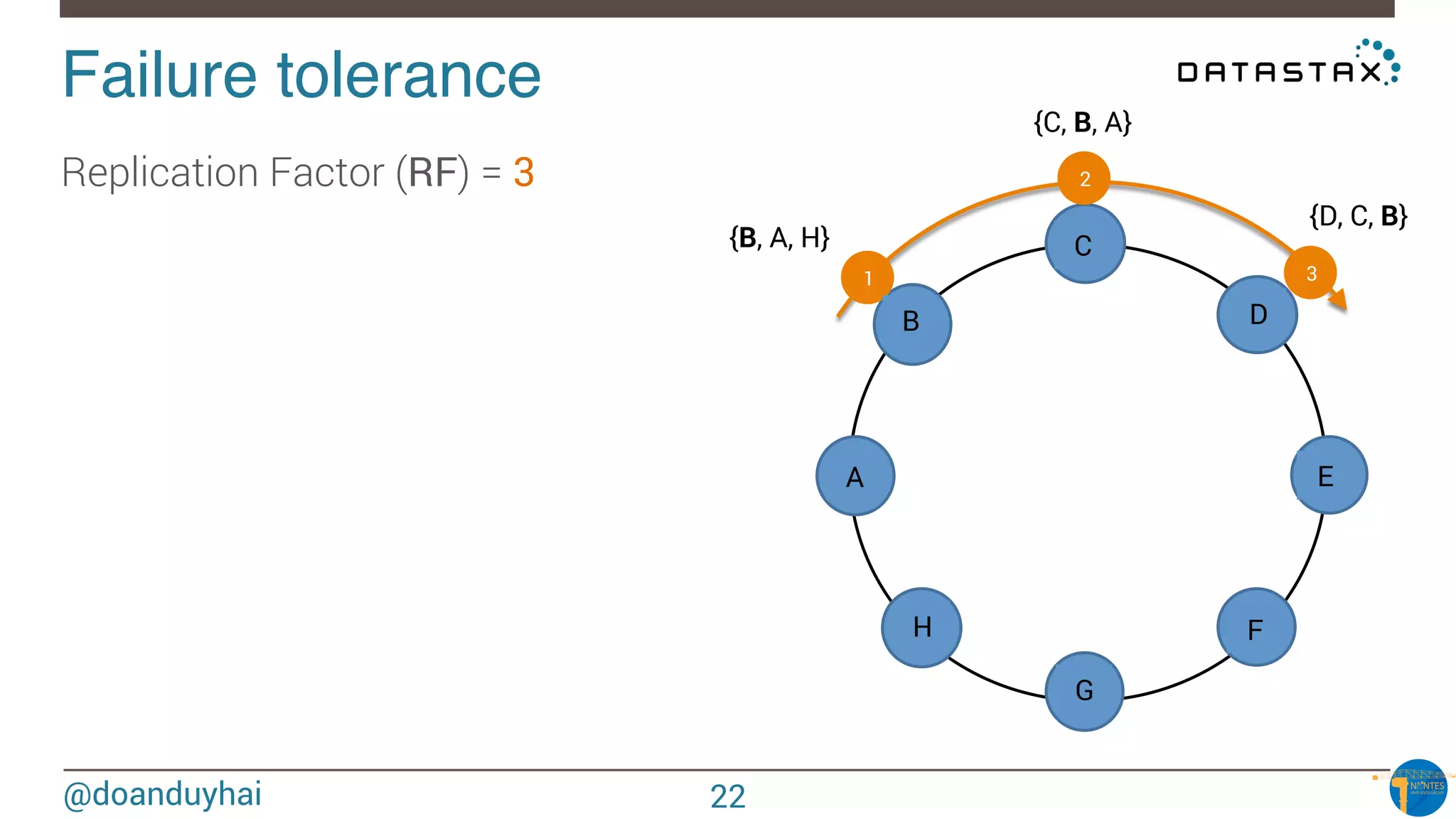
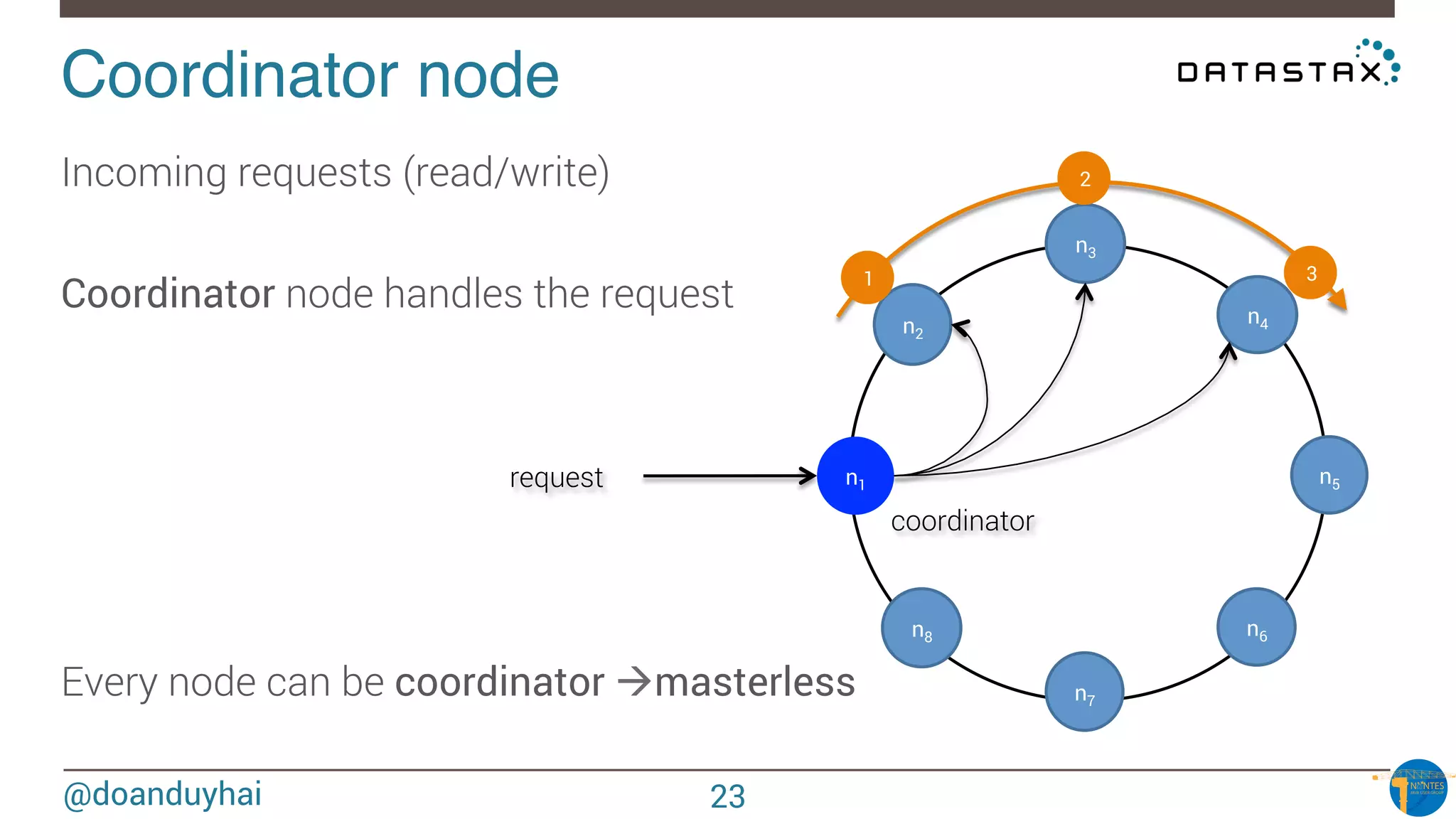
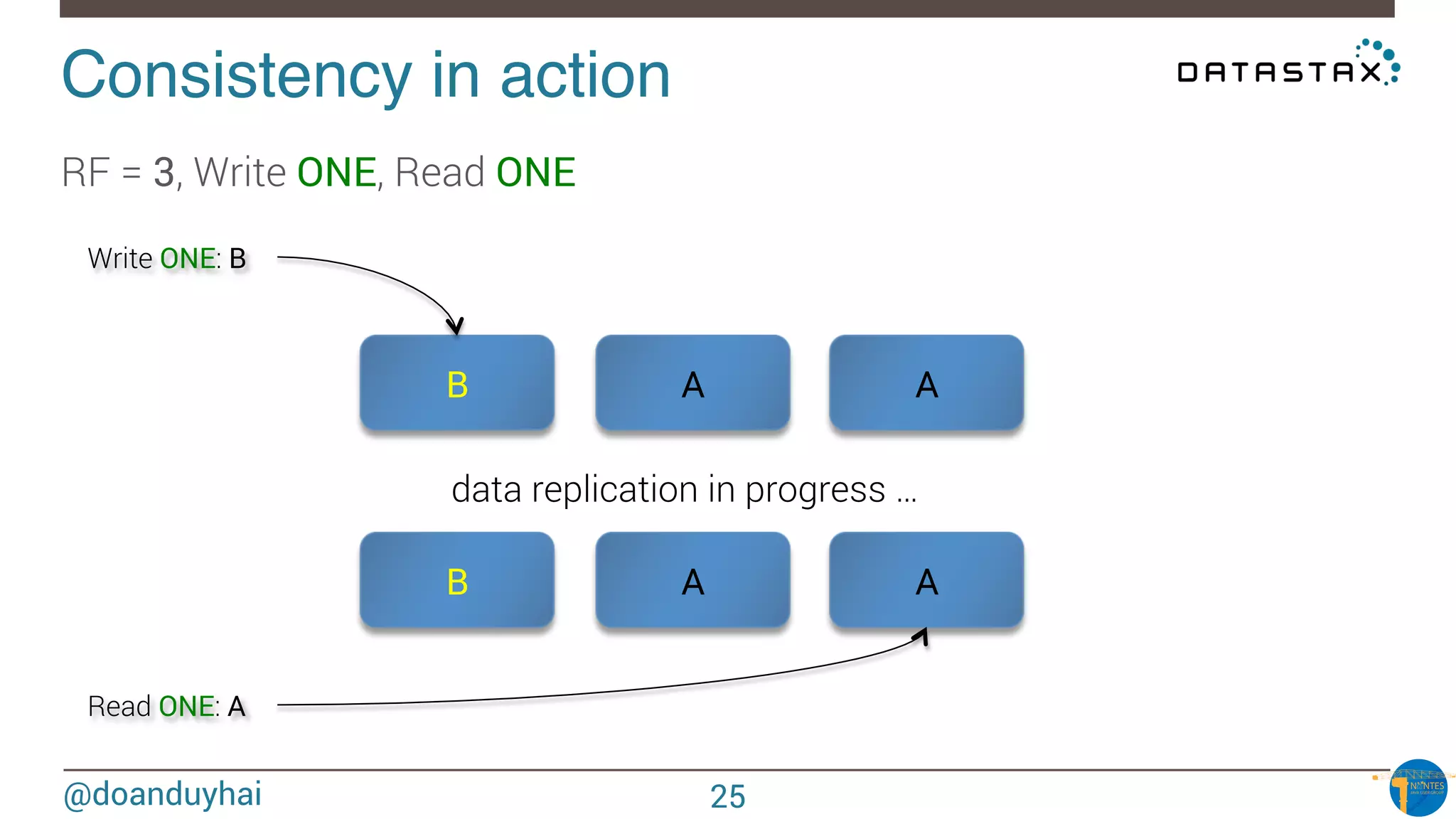
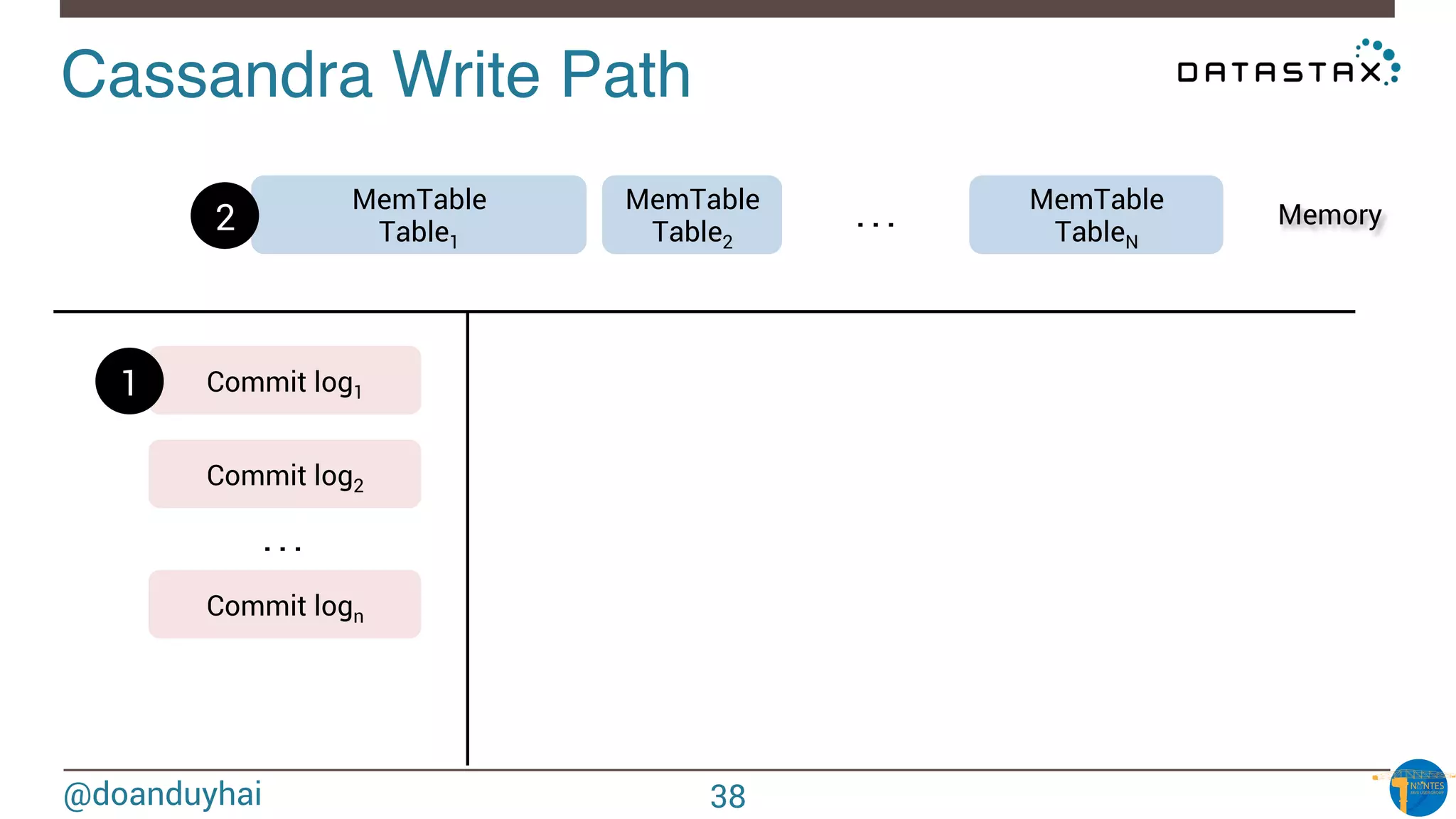
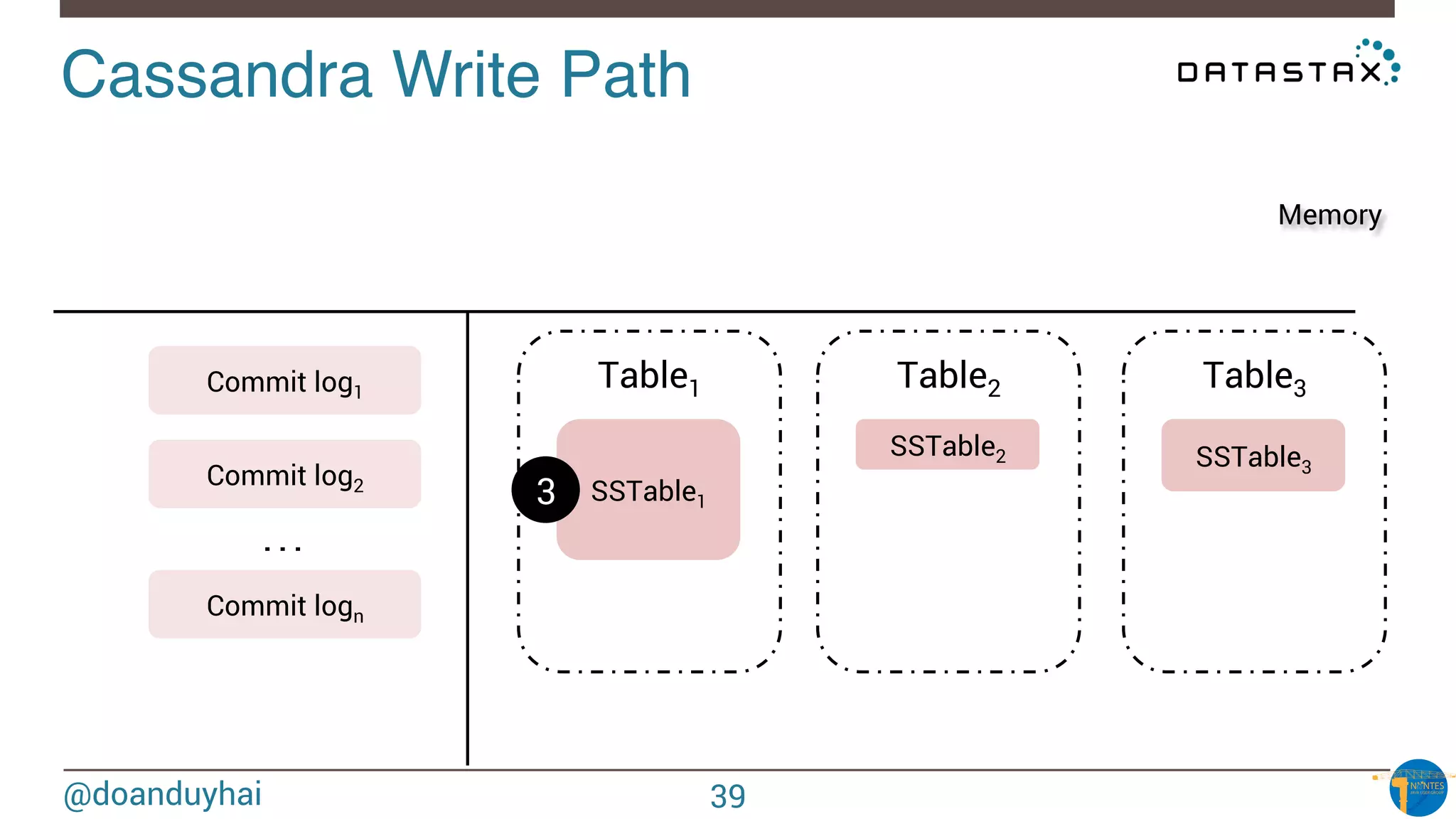
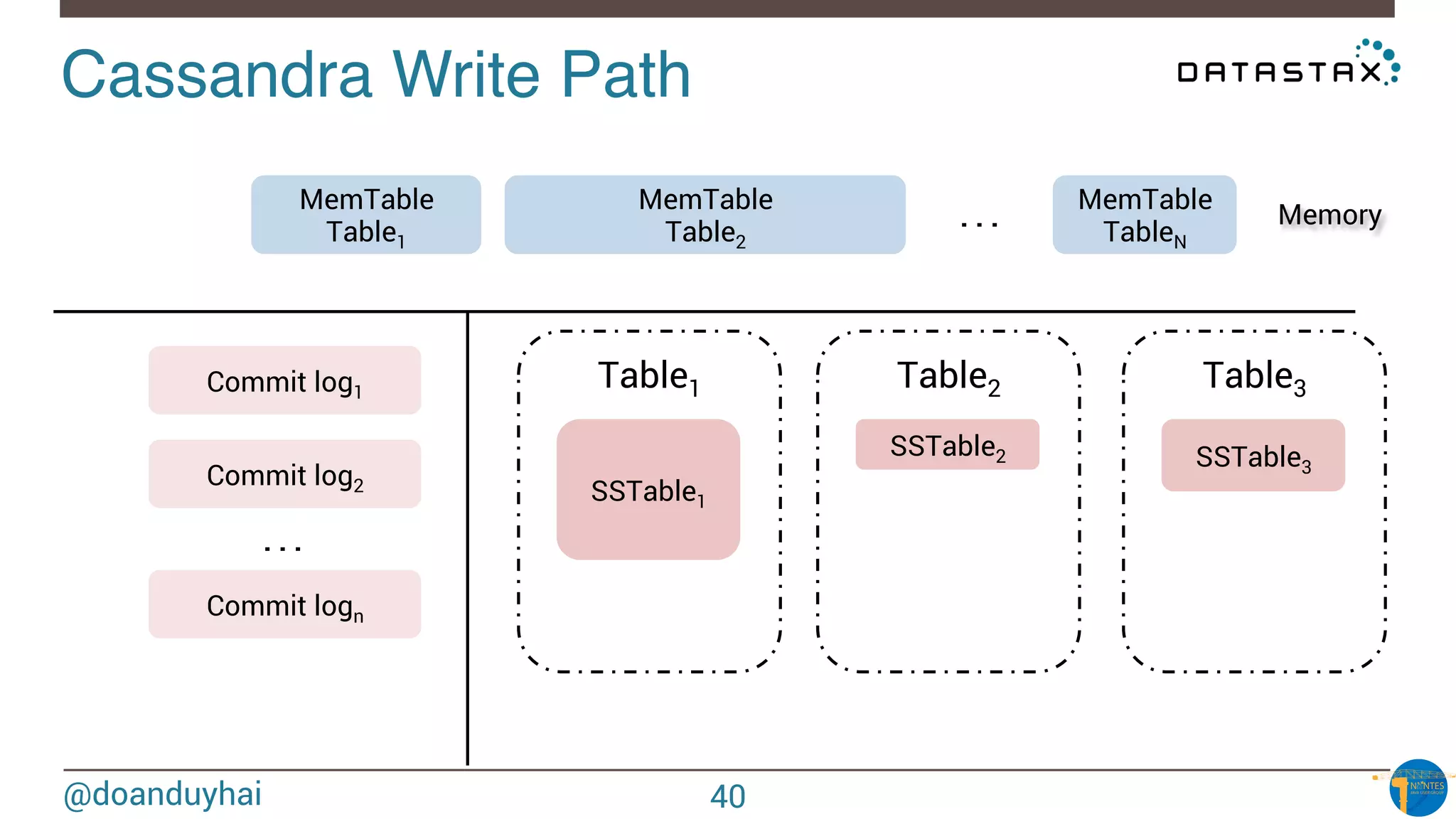
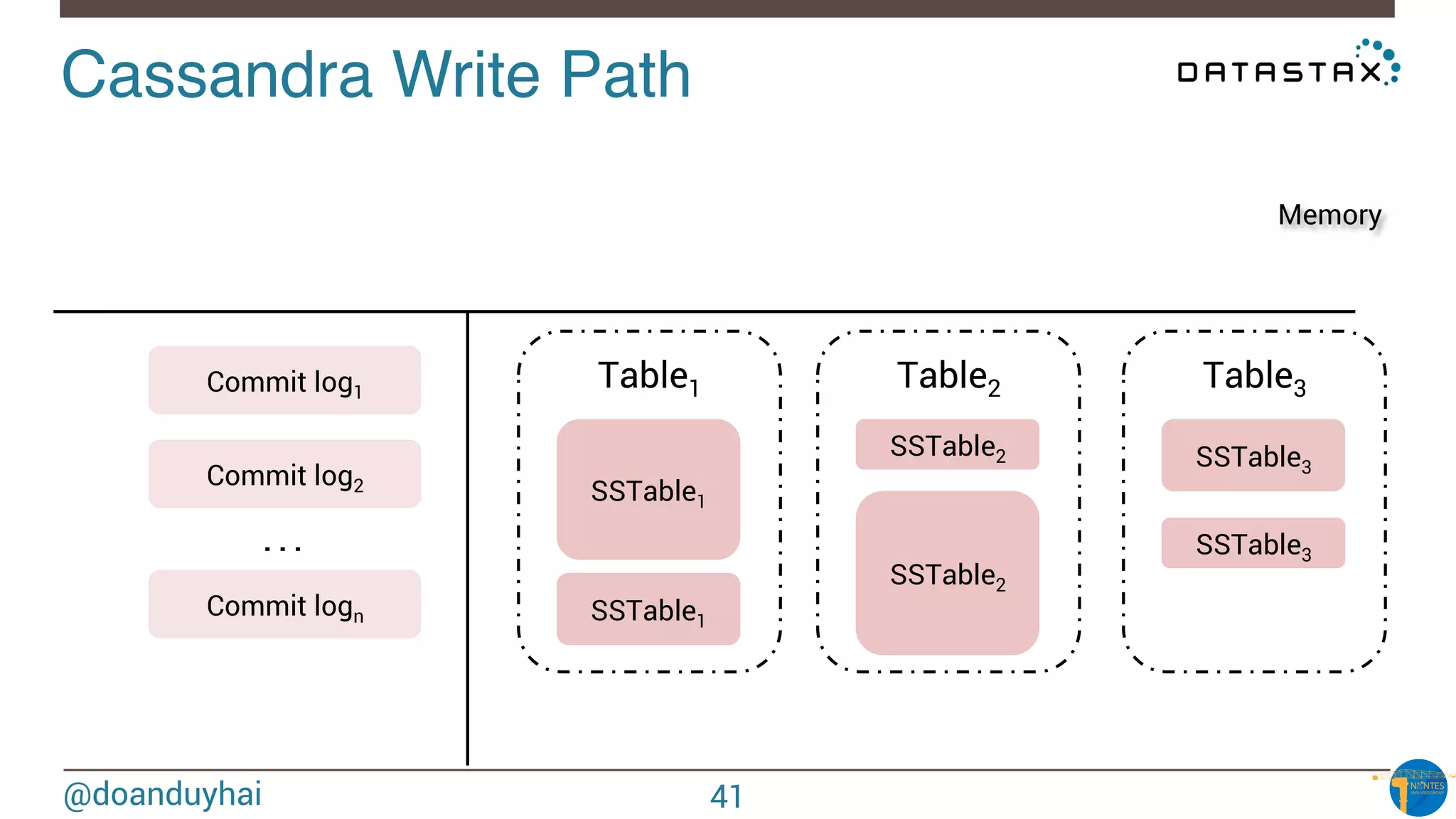
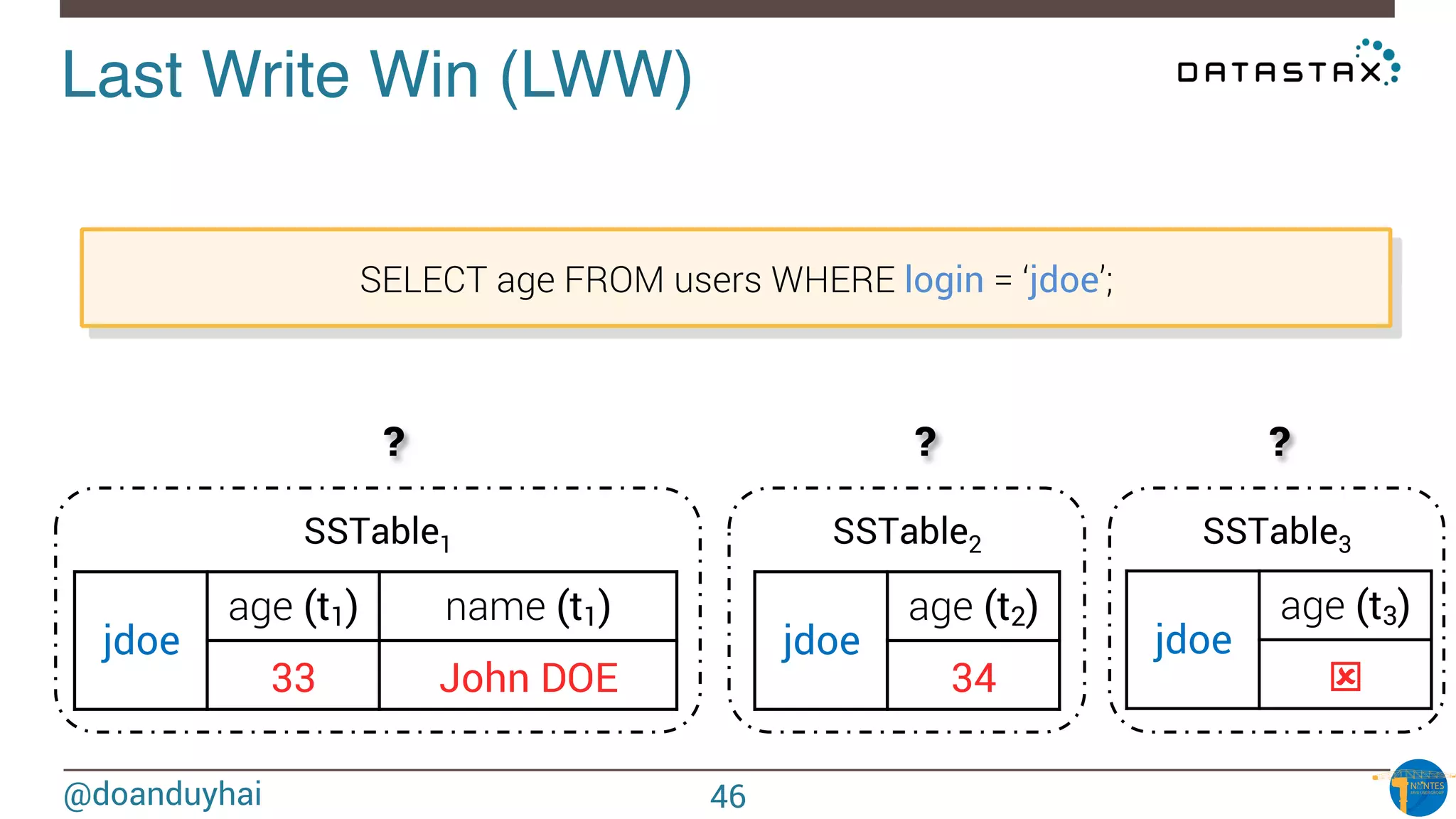
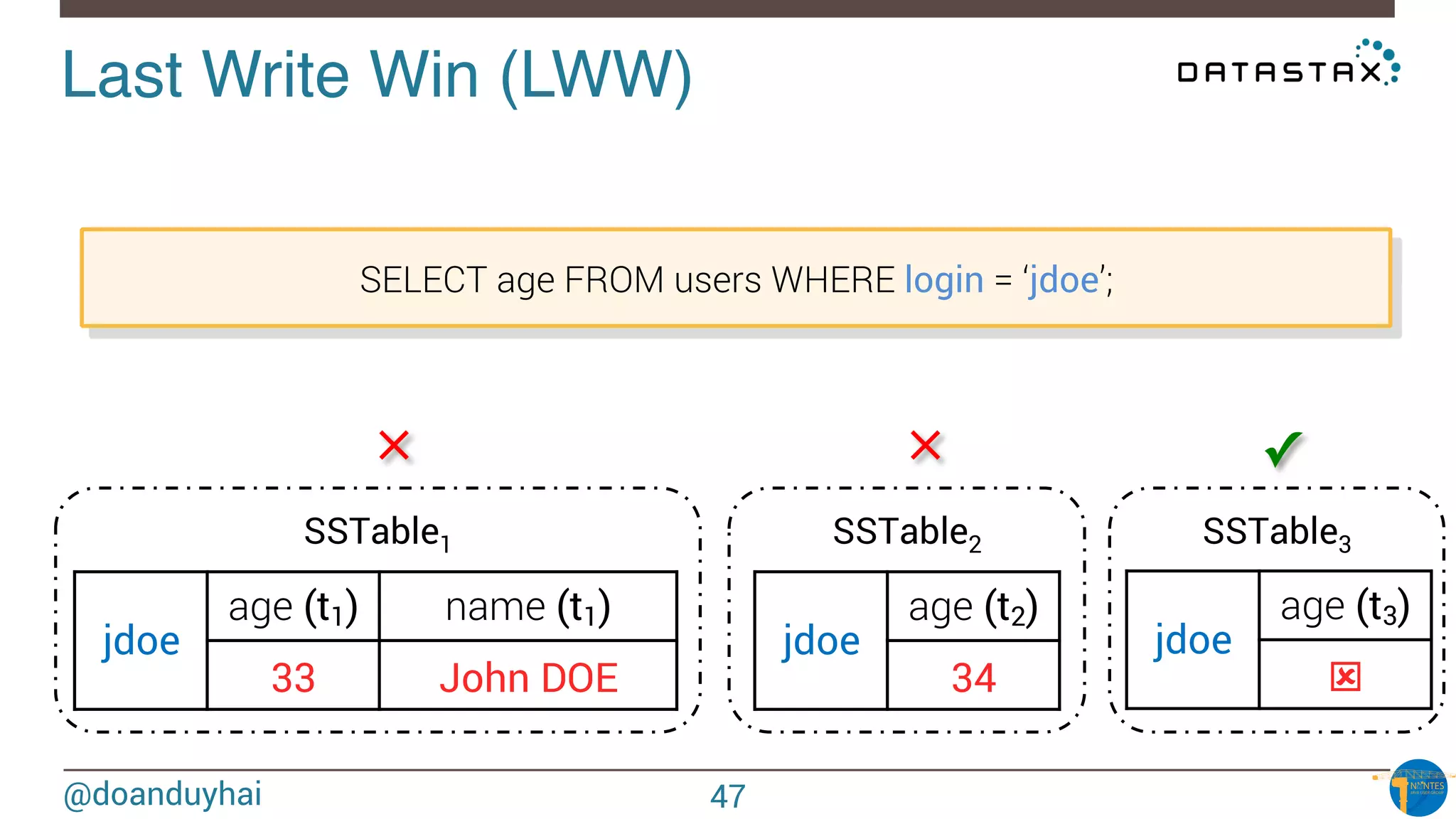
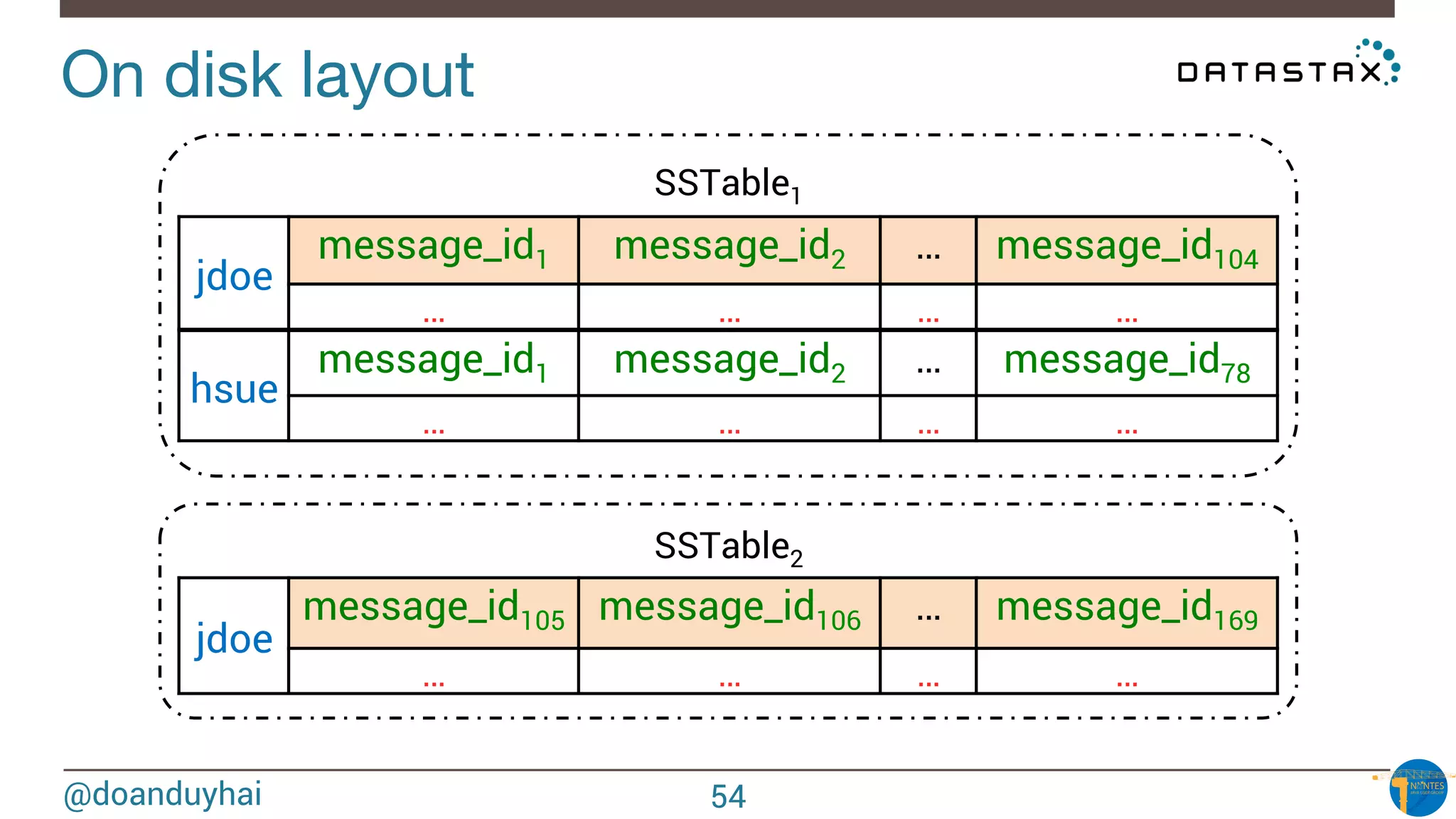
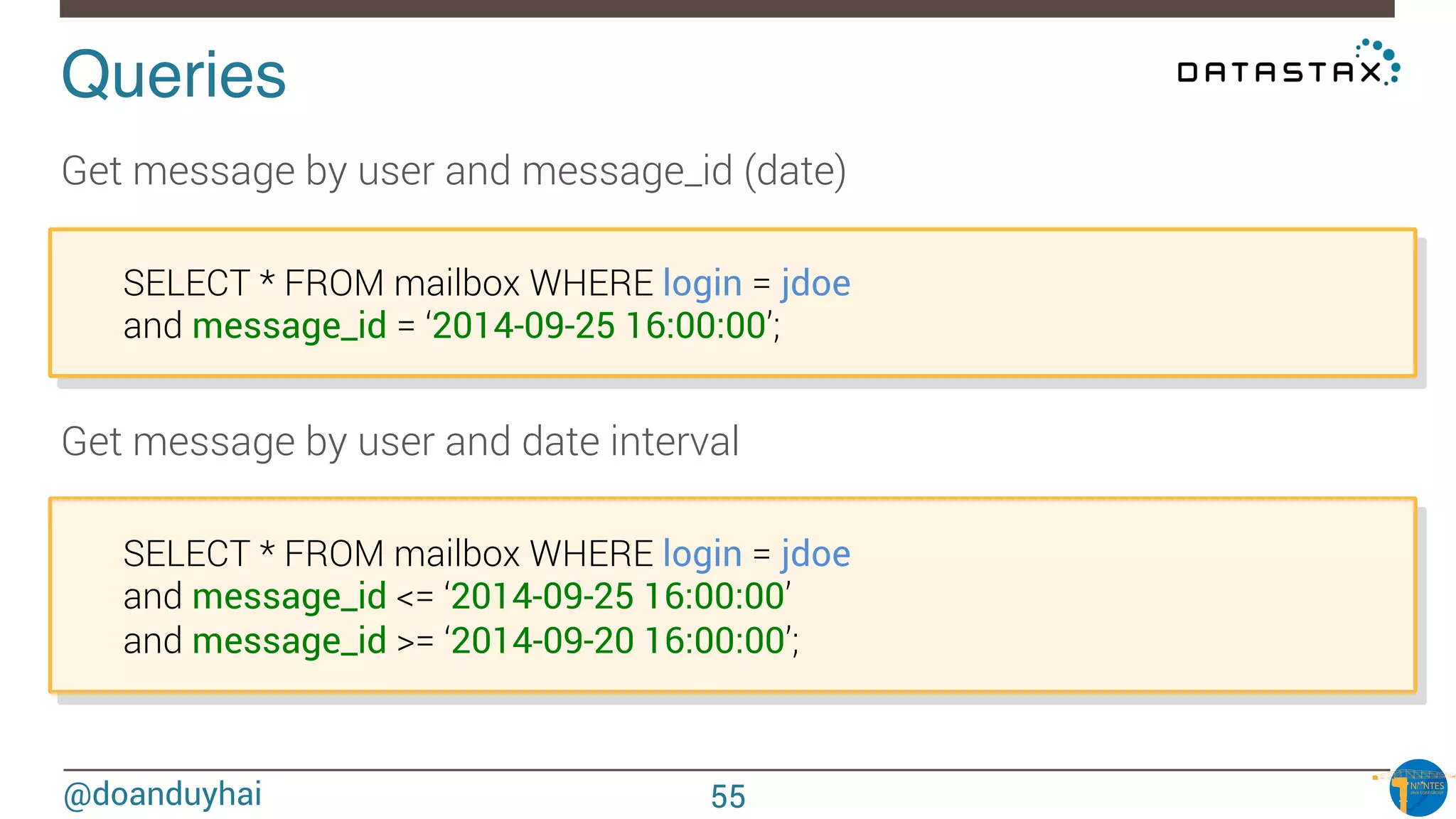
The document provides an introduction to Cassandra presented by Duy Hai Doan. It discusses Cassandra's history, key features including linear scalability, availability, support for multiple data centers, operational simplicity, and analytics capabilities. It also covers Cassandra architecture including the cluster layer based on Dynamo and data-store layer based on BigTable, data distribution, replication, consistency levels, and the write path. The data model of using the last write to resolve conflicts is explained along with CQL basics and modeling one-to-many relationships with clustered tables.






























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







