











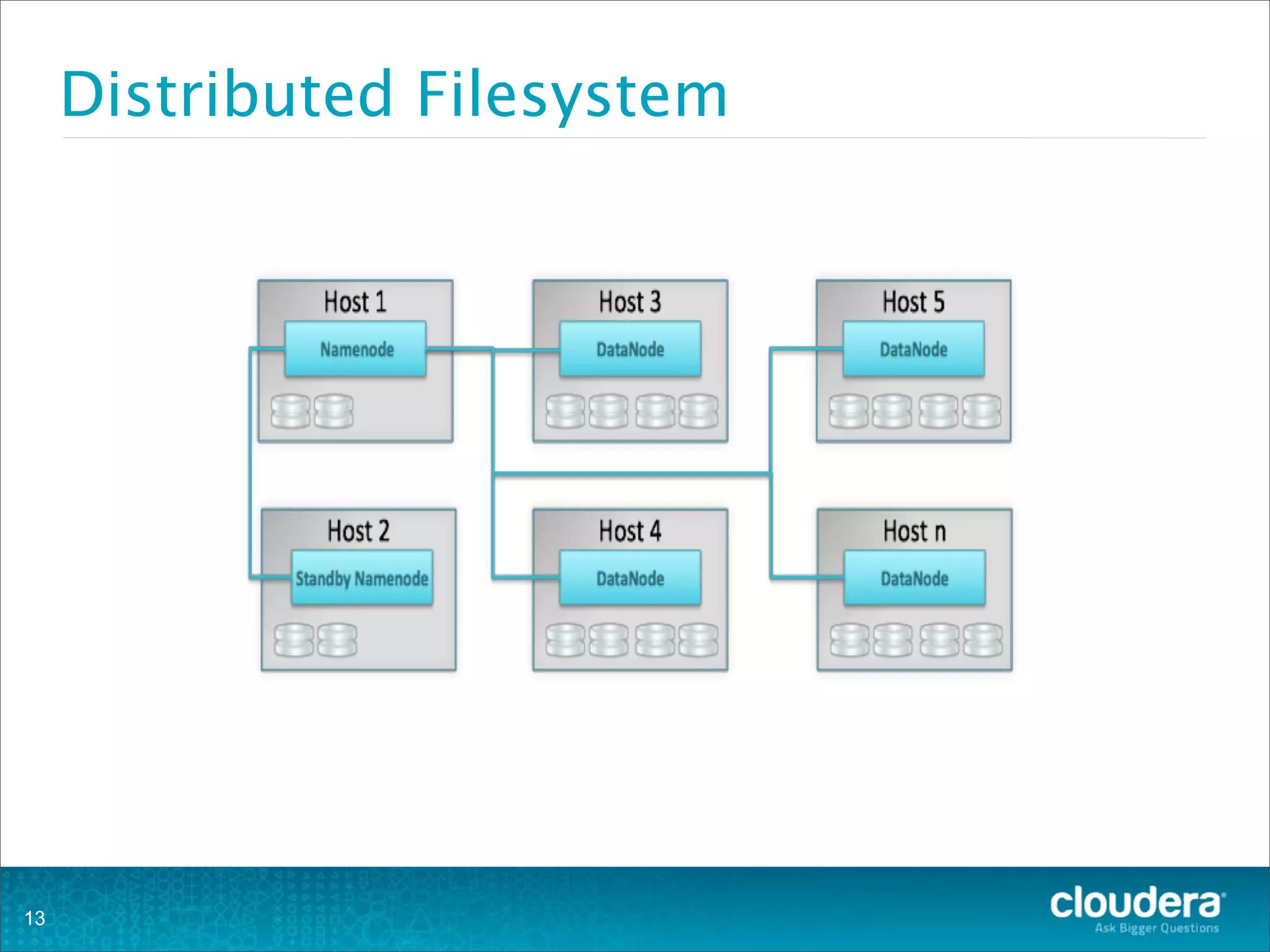

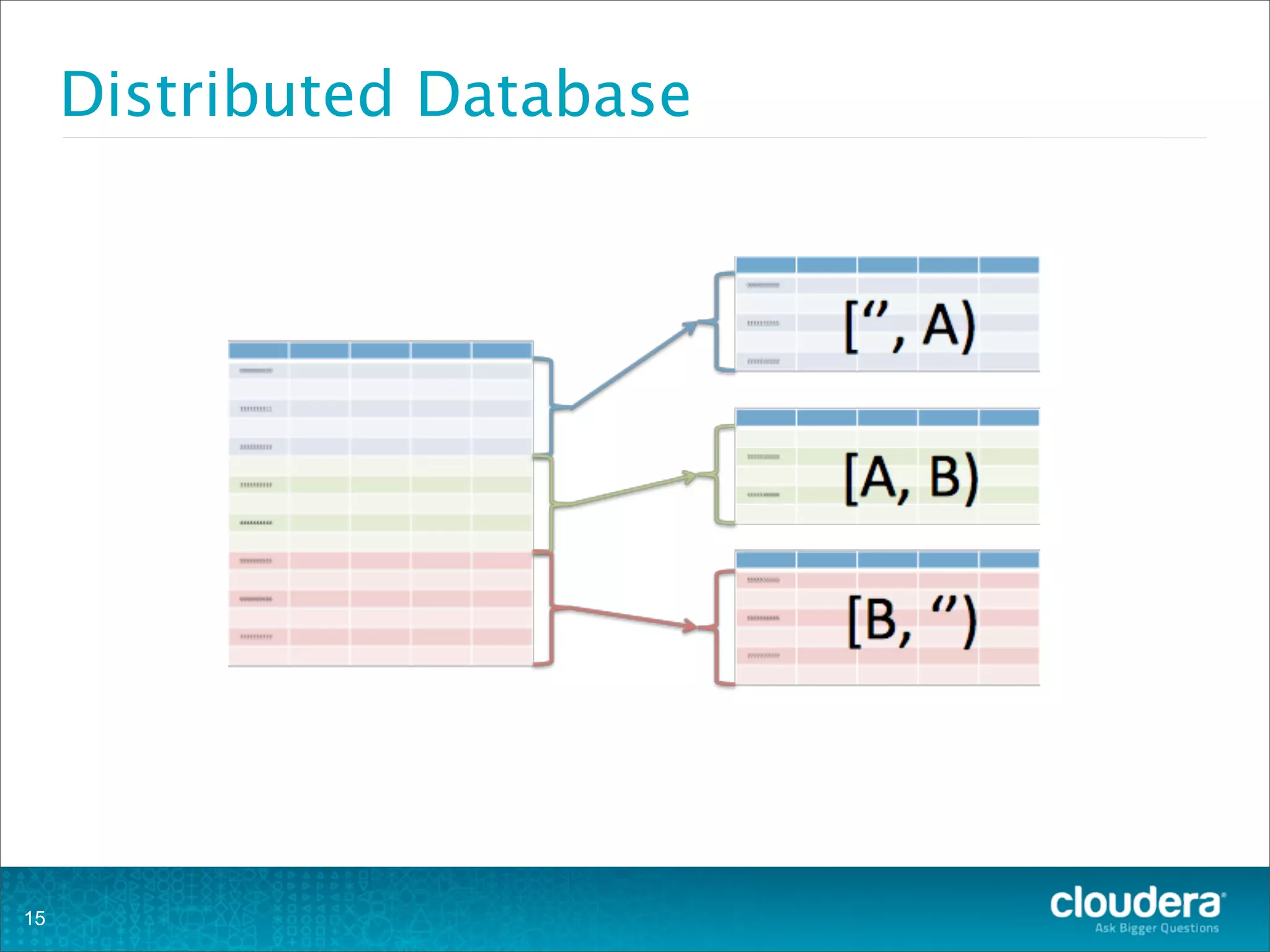


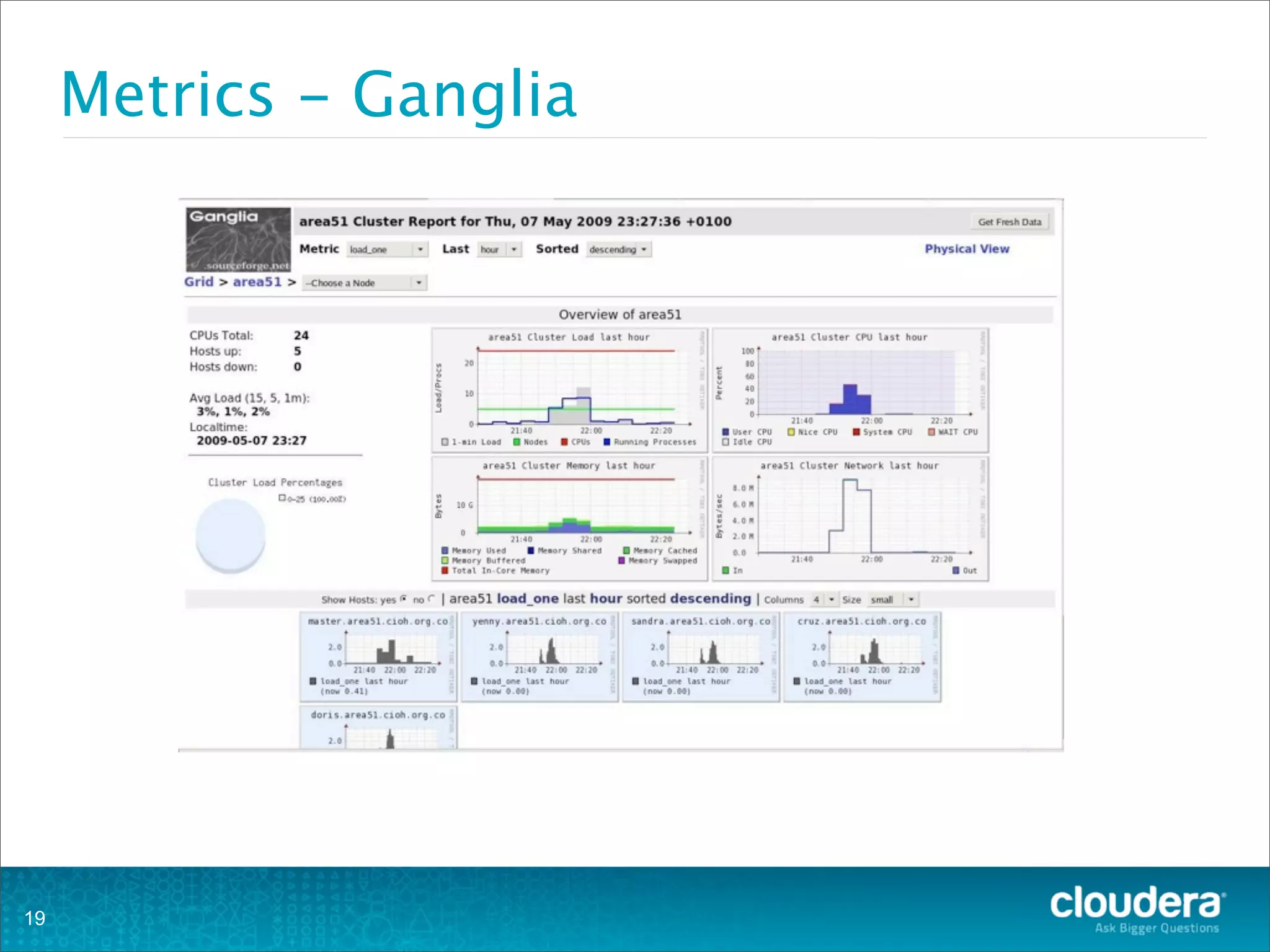


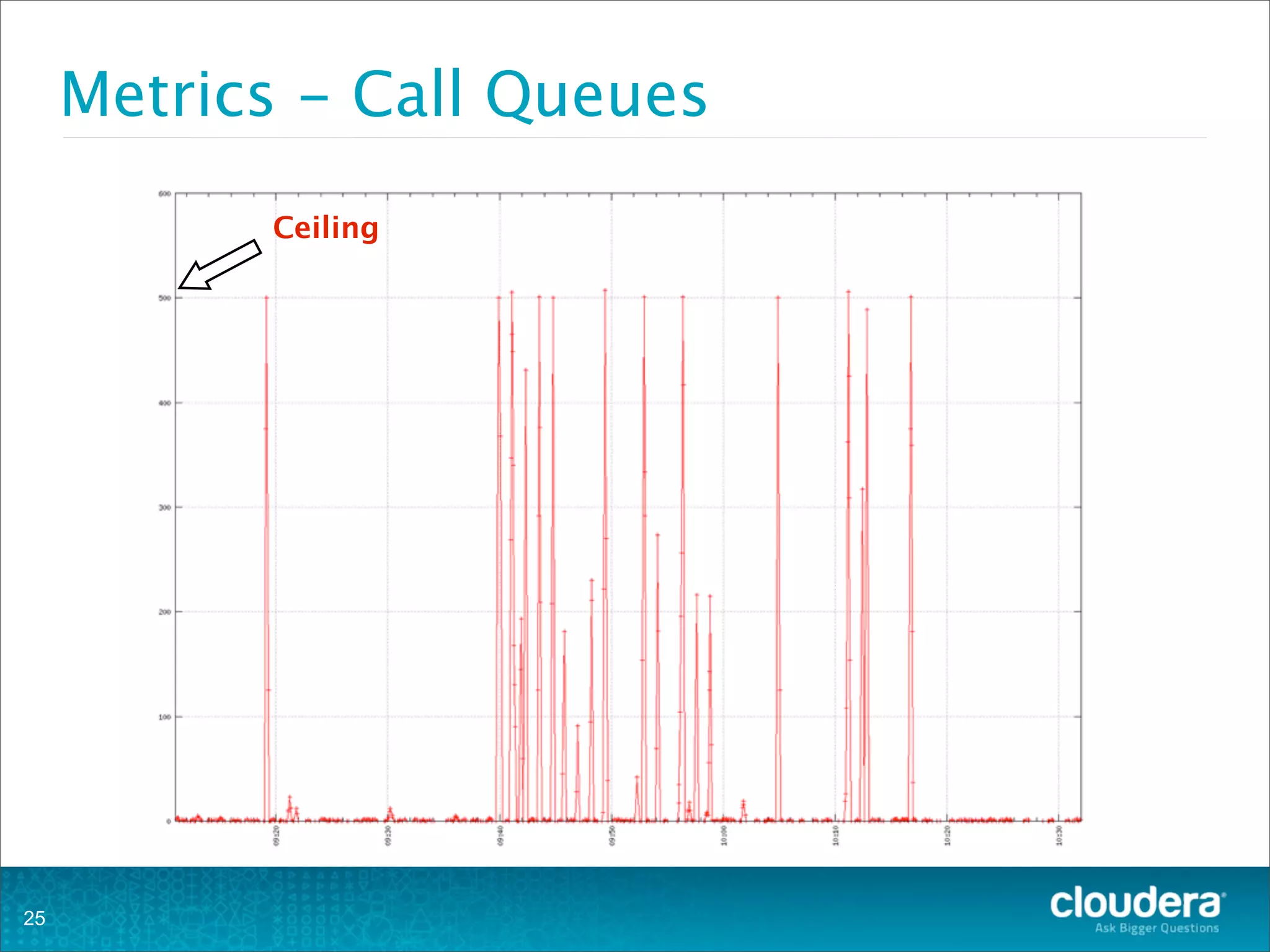
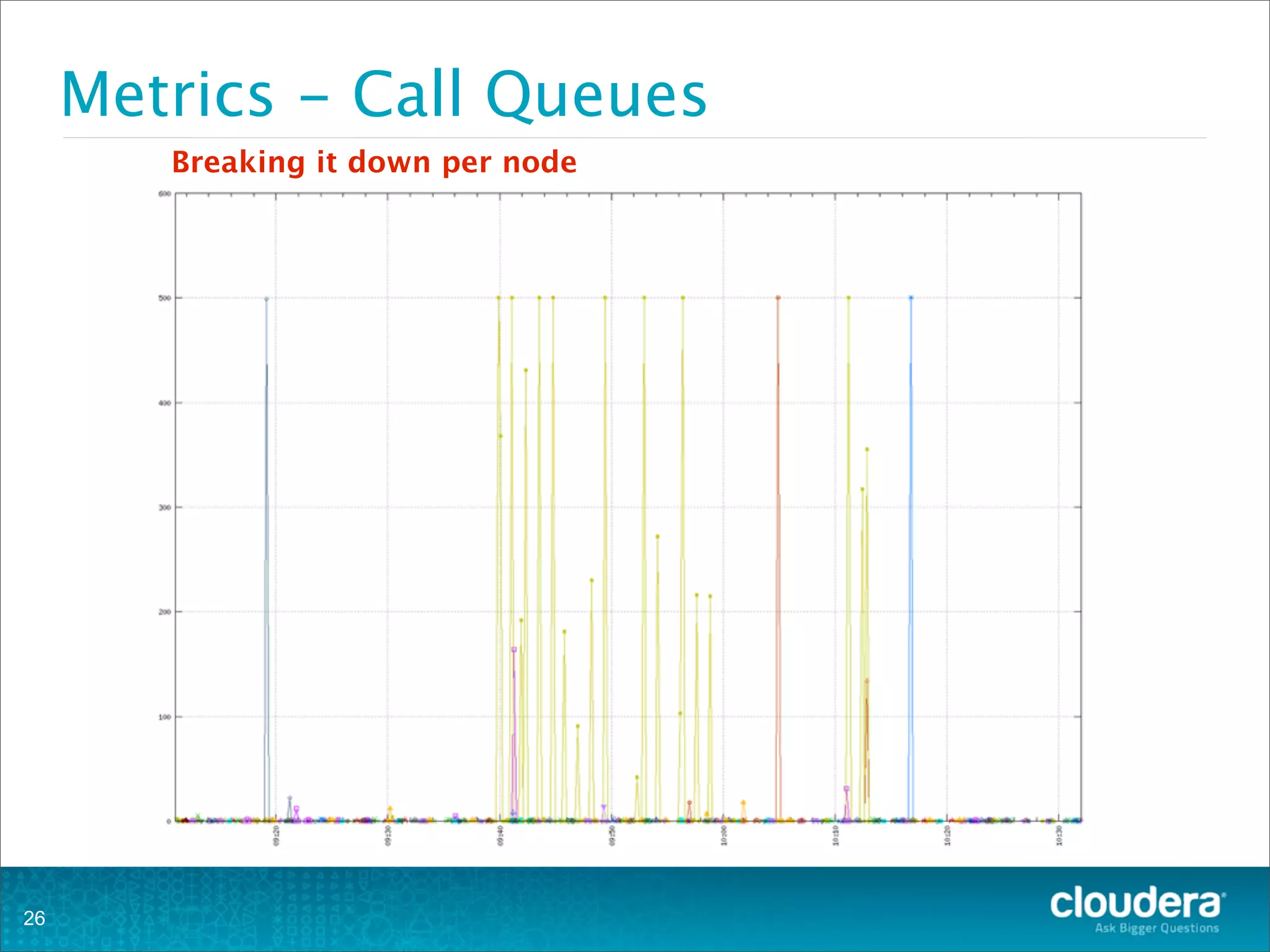
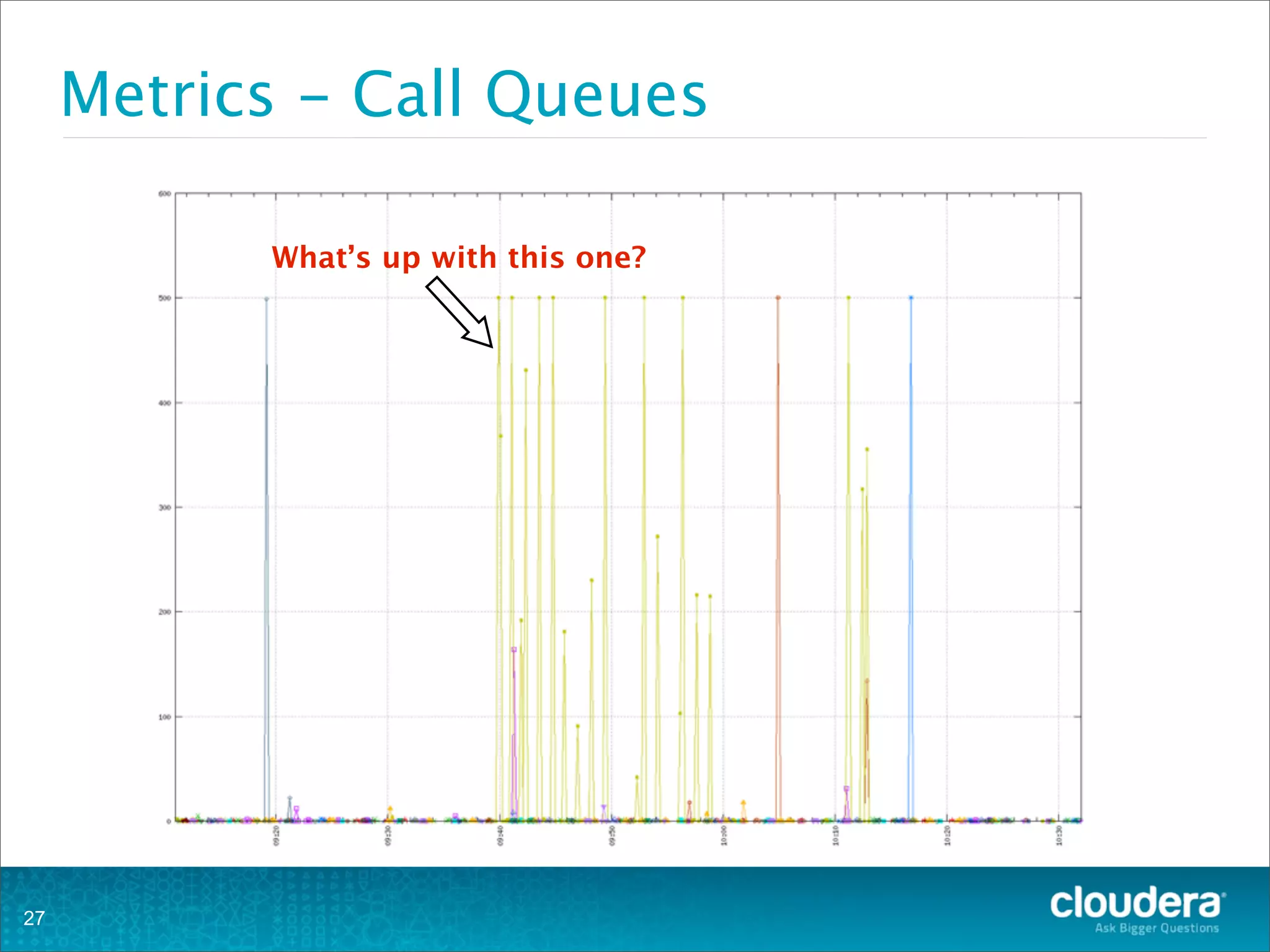
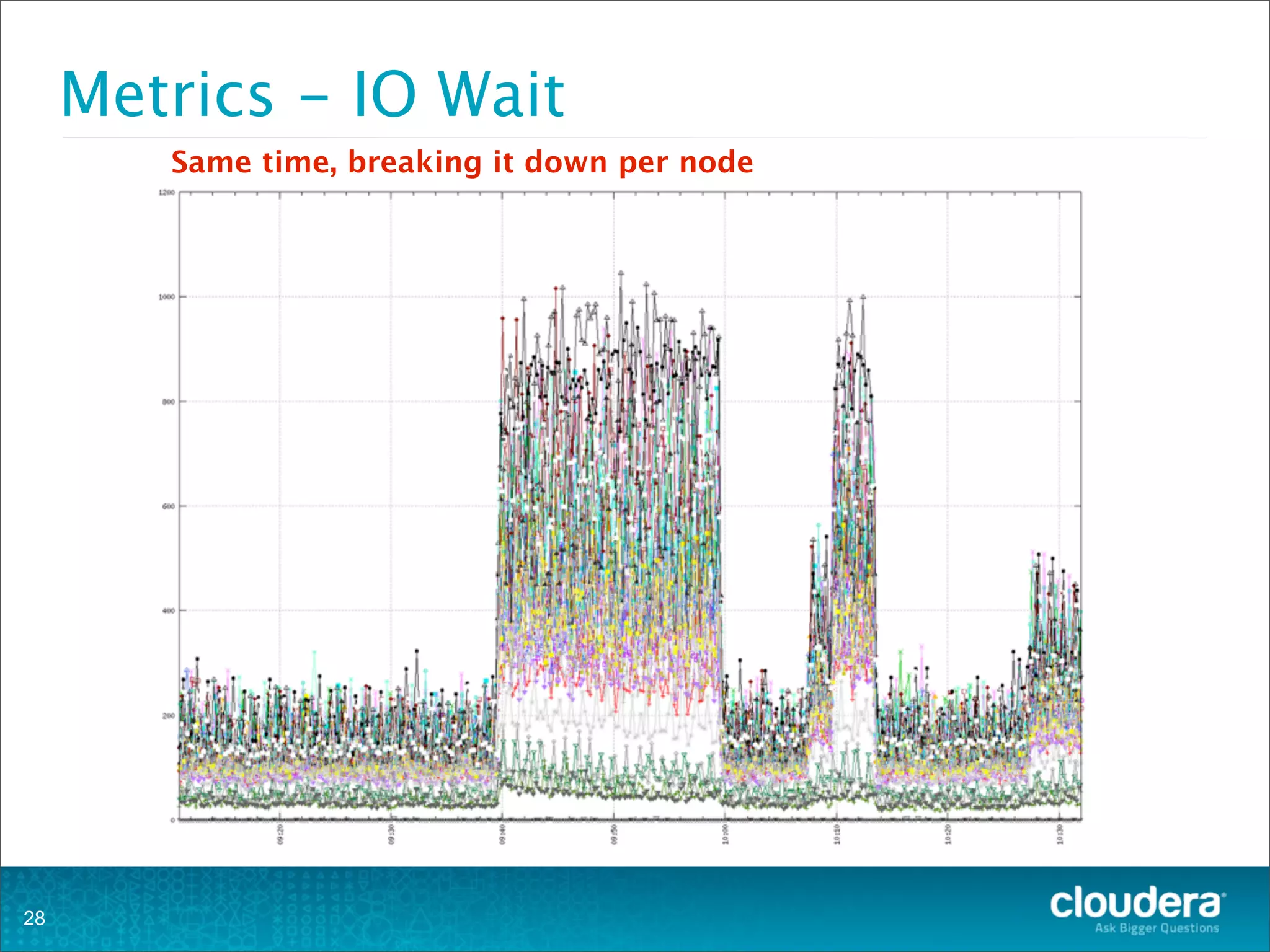
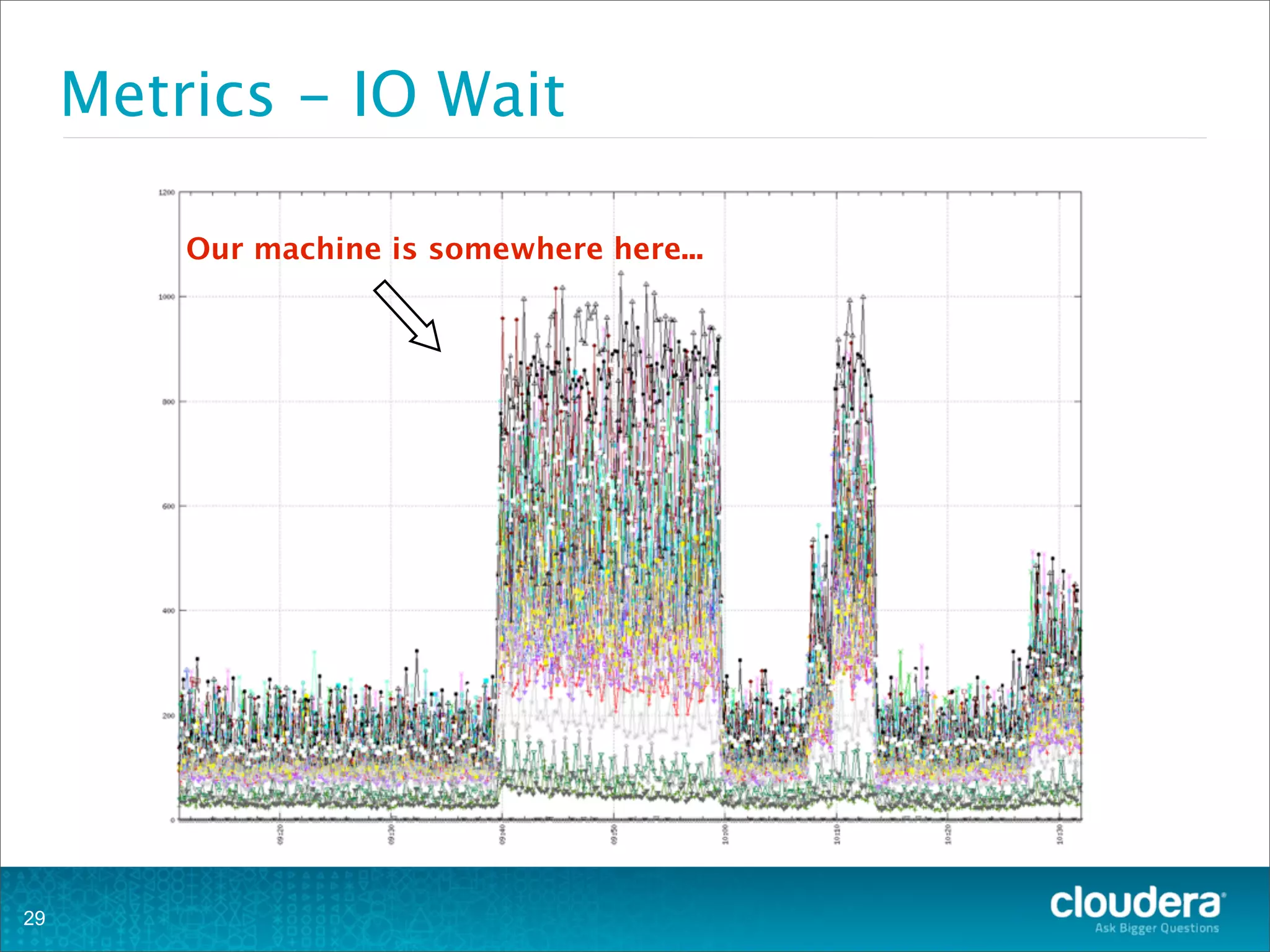




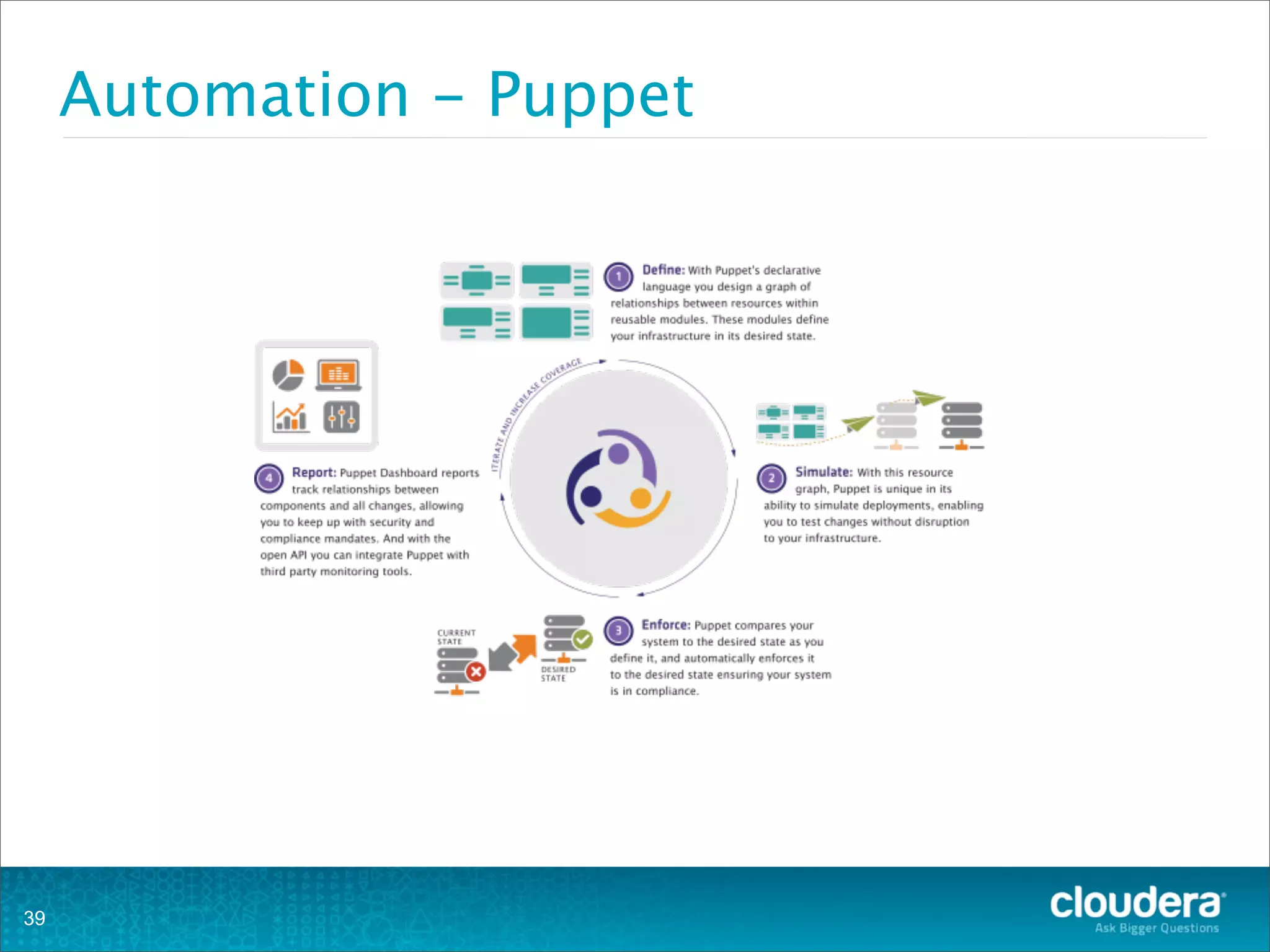
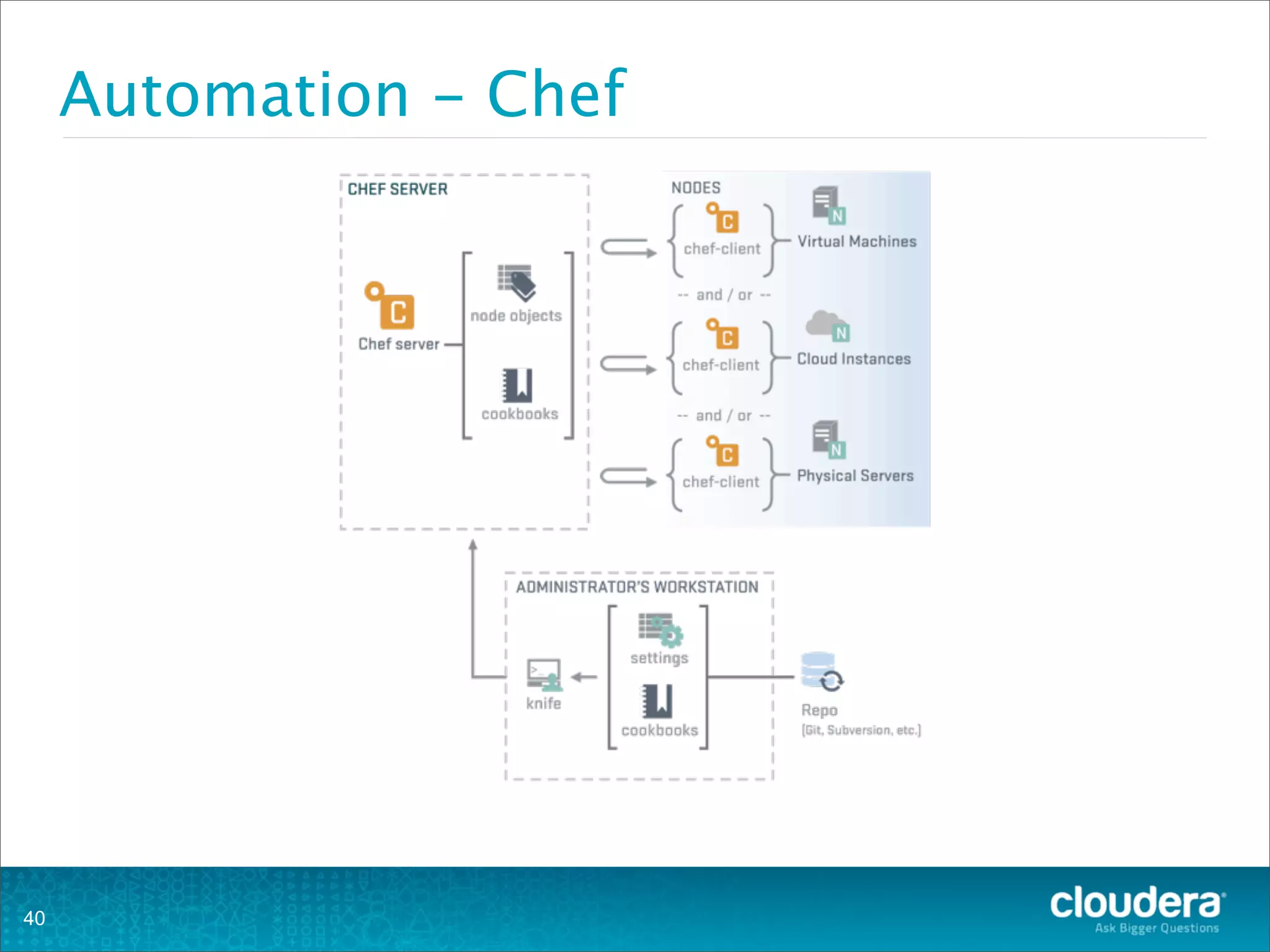


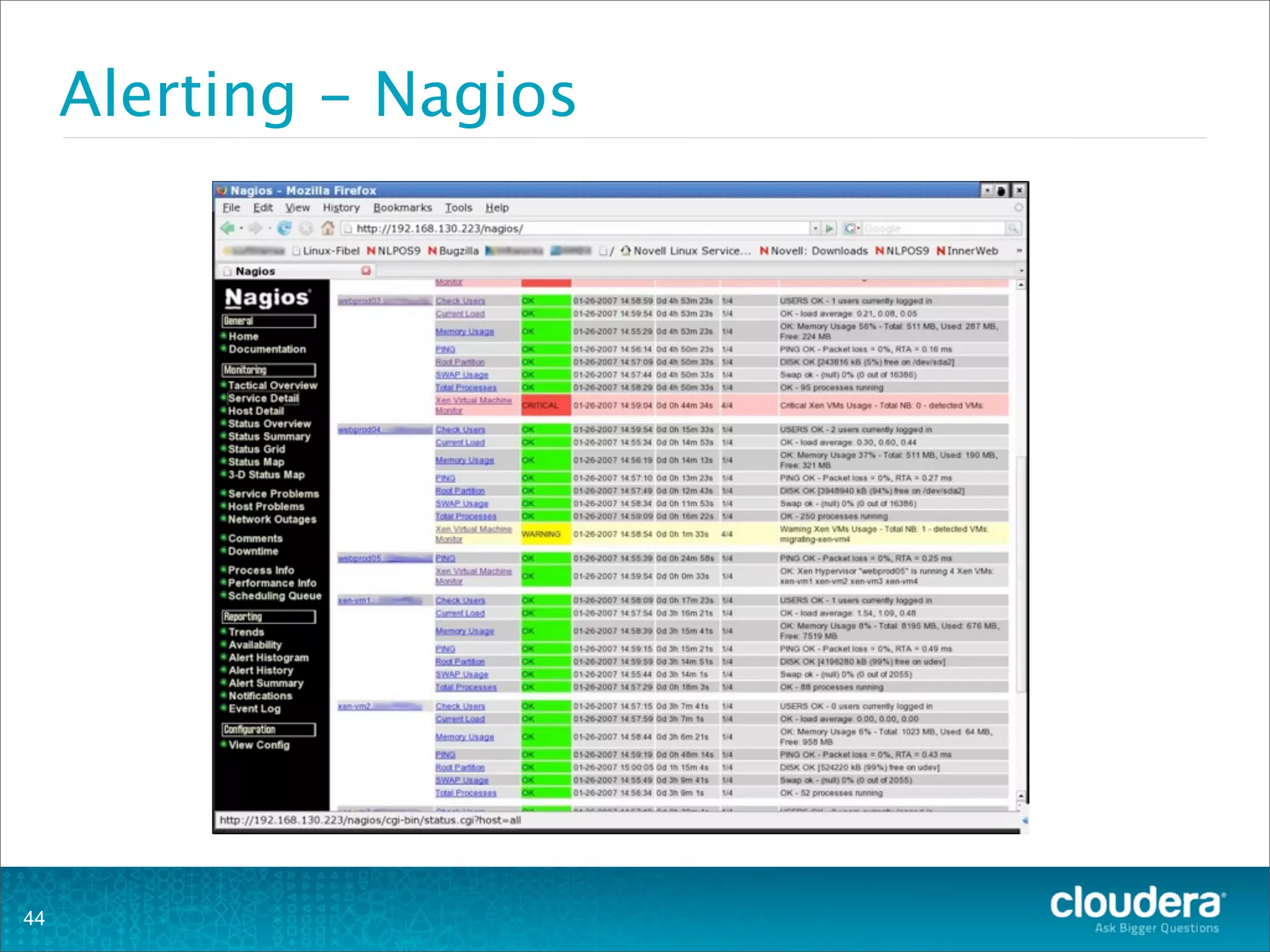









This document provides an overview of operating HBase clusters in production environments. It discusses leveraging existing knowledge of distributed systems, getting metrics set up using tools like Ganglia and OpenTSDB, automating tasks with Puppet, Chef and Fabric, setting up alerting with Nagios and Zabbix, and different backup strategies for HBase including offline distcp backups, replication to another cluster, and using HBase snapshots. The goals are to help operations teams understand how to manage HBase and empower them to work with their own operations organizations.











































































































