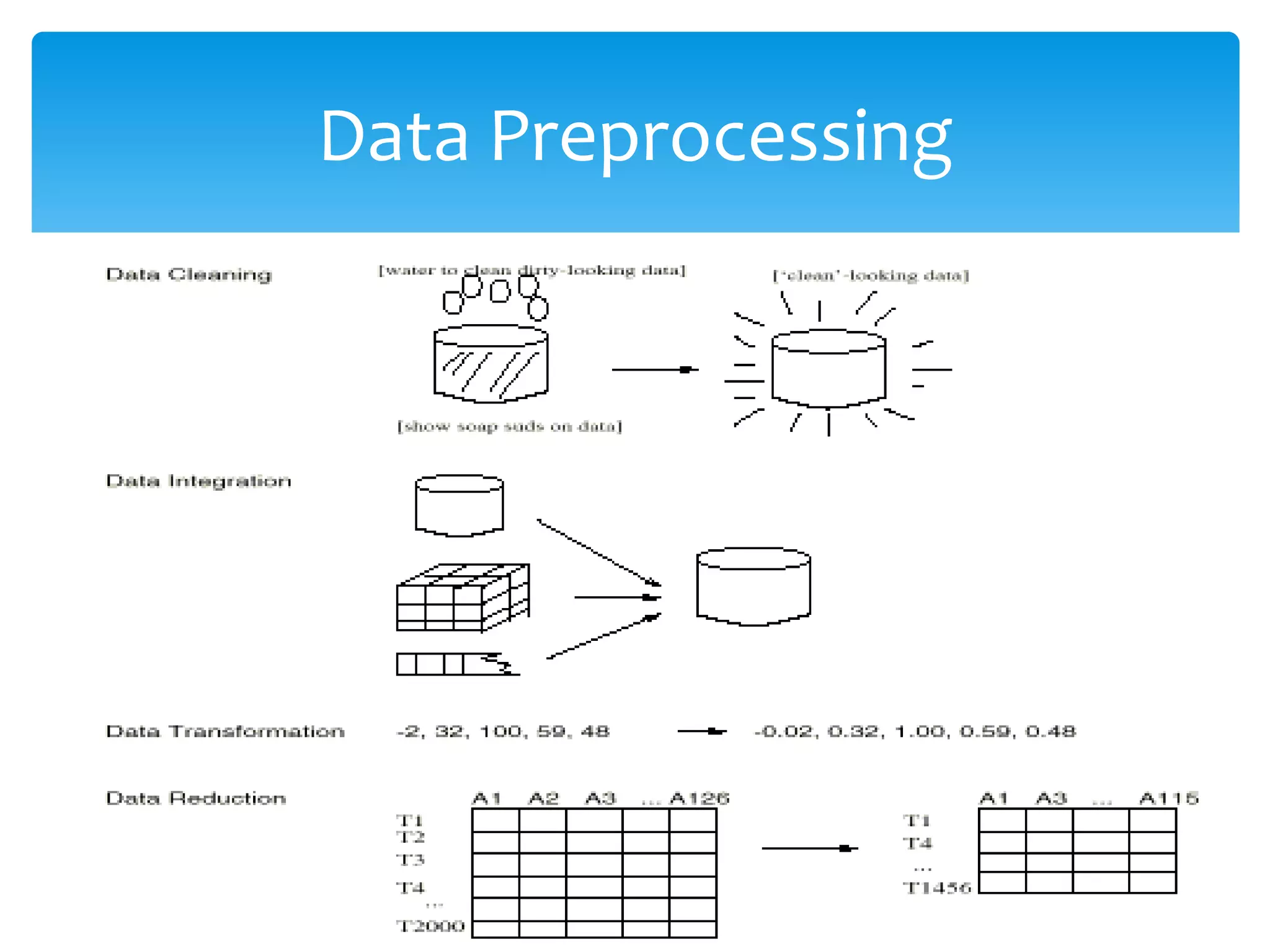
This document discusses various techniques for data preprocessing including data cleaning, integration, transformation, reduction, and discretization. The major tasks covered are filling in missing values, removing outliers, data integration, normalization, aggregation, dimensionality reduction, data cube aggregation, and discretization of continuous attributes. The goal of these techniques is to prepare raw data for analysis by handling issues like inconsistent, missing, or noisy data and reducing large volumes of data while retaining the most important information.







![Data Transformation: Normalization
Min-max normalization: to [new_minA, new_maxA]
v'
v minA
(new _ maxA new _ minA) new _ minA
maxA minA
Ex.
Let income range $12,000 to $98,000 normalized to
[0.0, 1.0]. Then $73,000 is mapped to
73,600
98,000
12 ,000
(1.0 0)
12 ,000
0
0.716](https://image.slidesharecdn.com/datapreprocessing-140304023616-phpapp01/75/Data-preprocessing-9-2048.jpg)
























































































