This document discusses data preprocessing techniques for transforming raw data into an understandable format. It describes measures for data quality such as accuracy, completeness, and consistency. The major tasks in data preprocessing are outlined as data cleaning, integration, reduction, transformation, and discretization. Data cleaning involves handling missing values, noise, and inconsistencies. Data integration merges data from multiple sources to reduce redundancies and inconsistencies. Data reduction techniques include aggregation, attribute selection, and dimensionality reduction to obtain a smaller data representation. Data transformation consolidates data into appropriate forms for mining through techniques like smoothing, aggregation, generalization, and normalization. Data discretization divides continuous attributes into intervals to reduce data size and prepare for further analysis.
In this document
Powered by AI
Introduction to data preprocessing by S. Dinesh Babu, highlighting the significance in handling raw data.
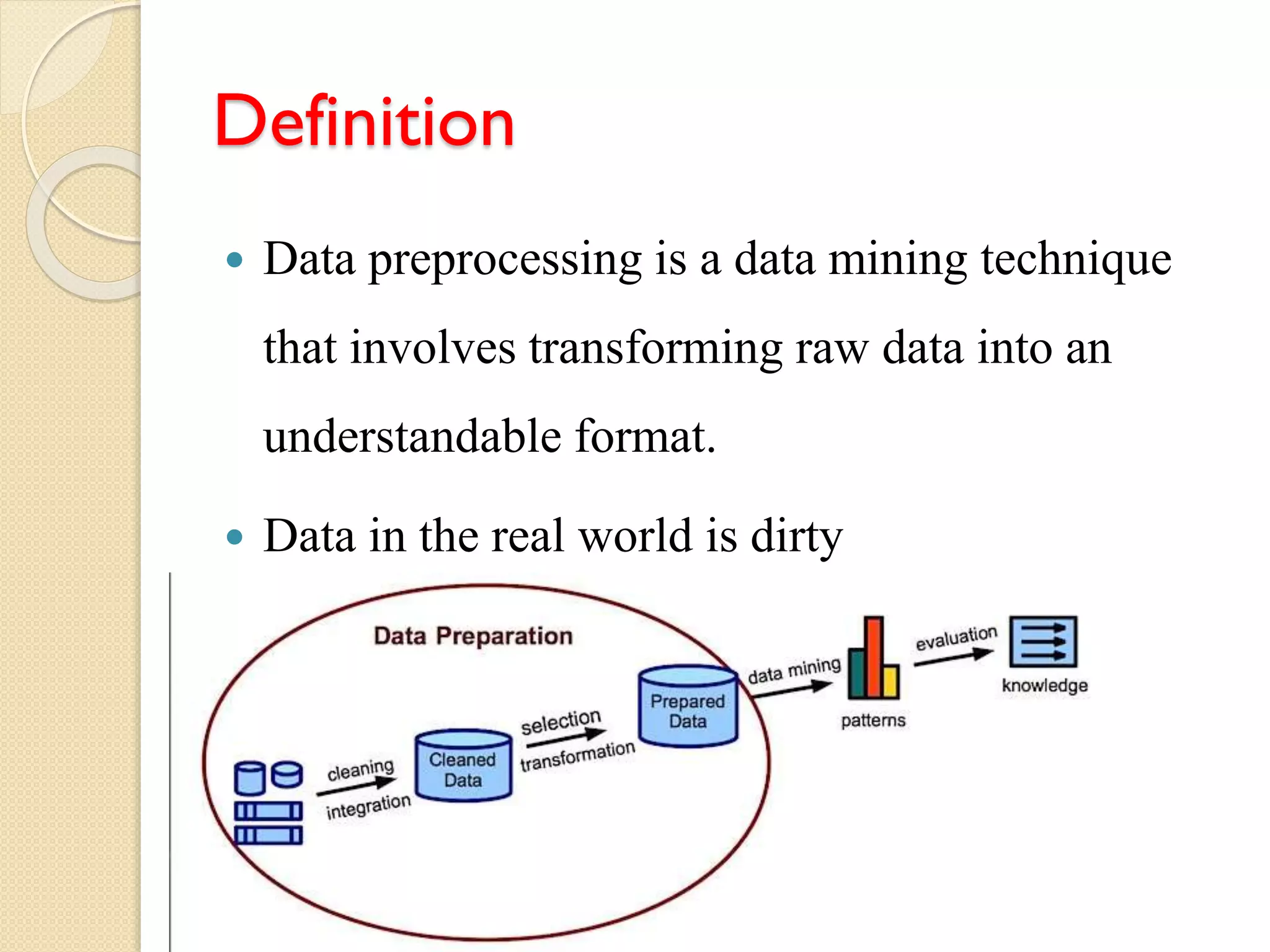
Data preprocessing transforms raw data, addressing real-world data issues described as 'dirty'.
Multidimensional view on data quality: accuracy, completeness, consistency, timeliness, believability, interpretability.
Major tasks of data preprocessing include cleaning, integration, reduction, transformation, and discretization.
Incomplete data issues such as missing values due to entry errors or misunderstanding.
Challenges with noisy data; causes include unstructured data and programming errors impacting storage.
Data cleaning process: identifying discrepancies due to poor design and human errors.
Rules for data integrity: unique values, consecutive data checks, and handling null values.
Data integration merges data from different sources to improve accuracy and minimize redundancy.
Data reduction strategies, including cube aggregation and attribute subset selection to reduce data volume.
Further strategies for data reduction: dimensionality and numerosity reduction using various methods.
Data transformation methods, including smoothing, aggregation, generalization, and normalization.
Data discretization involves dividing attribute ranges into intervals for reduced data size and analysis.
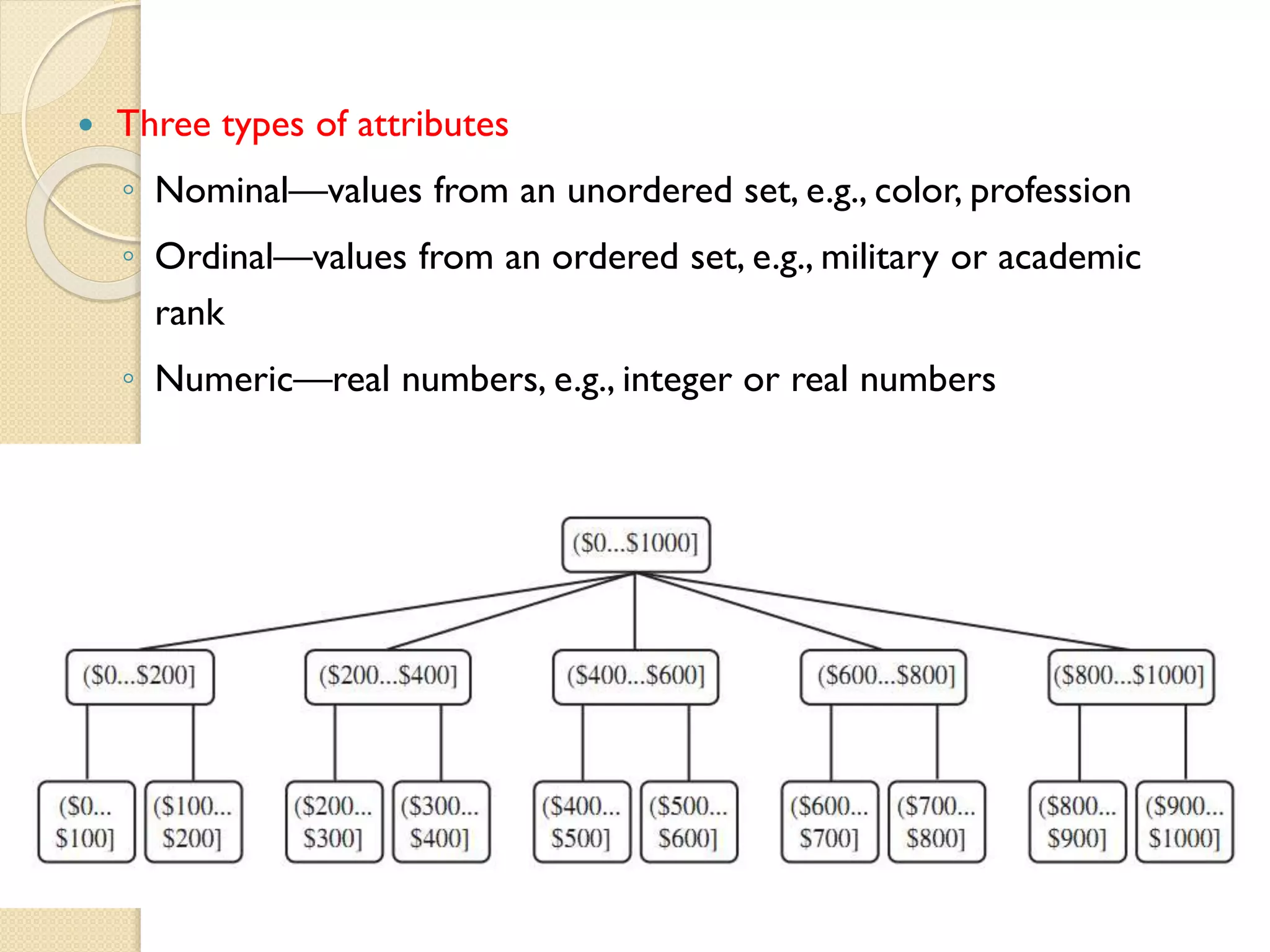
Three types of attributes in data: nominal, ordinal, and numeric.
Definition
Data preprocessingis a data mining technique
that involves transforming raw data into an
understandable format.
Data in the real world is dirty
3.
Measures for dataquality:A multidimensional view
◦ Accuracy: correct or wrong, accurate or not
◦ Completeness: not recorded, unavailable, …
◦ Consistency: some modified but some not,
dangling, …
◦ Timeliness: timely update?
◦ Believability: how trustable the data are correct?
◦ Interpretability: how easily the data can be
understood?
4.
Major Tasks inData Preprocessing
Data Cleaning
Data Integration
Data Reduction
Data Transformation and Data
Discretization
5.
Data Cleaning: Incomplete
Data is not always available
Ex:Age:” ”;
Missing data may be due to
◦ equipment malfunction
◦ inconsistent with other recorded data and thus deleted
◦ data not entered due to misunderstanding
◦ certain data may not be considered important at the
time of entry
6.
Noisy Data
UnstructuredData.
Increases the amount of storage space .
Causes:
Hardware Failure
Programming Errors
7.
Data Cleaning asa Process
Missing values, noise, and inconsistencies contribute to
inaccurate data.
The first step in data cleaning as a process is
discrepancy detection.
Discrepancies can be caused by several factors.
Poorly designed data entry forms
human error in data entry
8.
The data shouldalso be examined regarding:
o Unique rule:
Each attribute value must be different from all other attribute
value.
o Consecutive rule
No missing values between lowest and highest values of the
attribute.
o Null rule
Specifies the use of blanks, question marks, special
characters.
9.
Data Integration
Themerging of data from multiple data stores.
It can help reduce, avoid redundancies and
inconsistencies.
It improve the accuracy and speed of the subsequent
data mining process.
10.
Data Reduction
Toobtain a reduced representation of the data set that is
much smaller in volume.
Strategies for data reduction include the following:
Data cube aggregation, where aggregation operations
are applied to the data in the construction of a data cube.
Attribute subset selection, where irrelevant, weakly
relevant, or redundant attributes or dimensions may be
detected and removed.
11.
Dimensionality reduction,where encoding mechanisms are
used to reduce the data set size.
Numerosity reduction, where the data are replaced or
estimated by alternative, smaller data representations such as
Parametric models
Nonparametric methods such as clustering, sampling,
and the use of histograms.
12.
Data Transformation
Indata transformation, the data are transformed or
consolidated into forms appropriate for mining.
Data transformation can involve the following:
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small,
specified range
min-max normalization
13.
Data Discretization
Discretization:Divide the range of a continuous attribute
into intervals
◦ Interval labels can then be used to replace actual data
values
◦ Reduce data size by Discretization
◦ Split (top-down) vs. merge (bottom-up)
◦ Discretization can be performed recursively on an
attribute
◦ Prepare for further analysis, e.g., classification
14.
Three typesof attributes
◦ Nominal—values from an unordered set, e.g., color, profession
◦ Ordinal—values from an ordered set, e.g., military or academic
rank
◦ Numeric—real numbers, e.g., integer or real numbers