Downloaded 82 times



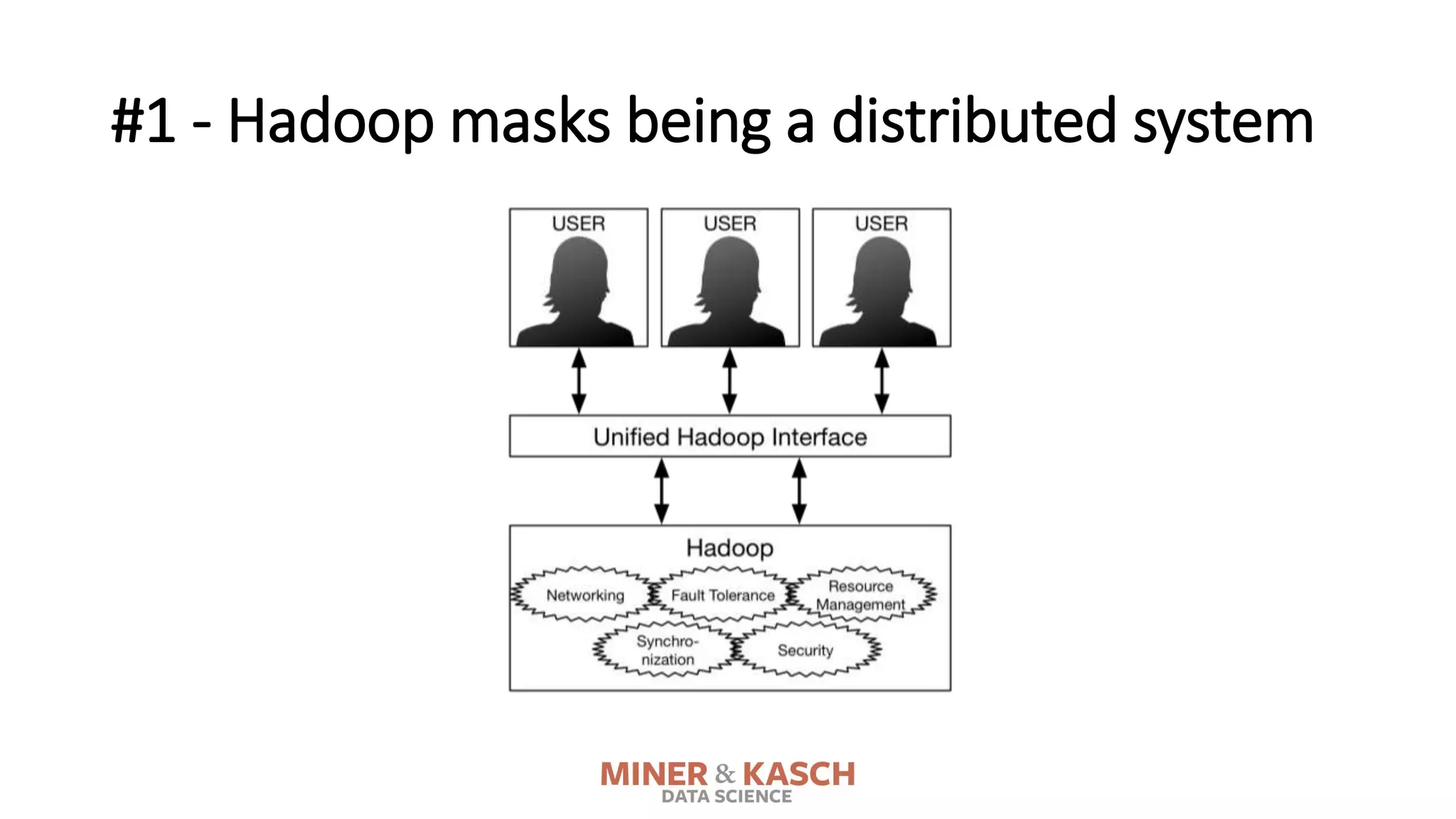
![#1 - Hadoop masks being a distributed system
// This block of code defines the behavior of the map phase
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// Split the line of text into words
StringTokenizer itr = new StringTokenizer(value.toString());
// Go through each word and send it
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
// "I've seen this word once!"
context.write(word, one);
}
}
[1]$ hadoop fs -put hamlet.txt datz/hamlet.txt
[2]$ hadoop fs -put macbeth.txt data/macbeth.txt
[3]$ hadoop fs -mv datz/hamlet.txt data/hamlet.txt
[4]$ hadoop fs -ls data/
-rw-r–r– 1 don don 139k 2012-01-31 23:49 /user/don/data/caesar.txt
-rw-r–r– 1 don don 180k 2013-09-25 20:45 /user/don/data/hamlet.txt
-rw-r–r– 1 don don 117k 2013-09-25 20:46 /user/don/data/macbeth.txt](https://image.slidesharecdn.com/tenthingsabouthadoop-160331185744/75/10-concepts-the-enterprise-decision-maker-needs-to-understand-about-Hadoop-5-2048.jpg)


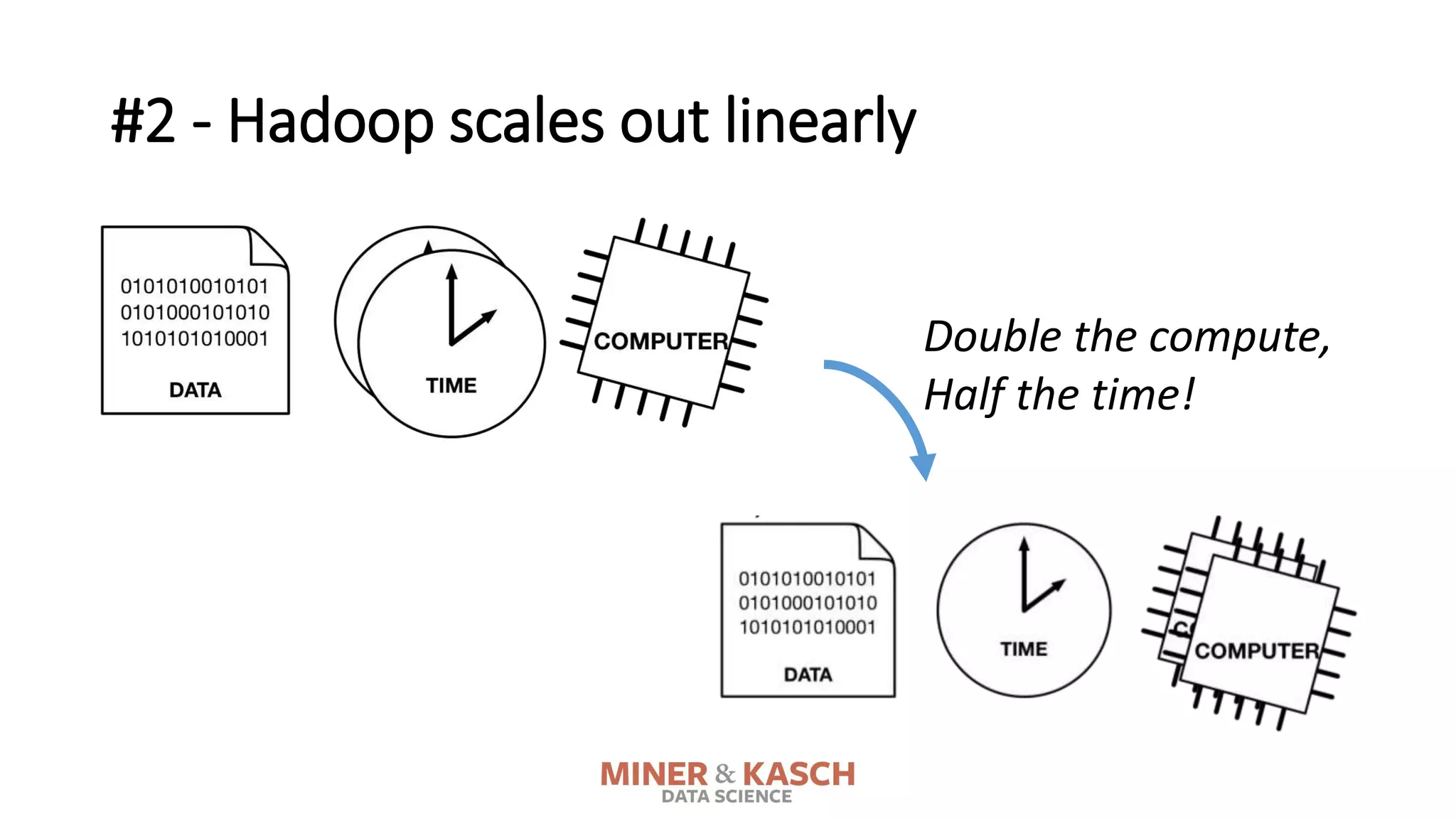
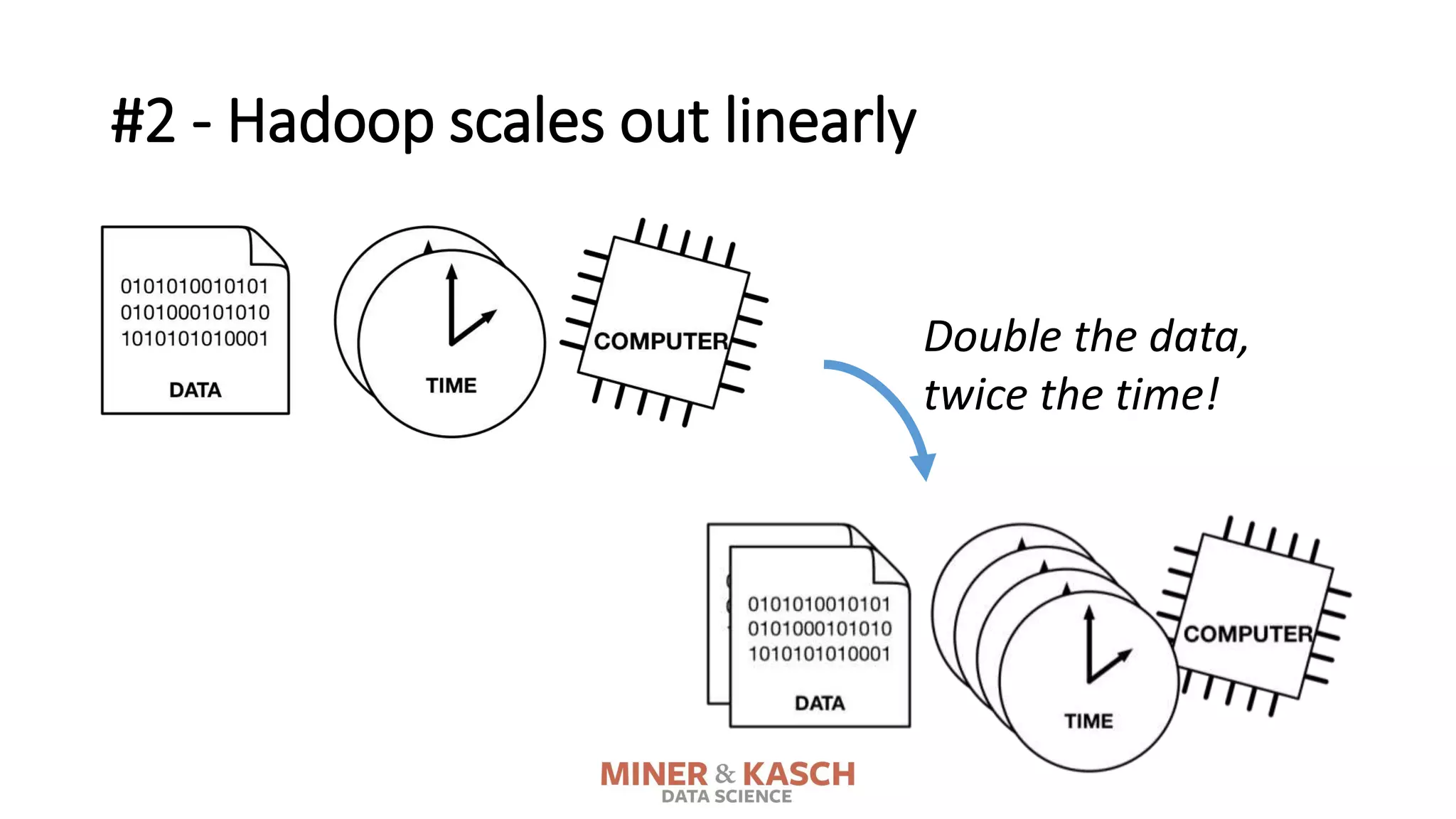
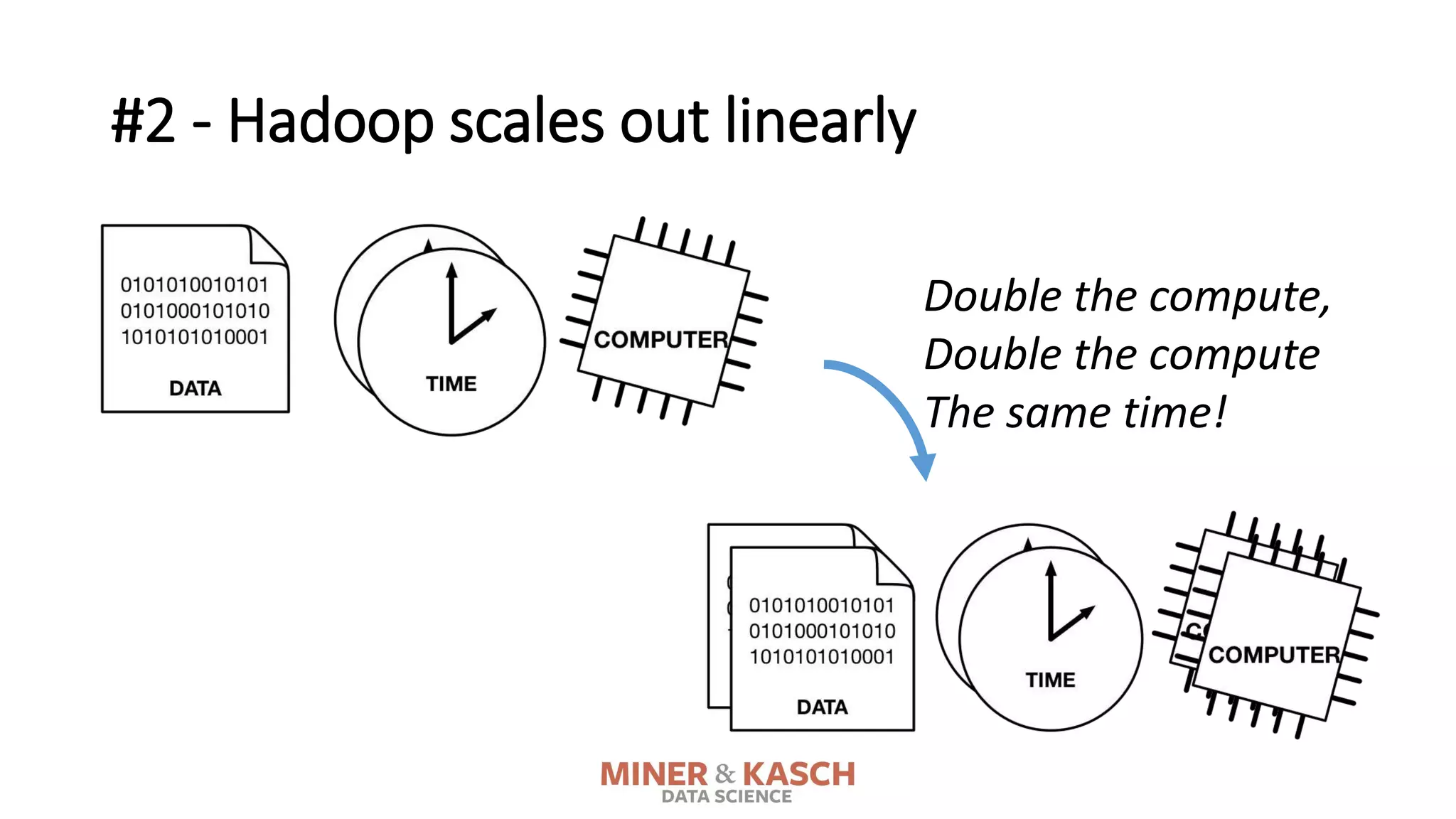
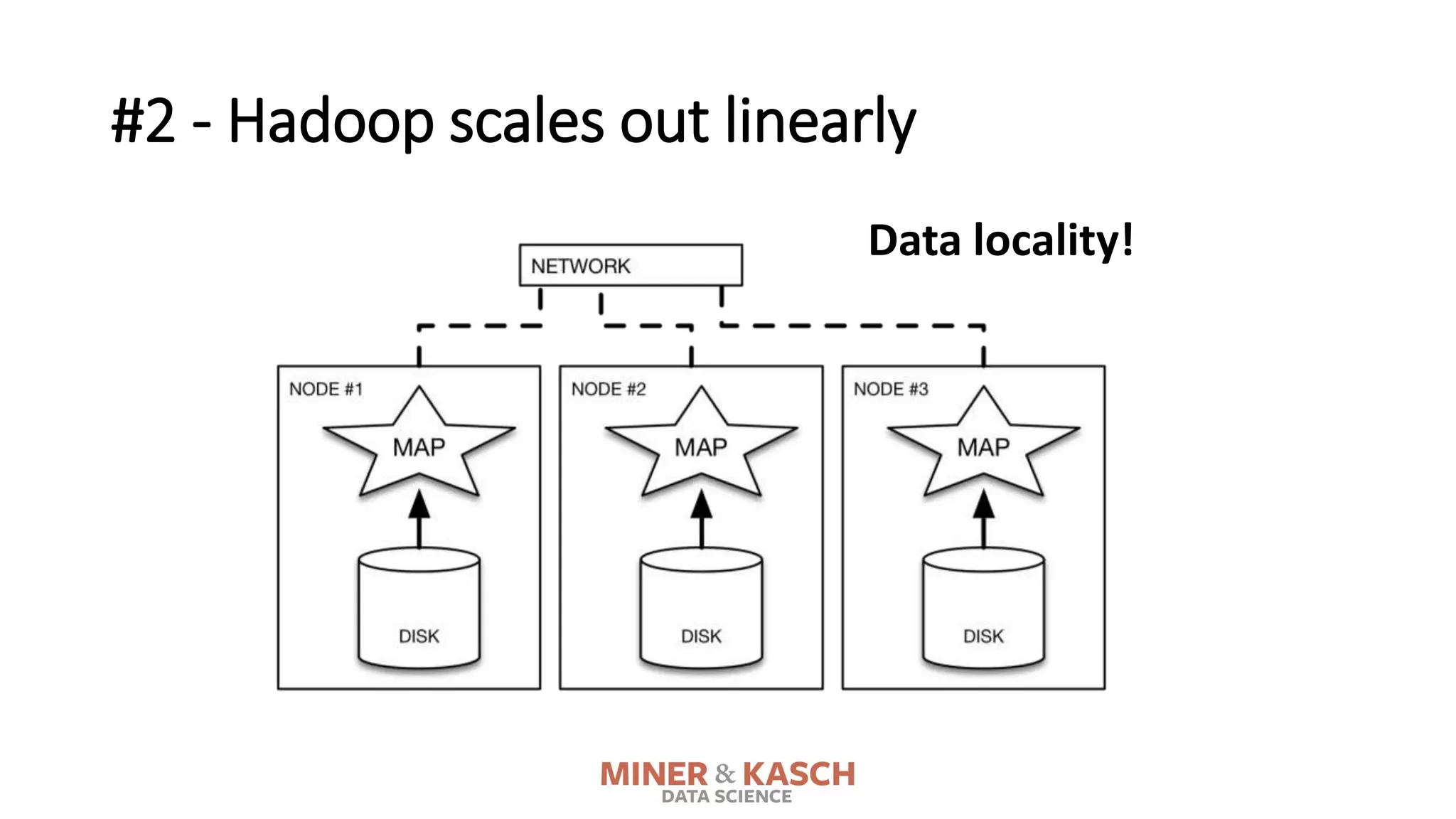








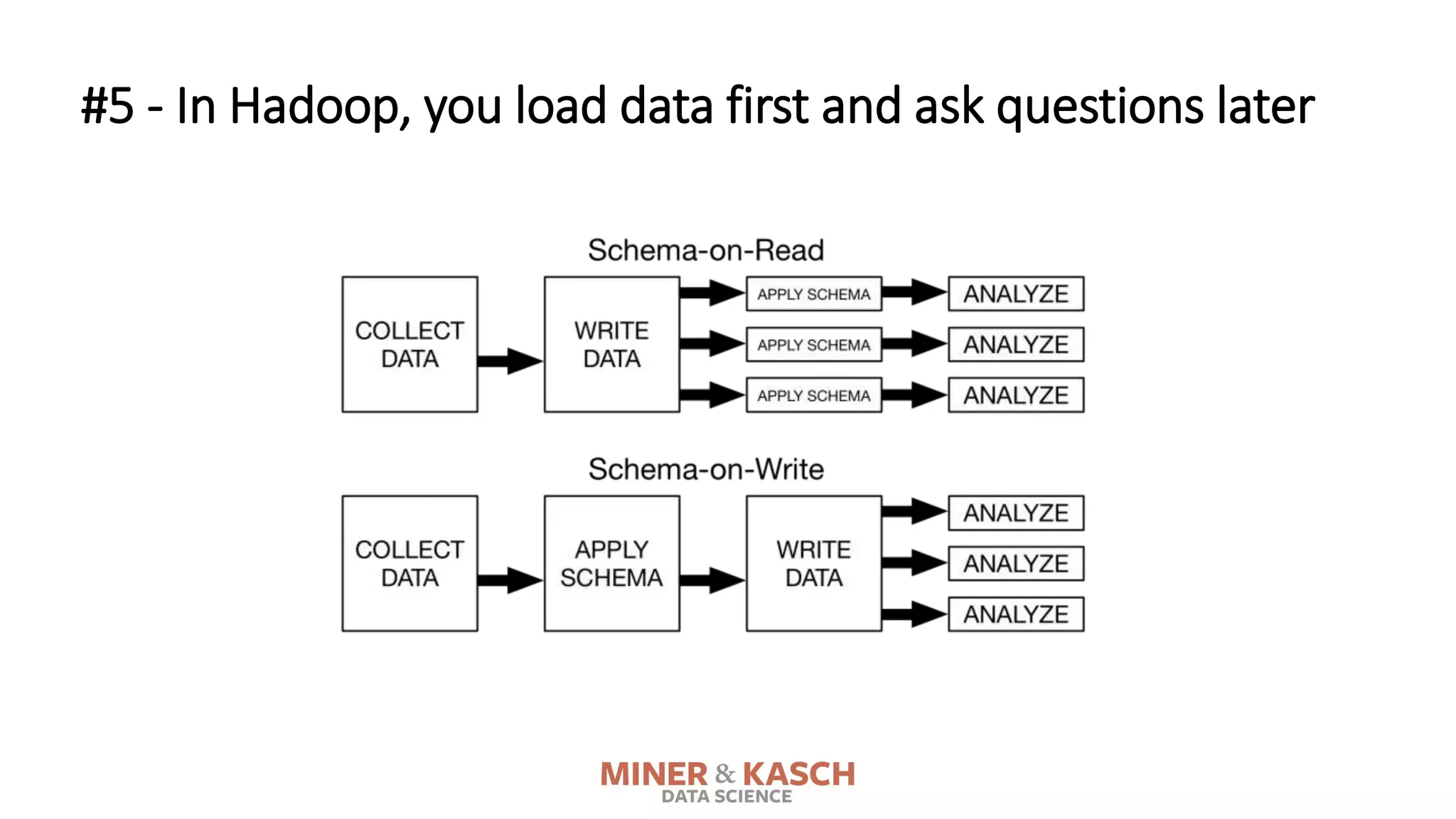

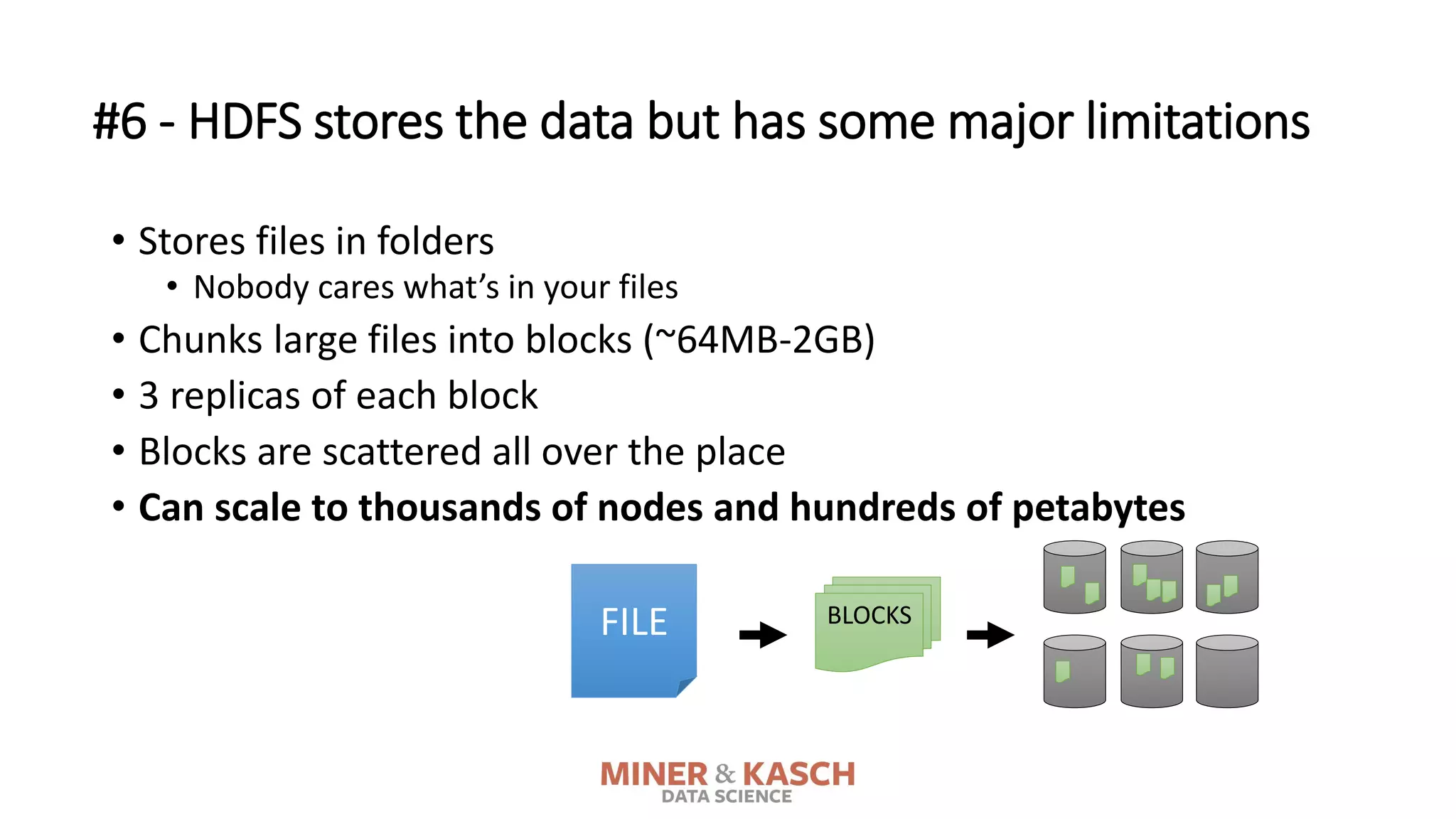




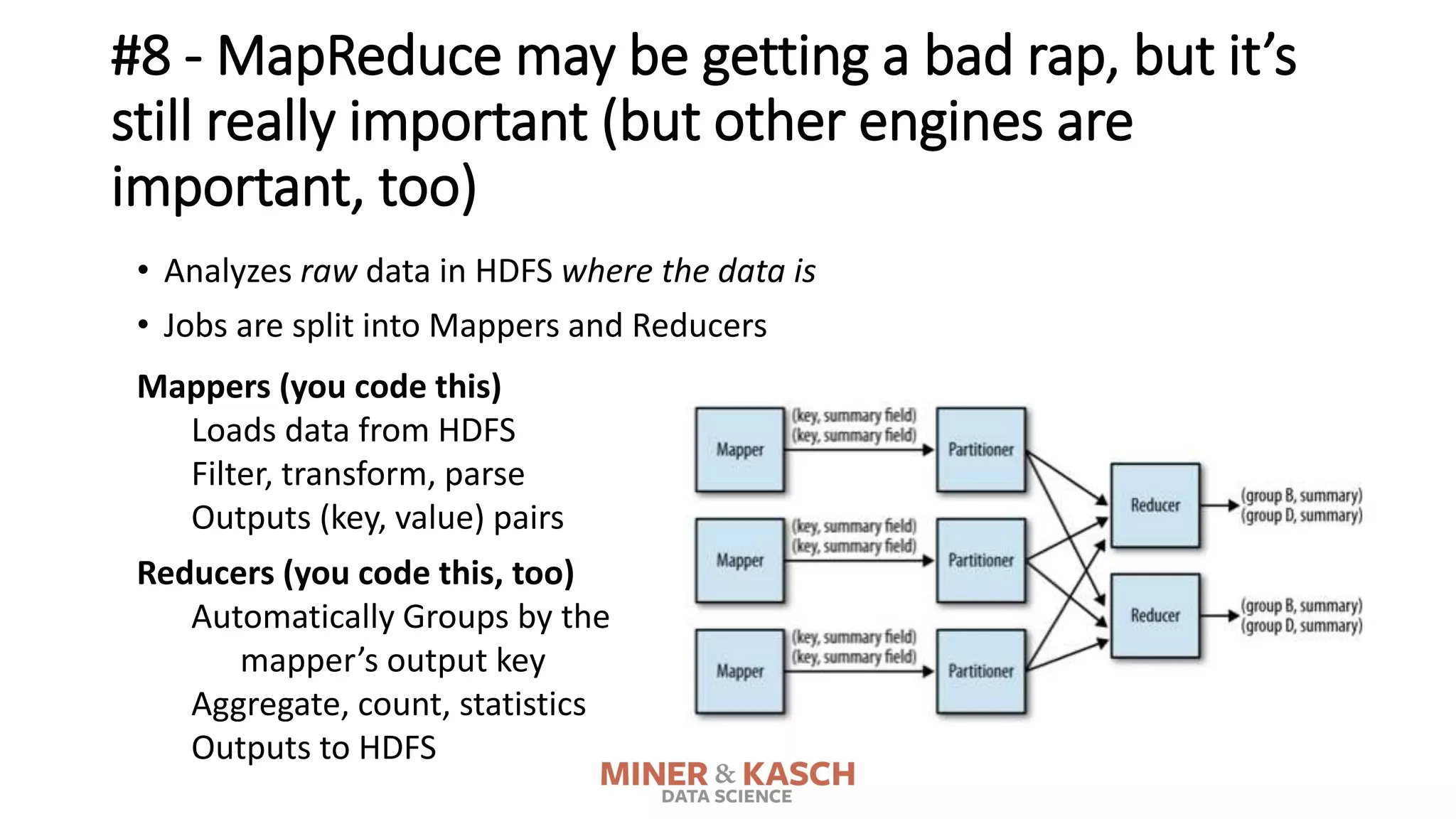

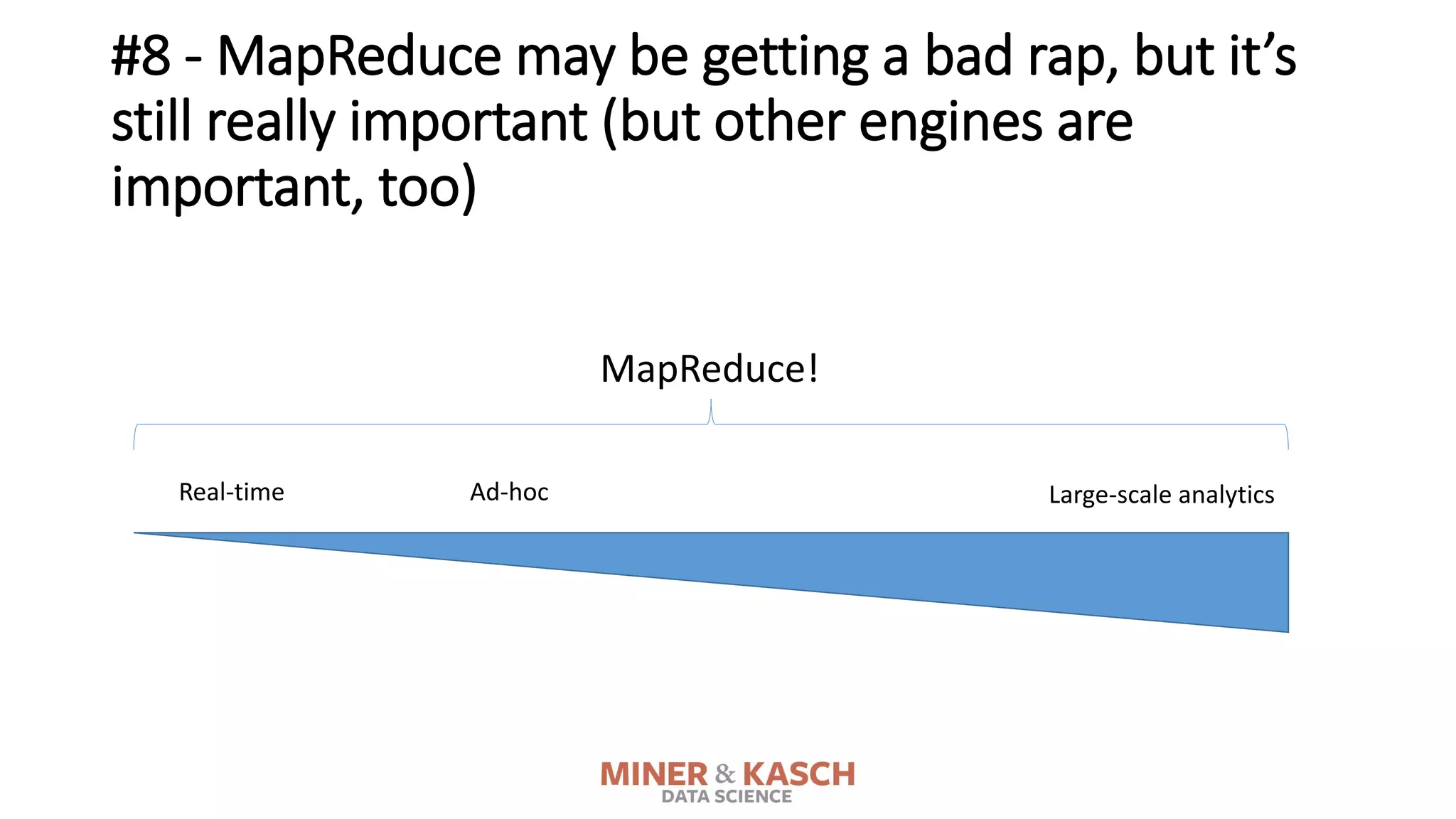
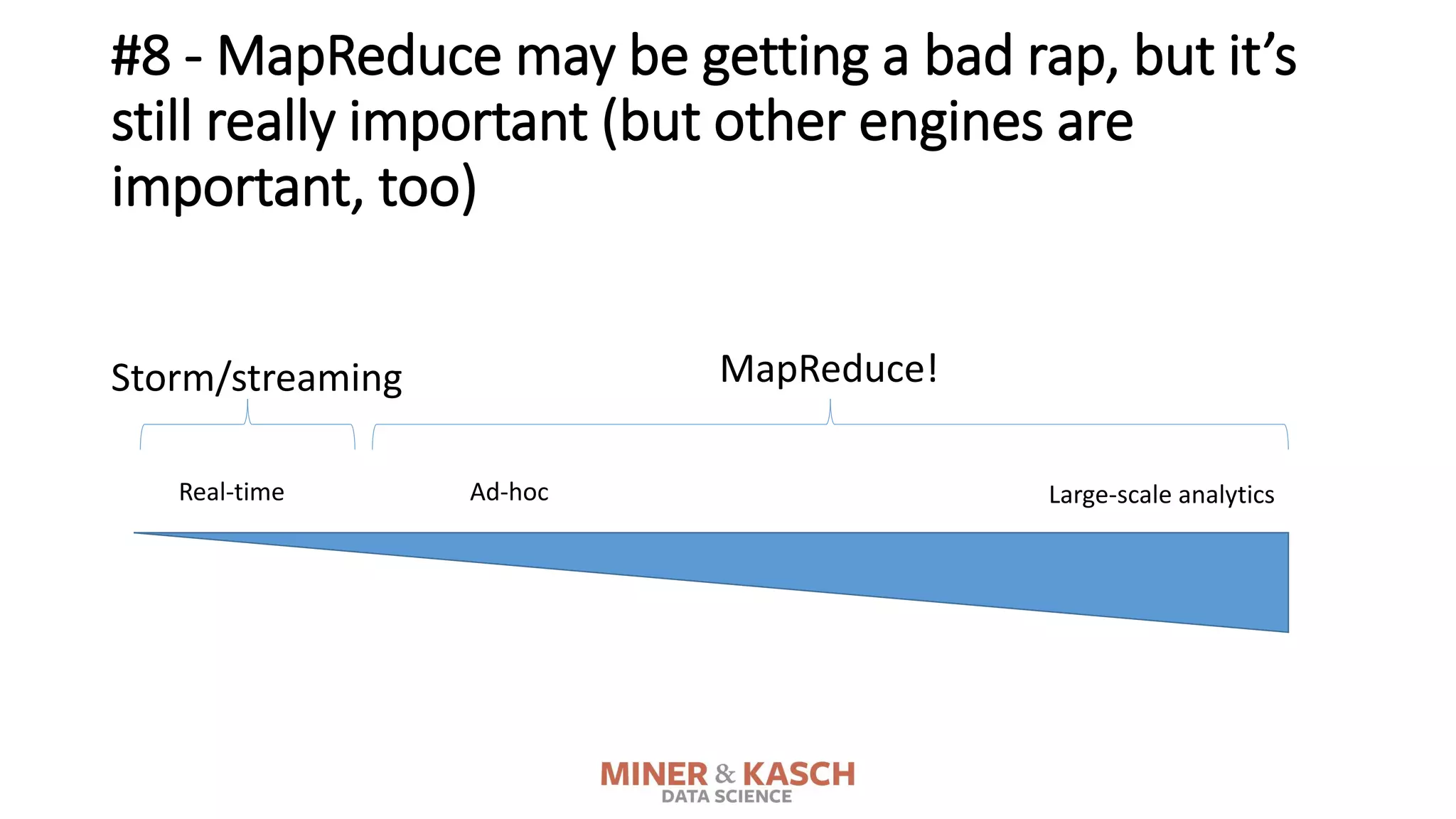
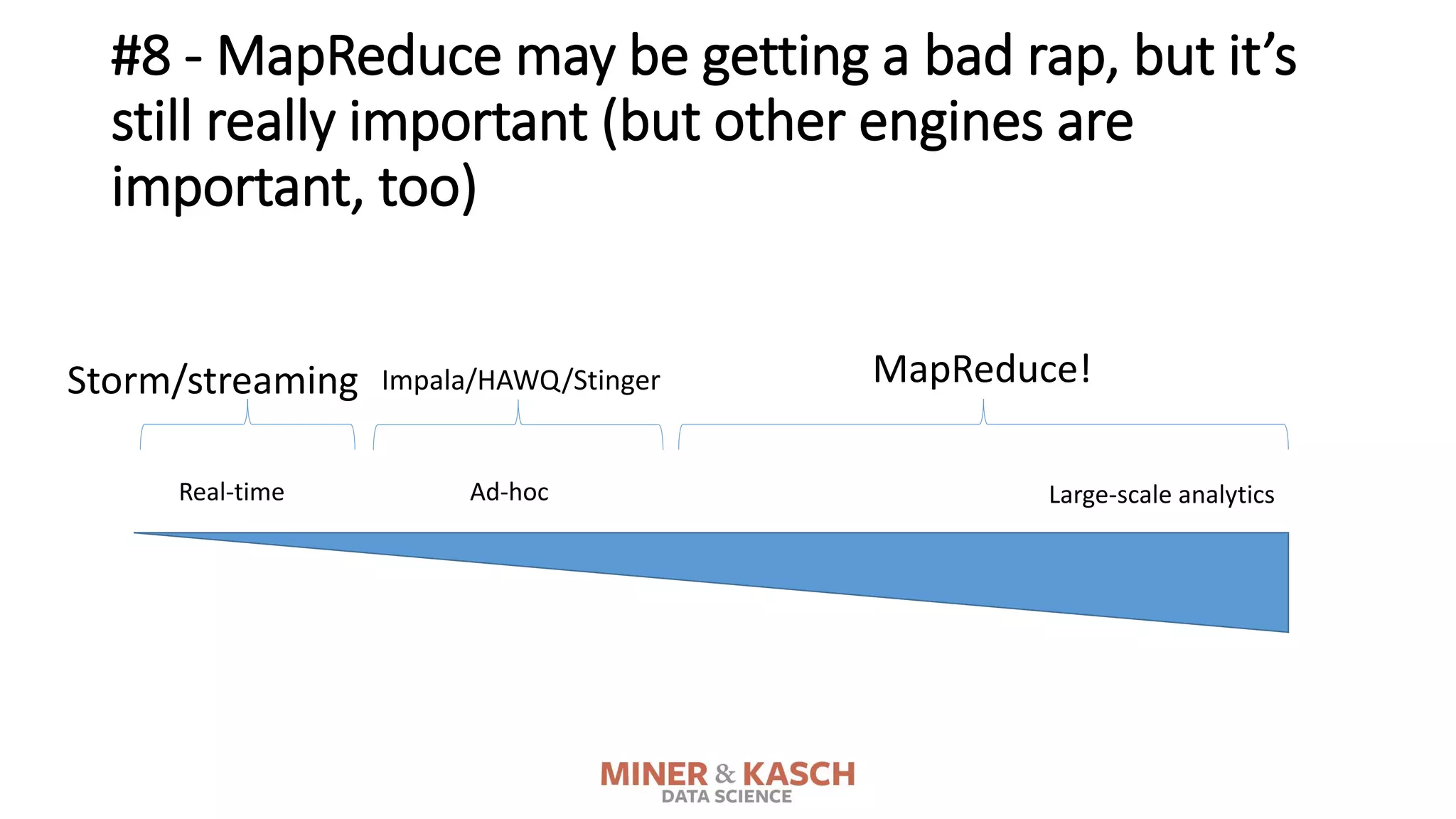
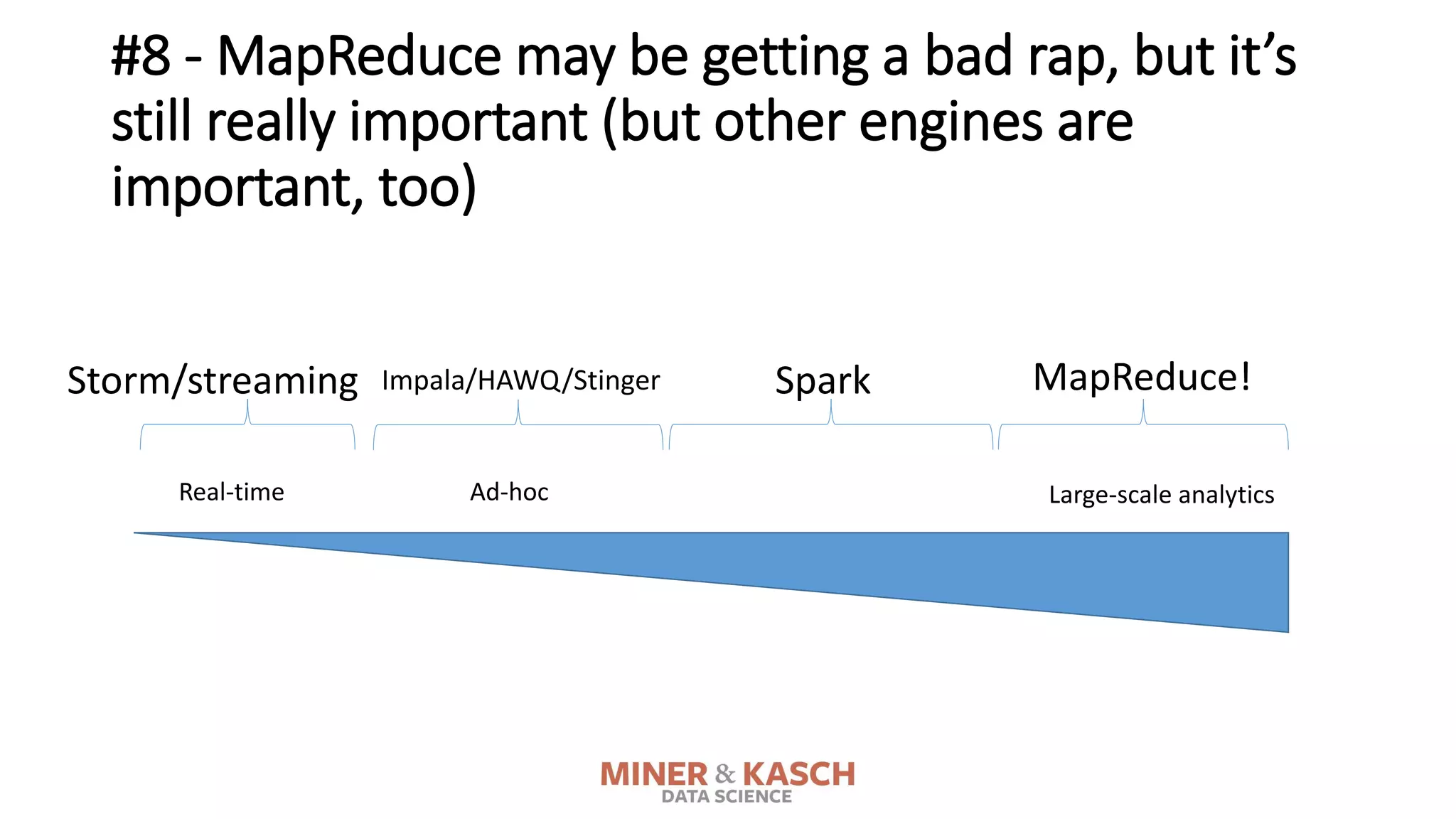
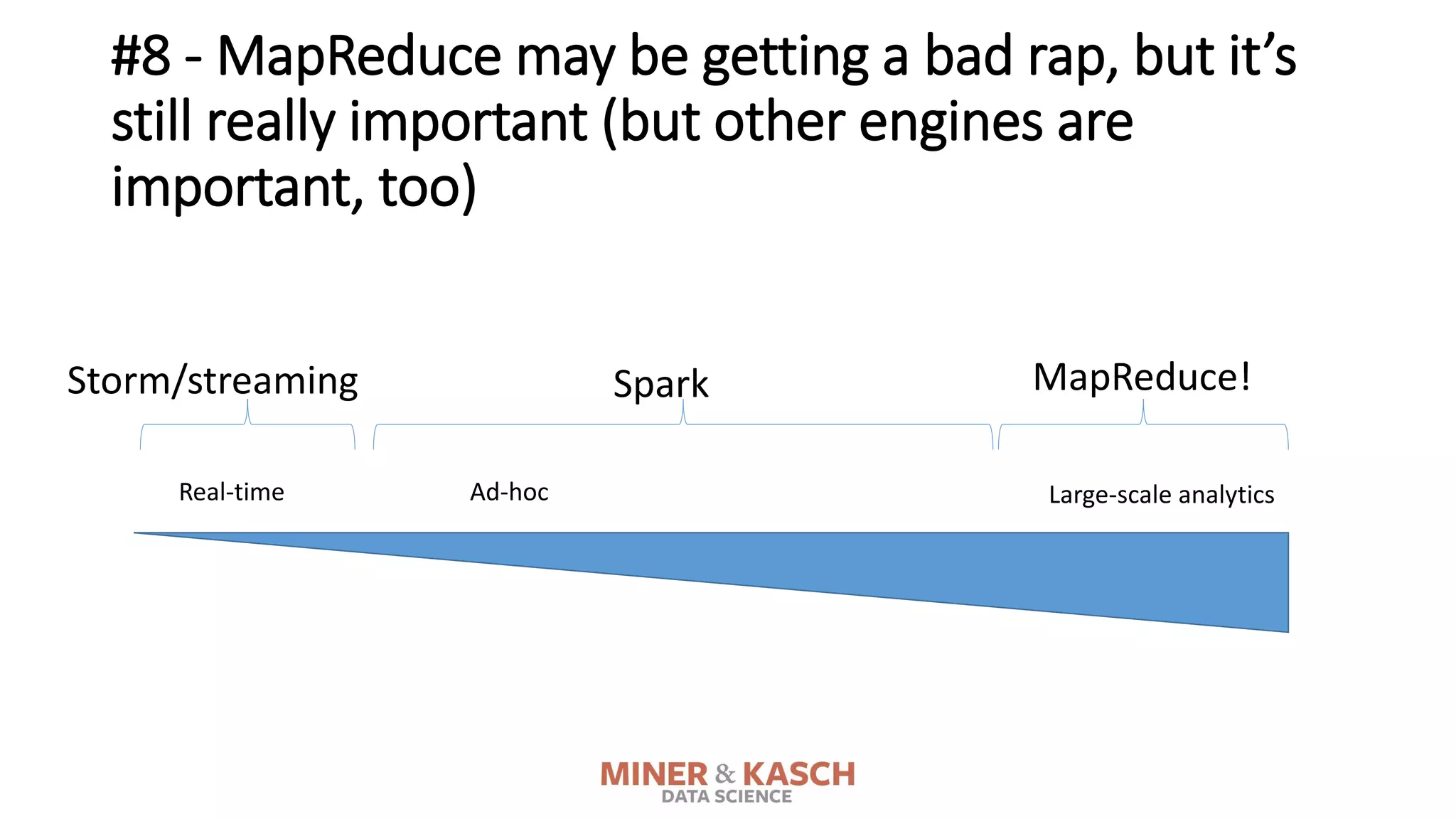
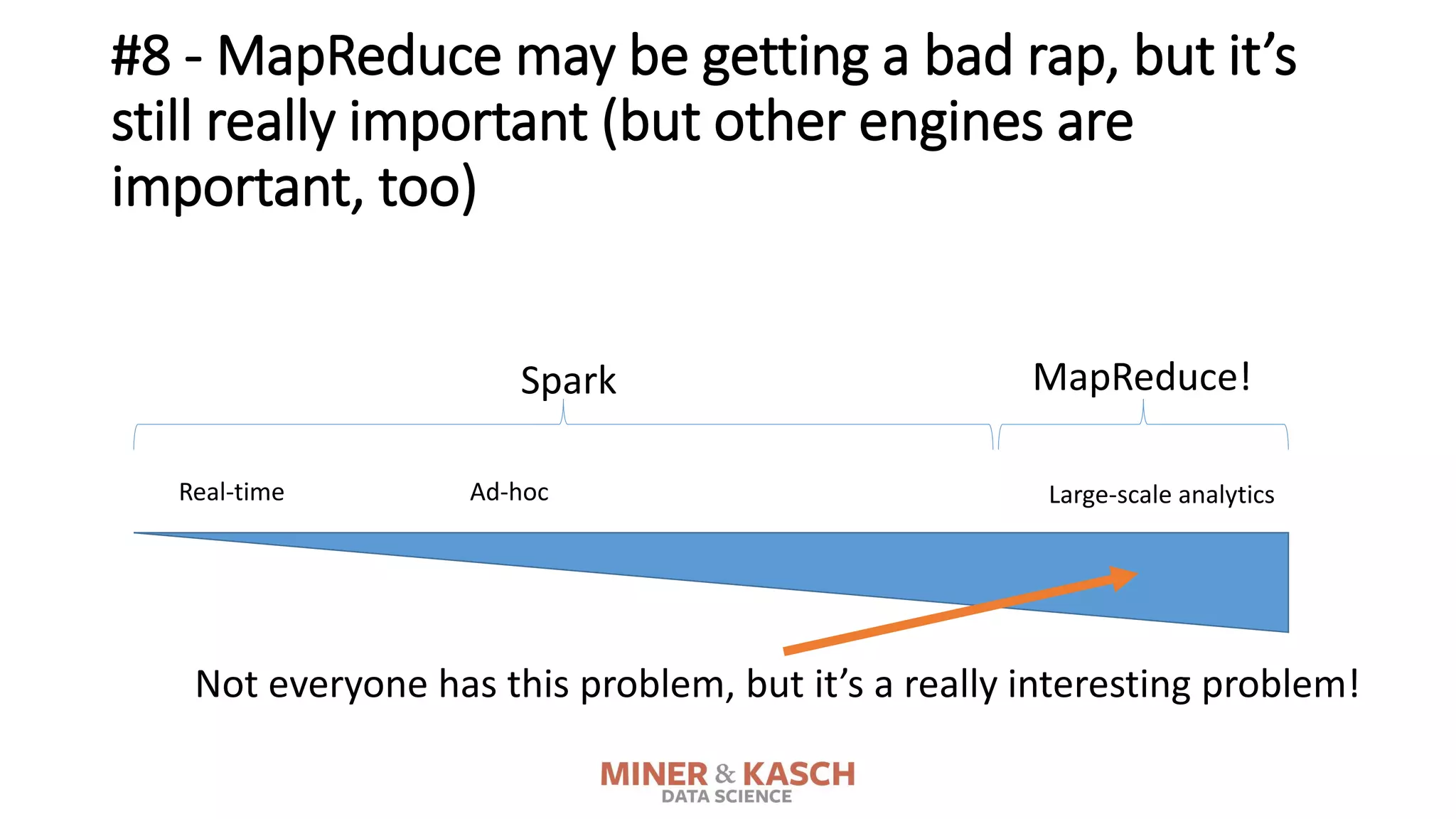



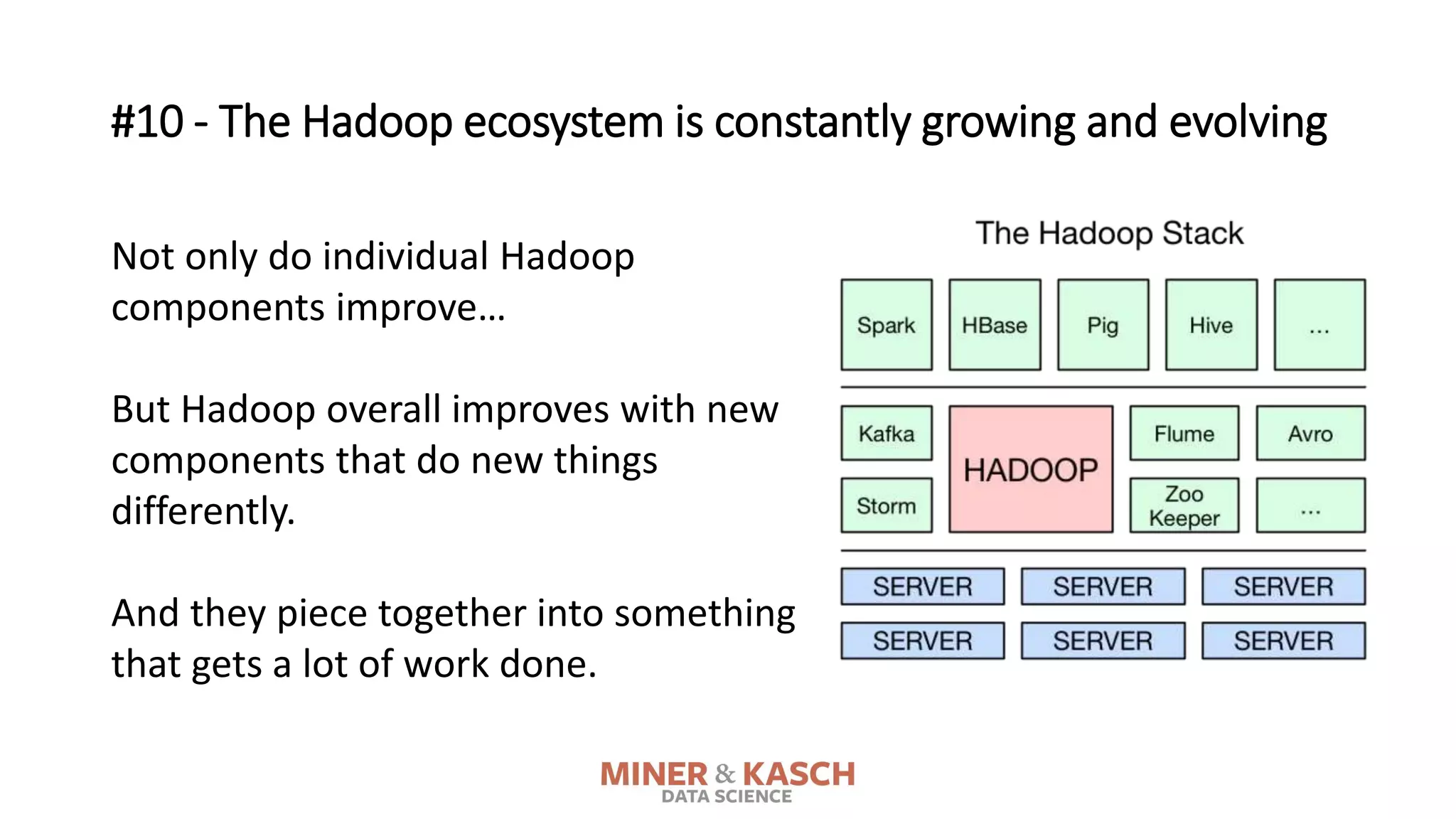




The document outlines ten key concepts that enterprise decision makers must understand about Hadoop, including its popularities such as running on commodity hardware and handling unstructured data. It addresses Hadoop's limitations, the importance of YARN for resource management, and the relevance of MapReduce despite common criticisms. The document also highlights the open-source nature of Hadoop and the evolving ecosystem surrounding it.





















































































