Download as PDF, PPTX




























![Thank You!
Contact me at [pavel at basho dot com]](https://image.slidesharecdn.com/8apavelhardak-170215221111/75/Using-Spark-and-Riak-for-IoT-Apps-Patterns-and-Anti-Patterns-Spark-Summit-East-talk-Pavel-Hardak-46-2048.jpg)

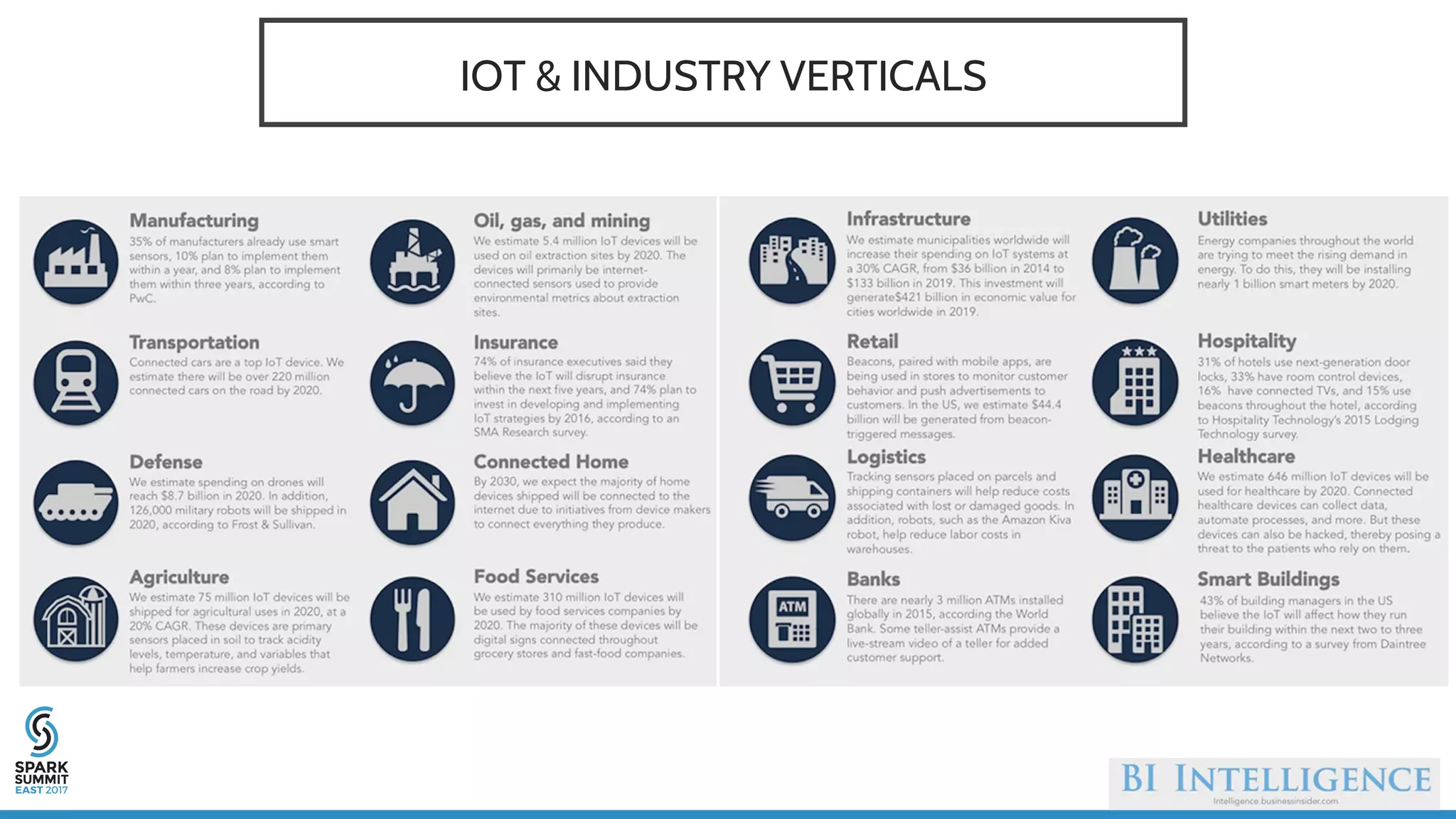
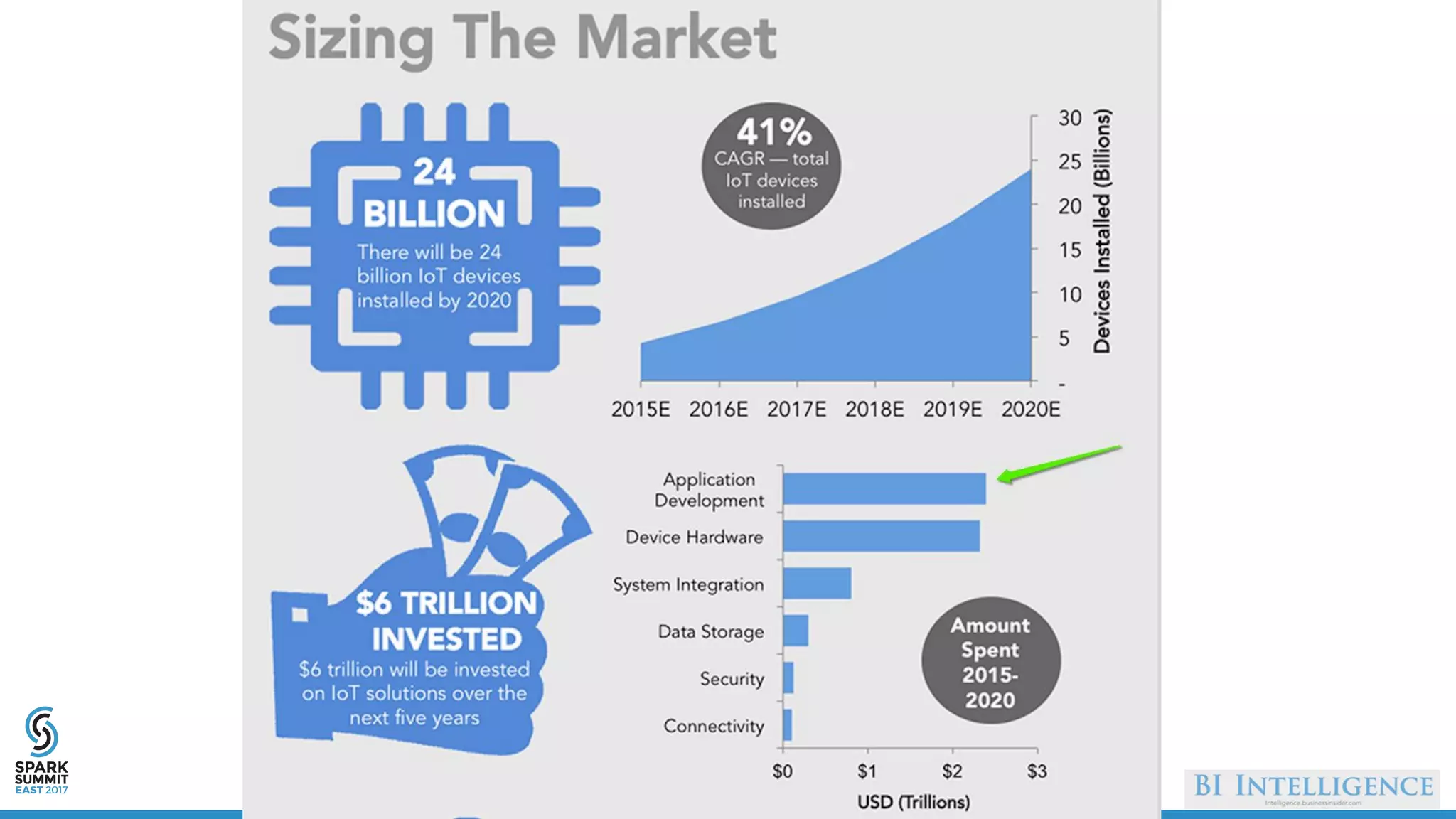
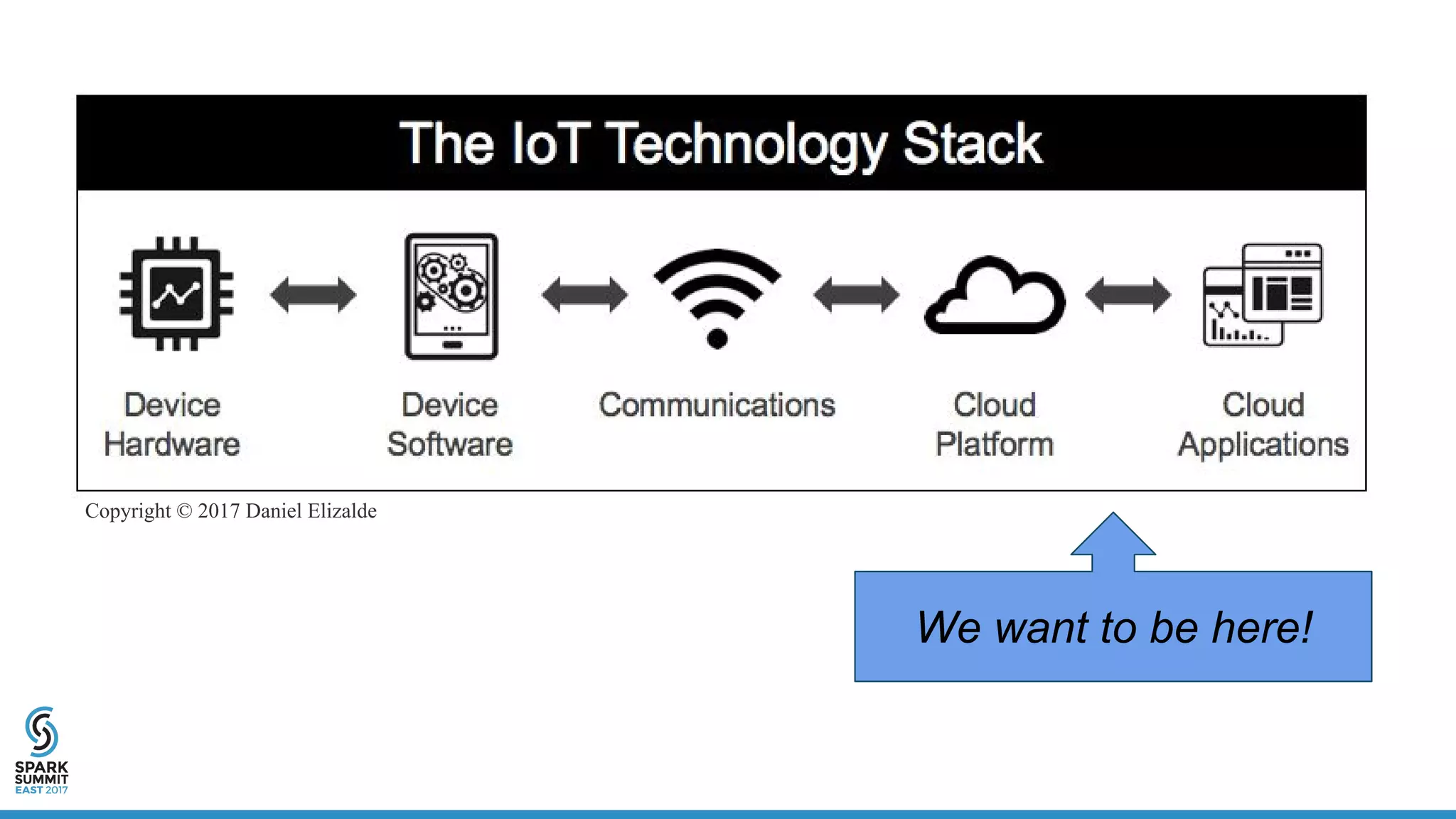
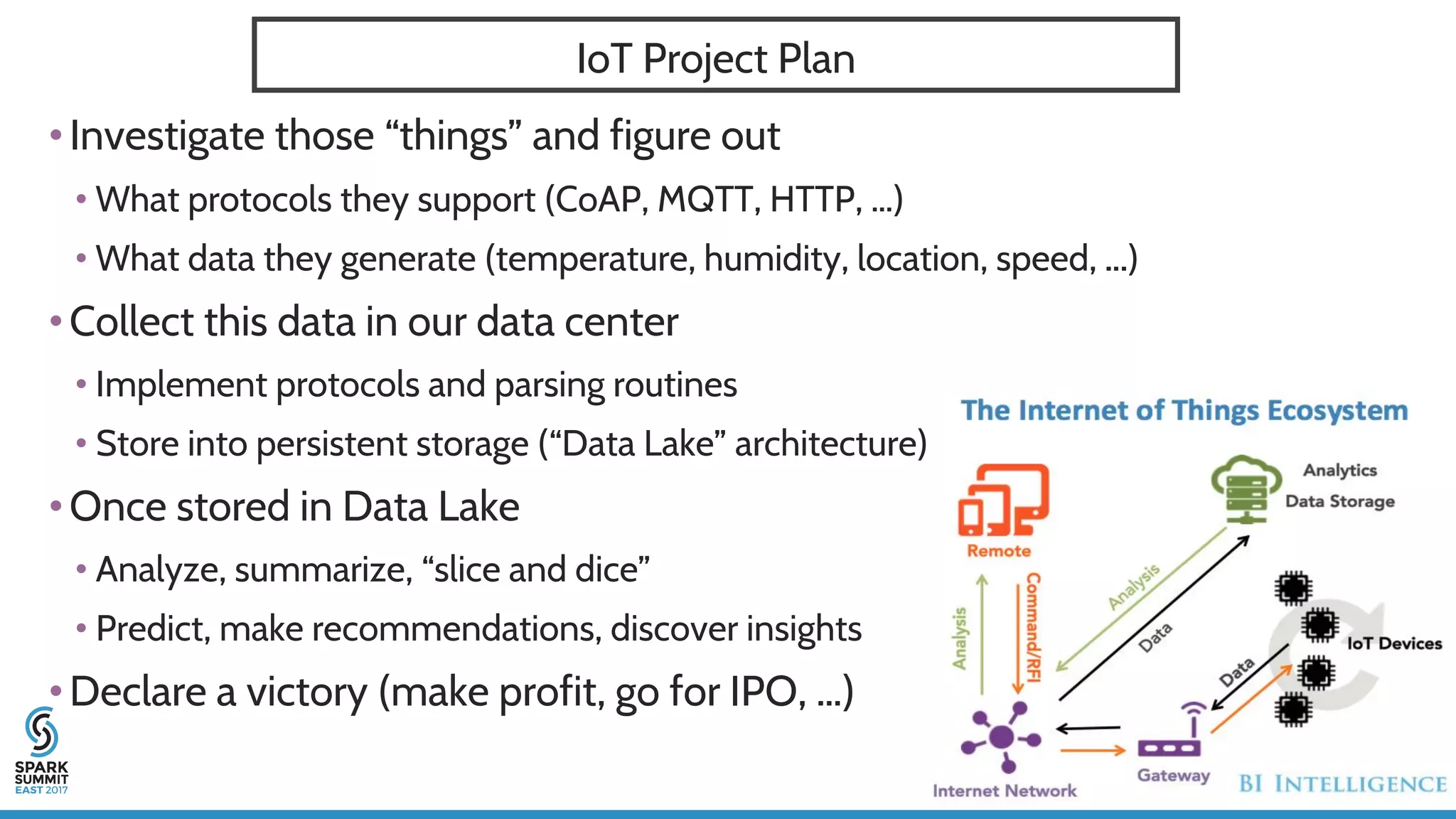
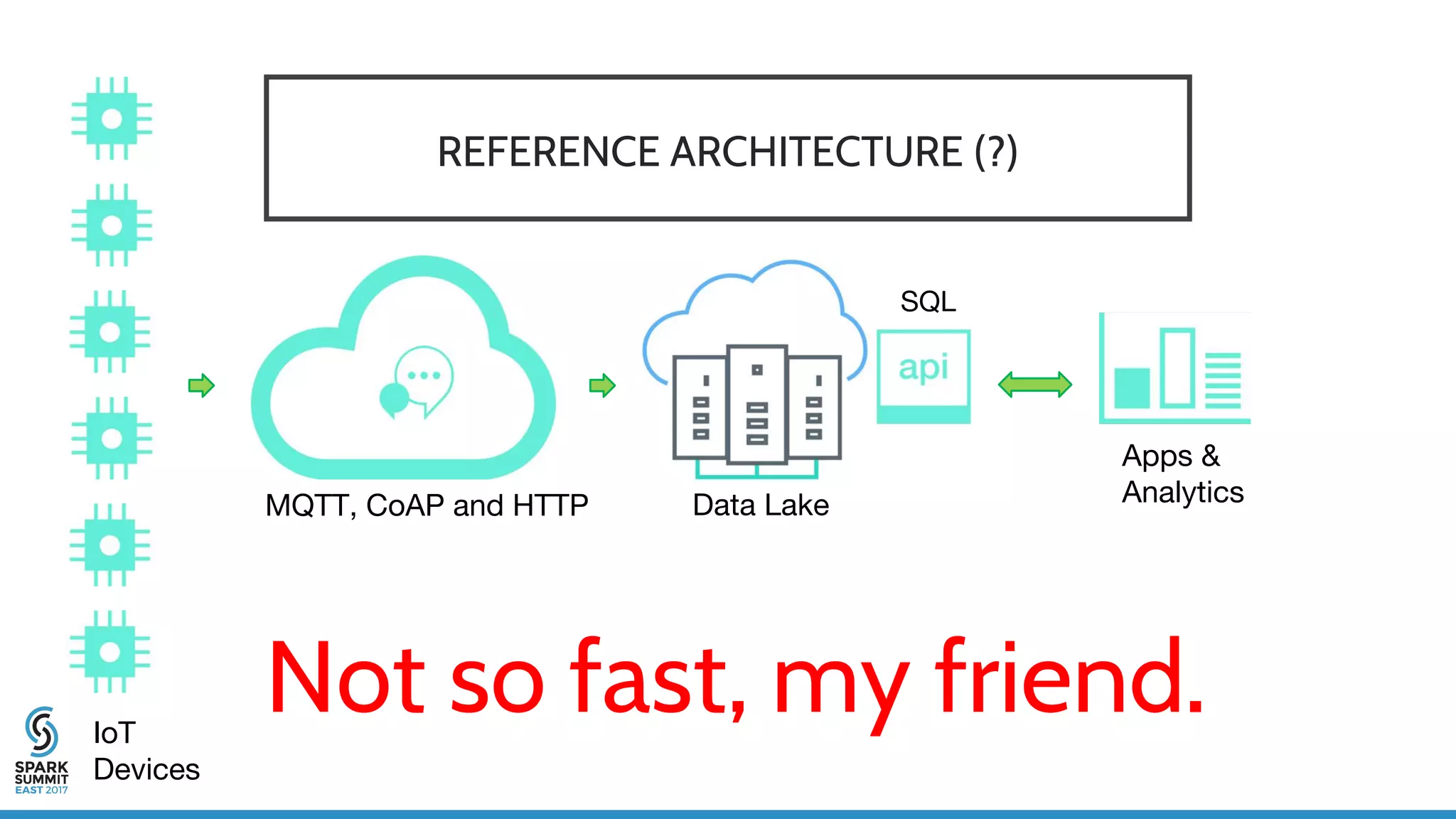
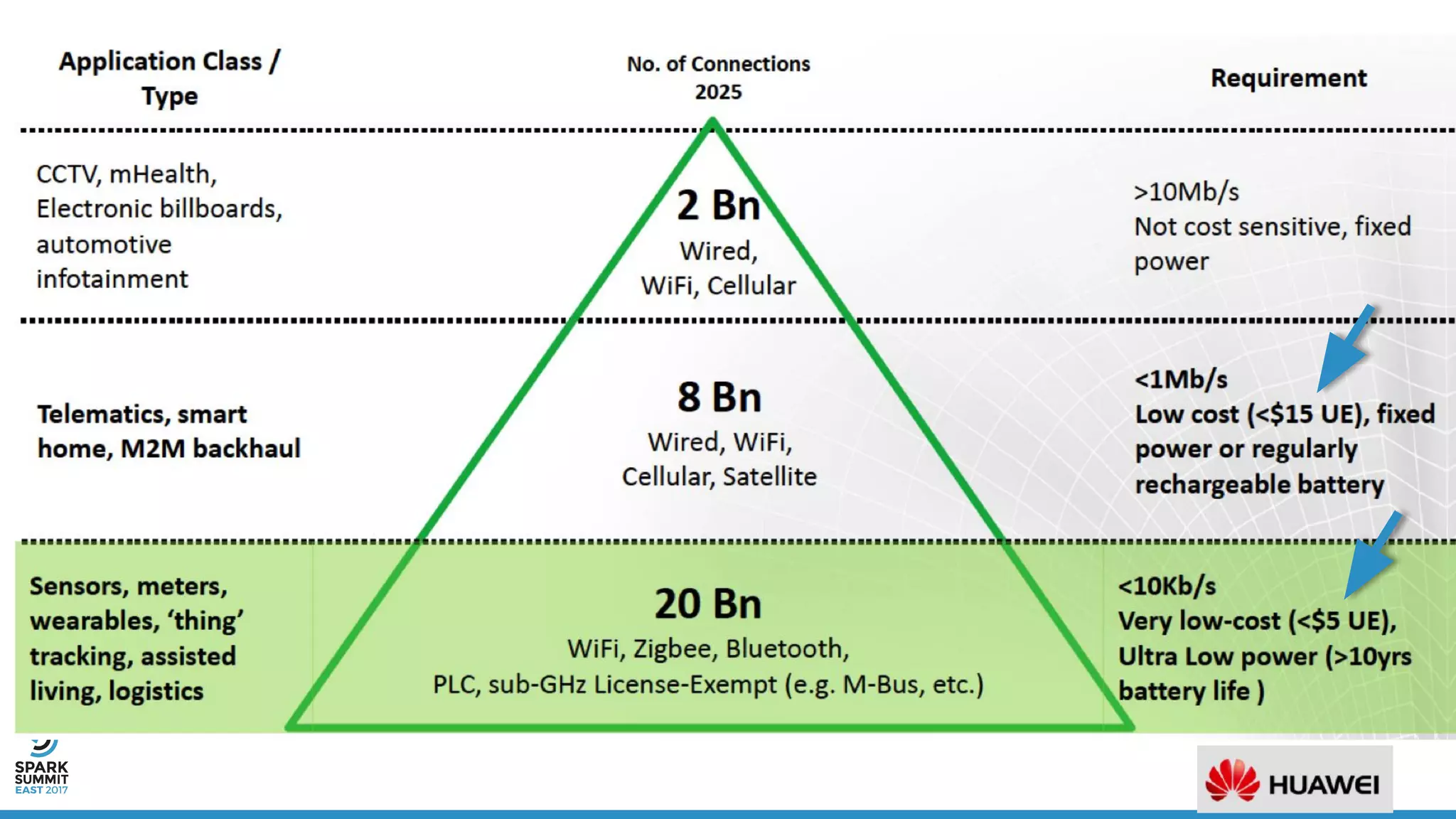
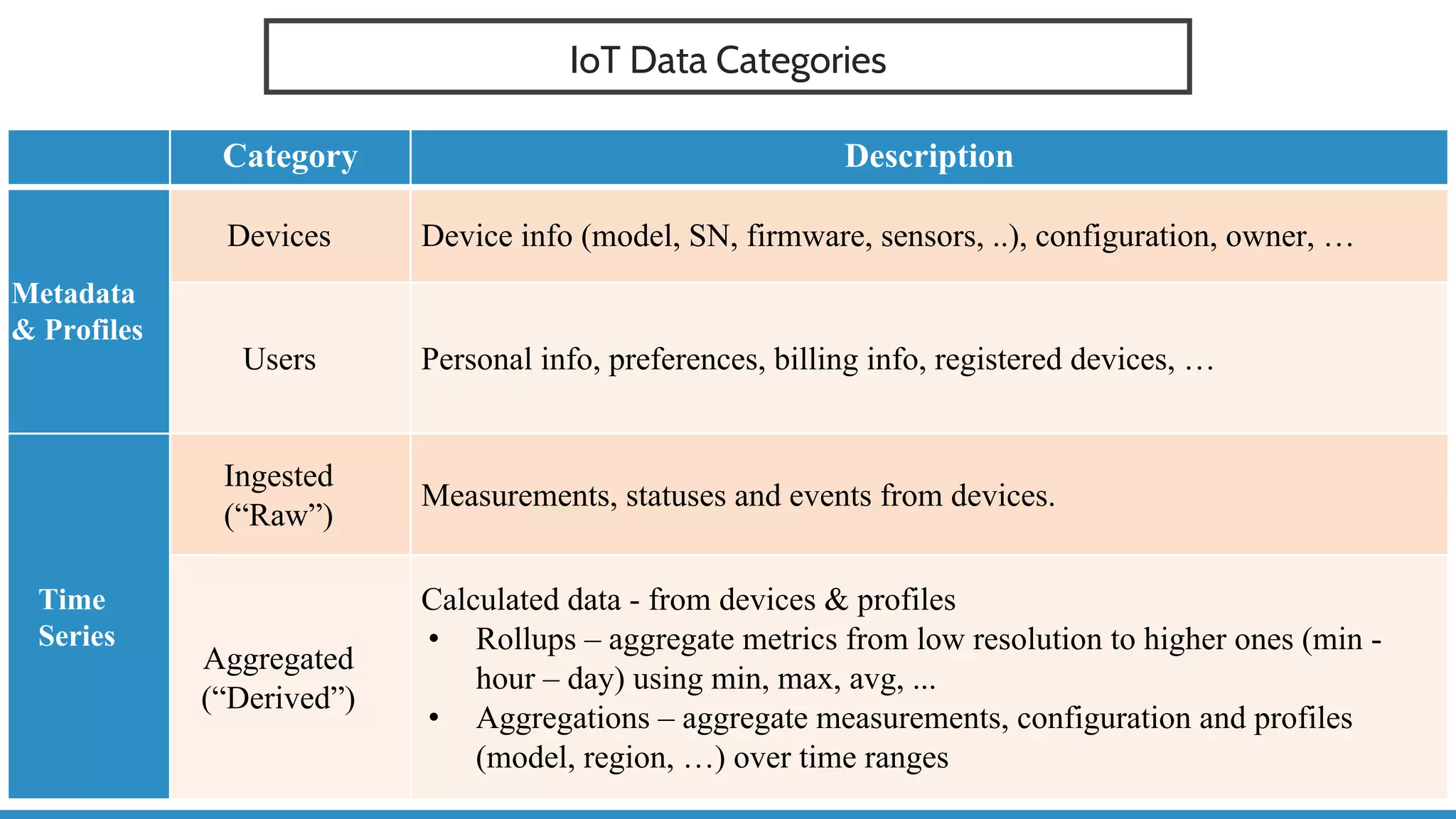
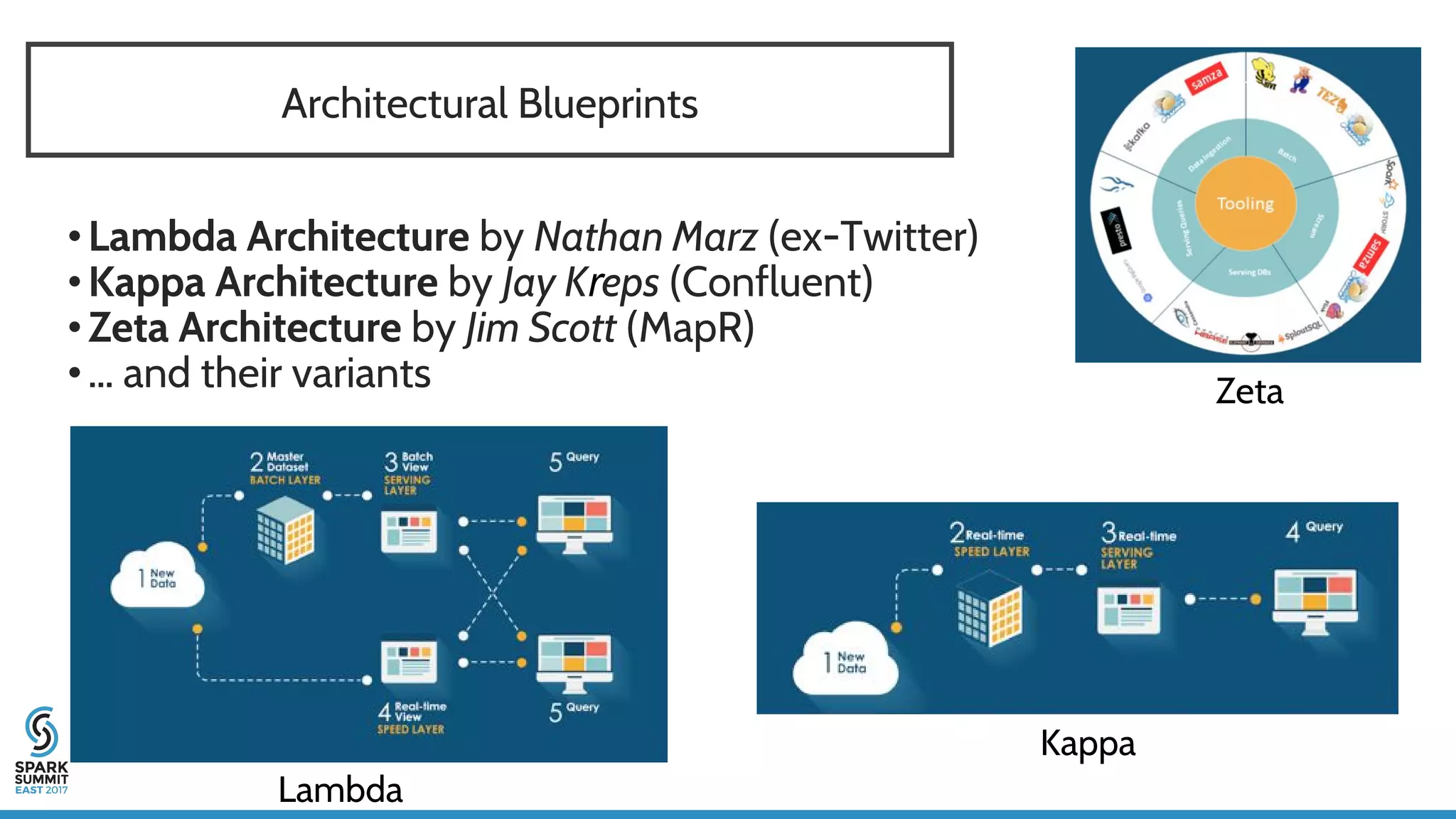
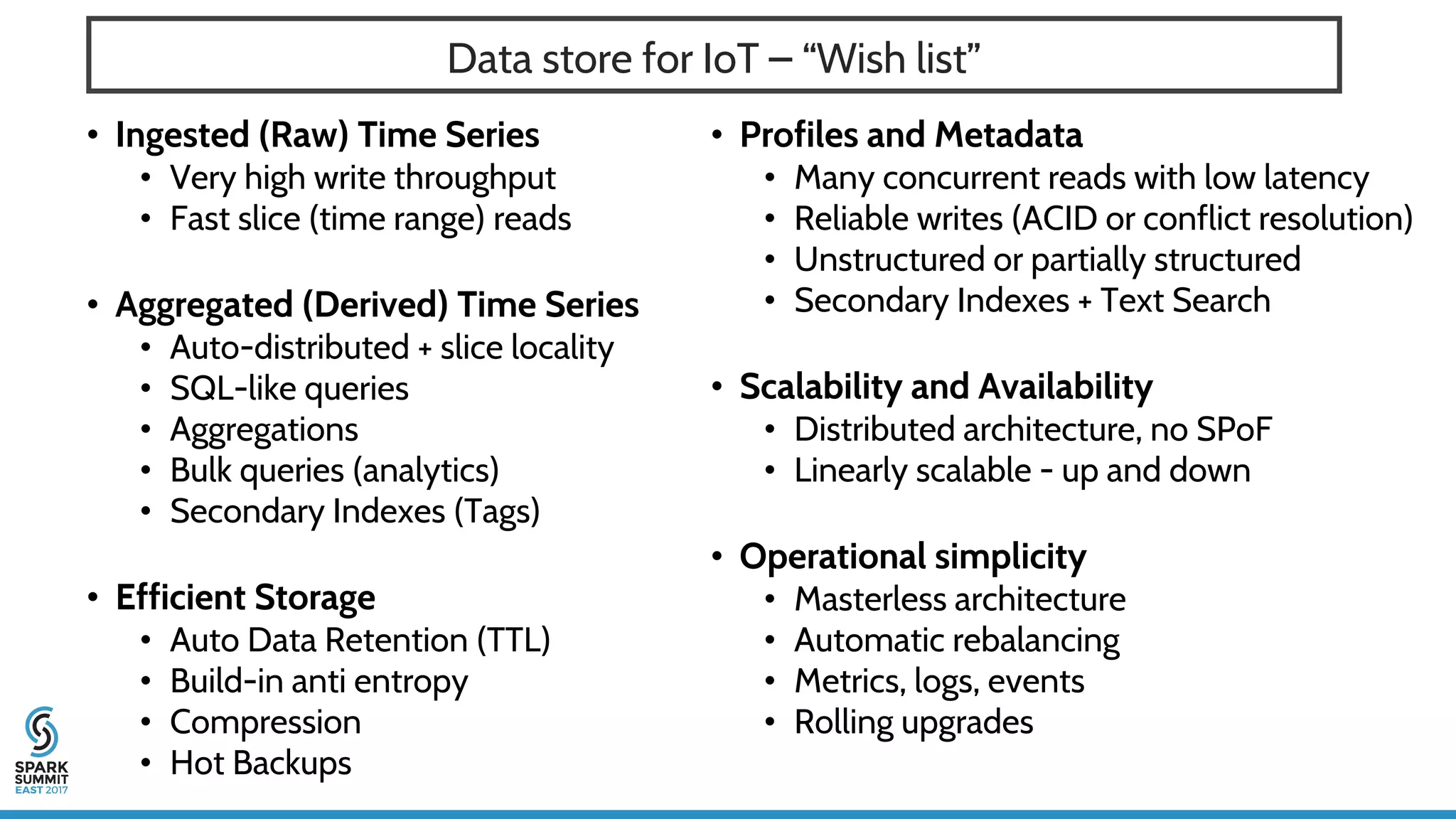
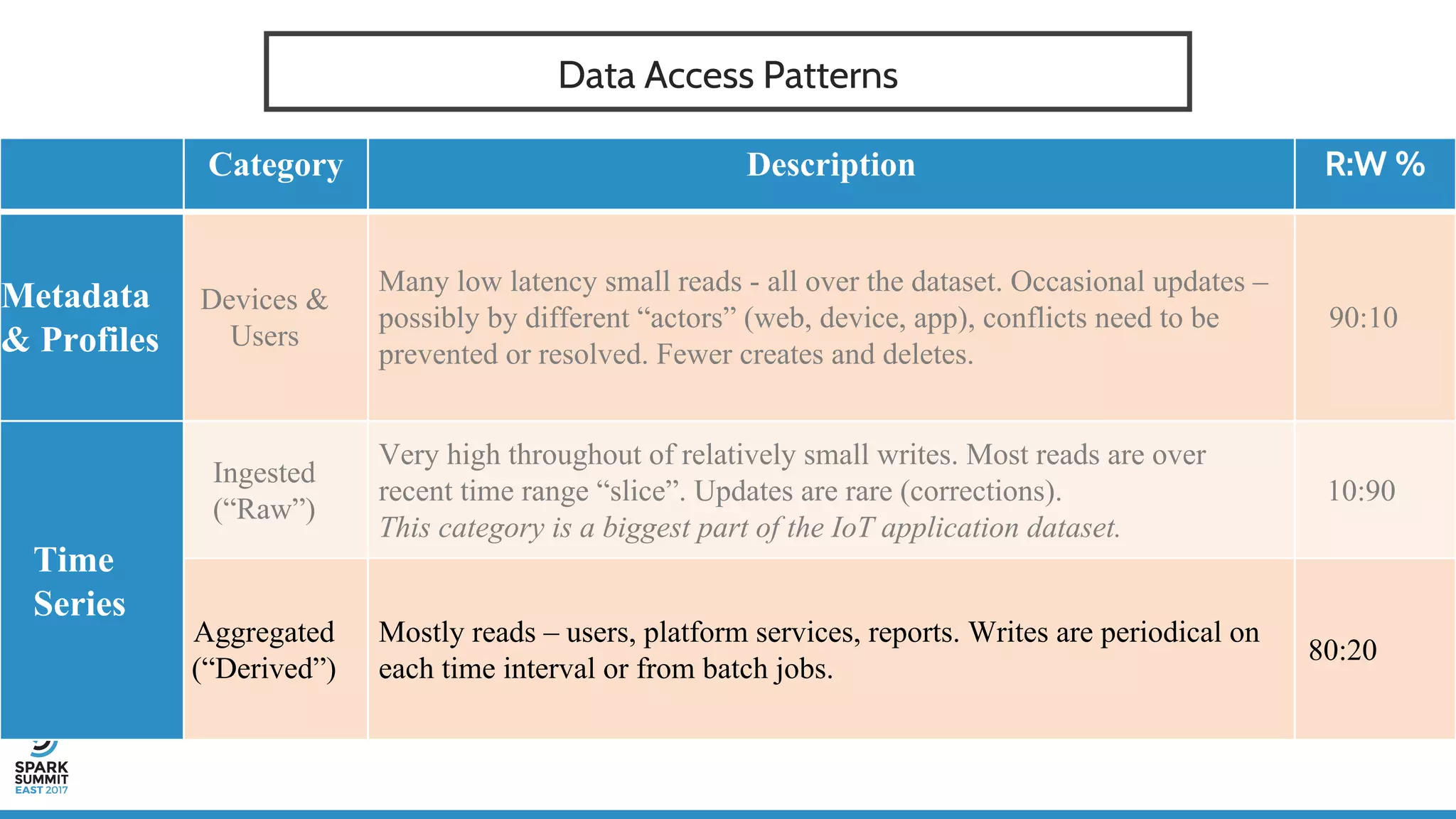
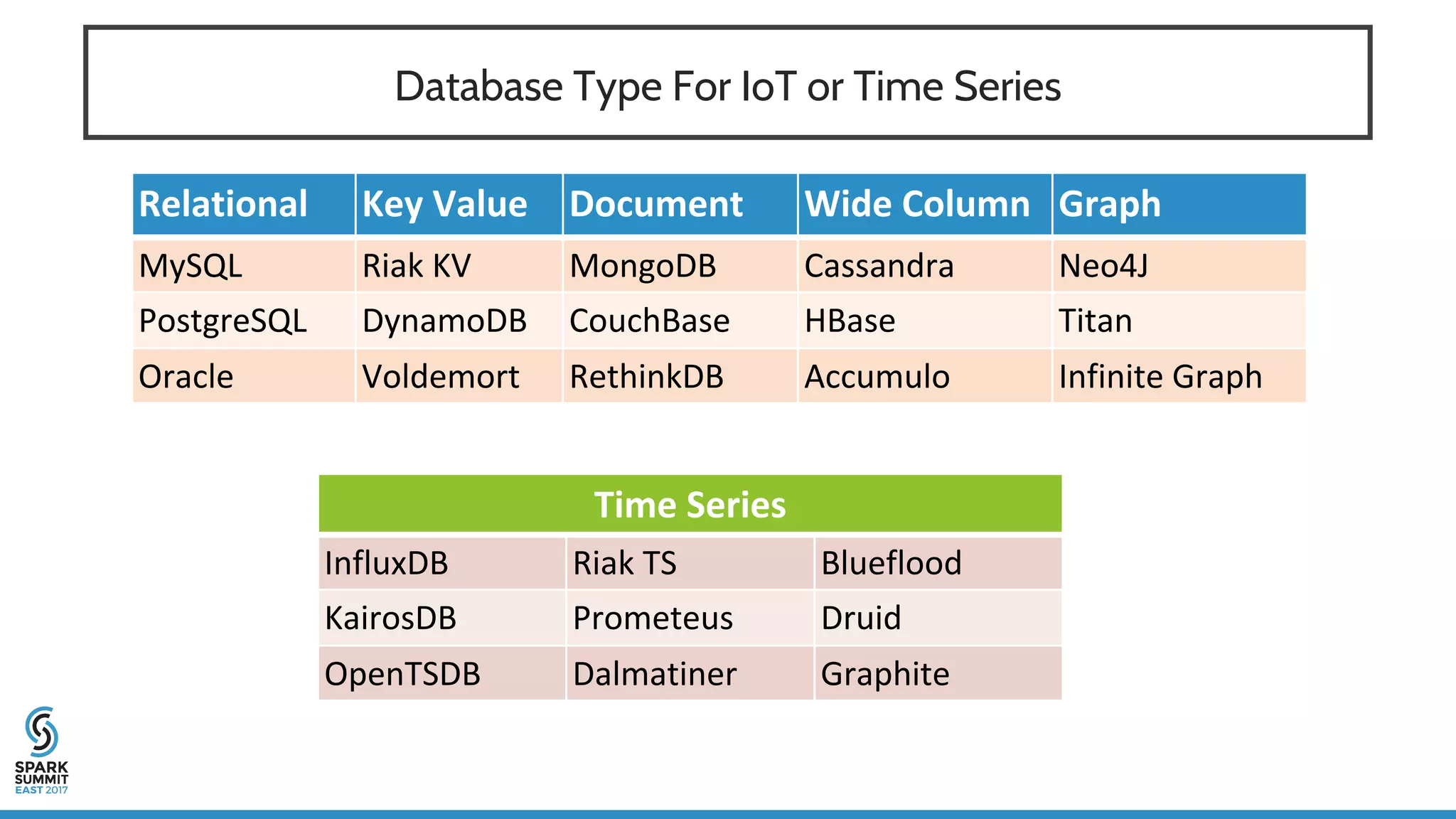
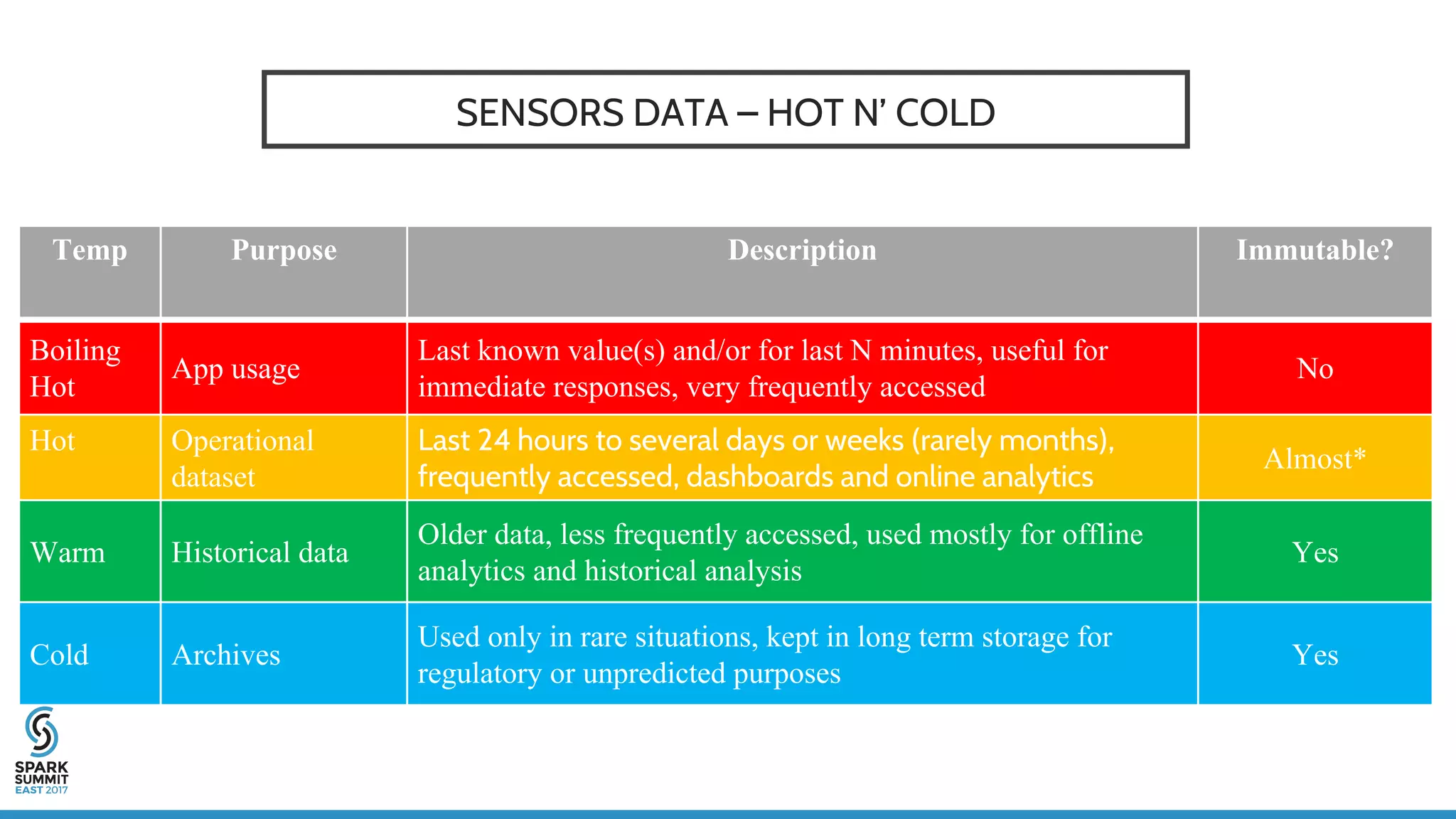
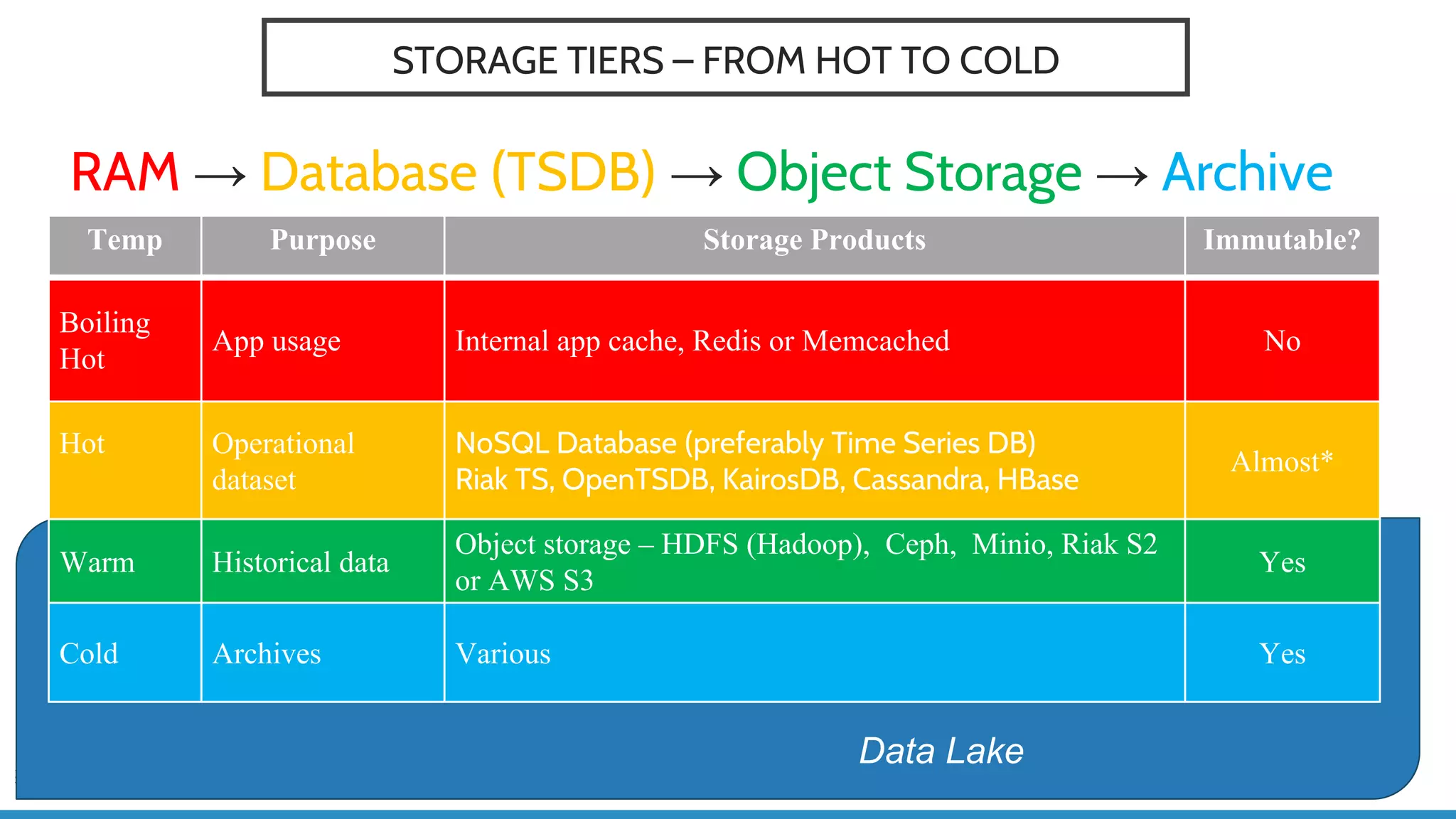
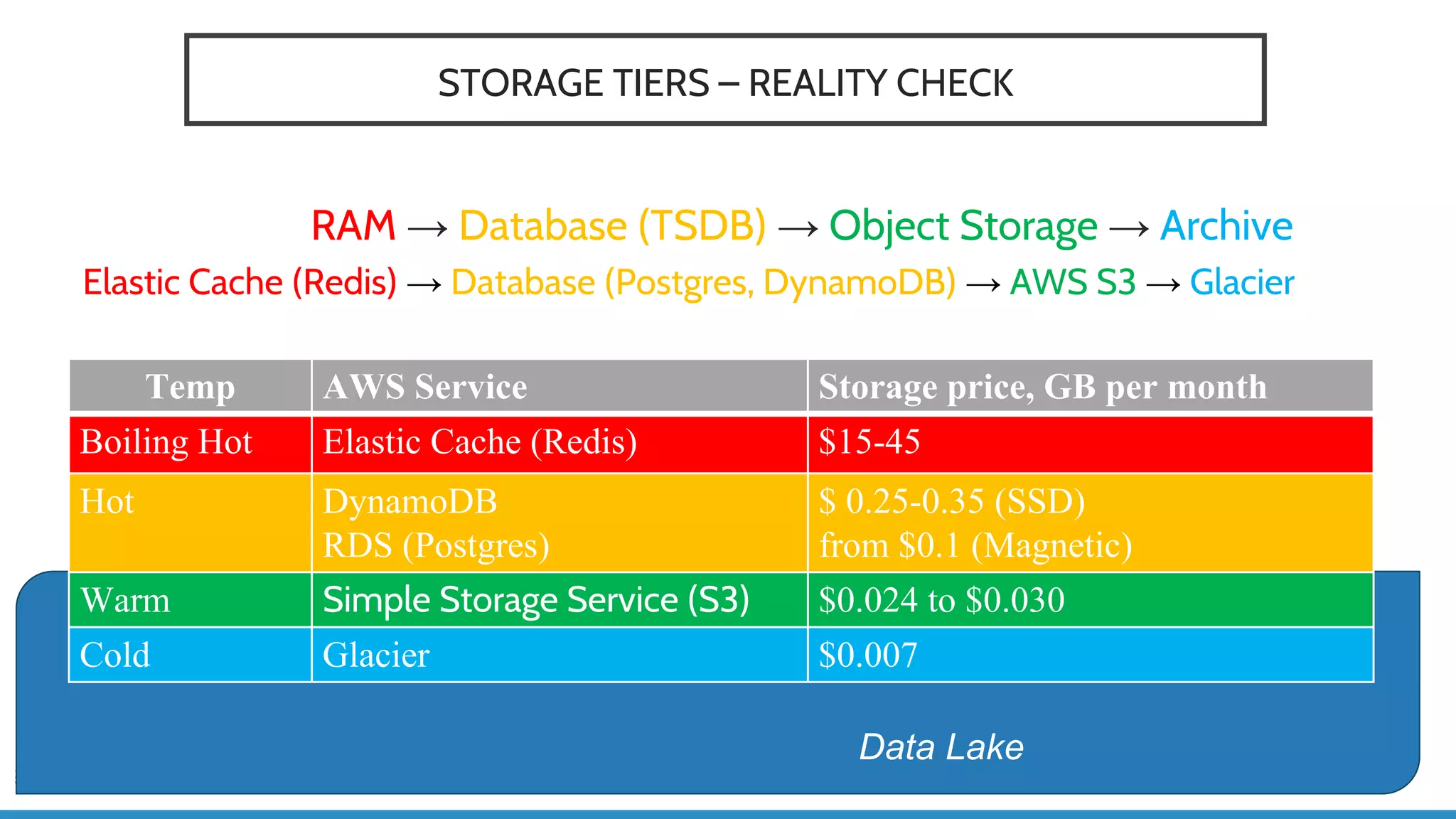
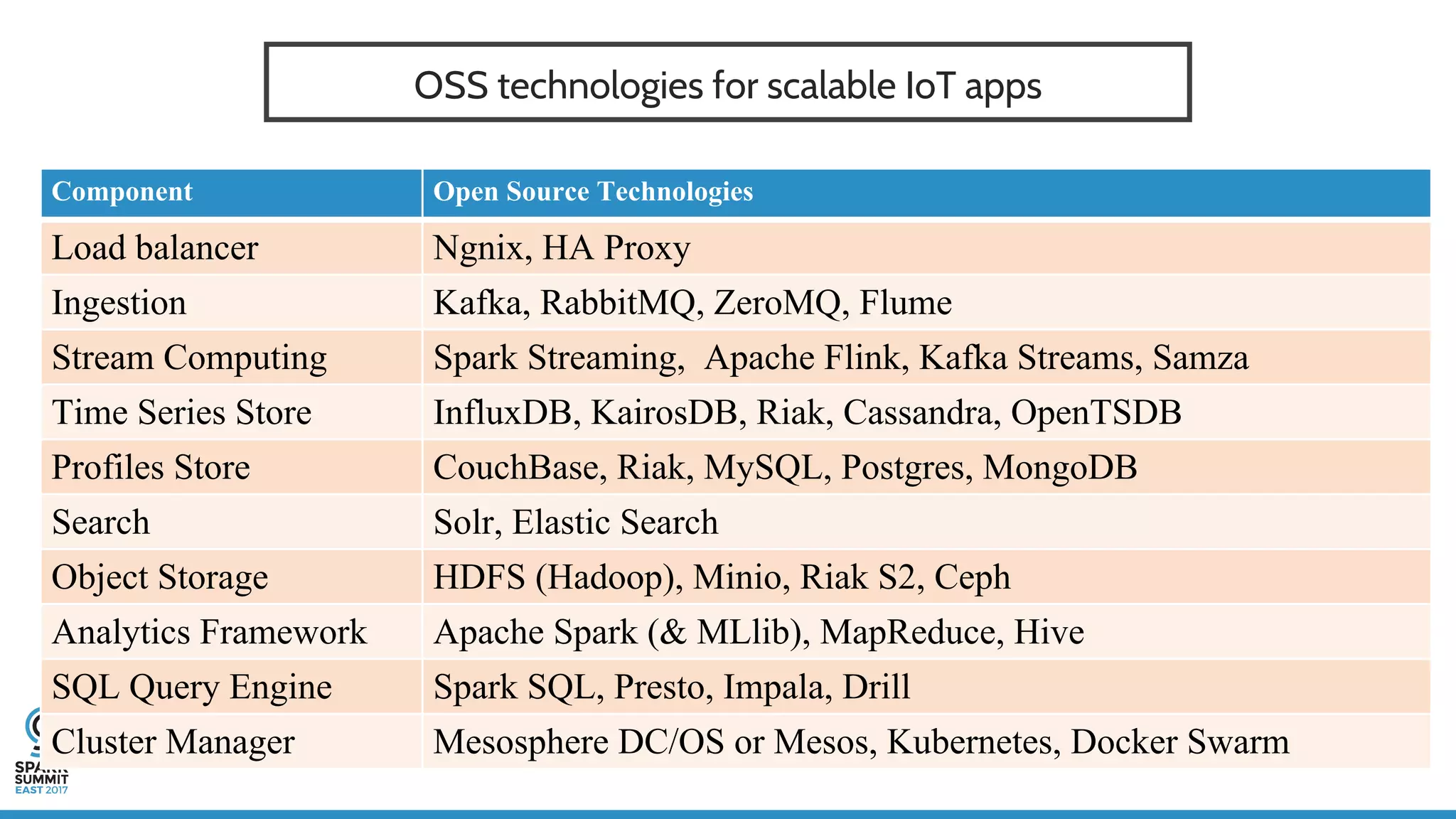
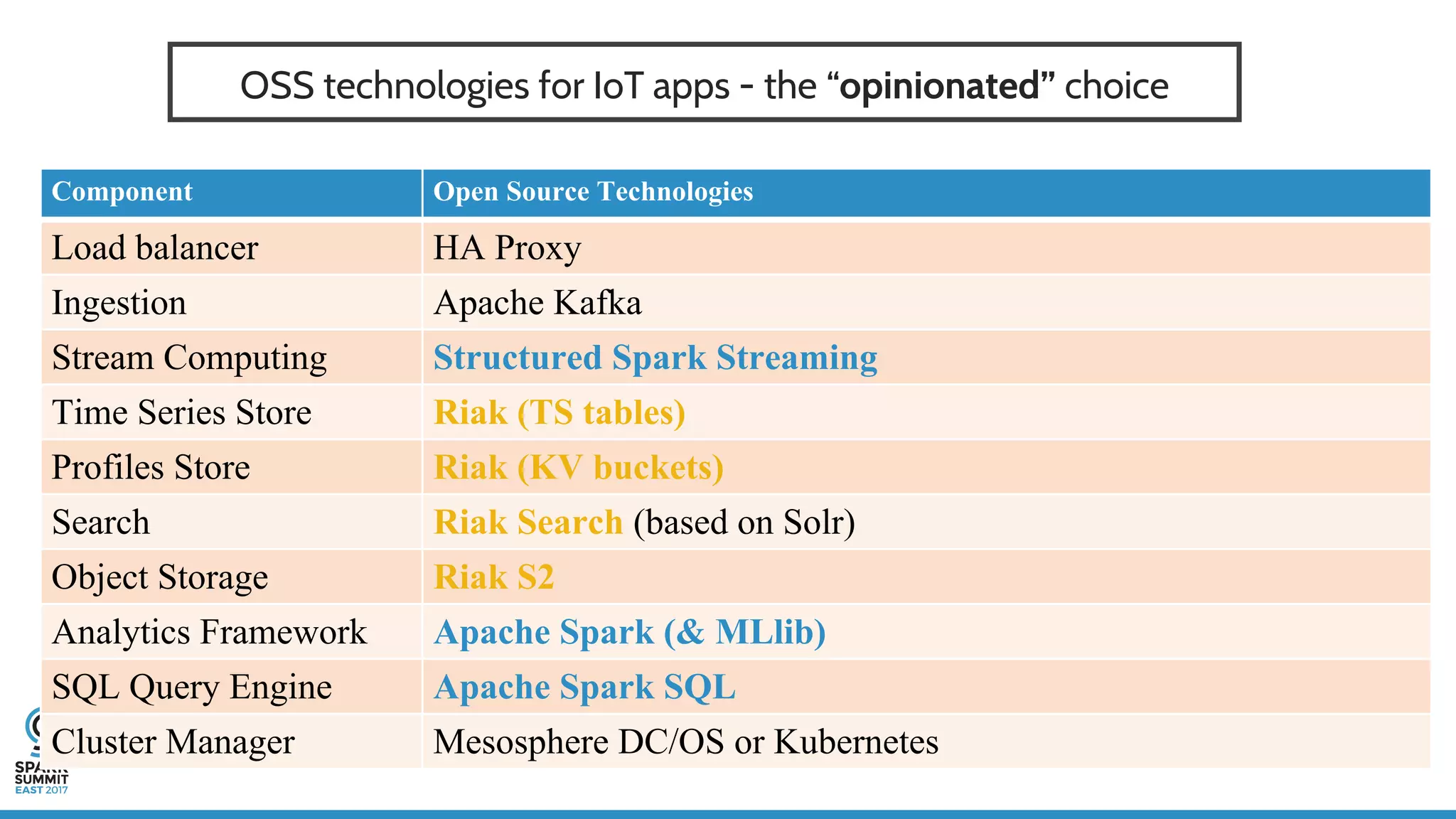
The document discusses IoT application development using Spark and Riak, emphasizing the rapid growth of connected devices and the importance of various IoT protocols and data management strategies. It highlights the challenges of data handling, including velocity, variety, volume, and veracity, while advocating for effective data retention policies and the use of specialized databases for time series data. Additionally, it outlines an architectural framework for IoT data processing and examines the advantages of open-source technologies in creating scalable IoT applications.




























































































![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)