Download as PDF, PPTX
![[course site]
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Unsupervised Learning
#DLUPC](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-320.jpg)
![[course site]
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Unsupervised Learning
#DLUPC](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/75/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-2048.jpg)
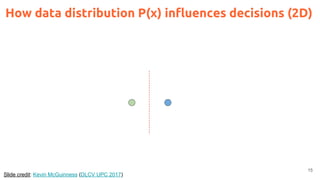
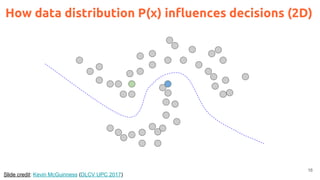
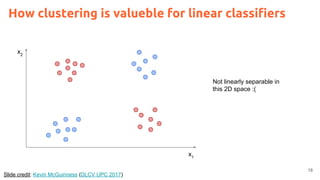
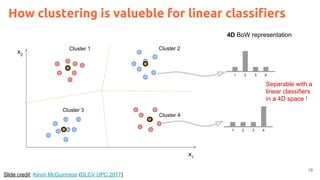
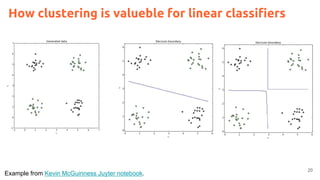
![2
Acknowledegments
Kevin McGuinness, “Unsupervised Learning” Deep Learning for Computer Vision.
[Slides 2016] [Slides 2017]](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-2-320.jpg)



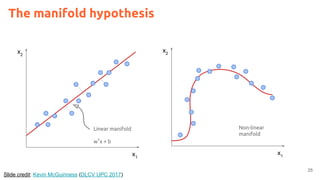
![7
Greff, Klaus, Antti Rasmus, Mathias Berglund, Tele Hao, Harri Valpola, and Juergen Schmidhuber. "Tagger: Deep unsupervised
perceptual grouping." NIPS 2016 [video] [code]](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-7-320.jpg)










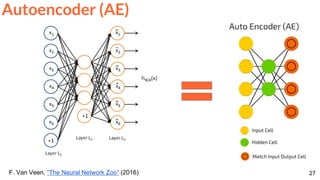
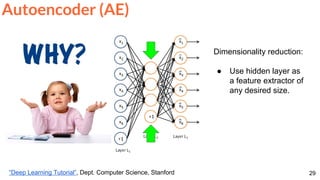










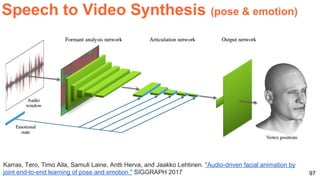
![Frame Reconstruction & Prediction
59
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Unsupervised feature learning (no labels) for...](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-59-320.jpg)
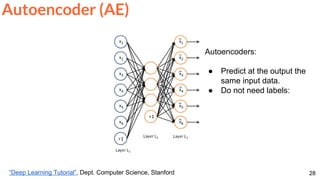
![Frame Reconstruction & Prediction
60
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Unsupervised feature learning (no labels) for...
...frame prediction.](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-60-320.jpg)
![Frame Reconstruction & Prediction
61
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Unsupervised feature learning (no labels) for...
...frame prediction.](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-61-320.jpg)
![62
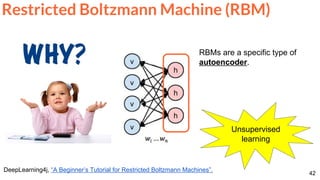
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Unsupervised learned features (lots of data) are
fine-tuned for activity recognition (little data).
Frame Reconstruction & Prediction](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-62-320.jpg)
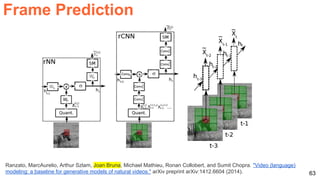
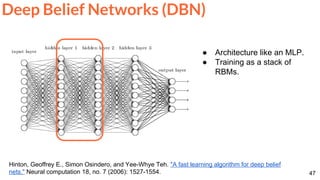
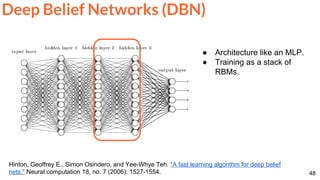
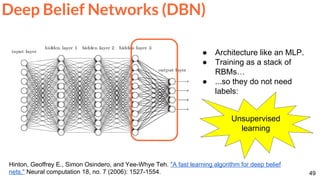
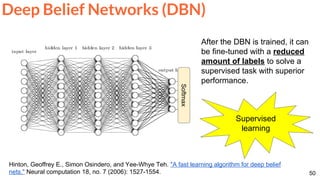
![64
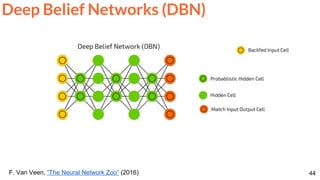
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
Video frame prediction with a ConvNet.
Frame Prediction](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-64-320.jpg)
![65
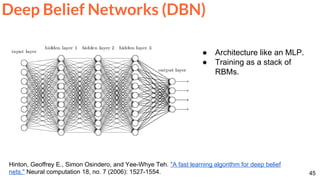
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture,
adversarial learning and an image gradient difference loss function.
Frame Prediction](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-65-320.jpg)
![66
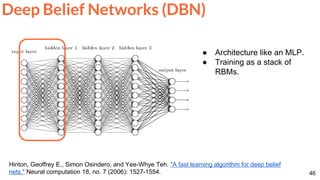
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture,
adversarial training and an image gradient difference loss (GDL) function.
Frame Prediction](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-66-320.jpg)
![67
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
Frame Prediction](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-67-320.jpg)
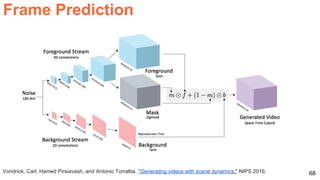

![70
Xue, Tianfan, Jiajun Wu, Katherine Bouman, and Bill Freeman. "Visual dynamics: Probabilistic future frame
synthesis via cross convolutional networks." NIPS 2016 [video]](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-70-320.jpg)
![71
Frame Prediction
Xue, Tianfan, Jiajun Wu, Katherine Bouman, and Bill Freeman. "Visual dynamics: Probabilistic future
frame synthesis via cross convolutional networks." NIPS 2016 [video]
Given an input image, probabilistic generation of future frames with a Variational
AutoEncoder (VAE).](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-71-320.jpg)
![72
Frame Prediction
Xue, Tianfan, Jiajun Wu, Katherine Bouman, and Bill Freeman. "Visual dynamics: Probabilistic future
frame synthesis via cross convolutional networks." NIPS 2016 [video]
Encodes image as feature maps, and motion as and cross-convolutional kernels.](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-72-320.jpg)


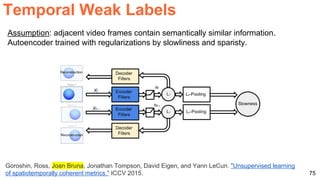
![76
Jayaraman, Dinesh, and Kristen Grauman. "Slow and steady feature analysis: higher order temporal
coherence in video." CVPR 2016. [video]
●
●
Temporal Weak Labels](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-76-320.jpg)
![77
Jayaraman, Dinesh, and Kristen Grauman. "Slow and steady feature analysis: higher order temporal
coherence in video." CVPR 2016. [video]
Temporal Weak Labels](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-77-320.jpg)
![78
(Slides by Xunyu Lin): Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using
temporal order verification." ECCV 2016. [code]
Temporal order of frames is
exploited as the supervisory
signal for learning.
Temporal Weak Labels](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-78-320.jpg)
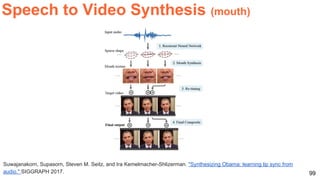
![79
(Slides by Xunyu Lin): Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using
temporal order verification." ECCV 2016. [code]
Take temporal order as the supervisory signals for learning
Shuffled
sequences
Binary classification
In order
Not in order
Temporal Weak Labels](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-79-320.jpg)

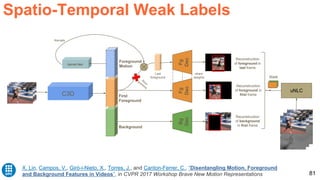

![83
Greff, Klaus, Antti Rasmus, Mathias Berglund, Tele Hao, Harri Valpola, and Juergen Schmidhuber. "Tagger: Deep unsupervised
perceptual grouping." NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels](https://image.slidesharecdn.com/dlai2017dl09l1-171128152236/85/Unsupervised-Learning-DLAI-D9L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-83-320.jpg)
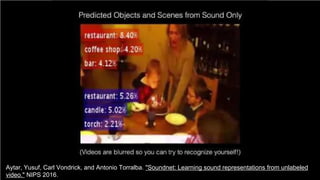
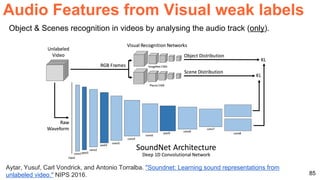
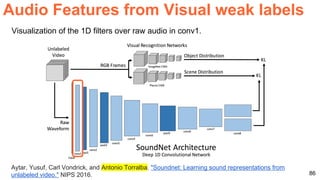
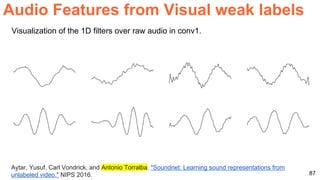
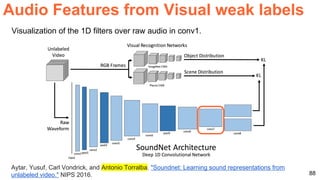

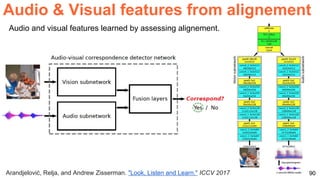
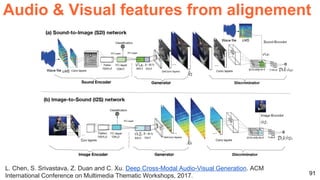



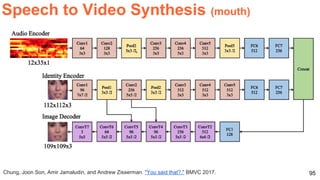




The document discusses unsupervised learning in the context of deep learning, outlining its motivation, methods, and various types such as predictive and self-supervised learning. It highlights the advantages of unsupervised learning, including its ability to utilize vast amounts of unlabelled data and the potential to emulate human-like intelligence in artificial agents. Multiple techniques and models like autoencoders and restricted Boltzmann machines are presented as significant contributions to the field.



































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















