Download as PDF, PPTX














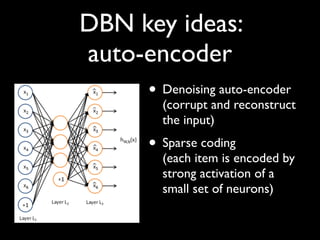





Deep learning involves using deep neural networks with many layers to learn hierarchical representations of data. [1] Deep networks are better able to learn complex patterns than shallow networks. [2] Advances in computing power and algorithms like pre-training and contrastive divergence have enabled training very deep networks. [3] Deep learning is achieving state-of-the-art results in areas like computer vision, speech recognition, and natural language processing.















































