Download as PDF, PPTX






![bit.ly/InsightDL2018
#InsightDL2018
Outline
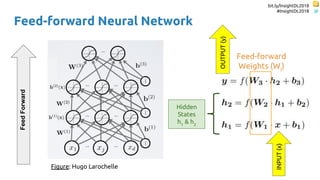
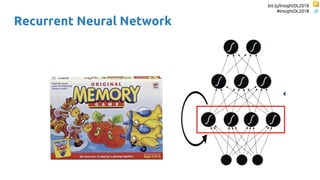
Recurrent Neural
Networks (RNNs)
SkipRNN
[ICLR 2018]
RepeatRNN
[ICLRW 2018]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-8-320.jpg)
![bit.ly/InsightDL2018
#InsightDL2018
Outline
Recurrent Neural
Networks (RNNs)
SkipRNN
[ICLR 2018]
RepeatRNN
[ICLRW 2018]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-9-320.jpg)
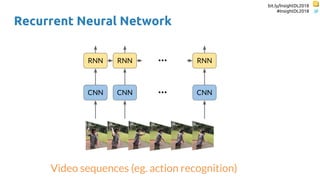
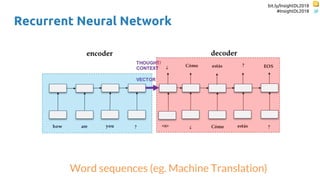
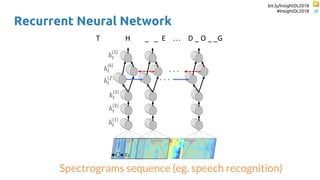
![bit.ly/InsightDL2018
#InsightDL2018
Outline
Recurrent Neural
Networks (RNNs)
SkipRNN
[ICLR 2018]
RepeatRNN
[ICLRW 2018]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-19-320.jpg)

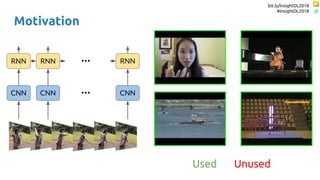



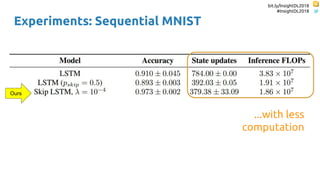

![bit.ly/InsightDL2018
#InsightDL2018
Outline
Recurrent Neural
Networks (RNNs)
SkipRNN
[ICLR 2018]
RepeatRNN
[ICLRW 2018]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-37-320.jpg)

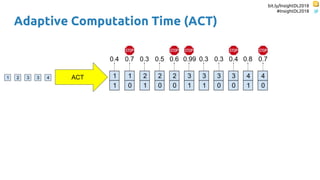
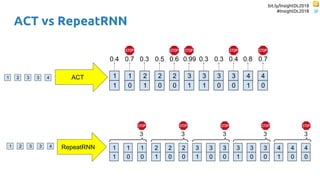

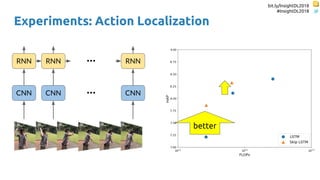
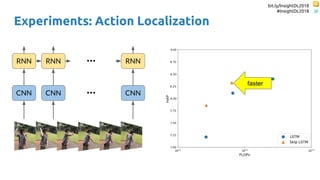
![bit.ly/InsightDL2018
#InsightDL2018
Outline
Recurrent Neural
Networks (RNNs)
SkipRNN
[ICLR 2018]
RepeatRNN
[ICLRW 2018]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-48-320.jpg)





![bit.ly/InsightDL2018
#InsightDL2018
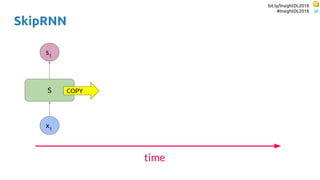
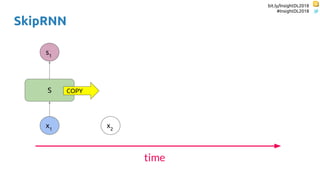
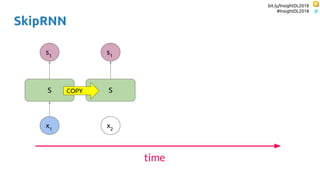
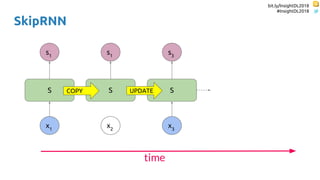
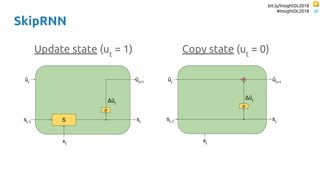
SkipRNN
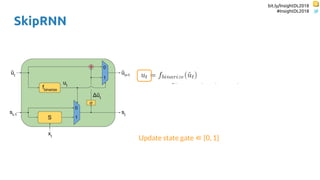
Update state gate ∈ {0, 1}
Update state probability ∈ [0, 1]](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-55-320.jpg)
![bit.ly/InsightDL2018
#InsightDL2018
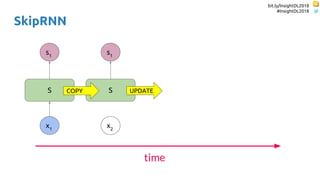
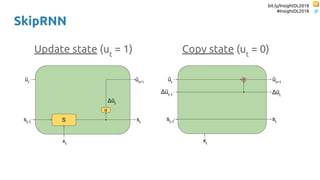
SkipRNN
Update state gate ∈ {0, 1}
Update state probability ∈ [0, 1]
Increment for the update state probability](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-56-320.jpg)
![bit.ly/InsightDL2018
#InsightDL2018
SkipRNN
Update state gate ∈ {0, 1}
Update state probability ∈ [0, 1]
Increment for the update state probability](https://image.slidesharecdn.com/dlmmdcu2018skippingandrepeatingsamplesinrnns-180530113149/85/Skipping-and-Repeating-Samples-in-Recurrent-Neural-Networks-57-320.jpg)
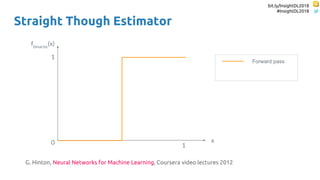
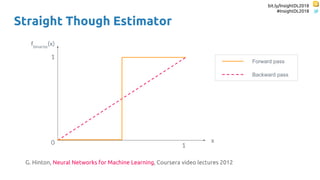

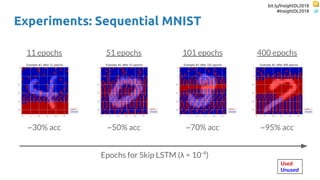
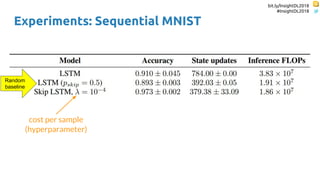
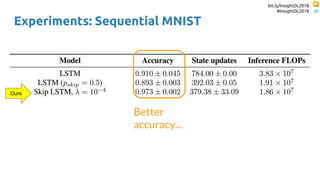
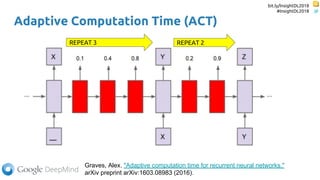
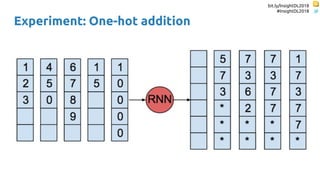
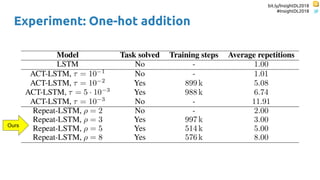
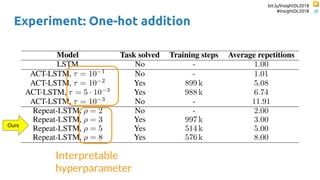
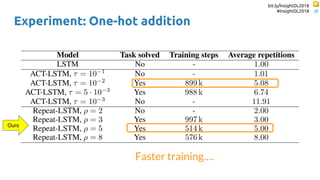
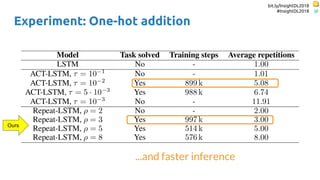
The document discusses SkipRNN and RepeatRNN, which are recurrent neural network models that can dynamically control computation. SkipRNN learns to skip state updates in RNNs by introducing a binary gate that decides whether to update or copy the state. It was shown to achieve better accuracy with less computation on sequential tasks. RepeatRNN reproduces adaptive computation time, allowing the network to repeat computations for difficult examples. It was found to train and infer faster than baselines on an addition task. Code for both models is available online in PyTorch and TensorFlow.



















































































