



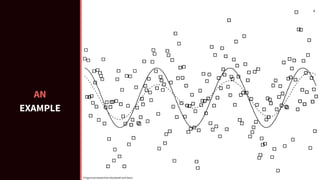
![[Faullkner,
Comstock, Fossum]
[Craw]
[Brockwell, Davis]
[Chatfield]
[Bowerman,
O’Connell, Koehler]
[Granger, Newbold]
Long History
Research
Books](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-7-320.jpg)
![8
[Gilchrist]
[Hyndman, Athanasopoulos ]
[Box et al.]
[Wilson, Keating]
[Makridarkis et al.]
[Mallios]
[Montgomery et al.]
[Pankratz]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-8-320.jpg)




![S2S
13
# http://karpathy.github.io/2015/05/21/rnn-effectiveness/
#
[2014]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-13-320.jpg)

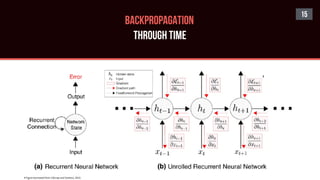
![16
BACKPROPAGATION
THROUGH TIME
[1986]
[1990]
[1986]
[EARLY WORK]
[1990]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-16-320.jpg)
![17
REAL-TIME RECURRENT
LEARNING#*
# A Learning Algorithm for Continually Running Fully Recurrent Neural Networks [Williams and Zipser, 1989]
* A Method for Improving the Real-Time Recurrent Learning Algorithm [Catfolis, 1993]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-17-320.jpg)
![UORO
A
APPROXIMATE
RTRL
UORO
[Unbiased Online Recurrent Optimization]
Works in a streaming fashion
Online, Memoryless
Avoids backtracking through past
activations and inputs
Low-rank approximation to forward-
mode automatic differentiation
Reduced computation and storage
KF-RTRL
[Kronecker Factored RTRL]
Kronecker product decomposition to
approximate the gradients
Reduces noise in the approximation
Asymptotically, smaller by a factor of n
Memory requirement equivalent to UORO
Higher computation than UORO
Not applicable to arbitrary architectures
# Unbiased Online Recurrent Optimization [Tallec and Ollivier, 2017]
#
* Approximating Real-Time Recurrent Learning with Random Kronecker Factors
[Mujika et al. 2018]
*](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-18-320.jpg)
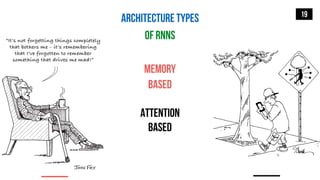
![MEMORY-BASED RNN
ARCHITECTURES
20
BRNN: Bi-directional RNN
[Schuster and Paliwal, 1997]
GLU: Gated Linear Unit
[Dauphin et al. 2016]
Long Short-Term Memory: LSTM
[Hochreiter and Schmidhuber, 1996]
Gated Recurrent Unit: GRU
[Cho et al. 2014]
Gated Highway Network: GHN
[Zilly et al. 2017]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-20-320.jpg)
![Neural Computation, 1997
* Figure borrowed from http://colah.github.io/posts/2015-08-Understanding-LSTMs/
(a) Forget gate (b) Input gate
(c) Output gate
St: hidden state
“The LSTM’s main idea is that, instead of compu7ng St
from St-1 directly with a matrix-vector product followed
by a nonlinearity, the LSTM directly computes St, which
is then added to St-1 to obtain St.” [Jozefowicz et al.
2015]
Resistant to vanishing gradient problem
Achieve better results when dropout is used
Adding bias of 1 to LSTM’s forget gate
*](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-21-320.jpg)




![26
Psychology, Neuroscience, Cognitive Sciences
[1959]
[1974]
[1956]
Span of absolute judgement](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-26-320.jpg)
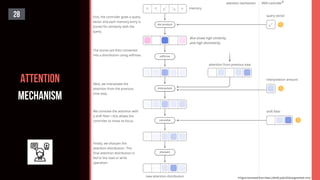
![ATTENTION
27
#
[2014]
[2017]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-27-320.jpg)


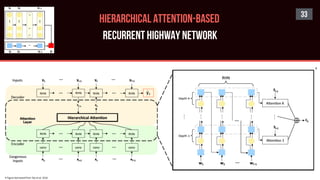
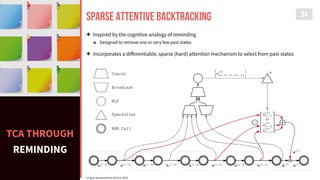
![ATTENTION-BASED
Models
32
Sparse
Attentive Backpropagation
[Ke et al. 2018]
Hierarchical
Attention-Based RHN
[Tao et al. 2018]
Long Short-Term
Memory-Networks
[Cheng et al. 2016]
Self-Attention GAN
[Zhang et al. 2018]
[A SNAPSHOT]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-32-320.jpg)

![READINGS
37
[Rosenblatt]
Principles of Neurodynamics: Perceptrons
and the theory of brain mechanisms
[Eds. Anderson and Rosenfeld]
Neurocomputing: Foundations of
Research
[Eds. Rumelhart and McClelland]
Parallel and Distributed Processing
[Werbos]
The Roots of Backpropagation: From Ordered
Derivatives to Neural Networks and Political
Forecasting
[Eds. Chauvin and Rumelhart]
Backpropagation: Theory, Architectures
and Applications
[Rojas]
Neural Networks: A Systematic
Introduction
[BOOKS]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-37-320.jpg)
![READINGS
38
Perceptrons [Minsky and Papert, 1969]
Une procedure d'apprentissage pour reseau a seuil assymetrique [Le Cun, 1985]
The problem of serial order in behavior [Lashley, 1951]
Beyond regression: New tools for prediction and analysis in the behavioral sciences [Werbos, 1974]
Connectionist models and their properties [Feldman and Ballard, 1982]
Learning-logic [Parker, 1985]
[EARLY WORKS]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-38-320.jpg)
![READINGS
39
Learning internal representations by error propagation [Rumelhart, Hinton, and Williams, Chapter 8 in D. Rumelhart and F. McClelland, Eds.,
Parallel Distributed Processing, Vol. 1, 1986] (Generalized Delta Rule)
Generalization of backpropagation with application to a recurrent gas market model [Werbos, 1988]
Generalization of backpropagation to recurrent and higher order networks [Pineda, 1987]
Backpropagation in perceptrons with feedback [Almeida, 1987]
Second-order backpropagation: Implementing an optimal O(n) approximation to Newton's method in an artificial neural network [Parker,
1987]
Learning phonetic features using connectionist networks: an experiment in speech recognition [Watrous and Shastri, 1987] (Time-delay NN)
[BACKPROPAGATION]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-39-320.jpg)
![READINGS
40
Backpropagation: Past and future [Werbos, 1988]
Adaptive state representation and estimation using recurrent connectionist networks [Williams, 1990]
Generalization of back propagation to recurrent and higher order neural networks [Pineda, 1988]
Learning state space trajectories in recurrent neural networks [Pearlmutter 1989]
Parallelism, hierarchy, scaling in time-delay neural networks for spotting Japanese phonemes/CV-syllables [Sawai et al. 1989]
The role of time in natural intelligence: implications for neural network and artificial intelligence research [Klopf and Morgan, 1990]
[BACKPROPAGATION]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-40-320.jpg)
![READINGS
41
Recurrent Neural Network Regularization [Zaremba et al. 2014]
Regularizing RNNs by Stabilizing Activations [Krueger and Memisevic, 2016]
Sampling-based Gradient Regularization for Capturing Long-Term Dependencies in Recurrent Neural Networks [Chernodub and Nowicki 2016]
A Theoretically Grounded Application of Dropout in Recurrent Neural Networks [Gal and Ghahramani, 2016]
Noisin: Unbiased Regularization for Recurrent Neural Networks [Dieng et al. 2018]
State-Regularized Recurrent Neural Networks [Wang and Niepert, 2019]
[REGULARIZATION of RNNs]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-41-320.jpg)
![READINGS
42
A Decomposable Attention Model for Natural Language Inference [Parikh et al. 2016]
Hybrid Computing Using A Neural Network With Dynamic External Memory [Graves et al. 2017]
Image Transformer [Parmar et al. 2018]
Universal Transformers [Dehghani et al. 2019]
The Evolved Transformer [So et al. 2019]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context [Dai et al. 2019]
[ATTENTION & TRANSFORMERS]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-42-320.jpg)
![READINGS
43
Financial Time Series Prediction using hybrids of Chaos Theory, Multi-layer Perceptron and Multi-objective Evolutionary Algorithms [Ravi et
al. 2017]
Model-free Prediction of Noisy Chaotic Time Series by Deep Learning [Yeo, 2017]
DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks [Salinas et al. 2017]
Real-Valued (Medical) Time Series Generation With Recurrent Conditional GANs [Hyland et al. 2017]
R2N2: Residual Recurrent Neural Networks for Multivariate Time Series Forecasting [Goel et al. 2017]
Temporal Pattern Attention for Multivariate Time Series Forecasting [Shih et al. 2018]
[TIME SERIES PREDICTION]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-43-320.jpg)
![READINGS
44
Unbiased Online Recurrent Optimization [Tallec and Ollivier, 2017]
Approximating real-time recurrent learning with random Kronecker factors [Mujika et al. 2018]
Theory and Algorithms for Forecasting Time Series [Kuznetsov and Mohri, 2018]
Foundations of Sequence-to-Sequence Modeling for Time Series [Kuznetsov and Meriet, 2018]
On the Variance Unbiased Recurrent Optimization [Cooijmans and Martens, 2019]
Backpropagation through time and the brain [Lillicrap and Santoro, 2019]
[POTPOURRI]](https://image.slidesharecdn.com/s2sonlyme-190501162431/85/Sequence-to-Sequence-Modeling-for-Time-Series-44-320.jpg)


This document provides an overview of time series forecasting using deep learning techniques. It discusses recurrent neural networks (RNNs) and their application to time series forecasting, including different RNN architectures like LSTMs and attention mechanisms. It also summarizes various approaches to training RNNs, such as backpropagation through time, and regularization techniques. Finally, it lists several examples of time series forecasting applications and provides references for further reading on the topic.
























![[20240422_LabSeminar_Huy]Taming_Effect.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240422labseminarhuytamingeffect-240423153149-d879b2ce-thumbnail.jpg?width=640&height=640&fit=bounds)


















































