Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yifeng Jiang
PDF, PPTX
2,351 views
HDFS Deep Dive
HDFS deep dive. Erasure code in HDFS. How to choose storage for Hadoop on EC2.
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
PPTX
Coherenceを利用するときに気をつけること #OracleCoherence
by
Toshiaki Maki
PDF
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
PDF
[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...
by
Insight Technology, Inc.
PDF
HBase at LINE
by
Shun Nakamura
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Yahoo! JAPANのOracle構成-2017年版
by
Makoto Sato
HDFS Supportaiblity Improvements
by
Cloudera Japan
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
Coherenceを利用するときに気をつけること #OracleCoherence
by
Toshiaki Maki
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...
by
Insight Technology, Inc.
HBase at LINE
by
Shun Nakamura
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Yahoo! JAPANのOracle構成-2017年版
by
Makoto Sato
What's hot
PPTX
[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...
by
Insight Technology, Inc.
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PDF
[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...
by
Insight Technology, Inc.
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
HDFS HA セミナー #hadoop
by
Cloudera Japan
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
Yifeng hadoop-present-public
by
Yifeng Jiang
PDF
Log analysis with Hadoop in livedoor 2013
by
SATOSHI TAGOMORI
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PDF
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
PPTX
A Benchmark Test on Presto, Spark Sql and Hive on Tez
by
Gw Liu
PDF
HDP Security Overview
by
Yifeng Jiang
PDF
Evolution of Impala #hcj2014
by
Cloudera Japan
PPTX
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
PPTX
絵で見てわかる 某分散データストア
by
Takahiko Sato
PDF
Apache Hiveの今とこれから
by
Yifeng Jiang
PDF
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
PDF
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...
by
Insight Technology, Inc.
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...
by
Insight Technology, Inc.
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
HDFS HA セミナー #hadoop
by
Cloudera Japan
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
Yifeng hadoop-present-public
by
Yifeng Jiang
Log analysis with Hadoop in livedoor 2013
by
SATOSHI TAGOMORI
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
A Benchmark Test on Presto, Spark Sql and Hive on Tez
by
Gw Liu
HDP Security Overview
by
Yifeng Jiang
Evolution of Impala #hcj2014
by
Cloudera Japan
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
絵で見てわかる 某分散データストア
by
Takahiko Sato
Apache Hiveの今とこれから
by
Yifeng Jiang
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
Viewers also liked
PPTX
HDFS Erasure Code Storage - Same Reliability at Better Storage Efficiency
by
DataWorks Summit
PPTX
Less is More: 2X Storage Efficiency with HDFS Erasure Coding
by
Zhe Zhang
PDF
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
PPTX
HDFS Erasure Coding in Action
by
DataWorks Summit/Hadoop Summit
PDF
Native erasure coding support inside hdfs presentation
by
lin bao
PPTX
HDFS: Optimization, Stabilization and Supportability
by
DataWorks Summit/Hadoop Summit
PPTX
Hadoop fault tolerance
by
Pallav Jha
PDF
図でわかるHDFS Erasure Coding
by
Kai Sasaki
PDF
Data Science Crash Course Hadoop Summit SJ
by
Daniel Madrigal
PPTX
Samsung’s First 90-Days Building a Next-Generation Analytics Platform
by
Cloudera, Inc.
PPTX
Five Tips for Running Cloudera on AWS
by
Cloudera, Inc.
PPTX
Evolving HDFS to a Generalized Distributed Storage Subsystem
by
DataWorks Summit/Hadoop Summit
PDF
Timeline Service v.2 (Hadoop Summit 2016)
by
Sangjin Lee
PDF
Apache Hadoop Crash Course - HS16SJ
by
DataWorks Summit/Hadoop Summit
PDF
Apache Hadoop Crash Course
by
DataWorks Summit/Hadoop Summit
PPTX
Hadoop crashcourse v3
by
Hortonworks
PDF
Performance comparison of Distributed File Systems on 1Gbit networks
by
Marian Marinov
PPTX
What's new in hadoop 3.0
by
Heiko Loewe
PDF
Intro to Spark with Zeppelin Crash Course Hadoop Summit SJ
by
Daniel Madrigal
PPTX
Apache Hadoop 3.0 What's new in YARN and MapReduce
by
DataWorks Summit/Hadoop Summit
HDFS Erasure Code Storage - Same Reliability at Better Storage Efficiency
by
DataWorks Summit
Less is More: 2X Storage Efficiency with HDFS Erasure Coding
by
Zhe Zhang
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
HDFS Erasure Coding in Action
by
DataWorks Summit/Hadoop Summit
Native erasure coding support inside hdfs presentation
by
lin bao
HDFS: Optimization, Stabilization and Supportability
by
DataWorks Summit/Hadoop Summit
Hadoop fault tolerance
by
Pallav Jha
図でわかるHDFS Erasure Coding
by
Kai Sasaki
Data Science Crash Course Hadoop Summit SJ
by
Daniel Madrigal
Samsung’s First 90-Days Building a Next-Generation Analytics Platform
by
Cloudera, Inc.
Five Tips for Running Cloudera on AWS
by
Cloudera, Inc.
Evolving HDFS to a Generalized Distributed Storage Subsystem
by
DataWorks Summit/Hadoop Summit
Timeline Service v.2 (Hadoop Summit 2016)
by
Sangjin Lee
Apache Hadoop Crash Course - HS16SJ
by
DataWorks Summit/Hadoop Summit
Apache Hadoop Crash Course
by
DataWorks Summit/Hadoop Summit
Hadoop crashcourse v3
by
Hortonworks
Performance comparison of Distributed File Systems on 1Gbit networks
by
Marian Marinov
What's new in hadoop 3.0
by
Heiko Loewe
Intro to Spark with Zeppelin Crash Course Hadoop Summit SJ
by
Daniel Madrigal
Apache Hadoop 3.0 What's new in YARN and MapReduce
by
DataWorks Summit/Hadoop Summit
Similar to HDFS Deep Dive
PDF
Hadoop book-2nd-ch3-update
by
Taisuke Yamada
PDF
141030ceph
by
OSSラボ株式会社
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PDF
Yahoo! JAPAN MeetUp #8 (インフラ技術カンファレンス)セッション②
by
Yahoo!デベロッパーネットワーク
PDF
大規模HDFS & ErasureCoding#yjdsw3
by
Yahoo!デベロッパーネットワーク
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PDF
OSSラボ様講演 OpenStack最新情報セミナー 2014年6月
by
VirtualTech Japan Inc.
PDF
[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料
by
OSSラボ株式会社
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
CDH4.0.0のNameNode HAを触ってみて
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
PPTX
HDFS (fsimage and edits) in CDH3,CDH4
by
Tatsuo Kawasaki
PDF
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
by
Amazon Web Services Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
PPTX
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
Hadoop book-2nd-ch3-update
by
Taisuke Yamada
141030ceph
by
OSSラボ株式会社
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
Yahoo! JAPAN MeetUp #8 (インフラ技術カンファレンス)セッション②
by
Yahoo!デベロッパーネットワーク
大規模HDFS & ErasureCoding#yjdsw3
by
Yahoo!デベロッパーネットワーク
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
OSSラボ様講演 OpenStack最新情報セミナー 2014年6月
by
VirtualTech Japan Inc.
[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料
by
OSSラボ株式会社
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
CDH4.0.0のNameNode HAを触ってみて
by
NTT DATA OSS Professional Services
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
HDFS (fsimage and edits) in CDH3,CDH4
by
Tatsuo Kawasaki
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
by
Amazon Web Services Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
More from Yifeng Jiang
PDF
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
PDF
introduction-to-apache-kafka
by
Yifeng Jiang
PDF
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
PDF
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
PDF
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
PDF
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
PDF
Spark Security
by
Yifeng Jiang
PDF
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
PDF
Real-time Analytics in Financial
by
Yifeng Jiang
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
Nifi workshop
by
Yifeng Jiang
PDF
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
PPTX
Hive present-and-feature-shanghai
by
Yifeng Jiang
PDF
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
PDF
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
PDF
Data Science on Hadoop
by
Yifeng Jiang
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
introduction-to-apache-kafka
by
Yifeng Jiang
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
Spark Security
by
Yifeng Jiang
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
Real-time Analytics in Financial
by
Yifeng Jiang
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
Nifi workshop
by
Yifeng Jiang
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
Yifeng spark-final-public
by
Yifeng Jiang
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
Hive present-and-feature-shanghai
by
Yifeng Jiang
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
Data Science on Hadoop
by
Yifeng Jiang
HDFS Deep Dive
1.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved HDFS Deep Dive Yifeng Jiang Solutions Engineer, Hortonworks, inc. March 29, 2015
2.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 自己紹介 蒋 逸峰 (Yifeng Jiang) • Solutions Engineer @ Hortonworks Japan • HBase book author • ⽇日本に来て10年年経ちました… • 趣味は⼭山登り • Twitter: @uprush
3.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved アジェンダ • HDFSのガチな内容 • Erasure Code in HDFS • Hadoop on EC2 少し深堀り
4.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved JAWSUG DAYS 2015 http://goo.gl/9ZjNoh
5.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved HDFSのガチな内容 Architecture, Erasure Code Page 5
6.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved What is HDFS? • Hadoop Distributed File System • 分散ファイルシステム • ⾼高い安定性、可⽤用性、スループット • データ ローカリティ • めっちゃスケールできる: 数千台クラスタの実績
7.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved HDFSの主要な新機能 • Namenode HA • スナップショット • Tiered Storage • HDFS NFS Gateway • たくさんのPerformance改善 – DataNode cache, short circuit local read, etc. • Erasure Code (WIP)
8.
© Hortonworks Inc.
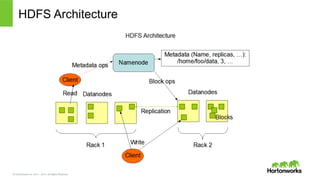
2011 – 2015. All Rights Reserved HDFS Architecture
9.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Namenode • In-‐‑‒memory file system – Directory – File – FSのメタデータ処理理: mkdir, rm, … • Edit log • Checkpoint • Block管理理
10.
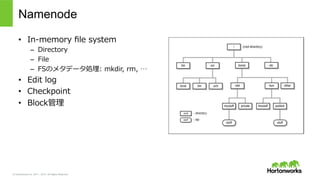
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Datanode • 実際のデータ(block)を保存 – ローカルFS上に保存 – dfs/data/current/…/blk_̲1073741825 • Namenodeとやり取り
11.
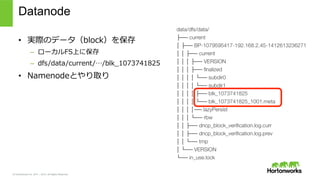
© Hortonworks Inc.
2011 – 2015. All Rights Reserved NamenodeとDatanodeのやり取り • ストレージレポート – ディスクのタイプ、利利⽤用率率率 • Heart beat – 死活管理理 – NNがレスポンスにコマンドを送る。 o 例例:block削除 • Block report: のちほど詳しく DN1 DN2 Namenode I am alive Delete blk1
12.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Files & Blocks • Fileはblocksとして保存されます – /home/yifeng/foo.txt: {b1, b2, b3} • BlockはDatanodeに分散して保存 – 同じblockは3つのDNに複製 – Block sizeは初期値128MB • Blockの配置は重要 – データ ローカリティ – 対障害 /home/yifeng/foo.txt b1 | b2 | b3 128MB 128MB
13.
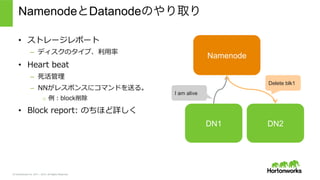
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Block Management • Namenodeはblock locationを保持 – b1: {dn1, dn3, dn4} • NamenodeはDatanodeが保存してい るすべてのblockのリストを保持 – dn1: [b1, b2] /home/yifeng/foo.txt b1 | b2 | b3 DN1 b1 DN2 DN3 DN4 b1 b1 b2 b2 b2 b3 b3 b3
14.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Block Report • NNとDNのblock情報の突き合わせ(diff) – Full report: DNが定期的にNNに送る – Incremental report: block変更更があるたび • Diffが合った場合 – NNがメモリ上のblock mapを更更新か – NNがDNに命令令を出す o 例例:block削除 DN1 b1 DN2 b2 b2 b3 { dn1: [b1, b2] dn2: [b2, b3] } { b1: [dn1, dn3, dn4] b2: [dn1, dn2, dn4] } Namenode b4 I have [b1, b2] I have [b2, b3, b4]
15.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Write Operation 15 • Client: NNに書込み要求 • NN: write lockをかけ、インメモリのFS変更更、lock解除 • NN: edit log sync • NN: audit log sync • NN: clientにレスポンス • Client: write pipeline 的にデータ書込み
16.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved rack1 Write Pipeline 16 DN1 Namenode client switch rack2 DN3 switch DN2 switch 1. Add block 2. Res [dn1, dn2, dn3] 3. client write to dn1 4. dn1 to dn2 5. dn2 to dn3 • Rack認識識 – Dn1: rack1 – Dn2, dn3: rack2 • 書込みはpipeline – Client -‐‑‒> dn1 -‐‑‒> dn2 -‐‑‒> dn3 – データを受取ったら次にパス – Ackは逆順
17.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Data Read • Client: NNに読込み要求 • NN: read lockをかけ、イン メモリFSを取得、clientにレ スポンス、lock解除 • Client: DNにデータ取得 • Rack認識識 17 rack1 DN1 Namenode client switch rack2 DN3 switch DN2 switch 1. Get block location 2. Res [dn1, dn2, dn3] 3. Client read from DNx
18.
© Hortonworks Inc.
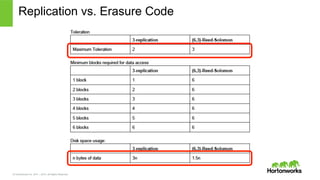
2011 – 2015. All Rights Reserved Data Replication • HDFSはデータを3つのDNに複製 • メリット – 障害時データを失わない – ローカリティ:ローカル、あるいは同じrackのデータを処理理 – コピーだけなのでシンプル • デメリット – ストレージコストが⾼高い – オーバーヘッドは2倍:1PBのストレージは実質0.33PBのデータしか保存できない 18
19.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Erasure Code in HDFS Page 19
20.
© Hortonworks Inc.
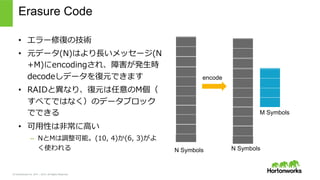
2011 – 2015. All Rights Reserved Erasure Code • エラー修復復の技術 • 元データ(N)はより⻑⾧長いメッセージ(N +M)にencodingされ、障害が発⽣生時 decodeしデータを復復元できます • RAIDと異異なり、復復元は任意のM個( すべてではなく)のデータブロック でできる • 可⽤用性は⾮非常に⾼高い – NとMは調整可能。(10, 4)か(6, 3)がよ く使われる N Symbols N Symbols M Symbols encode
21.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Erasure Code in HDFS • (6,3)-‐‑‒Reed-‐‑‒Solomon – データが6のdata blockと3のparity blockにencodingする – 任意の6のblock (data or parity)でデータ復復元できる • HDFSレイアでの実装 • Intel ISA-‐‑‒L library利利⽤用:通常の10倍早い • 想定ユースケース – ⼤大きい(GB~∼)ファイル:節約効果が⾼高い – データ可⽤用性を⾼高めつつ、ストレージコストを抑えたい – 頻繁にアクセスしないデータ:データローカリティがなくなる 21 HDFS-7285
22.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Replication vs. Erasure Code
23.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Erasure Code in HDFS: Write c1 c2 c3 c4 c5 c6 Incoming data c7 c8 c9 … b1 b2 b3 b4 b5 b6 b1 b2 b3 c1 p1 p2 p3 NamenodeEC Client 1. Add block group 2. Res [dn1, dn2, dn3, …, dn9] DN1 DN2 DN3 … DN9 3. Write c1 to DN1 3. Write c2 to DN2 3. Write c3 to DN3 3. Write cx to DNx 3. Write p3 to DN9 64KB 64KB Encode (6, 3) EC
24.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Erasure Code in HDFS: Read c1 c2 c3 c4 c5 c6 c7 c8 c9 … p1 p2 p3 NamenodeEC Client 1. Get block group 2. Res [dn1, dn2, dn3, …, dn6] DN1 DN2 DN3 … DN6 3. Read 64k from DN1 3. Read 64k from DN2 3. Read 64k from DN2 3. Read 64k from DNx 3. Read 64k from DN6 Decode (6, 3) EC if data block is unavailable Response
25.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Erasure Code in HDFS: Recovery • Namenodeはblockの欠損を検出し、EC Reconstructionをスケジューリング • EC Reconstructionは負荷が高い – CPU, I/O消費が多い – 1 block障害: 無視(書込み中)か低い優先度で – 2 blocks障害: 低い優先度で – 3 blocks障害: 高い優先度で
26.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Hadoop on EC2 すこし深堀り Page 26
27.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Best Practices 常時稼働Hadoopと⼀一時的Hadoop(例例: EMR)の要件が違う (常時稼働)Hadoop on EC2の基本的な考え⽅方 • ローカルストレージがポイント • データノードのデータはインスタンス ストアのみ利利⽤用 • マスタノードのデータはEBSに • データはS3にバックアップ • ディストリビューション(HDP)を使う • 運⽤用管理理ツール、可⽤用性、セキュリティ なぜ?
28.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved なぜインスタンスストア? • HDFSはスループットが重要 • ⼤大きいブロックサイズ(128MB)使っている • ディスクseekを減らし、Sequence IOに最適化 • データローカリティが重要 • インスタンスストアが⾼高速、かつ無料料。データ冗⻑⾧長化はHDFS任せ • EBSはお勧めしない • ネットワークI/Oがボトルネック • Random I/Oに最適
29.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved HDD vs. SSD • Hadoopはほとんどの場合はHDDがベスト • 大量のHDD (12本~)、1本あたり数TBのインスタンスストアがあるEC2 インスタンスタイプが望ましい HDD SSD Random IOPS 100 ~ 180 20,000 MB/s 160 ~ 200 400 TB 4 ~ 6 1.2 Cost $200 $1000 $/TB/(MB/s) Low High $/TB/IOPS High Low RDB HDFS
30.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved なぜS3にバックアップ? • EC2のtopologyは取れない、コントロールできない • 同じHWなのか?同じRackなのか? • Placement GroupはRackとみなすべき? • バックアップ⽅方法 • Batch: Distcp, Falcon • Double-‐‑‒write: Kinesis / Kafka + StormでS3とHDFSに両⽅方書込み
31.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved まとめ Page 31
32.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Hadoop Trends and Hadoop on EC2 • Hadoopは常に早く進化しています • 次世代モダン・データアーキテクチャ (MDA)はHadoopにて実現 • Hadoopはより効率率率、安全、早くなっています • Hadoopの深堀りはする価値がある • Hadoop on EC2は効率率率や柔軟性が⾼高い
33.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Thank you Yifeng Jiang, Solutions Engineer, Hortonworks @uprush
Download









![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Block Management
• Namenodeはblock locationを保持
– b1: {dn1, dn3, dn4}
• NamenodeはDatanodeが保存してい
るすべてのblockのリストを保持
– dn1: [b1, b2]
/home/yifeng/foo.txt
b1 | b2 | b3
DN1
b1
DN2
DN3 DN4
b1
b1
b2
b2
b2
b3
b3
b3](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-13-320.jpg)
![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Block Report
• NNとDNのblock情報の突き合わせ(diff)
– Full report: DNが定期的にNNに送る
– Incremental report: block変更更があるたび
• Diffが合った場合
– NNがメモリ上のblock mapを更更新か
– NNがDNに命令令を出す
o 例例:block削除
DN1
b1
DN2
b2
b2
b3
{ dn1: [b1, b2]
dn2: [b2, b3]
}
{ b1: [dn1, dn3, dn4]
b2: [dn1, dn2, dn4]
}
Namenode
b4
I have [b1,
b2]
I have [b2,
b3, b4]](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-14-320.jpg)

![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
rack1
Write Pipeline
16
DN1
Namenode
client
switch
rack2
DN3
switch
DN2
switch
1. Add block
2. Res [dn1, dn2, dn3]
3. client write to dn1
4. dn1 to dn2
5. dn2 to dn3
• Rack認識識
– Dn1: rack1
– Dn2, dn3: rack2
• 書込みはpipeline
– Client -‐‑‒> dn1 -‐‑‒> dn2 -‐‑‒> dn3
– データを受取ったら次にパス
– Ackは逆順](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-16-320.jpg)
![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Data Read
• Client: NNに読込み要求
• NN: read lockをかけ、イン
メモリFSを取得、clientにレ
スポンス、lock解除
• Client: DNにデータ取得
• Rack認識識
17
rack1
DN1
Namenode
client
switch
rack2
DN3
switch
DN2
switch
1. Get block location
2. Res [dn1, dn2, dn3]
3. Client read from DNx](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-17-320.jpg)



![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Erasure Code in HDFS: Write
c1
c2
c3
c4
c5
c6
Incoming data
c7
c8
c9
…
b1
b2
b3
b4
b5
b6
b1
b2
b3
c1
p1
p2
p3
NamenodeEC Client
1. Add block group
2. Res [dn1, dn2, dn3, …, dn9]
DN1
DN2
DN3
…
DN9
3. Write c1 to DN1
3. Write c2 to DN2
3. Write c3 to DN3
3. Write cx to DNx
3. Write p3 to DN9
64KB
64KB
Encode (6, 3) EC](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-23-320.jpg)
![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Erasure Code in HDFS: Read
c1
c2
c3
c4
c5
c6
c7
c8
c9
…
p1
p2
p3
NamenodeEC Client
1. Get block group
2. Res [dn1, dn2, dn3, …, dn6]
DN1
DN2
DN3
…
DN6
3. Read 64k from DN1
3. Read 64k from DN2
3. Read 64k from DN2
3. Read 64k from DNx
3. Read 64k from DN6
Decode (6, 3) EC
if data block is unavailable
Response](https://image.slidesharecdn.com/hdfs-deep-dive-150329223310-conversion-gate01/85/HDFS-Deep-Dive-24-320.jpg)














![[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...](https://cdn.slidesharecdn.com/ss_thumbnails/tehahj7vqmsswpgrzrq6-signature-4c7632456c9c538ff9d2a30431910153be9e17d570b88fac06692ab02f11f222-poli-160725043205-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料](https://cdn.slidesharecdn.com/ss_thumbnails/140605openstackcephbenchmark-140605203155-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























