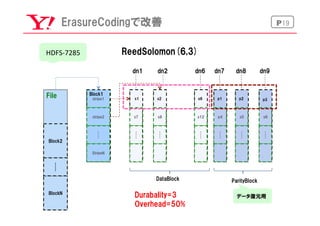
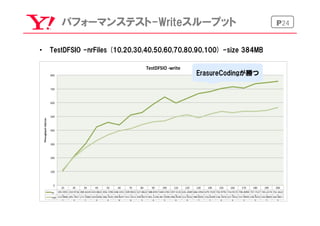
P9普通のHDFS
NameNode
※active
fsimage
NameNode
※standby
fsimage
JournalNode
client
create,rm…
editlog
k
block
k
block
k
block
k
block
DataNode
k
block
k
block
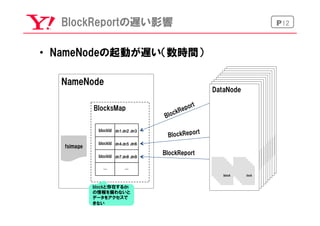
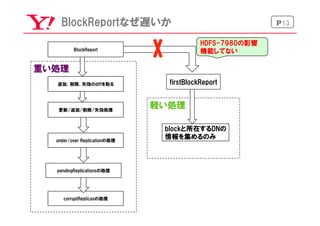
BlockReport
client
ls, create, mv…
editlog
editlog
/
10.
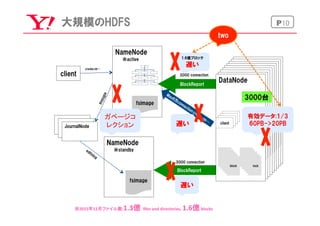
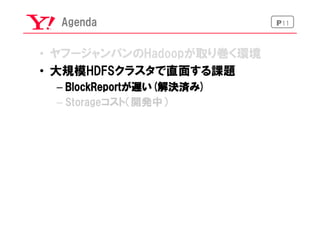
P10大規模のHDFS
NameNode
※active
fsimage
NameNode
※standby
fsimage
JournalNode
client
create,rm…
3000 connection
BlockReport
BlockReport
3000 connection
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
k
block
DataNode
blockblock
client
client
client
client
ガベージコ
レクション 遅い
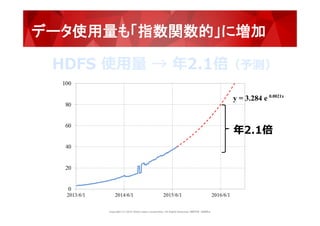
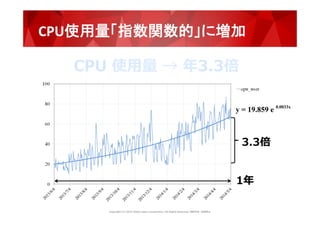
1.6億ブロック
遅い
遅い
※2015年11月ファイル数:1.3億 files
and
directories,
1.6億
blocks
3000台
/
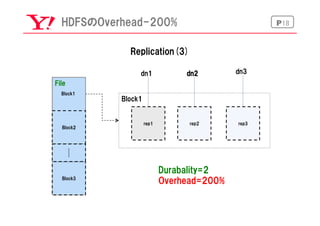
有効データ:1/3
60PB->20PB
two