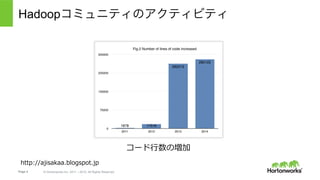
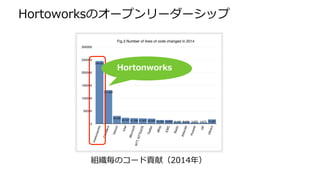
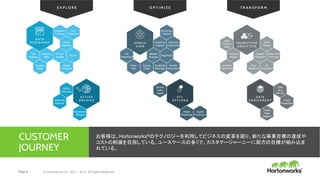
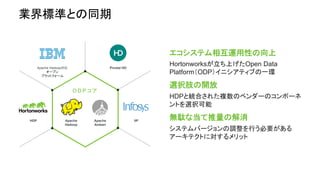
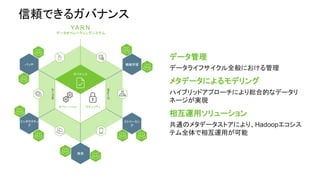
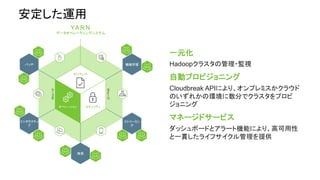
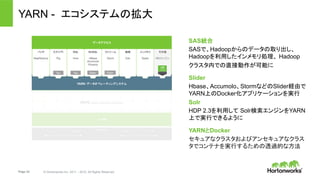
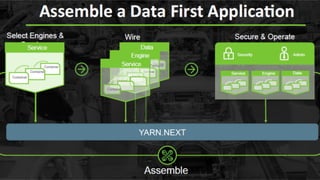
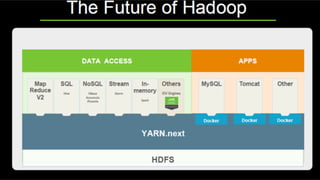
About Hortonworks
顧客
• 556のお客様 (2015年8月5日時点)
• 2015年2期に119 新規お客様追加
• NASDAQに上場(HDP)
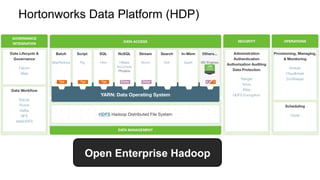
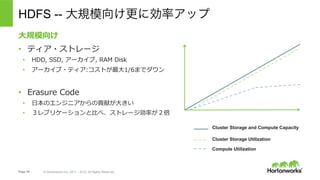
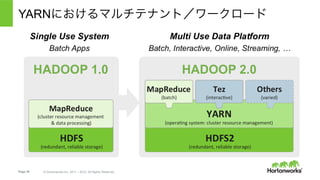
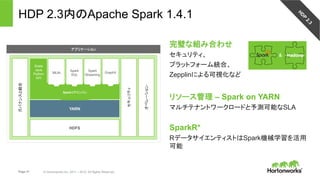
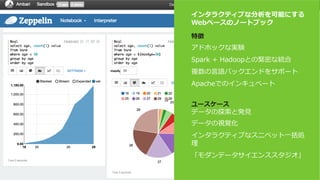
Hortonworks Data Platform
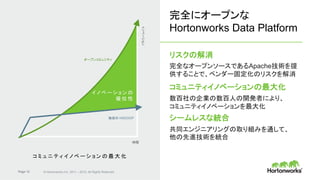
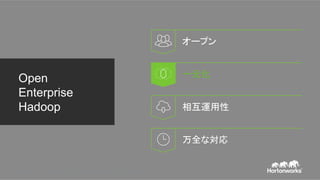
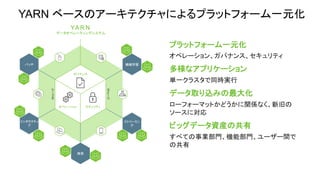
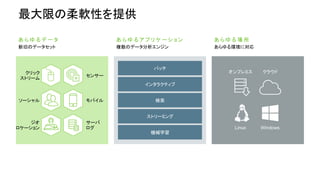
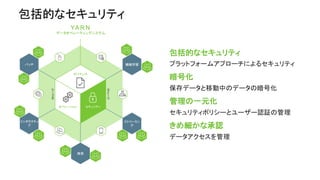
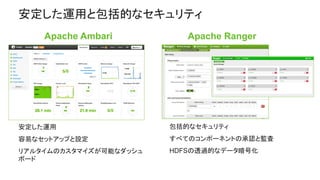
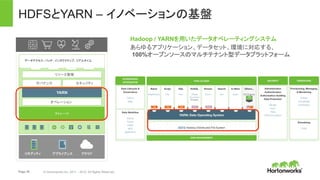
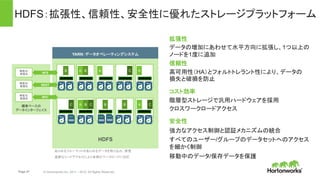
• 完全にオープンなマルチテナント プラット
フォーム。あらゆるデータ、あらゆるアプリ。
• 一貫したエンタプライズ サービス:セキュリ
ティ、オペレーション、ガバナンス
お客様のためのパートナー
• オープンソース コミュニティのリーダー、エ
ンタプライズ要件を満たすための革新に注力
• 比類のないHadoopのサポートサブスクリプ
ション
Founded in 2011
Original 24 architects, developers,
operators of Hadoop from Yahoo!
740+
E M P L O Y E E S
1350+
E C O S Y S T E M
PA R T N E R S