Recommended
PPTX
PPT
PDF
より速く より運用しやすく 進化し続けるJVM(Java Developers Summit Online 2023 発表資料)
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
PPTX
スケールアウトするPostgreSQLを目指して!その第一歩!(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PDF
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
PPTX
PDF
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
PDF
待ち事象から考える、Sql server の改善ポイント
PDF
PDF
PDF
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
PPTX
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
PDF
GKE に飛んでくるトラフィックを 自由自在に操る力 | 第 10 回 Google Cloud INSIDE Games & Apps Online
PPTX
NTTデータ流Infrastructure as Code~ 大規模プロジェクトを通して考え抜いた基盤自動化の新たな姿~(NTTデータ テクノロジーカンフ...
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
PDF
KeycloakのDevice Flow、CIBAについて
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PPTX
PDF
PDF
PDF
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
PDF
Guide to Cassandra for Production Deployments
PPTX
More Related Content
PPTX
PPT
PDF
より速く より運用しやすく 進化し続けるJVM(Java Developers Summit Online 2023 発表資料)
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
PPTX
スケールアウトするPostgreSQLを目指して!その第一歩!(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PDF
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
What's hot
PPTX
PDF
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
PDF
待ち事象から考える、Sql server の改善ポイント
PDF
PDF
PDF
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
PPTX
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
PDF
GKE に飛んでくるトラフィックを 自由自在に操る力 | 第 10 回 Google Cloud INSIDE Games & Apps Online
PPTX
NTTデータ流Infrastructure as Code~ 大規模プロジェクトを通して考え抜いた基盤自動化の新たな姿~(NTTデータ テクノロジーカンフ...
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
PDF
KeycloakのDevice Flow、CIBAについて
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PPTX
PDF
PDF
PDF
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
Similar to Coherenceを利用するときに気をつけること #OracleCoherence
PDF
Guide to Cassandra for Production Deployments
PPTX
PDF
PDF
Scalable Cooperative File Caching with RDMA-Based Directory Management
PDF
JPAのキャッシュを使ったアプリケーション高速化手法
PPTX
PDF
20110517 okuyama ソーシャルメディアが育てた技術勉強会
PDF
PPT
【17-C-2】 クラウド上でのエンタープライズアプリケーション開発
PDF
Amazon ElastiCache - AWSマイスターシリーズ
PDF
20120117 13 meister-elasti_cache-public
PDF
InfoTalk springbreak_2012
PDF
Cassandraのトランザクションサポート化 & web2pyによるcms用プラグイン開発
PDF
PPT
PDF
PDF
Hadoop book-2nd-ch3-update
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
PPTX
PDF
More from Toshiaki Maki
PDF
From Spring Boot 2.2 to Spring Boot 2.3 #jsug
PDF
Concourse x Spinnaker #concourse_tokyo
PDF
Serverless with Spring Cloud Function, Knative and riff #SpringOneTour #s1t
PDF
決済システムの内製化への旅 - SpringとPCFで作るクラウドネイティブなシステム開発 #jsug #sf_h1
PDF
Spring Boot Actuator 2.0 & Micrometer #jjug_ccc #ccc_a1
PDF
Spring Boot Actuator 2.0 & Micrometer
PDF
Open Service Broker APIとKubernetes Service Catalog #k8sjp
PDF
Spring Cloud Function & Project riff #jsug
PDF
Introduction to Spring WebFlux #jsug #sf_a1
PDF
BOSH / CF Deployment in modern ways #cf_tokyo
PDF
Why PCF is the best platform for Spring Boot
PDF
Zipkin Components #zipkin_jp
PPTX
マイクロサービスに必要な技術要素はすべてSpring Cloudにある #DO07
PDF
Spring Framework 5.0による Reactive Web Application #JavaDayTokyo
PDF
実例で学ぶ、明日から使えるSpring Boot Tips #jsug
PDF
PDF
Event Driven Microservices with Spring Cloud Stream #jjug_ccc #ccc_ab3
PDF
Managing your Docker image continuously with Concourse CI
PDF
Data Microservices with Spring Cloud Stream, Task, and Data Flow #jsug #spri...
PDF
Short Lived Tasks in Cloud Foundry #cfdtokyo
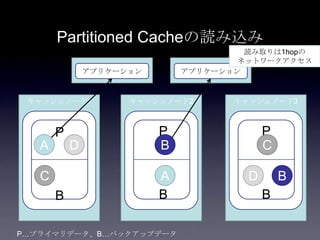
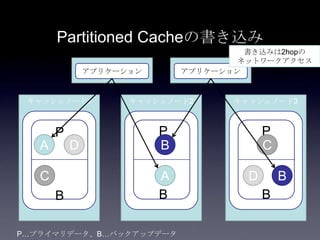
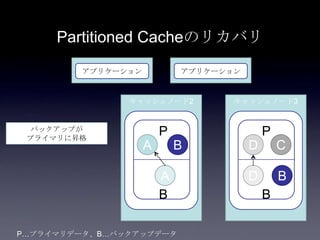
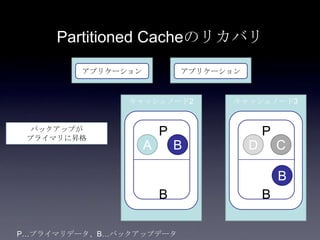
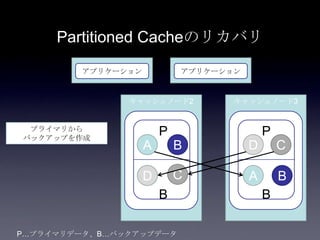
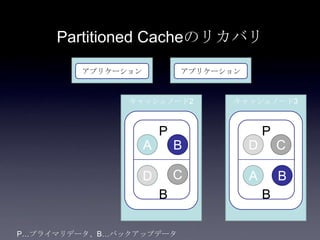
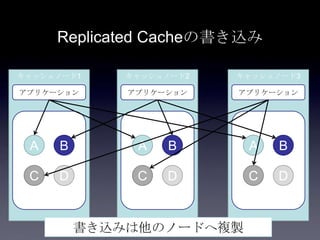
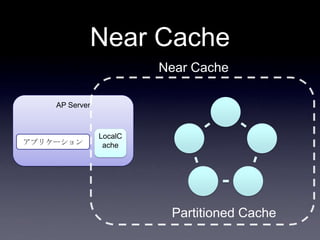
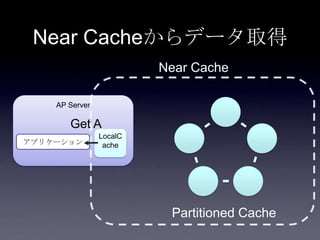
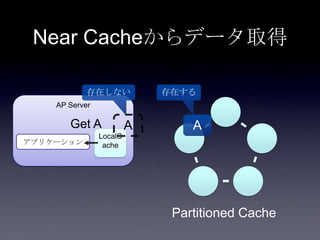
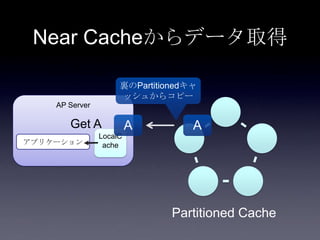
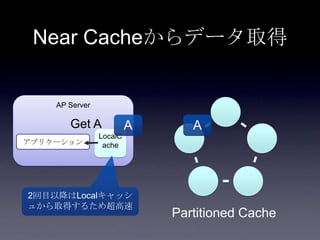
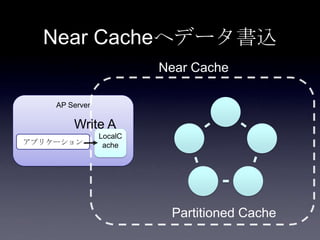
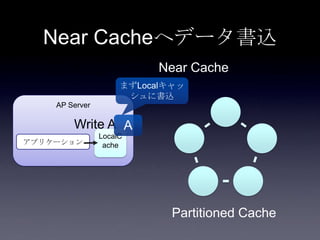
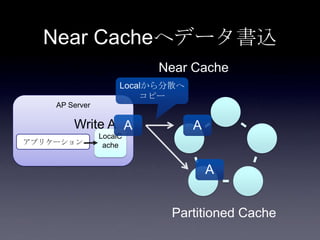
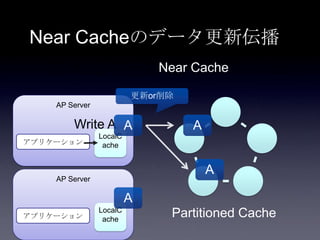
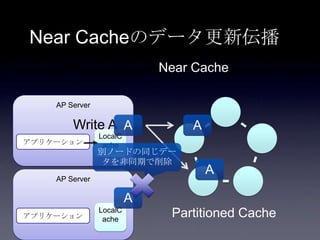
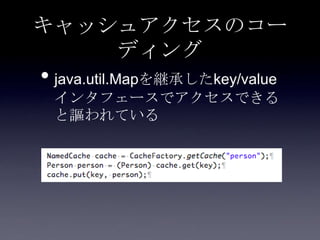
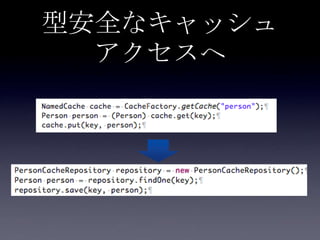
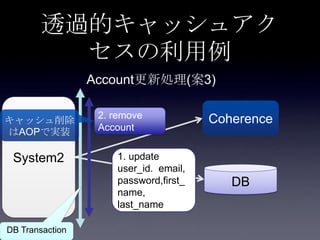
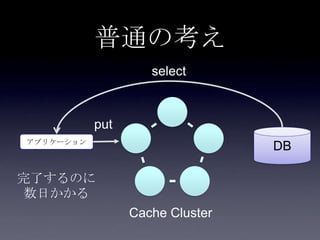
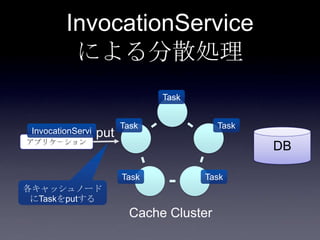
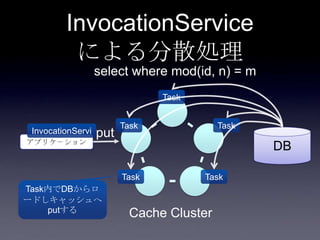
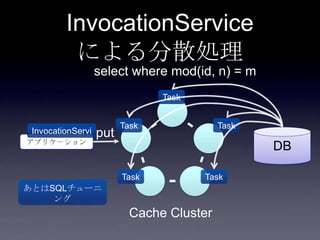
Coherenceを利用するときに気をつけること #OracleCoherence 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. Near Cache
• Partitioned Cache + Local Cache。
• 書き込みはLocal Cache→Partitioned Cacheの順
に行う。読み込み時にLocal Cacheになかったら
Partitioned Cacheを探す。
• 読み込み速度は2回目以降は超高速
• キャッシュ削除の伝播が非同期であることに注
意。
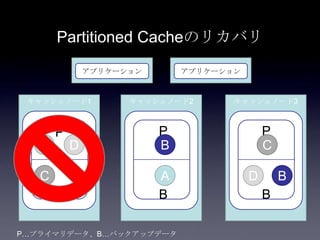
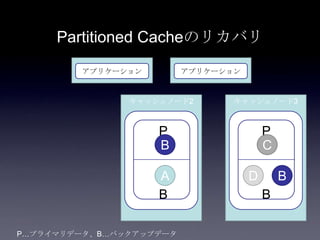
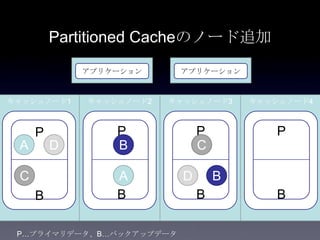
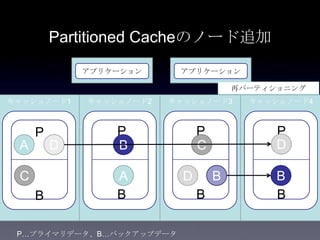
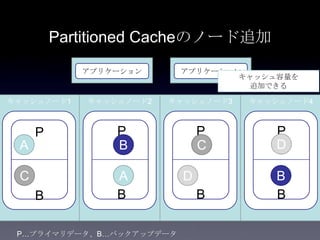
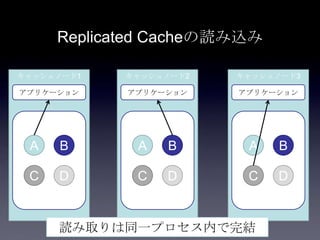
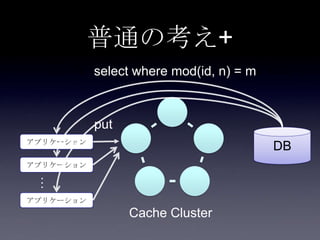
31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. Cache方式の比較
方式 書き込み 読み込み データサイズ 耐障害性 一貫性
Partitio
ned
1+n hop
n=バック
アップ数
通常n=1
1 hop ノードの追加
によって容量
を拡張可能
バックアップから
プライマリへ昇格
し、新たなバック
アップを別ノード
に作成
一貫
Replicat
ed
m-1 hop
m=ノード
数
(同期/非
同期でレ
イテンシ
が変わる)
0 hop 1プロセスに
割り当て可能
な最大量(2
~4GB)
高い(落ちたノード
を無視するのみ)
一貫
Near 1+n(+m-
1)
()内は非
0 hop
(初回を除
く)
Partitionedと
同じ
(local cache
が容量オーバ
? 要検討
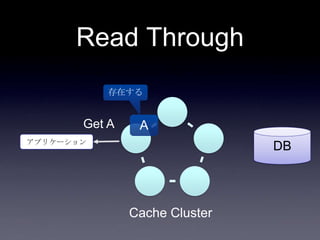
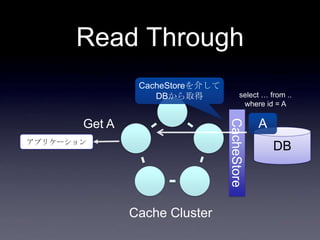
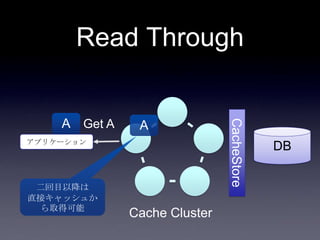
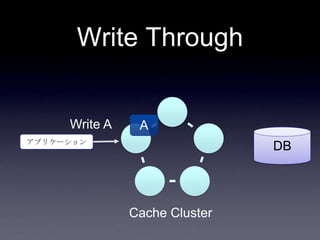
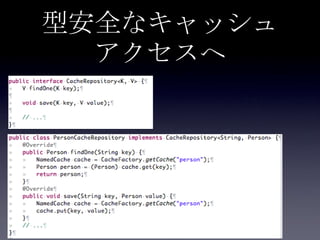
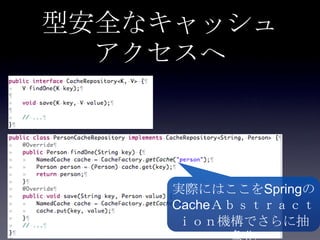
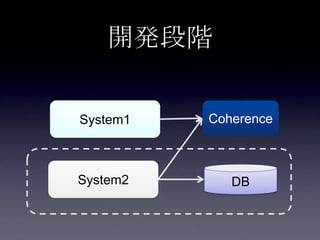
42. 43. DB連携方式
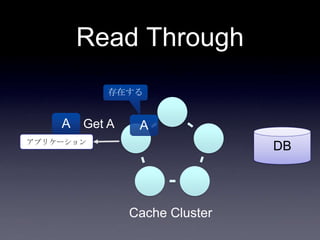
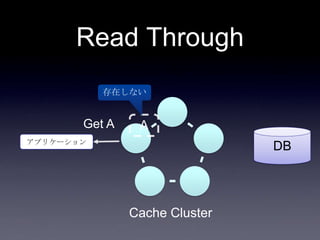
• read through
• キャッシュ上になかったらDBから取り出し
キャッシュに乗せる
• write through
• キャッシュに書き込んだ後、同期してDBに
書き込む
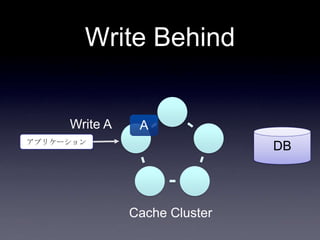
• write behind
• キャッシュに書き込んだ後、非同期でDBに
書き込む
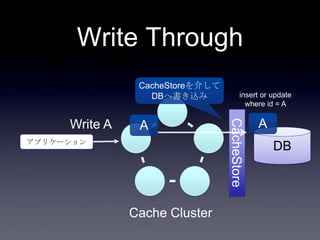
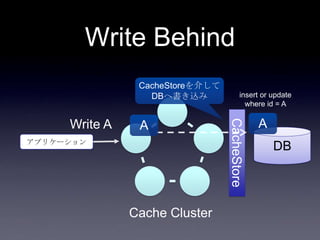
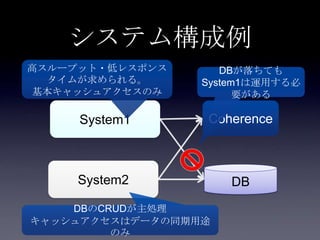
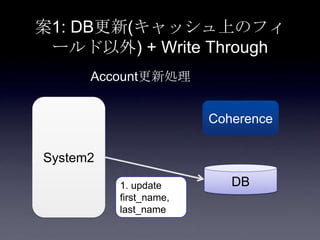
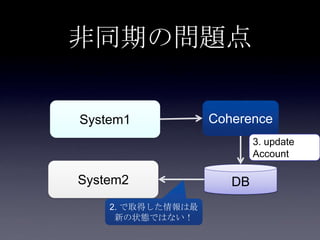
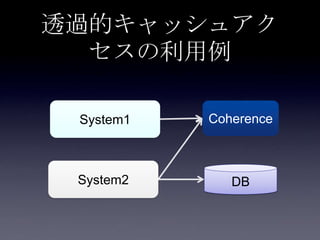
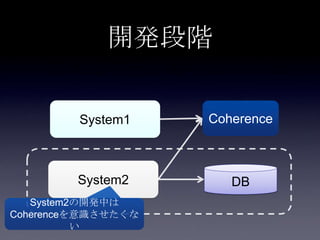
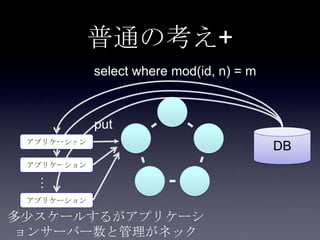
44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 案1: DB更新(キャッシュ上のフィ
ールド以外) + Write Through
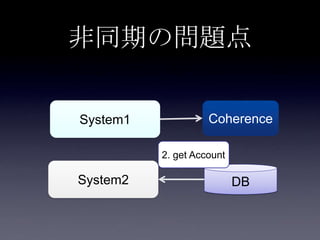
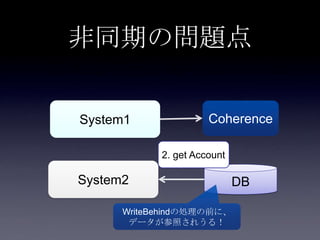
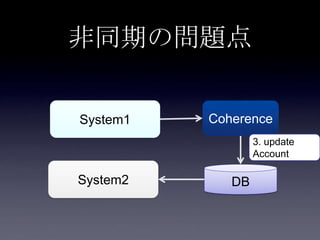
System2
Coherence
DB
2. put Account
3. update
user_id,
email,
password
1. update
first_name,
last_name
Account更新処理
write through
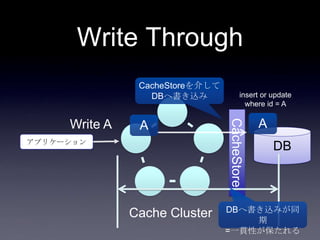
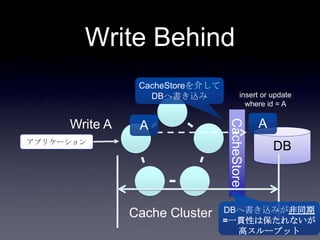
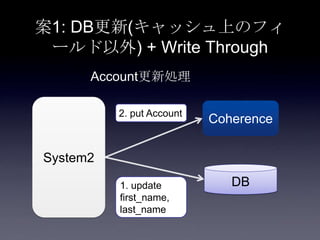
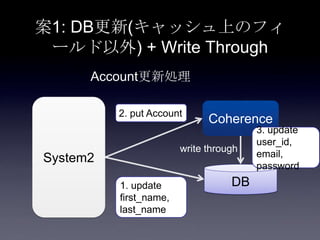
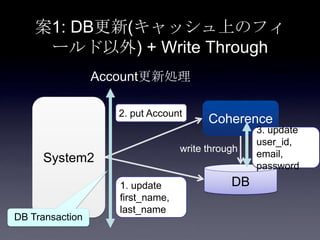
76. 案1: DB更新(キャッシュ上のフィ
ールド以外) + Write Through
System2
Coherence
DB
2. put Account
3. update
user_id,
email,
password
1. update
first_name,
last_name
Account更新処理
write through
DB Transaction
77. 案1: DB更新(キャッシュ上のフィ
ールド以外) + Write Through
• Account更新処理の実装が複雑
• キャッシュ更新とDB更新の両方を意識する必要がある
• JPAを使っており、accountテーブルの全フィールド更
新に比べて、一部フィールドのみ更新する実装コスト
が高い
• DB更新トランザクションとWrite Throughのトランザクシ
ョンが別になり、片方DBでエラーが生じすると整合性が
とれなくなる
• キャッシュへputしたあとDBコミットするまでに整合性が
とれていない期間がある
• トランザクション(AOP)がロールバックされてもキャッ
シュに残り続ける
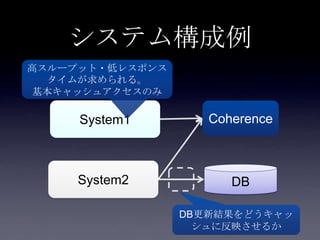
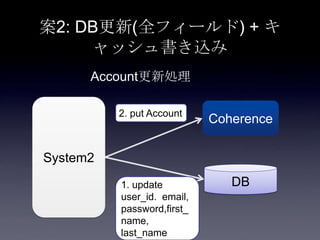
78. 79. 案2: DB更新(全フィールド) + キ
ャッシュ書き込み
System2
Coherence
DB1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
80. 案2: DB更新(全フィールド) + キ
ャッシュ書き込み
System2
Coherence
DB
2. put Account
1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
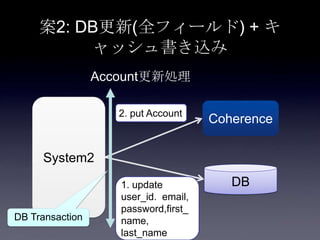
81. 案2: DB更新(全フィールド) + キ
ャッシュ書き込み
System2
Coherence
DB
2. put Account
1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
DB Transaction
82. 案2: DB更新(全フィールド) + キ
ャッシュ書き込み
• 実装は案1より低い
• 案1同様キャッシュへputしたあとDBコ
ミットするまでに整合性がとれていな
い期間がある
• トランザクション(AOP)がロールバッ
クされてもキャッシュに残り続ける
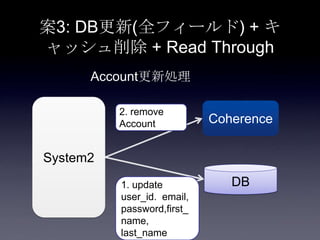
83. 84. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
System2
Coherence
DB1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
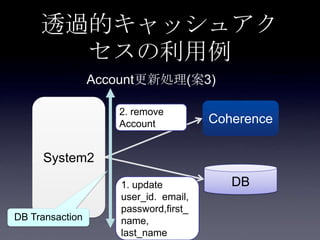
85. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
System2
Coherence
DB1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
2. remove
Account
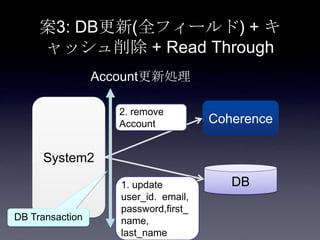
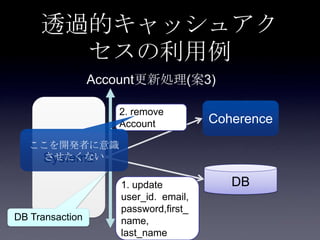
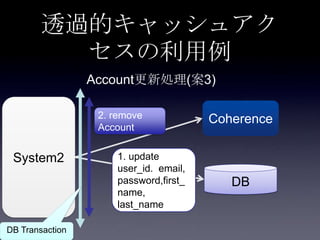
86. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
System2
Coherence
DB1. update
user_id. email,
password,first_
name,
last_name
Account更新処理
2. remove
Account
DB Transaction
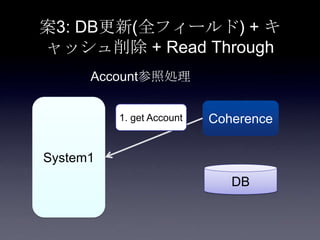
87. 88. 89. 案3: DB更新(全フィールド) + キ
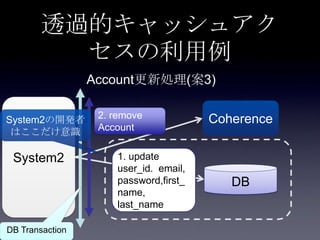
ャッシュ削除 + Read Through
System1
Coherence
DB
Account参照処理
1. get Account
remove済み
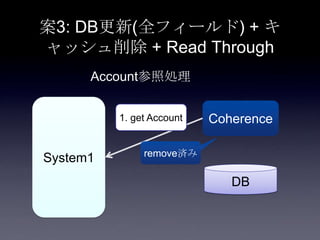
90. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
System1
Coherence
DB
Account参照処理
1. get Account
2. select
user_id,
email,
password
read through
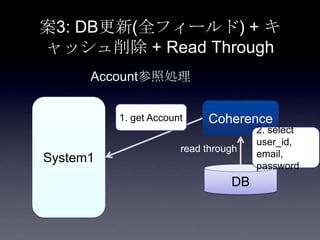
91. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
System1
Coherence
DB
Account参照処理
1. get Account
2. select
user_id,
email,
password
read through
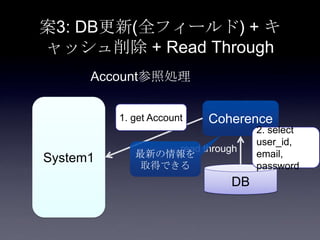
最新の情報を
取得できる
92. 案3: DB更新(全フィールド) + キ
ャッシュ削除 + Read Through
• 実装コストが低い
• キャッシュモデル作成不要
• 対象のキーを使って削除するだけ
• データ整合性が高い
• データ不整合が起こる可能性が低い
• 念のためDBコミット後もう一回削除で整合性
を高められる
• キャッシュに初回読み込み時は連ポンスタイム
が遅くなる
• DB更新後にpreloadで対応
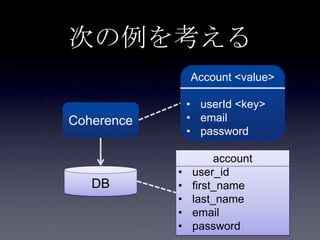
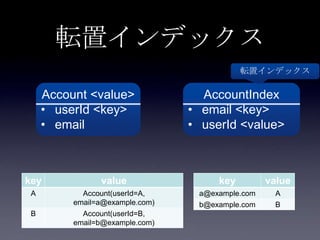
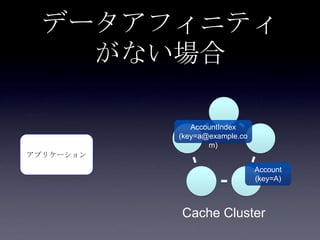
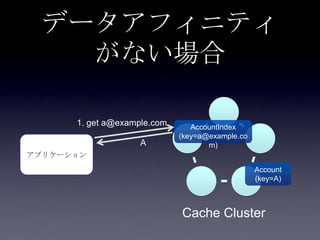
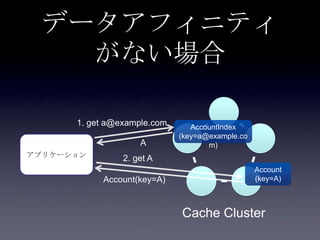
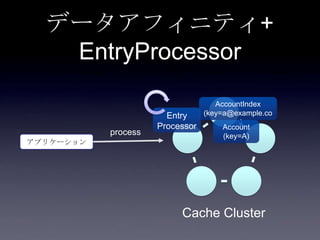
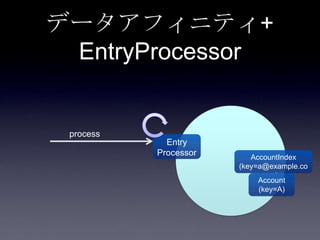
93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 転置インデックス
Account <value>
• userId <key>
• email
AccountIndex
• email <key>
• userId <value>
転置インデックス
key value
A Account(userId=A,
email=a@example.com)
B Account(userId=B,
email=b@example.com)
key value
a@example.com A
b@example.com B
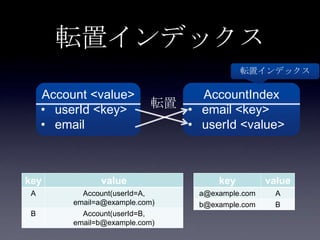
111. 転置インデックス
Account <value>
• userId <key>
• email
AccountIndex
• email <key>
• userId <value>
転置インデックス
key value
A Account(userId=A,
email=a@example.com)
B Account(userId=B,
email=b@example.com)
key value
a@example.com A
b@example.com B
転置
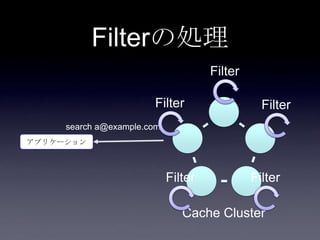
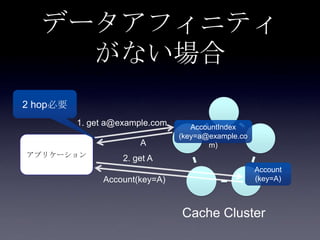
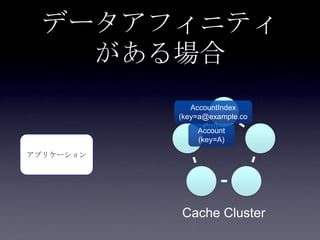
112. 113. 114. 115. 116. 117. 118. 比較
メリット デメリット
転置インデ
ックス
• 2hopで対象のキャッシュにア
クセスできて高速
• 通常のキャッシュアクセス
(put/get)の範疇で考えられる
• CRUDそれぞれで転置イ
ンデックス用のコーディ
ングを意識する必要があ
る
• 一対多の場合複雑(排他処
理の検討、
EntryProcessor)
Filter
• 自動でインデックスを作成で
きるのでコーディングがシン
プル
• Native APIの学習
• 全キャッシュノードに対
するパラレル処理になり、
負荷が大きい
• 高スループットな処理に
向かない
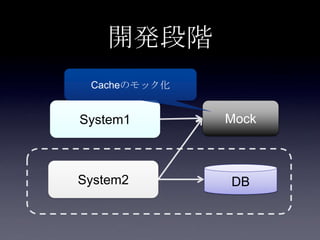
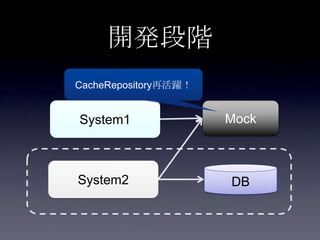
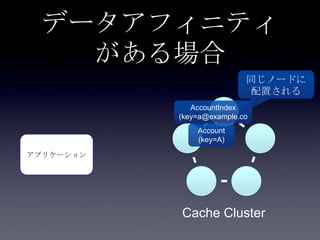
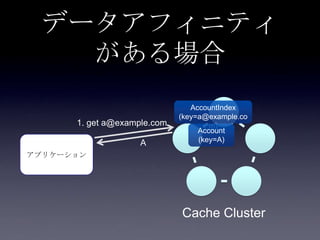
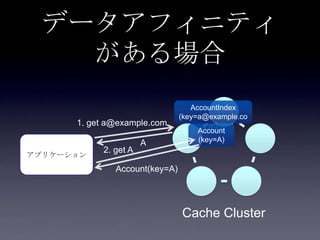
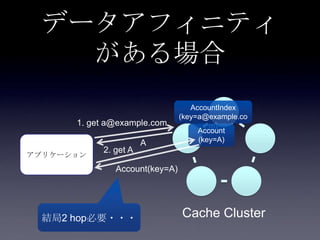
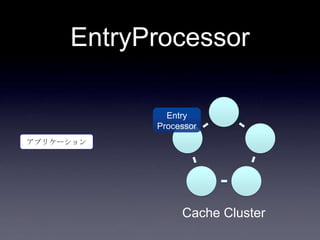
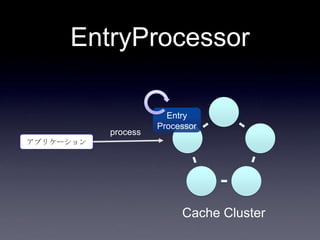
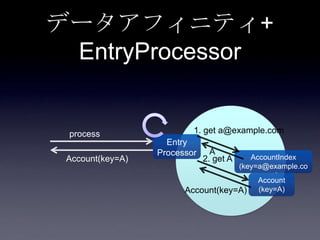
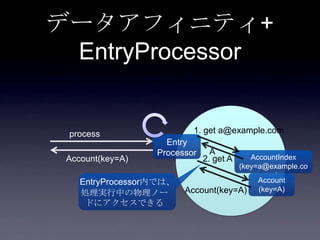
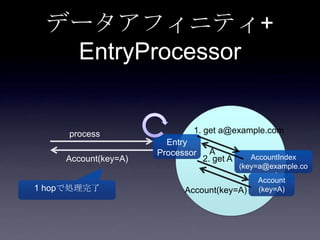
119. 120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143. 144. 145. 146. 147. 148. 149. 150. 151. 152. 153. 154. 155. 156. 157. 158. 159. 160. 161. 162. 163. 164. 165. 166. 167. 168. 169. 170. 171. 172. 173. 174. 175. 176. 177. 178. 179. 180. 181. 182. 183. 184. 185. まとめ
• 前提知識のおさらい
• Cache方式
• DB連携方式
• 設計編
• キャッシュデータの種類
• メモリとDBの同期
• データの検索
• コーディング編
• キャッシュアクセスのコーディング
• モックの利用
• チューニング編
• データアフィニティ
• EntryProcessor
• Advanced Topic
• InvocationServiceによる初期ロード
186.

























![キャッシュデータの種類
• メモリ上にのみ存在してDBには存在し
ないもの
• メモリ上にもDBにも存在して同期が必
要な物
• [メモリ上に一時的に存在してDBに同期
したら削除するもの]](https://image.slidesharecdn.com/coherence-130821054733-phpapp02/85/Coherence-OracleCoherence-58-320.jpg)
![キャッシュデータの種類
• メモリ上にのみ存在してDBには存在し
ないもの(非永続データ)
• メモリ上にもDBにも存在して同期が必
要な物(永続データ)
• [メモリ上に一時的に存在してDBに同期
したら削除するもの(揮発データ)]](https://image.slidesharecdn.com/coherence-130821054733-phpapp02/85/Coherence-OracleCoherence-59-320.jpg)
![キャッシュデータの種類
• メモリ上にのみ存在してDBには存在し
ないもの(非永続データ)
• メモリ上にもDBにも存在して同期が必
要な物(永続データ)
• [メモリ上に一時的に存在してDBに同期
したら削除するもの(揮発データ)]
同期方法要注意](https://image.slidesharecdn.com/coherence-130821054733-phpapp02/85/Coherence-OracleCoherence-60-320.jpg)











































































![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)




















































