Downloaded 27 times












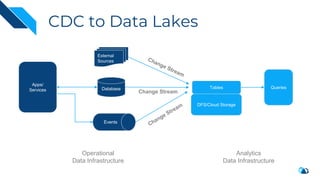








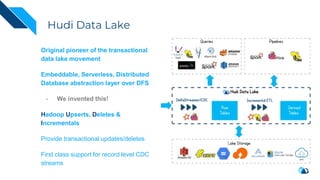
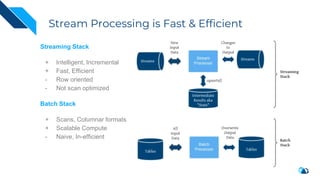
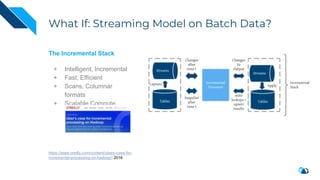


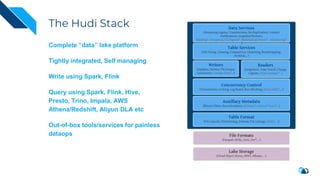
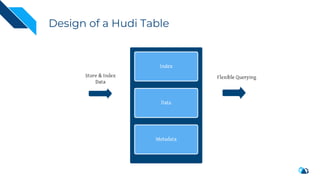
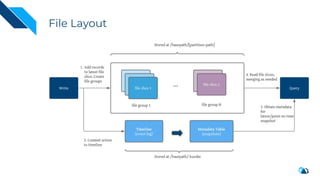
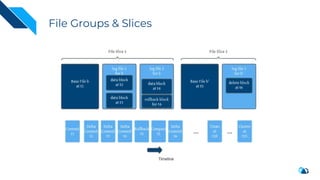
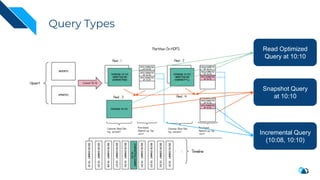
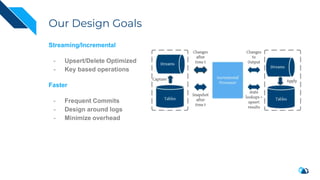
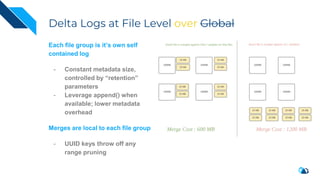
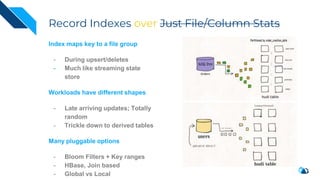
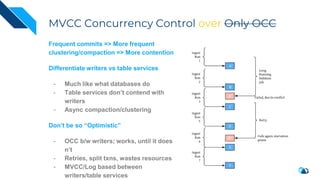

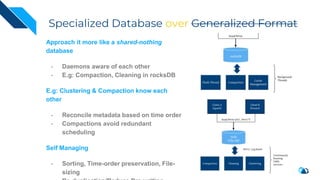
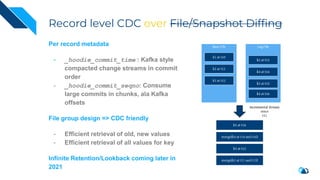


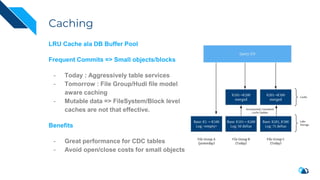
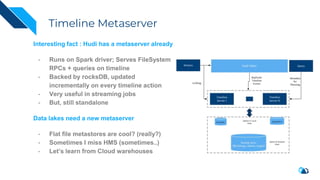
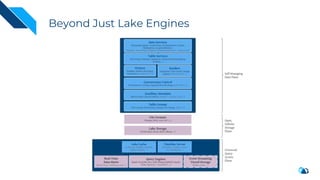






The document discusses the transition from change data capture (CDC) to data lakes using Apache Pulsar and Hudi, detailing the importance of CDC in data integration and low-latency systems. It outlines a comprehensive agenda covering CDC background, data lake creation, and an in-depth analysis of Hudi, including its architecture, design choices, and operational capabilities. The speaker bio indicates extensive expertise in data infrastructure and platforms, showcasing the significant impact of Hudi at Uber's large-scale transactional data lake.




























![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)


























































