Downloaded 659 times






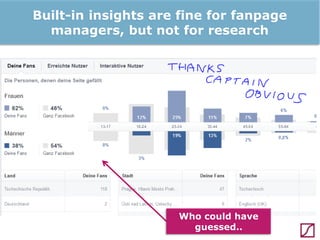













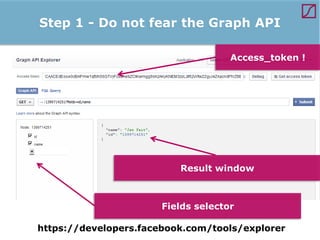



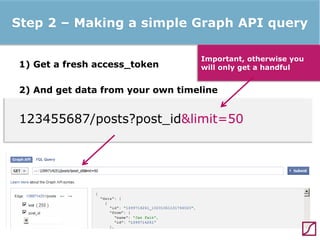
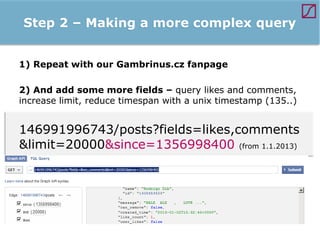

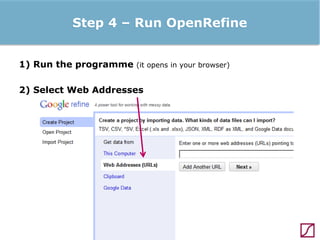
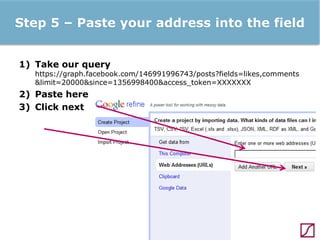
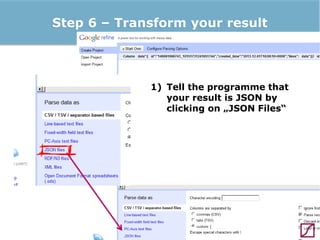
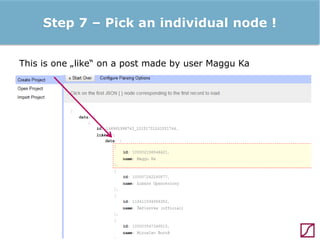
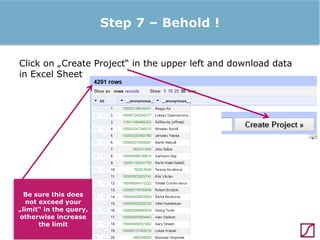

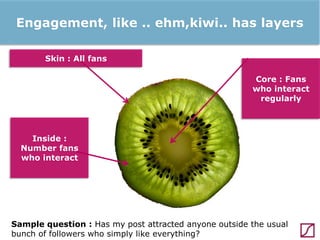
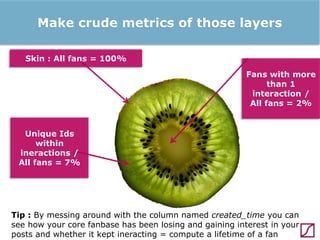

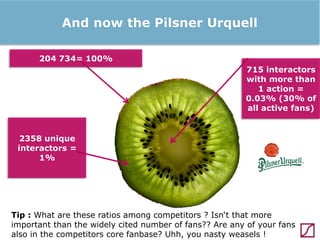
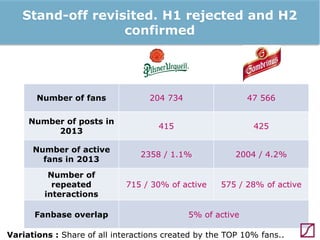

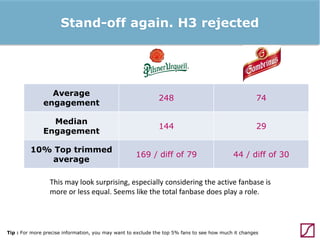




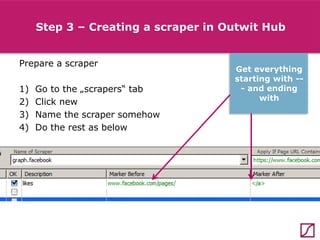
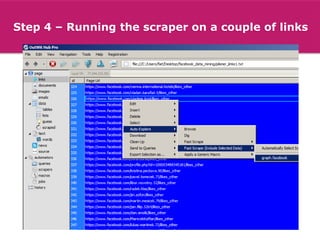






The lecture discusses the process and benefits of analyzing Facebook data without needing programming skills, focusing on understanding fan engagement and demographics for businesses. It highlights tools like the Facebook Graph API and OpenRefine for data extraction and analysis, while emphasizing the importance of metrics like active fan interaction over mere fan counts. The document also covers practical steps and potential obstacles in conducting this research, noting the evolving nature of Facebook's platform and its implications for data accessibility.























































































