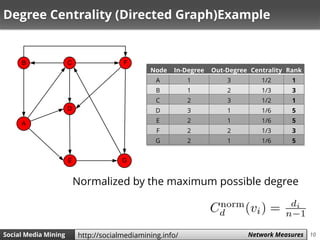
The document discusses various network measures related to social media mining, focusing on metrics such as centrality, degree centrality, eigenvector centrality, Katz centrality, and PageRank. It highlights the importance of defining measurements for quantifying centrality, interaction levels, and similarity among users to identify influential figures and common interaction patterns. Additionally, it explores methodologies for calculating these centrality measures and provides examples to illustrate their application.

























![27Social Media Mining Measures and Metrics 27Social Media Mining Network Measureshttp://socialmediamining.info/
PageRank Example – Alternative Approach [Markov Chains]
Step A B C D E F G
0 1/7 1/7 1/7 1/7 1/7 1/7 1/7
1 B/2 C/3 A/3 + G A/3 + C/3 + F/2 A/3 + D C/3 + B/2 F/2 + E
0.071 0.048 0.190 0.167 0.190 0.119 0.214
Using Power
Method
”You don't understand
anything until you learn it
more than one way”
𝛼=1 and 𝛽 =0?
Marvin Minsky (1927-2016)](https://image.slidesharecdn.com/smm-slides-ch3-160621151814/85/Social-Media-Mining-Chapter-3-Network-Measures-27-320.jpg)








![36Social Media Mining Measures and Metrics 36Social Media Mining Network Measureshttp://socialmediamining.info/
Brandes Algorithm [2001]
𝑝𝑟𝑒𝑑(𝑠, 𝑤) is the set of predecessors of 𝑤 in the
shortest paths from 𝑠 to 𝑤.
– In the most basic scenario, 𝑤 is the immediate child of 𝑣𝑖
There exists a recurrence equation that can help
us determine 𝛿𝑠(𝑣𝑖)](https://image.slidesharecdn.com/smm-slides-ch3-160621151814/85/Social-Media-Mining-Chapter-3-Network-Measures-36-320.jpg)
















![53Social Media Mining Measures and Metrics 53Social Media Mining Network Measureshttp://socialmediamining.info/
[Global] Clustering Coefficient
• Clustering coefficient measures transitivity
in undirected graphs
– Count paths of length two and check whether the
third edge exists
When counting triangles, since every triangle has 6
closed paths of length 2](https://image.slidesharecdn.com/smm-slides-ch3-160621151814/85/Social-Media-Mining-Chapter-3-Network-Measures-53-320.jpg)

![55Social Media Mining Measures and Metrics 55Social Media Mining Network Measureshttp://socialmediamining.info/
[Global] Clustering Coefficient: Example](https://image.slidesharecdn.com/smm-slides-ch3-160621151814/85/Social-Media-Mining-Chapter-3-Network-Measures-55-320.jpg)















![71Social Media Mining Measures and Metrics 71Social Media Mining Network Measureshttp://socialmediamining.info/
Normalized Similarity, cont.
𝒏 times the Covariance between 𝑨𝒊 and 𝑨𝒋
Normalize covariance by the multiplication of Variances.
We get Pearson correlation coefficient
(range of [-1,1] )](https://image.slidesharecdn.com/smm-slides-ch3-160621151814/85/Social-Media-Mining-Chapter-3-Network-Measures-71-320.jpg)



























































































