0.Background-From cv tasksto object detection-YOLO
• Object detection: Locate BBox and classfication;
• Input: image feature map or hand craft faeture; output: object bbox and label methods: one(two)-stage object
detection,anchor-Free etc ;
• Semantic segmentation: Classify each pixel semantic and classfication;
• Input: image feature map;output: segmentation label; methods: FCN,dilated Convolution etc;
• Instance segmentation: Classify different instance in each categories;
• Input: object detection preliminary result; output: pixel segmentation mask; methods: mask-rcnn etc.
• YOLO: This document mainly to illustrate YOLOV1,this paper solve the inference speed problem of two-stage
detection,and find a good balance between inference speed and accuracy.
3.
Abstract
• Background: Priorwork on object detection repurposes classifier to perform detection;
• Method: This paper proposed a kind of method that consider object detection as a regression probelm to
spatially separated bounding boxs and associated class probabilities. This is a single neural network predicts
bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection
pipeline is a single network, it can be optimized end-to-end directly on detection performance,it is very quck;
• Result: This architecture can handle real time image by 45 frames per-second, it out-performance better
than other framewok, such as DPM and RCNN.
4.
1.Introduction
• What isthe repurposes classifier method in object detection?
• One-stage method: DPM handle the silding window approach where the classifier is run at evenly spaced location over entire image ;
• Two-stage method: RCNN is a kind of region proposal and classfication network structure, high accuracy &roubstness but inference speed
slow;
• What does currently detector do?
• For example,R-CNN use region proposal method generate potenital boundaries in images,and run classifier at
proposal box, after then post-processing is used to refined the boundingbox,eliminate duplicate detections, and
rescore the box based on other objects in the scene;
• What does YOLO do?
• YOLO reframe object detection as a single regression problem, straight from image pixels to bounding box
coordinates and class probalities, a single convolutional netwrok simultaneously predicts multiple bounding
boxes and class probabilities predicts for those boxes.;
• What’s the YOLO property?
• Firstly: fast;secondly: reasons globally about the image when making predictions; thirdly: learns generalizable
representations of objects.
5.
2.Unified Detection
• Unify:Previousobject detector use silding window and region proposal-based techniques, but YOLO unify the
separate components of object detection into a single neural network;
• Image processing-grid-object: This system divides the input image into S*S grid, center of object decides
responsible for detecting that object;
• Detection:Grid-object confidence: Each grid predicts predict BBox and confidence(confidence of box contains
object) score() about these boxes;
• Bounding box consists of 5 predictions: x,y,w,h and confidence,(x,y)indicates box center,w,h indicates image
width and height;
• Each grid predicts C conditional class probabilities,Predict one set of class probabilities per grid cell,
regardless of the number of boxes B.
• Unify detection predict calculation: ,here this equation indicates: each target category multiplied by the
probability of the current target, and then multiplied the confidence probability of the boundingbox.
6.
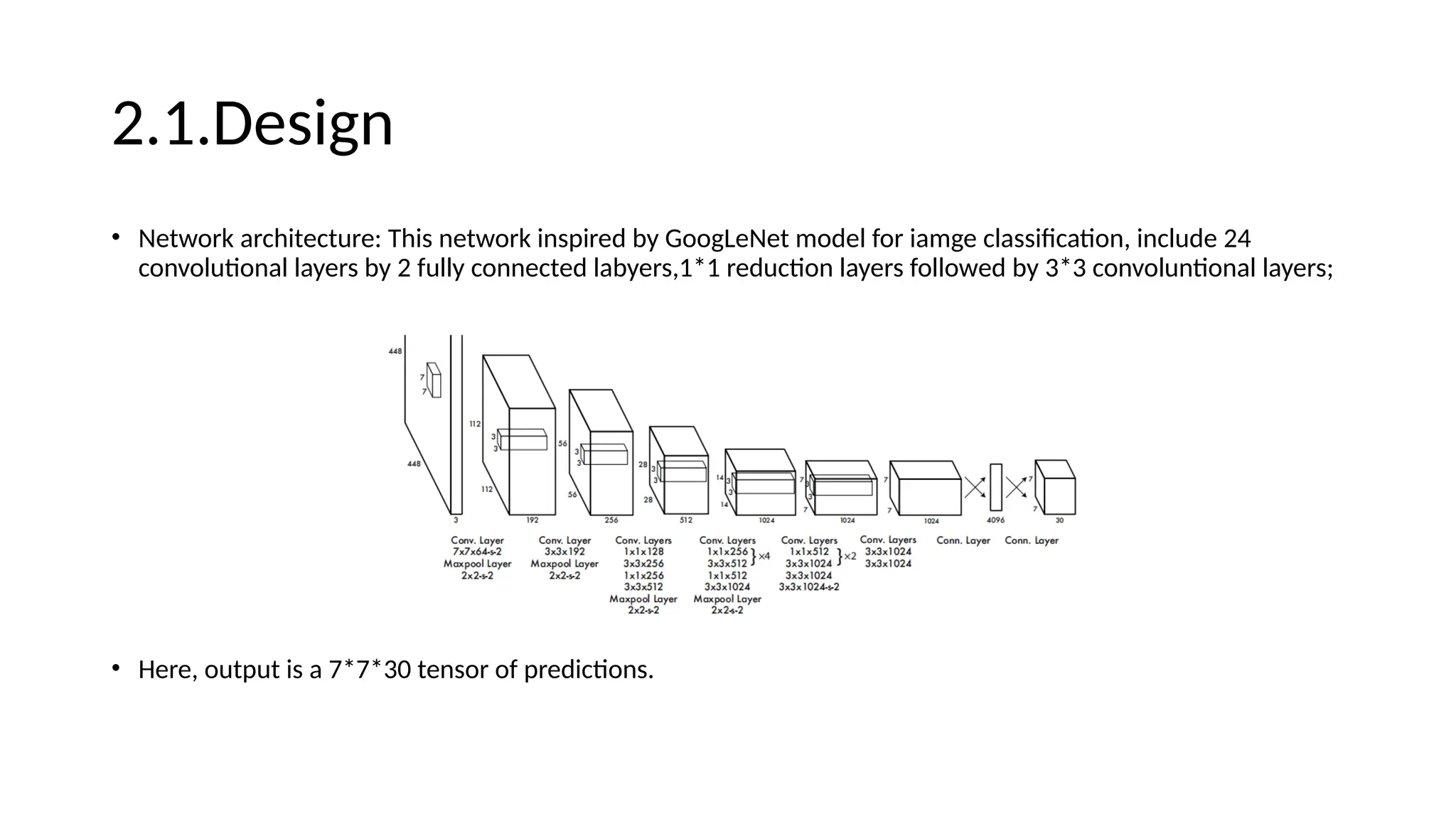
2.1.Design
• Network architecture:This network inspired by GoogLeNet model for iamge classification, include 24
convolutional layers by 2 fully connected labyers,1*1 reduction layers followed by 3*3 convoluntional layers;
• Here, output is a 7*7*30 tensor of predictions.
7.
2.2.Training
• Pretraining: ImageNet1000-class competition dataset was trained on 20 convlutional layers followed by a
average-pooling layer and a fully connected layer about approximately a week and achieve a single crop top-
5 accuracy of 88% on the ImageNet 2012 validation set, comparable to the GoogLeNet models in Caffe
framework;
• Training progress showed that adding both convolutional and connected layers to pretained networks can
improve performance.What’s more this paper add four convoluntional layers and two fully connected layers
with randomly initialized weights.Detection often requires fine-grained visual information so we increase the
input resolution of the network from 224*224 to 448*448;
• Final predicts both class probabilities and bounding box coordinates,and Normalize the bounding box width
and height by the image width and height so that they fall between 0 and 1.This paper parametrize the
bounding box x and coordinates to be offsets of a particular grid cell location os they are also bounded
between 0 and 1.
8.
2.2.1.Training loss
• Thispaper use a linear activation function for the final layer and all other layers use the following leaky
rectified linear activation:;
• This paper optimize for sum-squared error in the output of our model. Use sum-squared error beacuse it is
easy to optimize, however it does not perfectly align with our goal of maximizing average precision;
• Increas the loss from bounding box coordinate predictions and decrease the loss from confidence
predictions for boxes thta don’t contain objects.use two parameters, to accomplish this, and set value as 5;
• Sum.squared error also equally weights errors in large boxes and small boxes.Error metric should reflect that
small deviations in large boxes matter less than in small boxes.
• YOLO predicts multiple bounding boxes per grid cell.At training time only want one bounding box predictor
to be responsible for each object.Assign one predictor to be ‘responsible’ for predicting an object based on
which prediction has the hightest current IOU with the ground truth.This leads to specialization between the
bounding box predictors.Each predictor gets better at prediction certain size,aspect ratios,or classes of
object,improving overall recall.
9.
2.3.Inference
• Just liketraining, predicting detections for a test image only requires one network evaluation.On VOC the
network predicts 98 bounding boxes per image and class probilities for each box.YOLO is extremely fast at
test time since it only requires a single network evaluation, unlike classifier-based methods;
• The grid design enforces spatial diversity in the bounding box predictions.Often it is clasr which grid cell an
object fall in to and the network only predicts one box for each object.However, some large object near the
border of multiple cells can be well localized by multiple cells.Nox-maximal suppression can be used to fix
these multiple detections.While not critical to performance as it is for R-CNN or DPM,non-maximal
suppression adds 2%-3% in mAP;
10.
2.4.Limitation of YOLO
•YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two
boxes and can only have one class, this spatial constraint limits the number of nearby objects model can
predict.This model struggles with small objects that appear in groups, such as flocks of birds;
• This model learns to predict bounding boxes from data, it struggles to generalize to objects in new or unusal
aspect ratios or predicting bounding boxes since our architectures has multiple downsampling layers from
the input image;
• Finally, while train on a loss function thta approximates detection performance, loss function treats errors
the same in small bounding boxes versus large bounding boxes. A small error in a large box is generally
benign but a small error in a small box has a much greater effect on IOU;
11.
3.Comparison to OtherDetection Systems
• Object detection is a core problem in computer vision.Detection pipelines generally start by extracting a set
of robust features from input image,then classifiers or localizers are used to identify object in the feature
space.These classifiers or localizers are run either in sliding window fashion over the whole image or on
some subset of regions in the image,compare the YOLO detection system to several top detection
frameworks,highlighting key similarities














![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)













































