Download to read offline





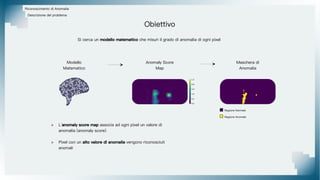
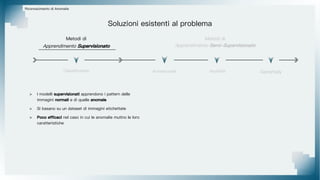
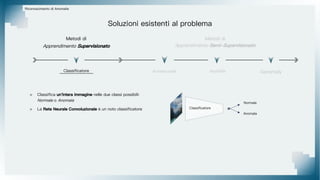
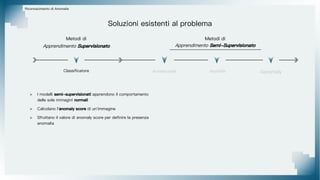
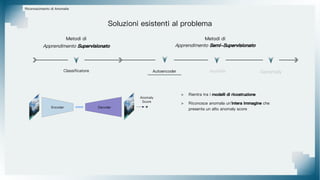
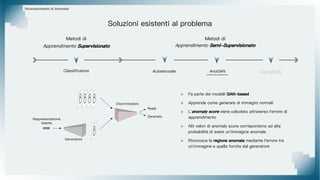
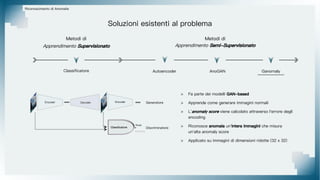








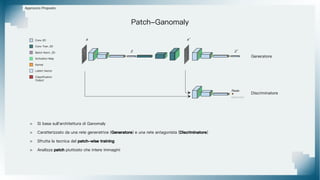

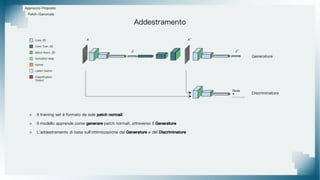
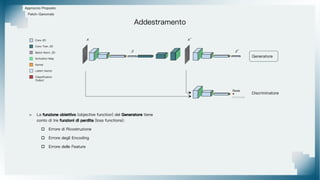
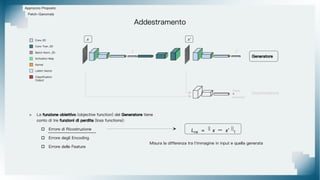
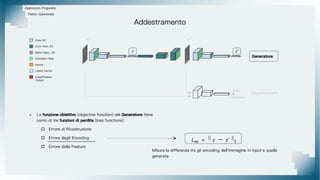
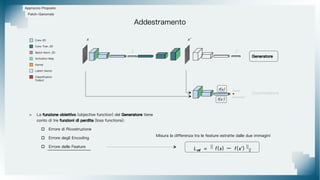
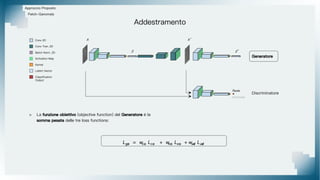
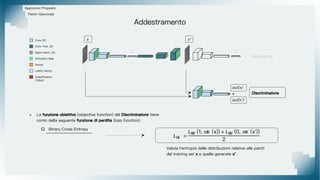








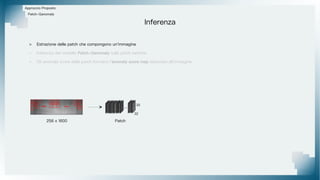

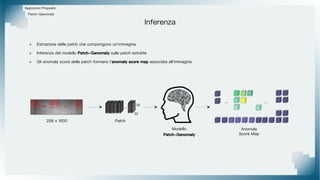
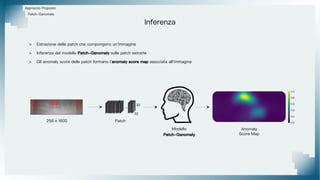


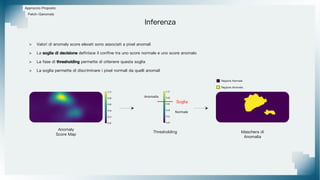


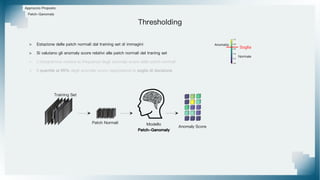
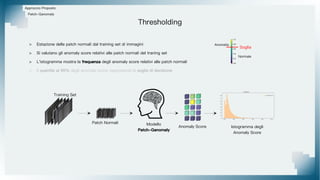
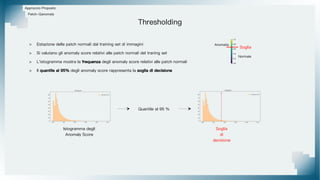
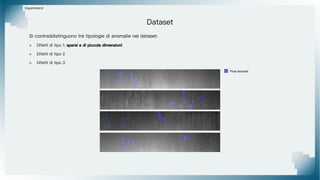
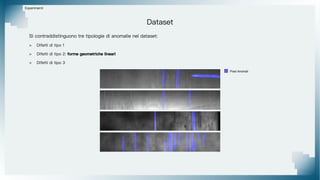
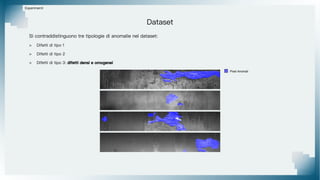



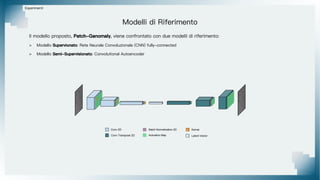
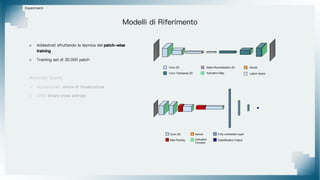




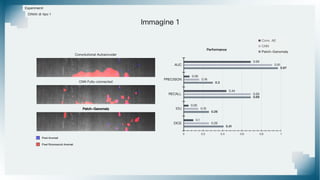
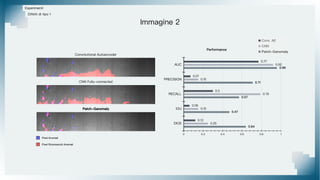

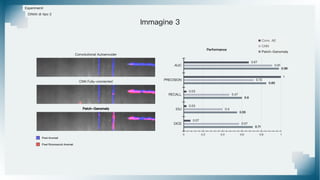
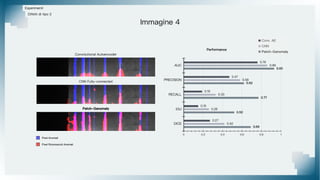

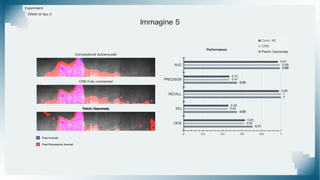
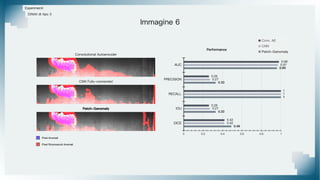

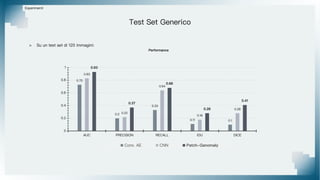





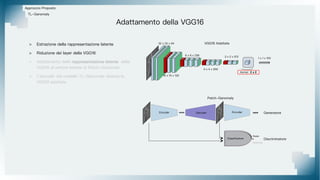
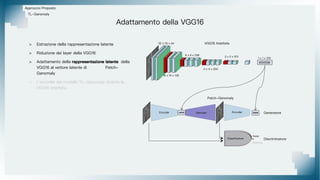
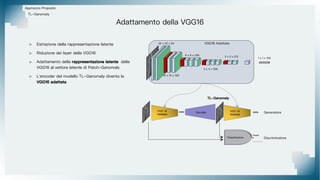
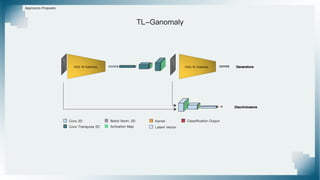


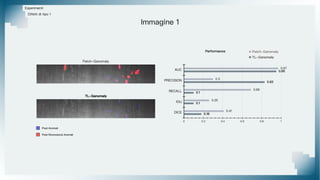
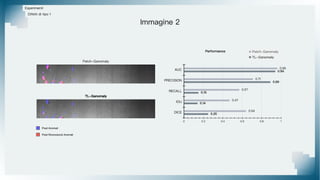

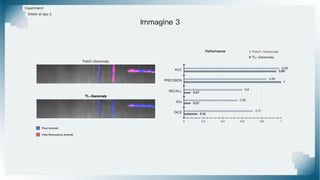
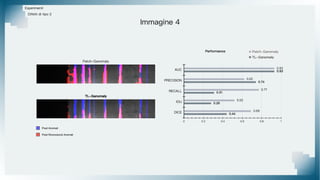

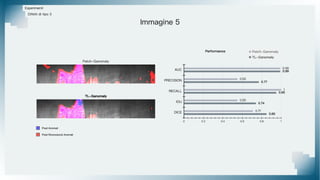
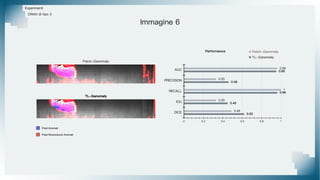

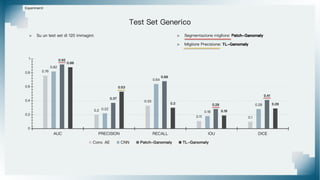
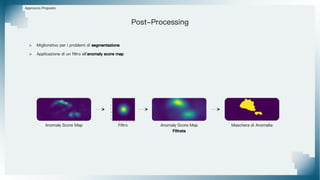

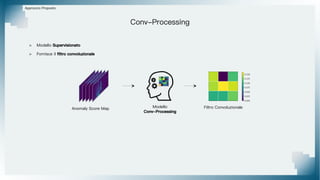

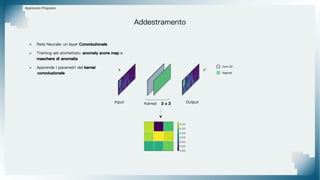
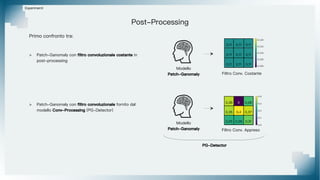
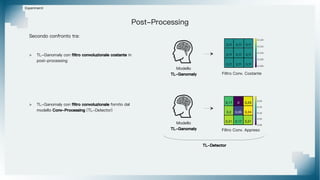


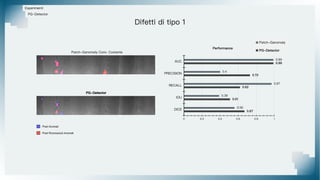
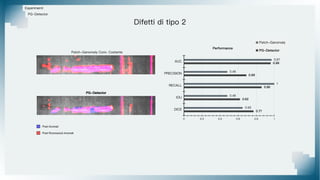
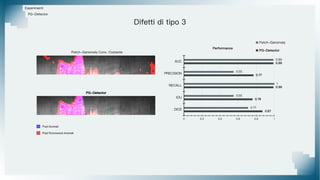
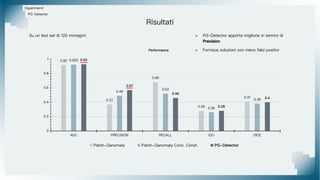

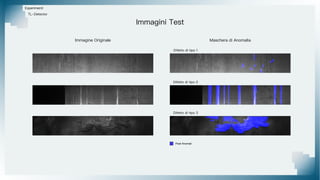
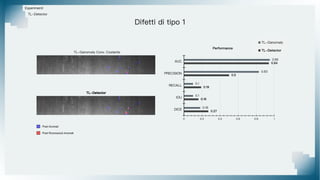
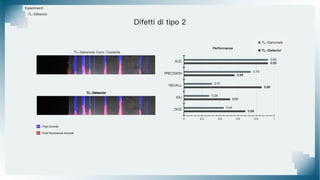
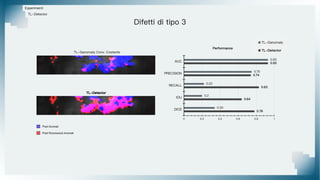
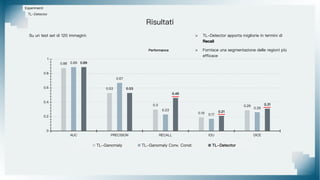

Il documento tratta il riconoscimento di anomalie nelle immagini di lastre di acciaio utilizzando un approccio basato su GAN, specificamente attraverso il metodo patch-wise training. Questo approccio prevede la suddivisione delle immagini in patch per migliorare l'addestramento e l'accuratezza del modello nel riconoscimento delle anomalie. Inoltre, viene illustrato il processo di definizione dell'anomaly score e della soglia decisionale per identificare le aree anomale nelle immagini.



























