Downloaded 49 times


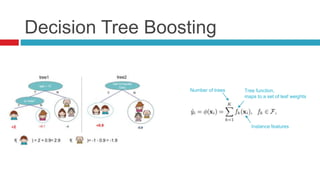
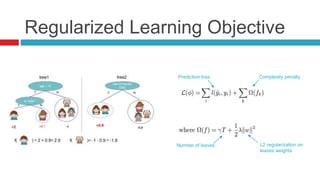
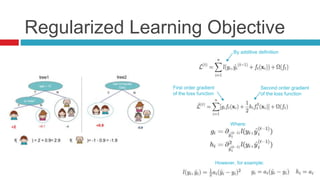
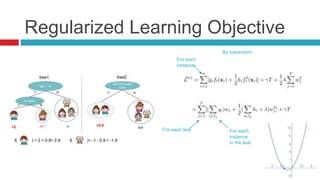
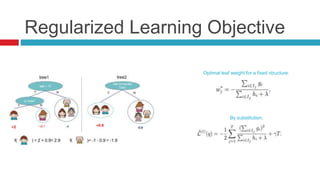
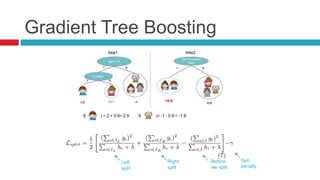


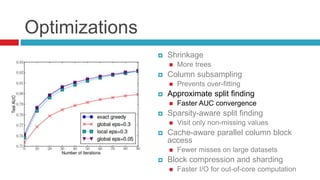
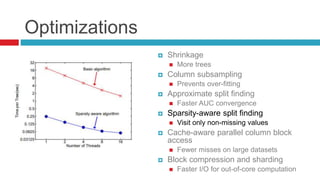
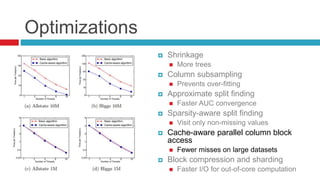
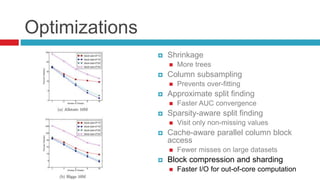
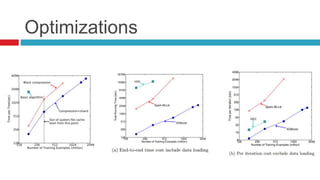


XGBoost is a widely-used scalable tree boosting system that excels in classification, regression, and learning-to-rank tasks, often outperforming competitors. It employs decision tree boosting with optimizations like column subsampling and approximate split finding to enhance performance and reduce overfitting. Further resources and tutorials are available to aid in understanding and implementation.






























![XGBOOST [Autosaved]12.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/xgboostautosaved12-230501140101-a562c3ba-thumbnail.jpg?width=640&height=640&fit=bounds)














































