Downloaded 78 times





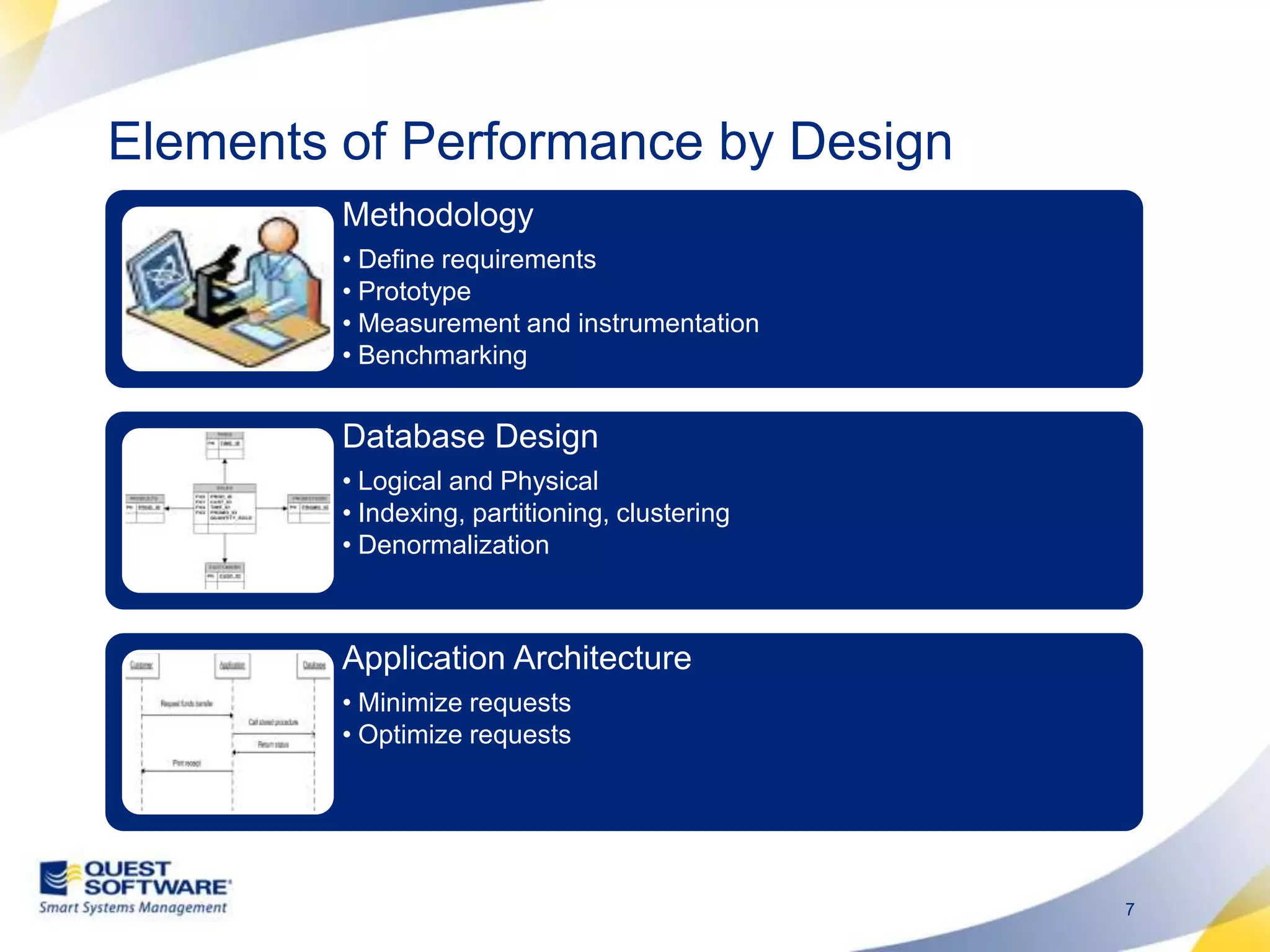








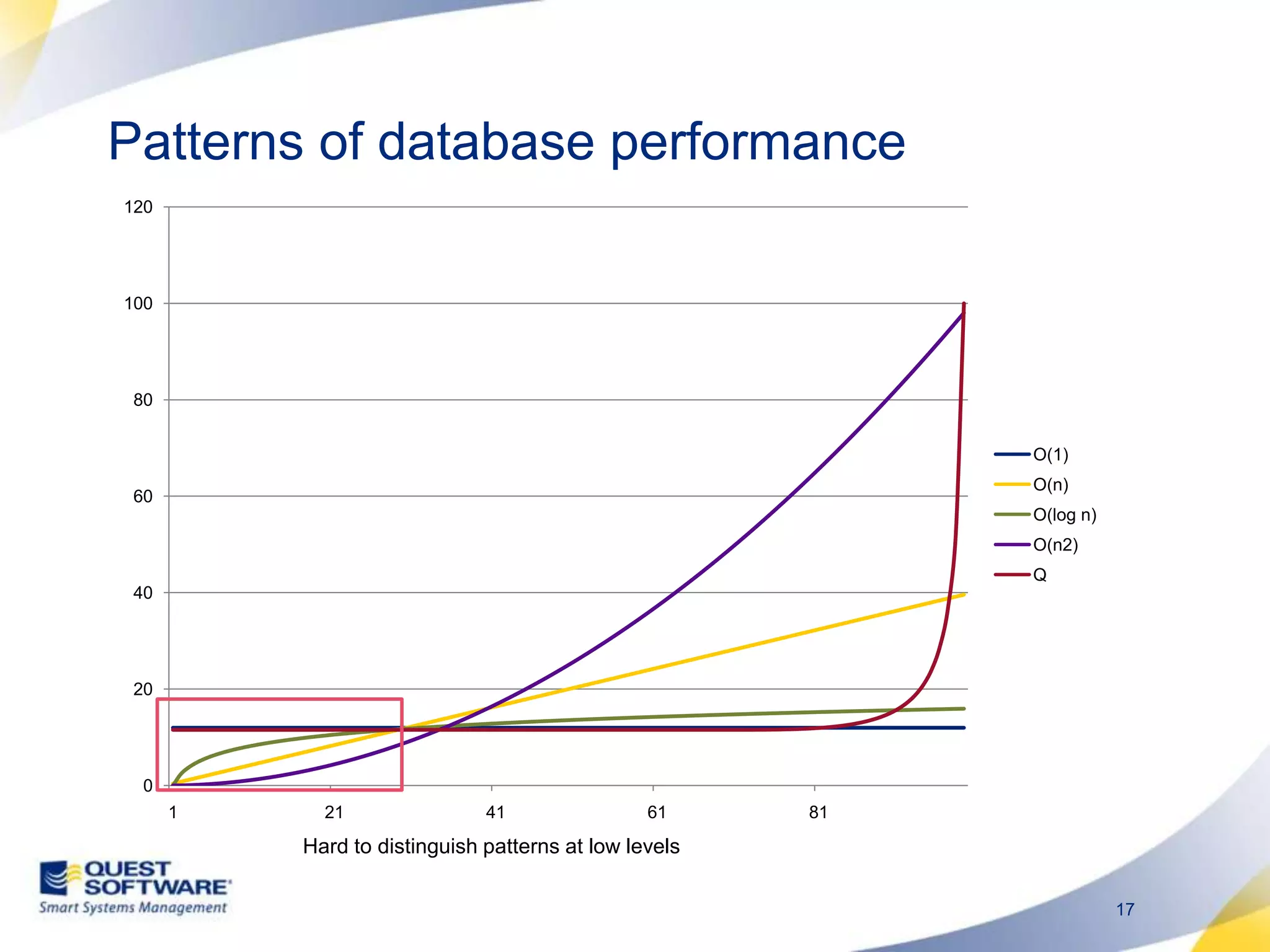
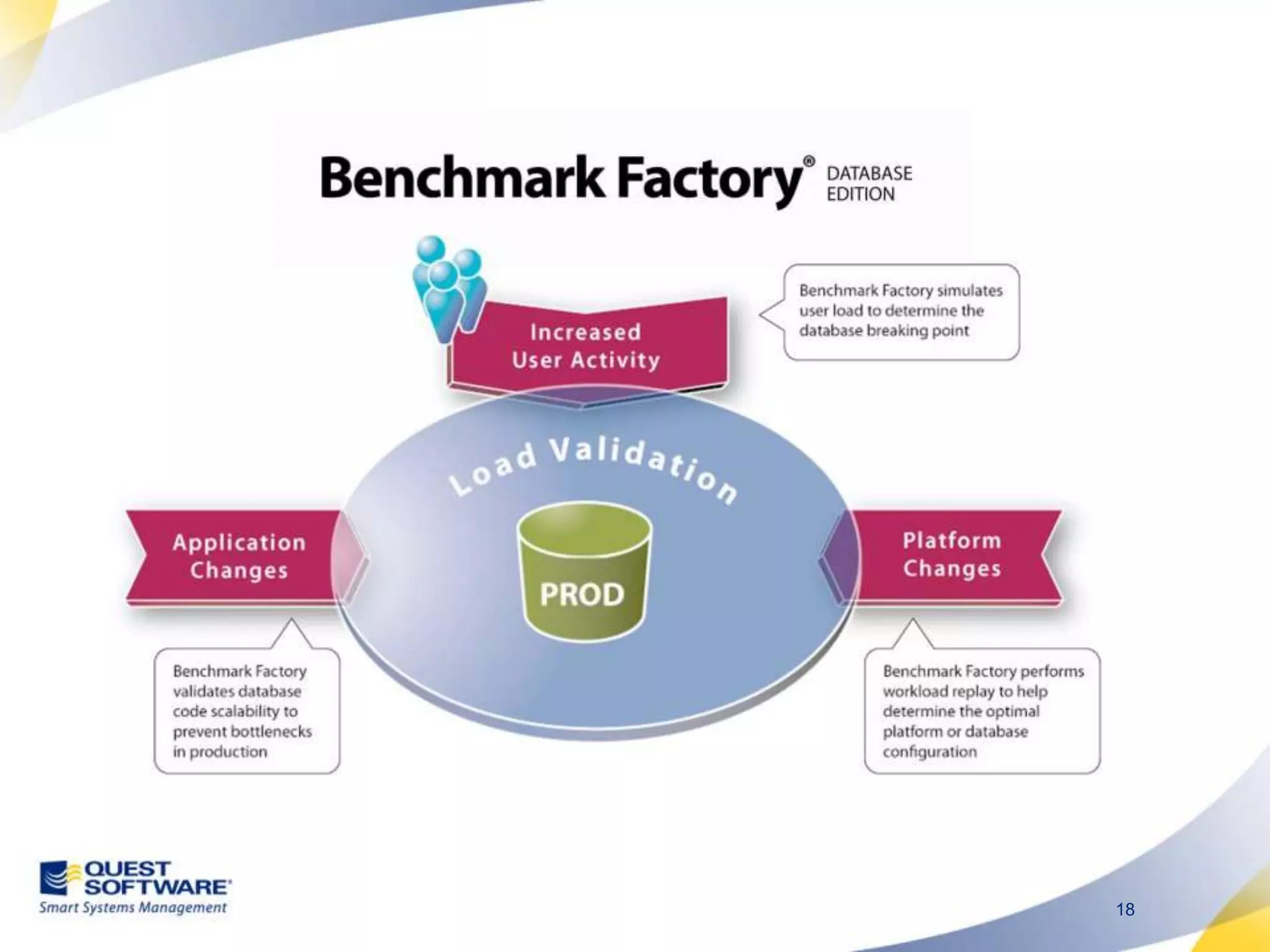

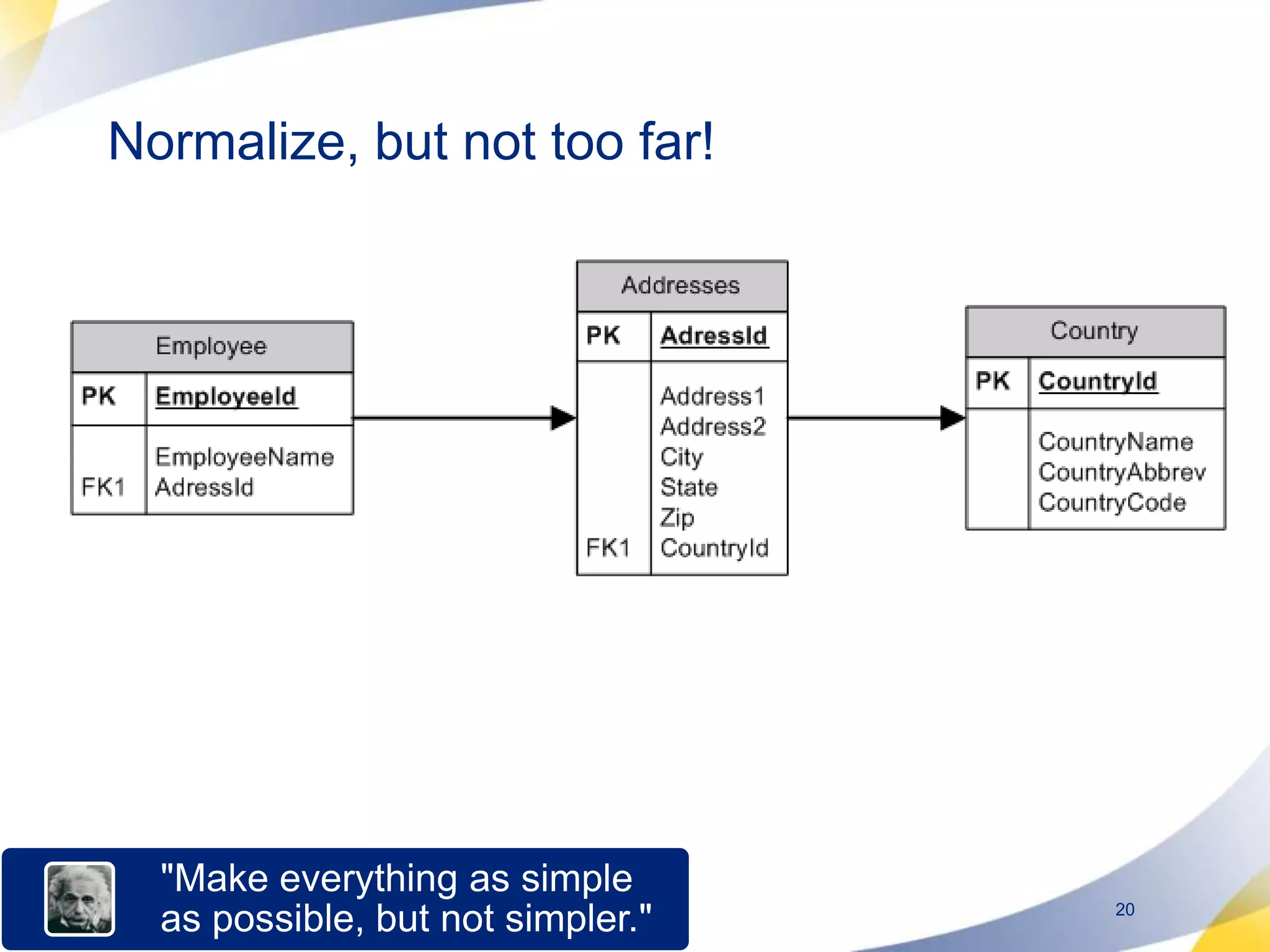



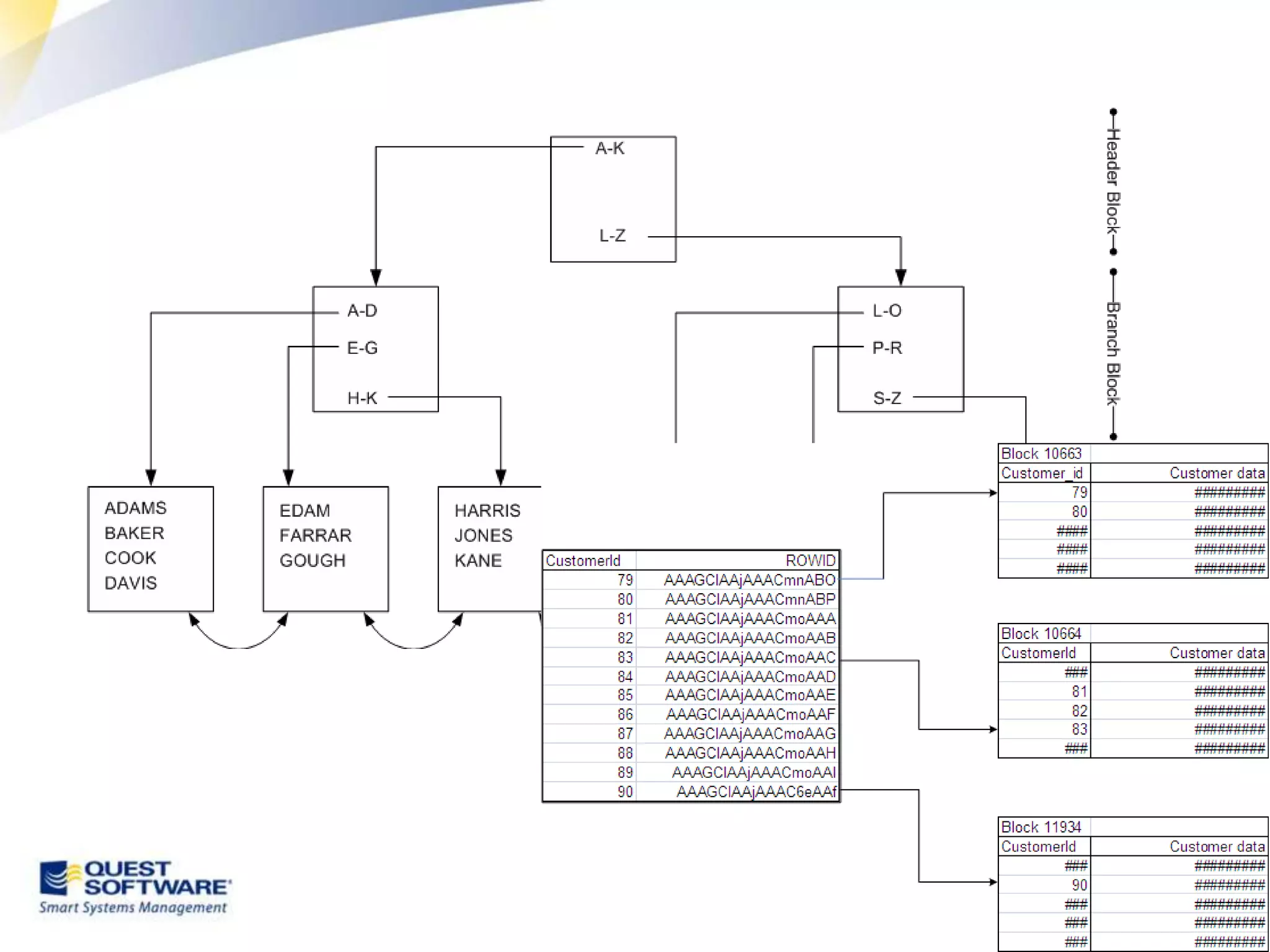
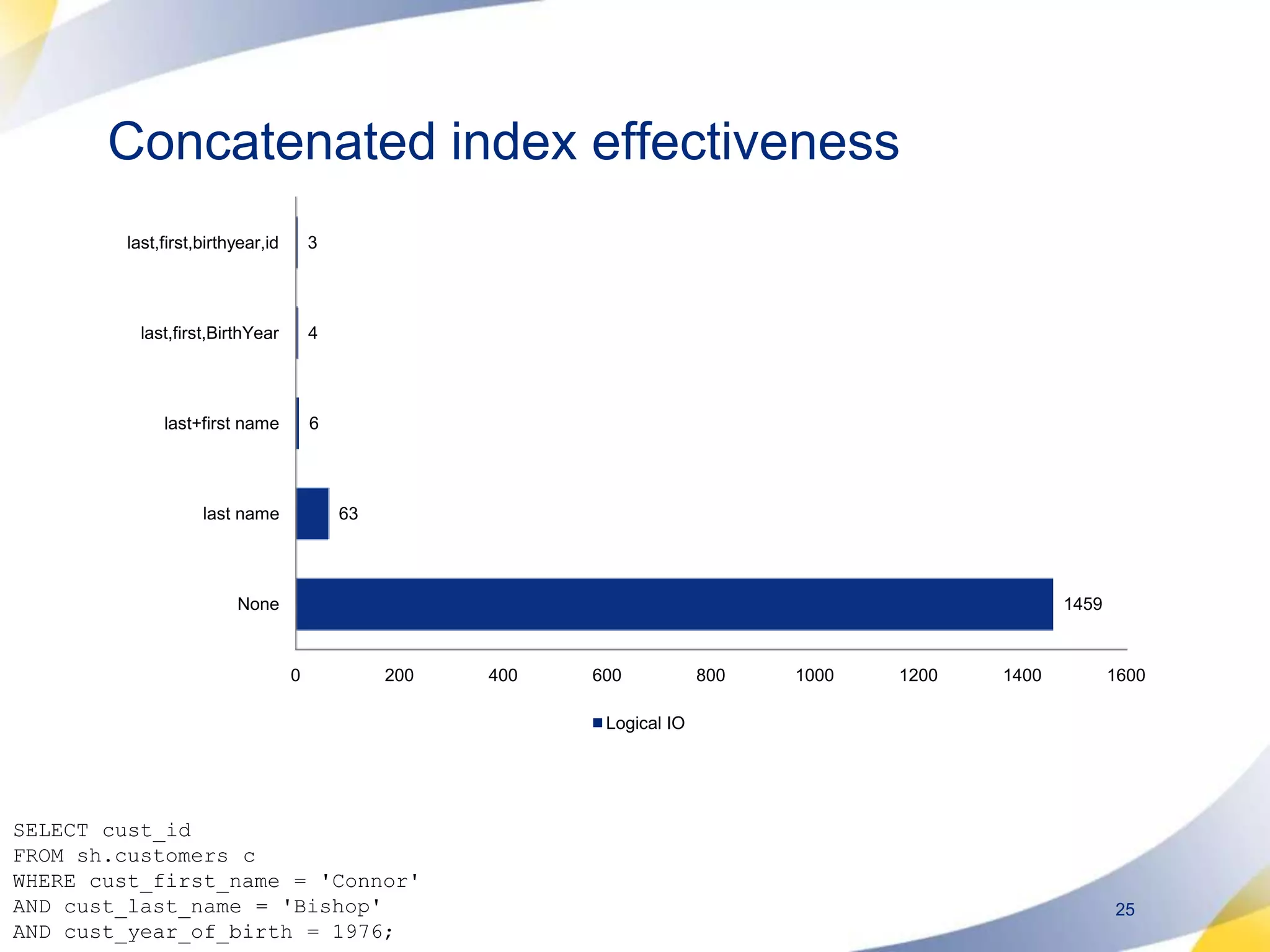

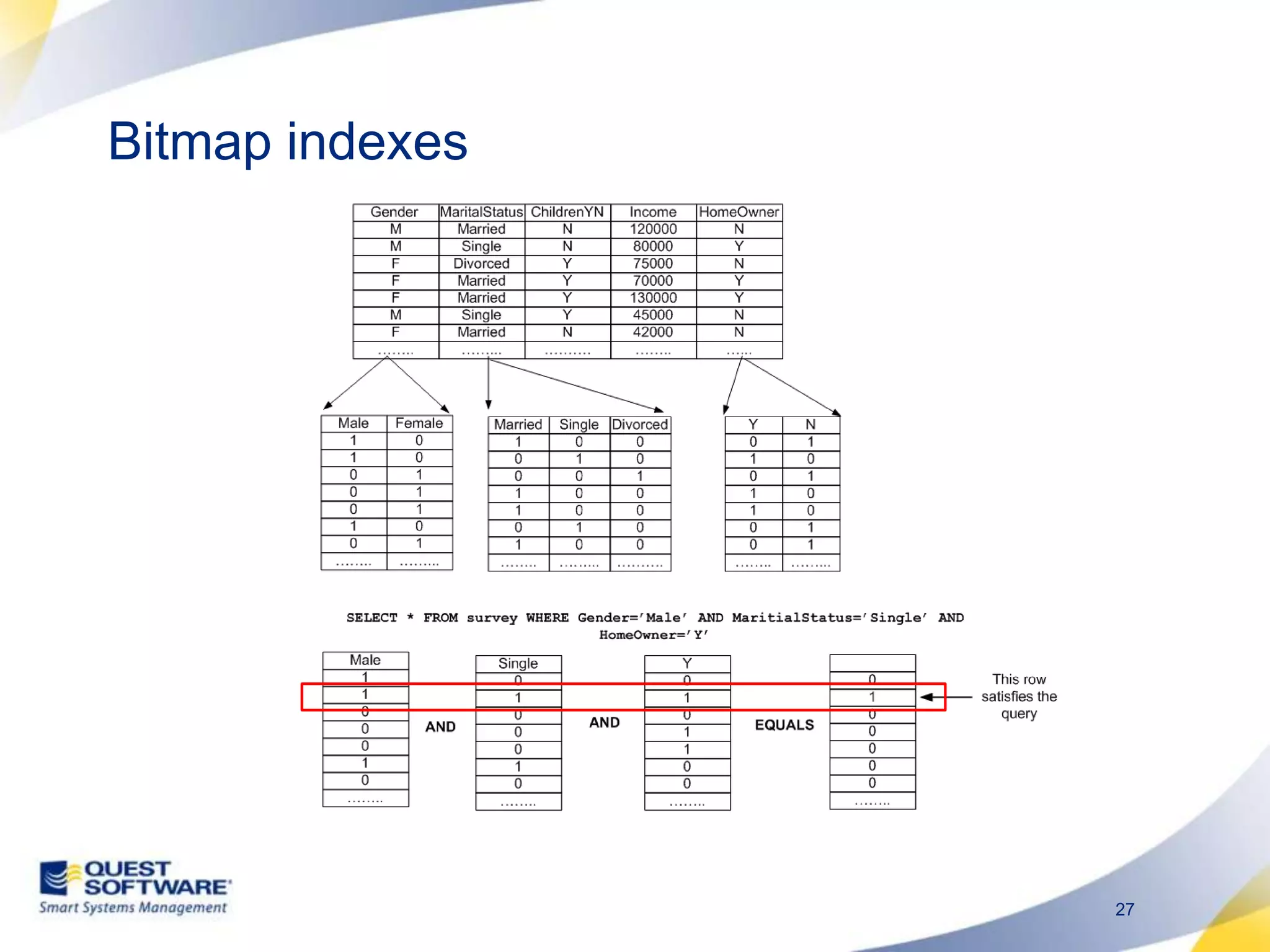
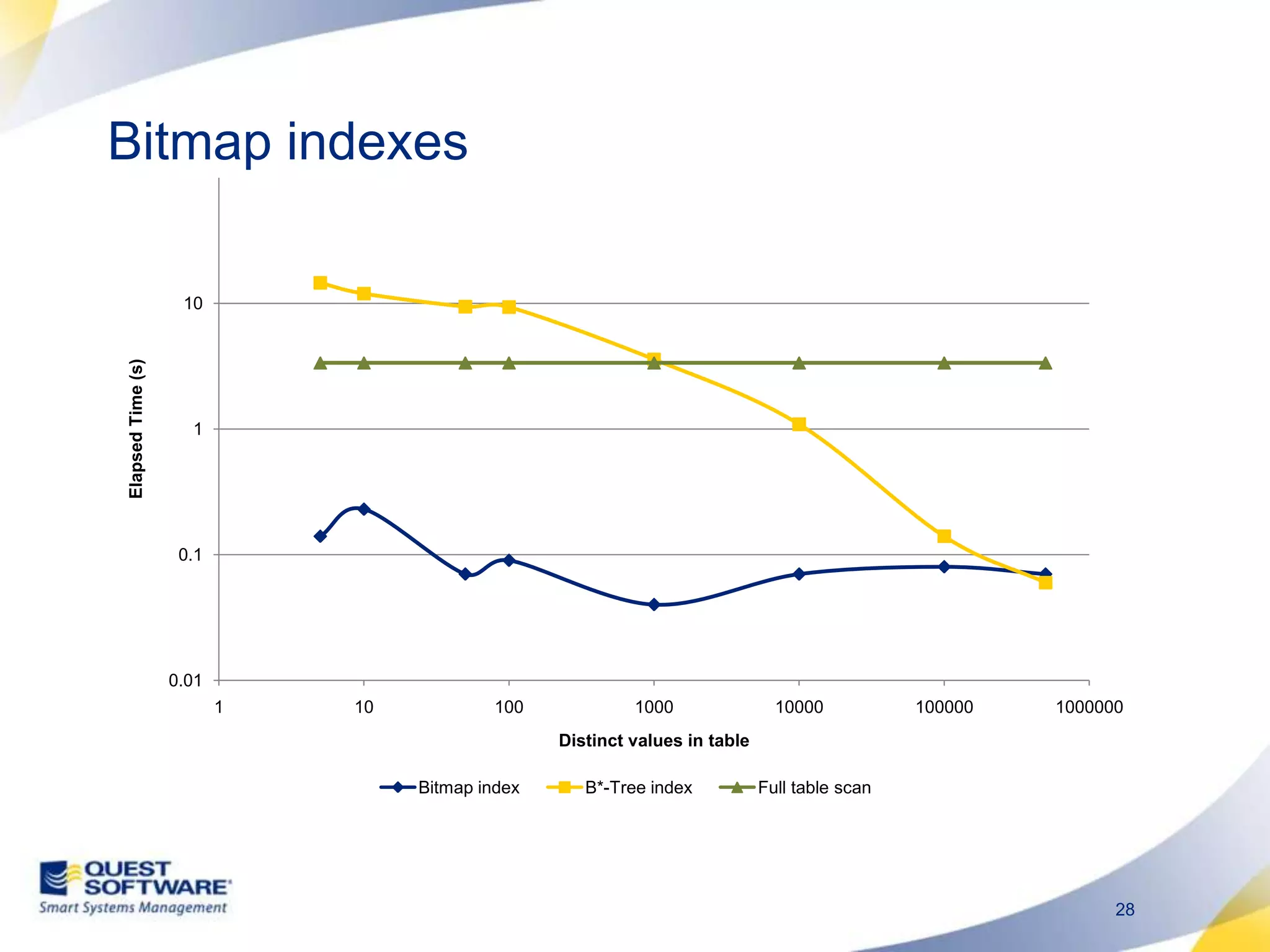
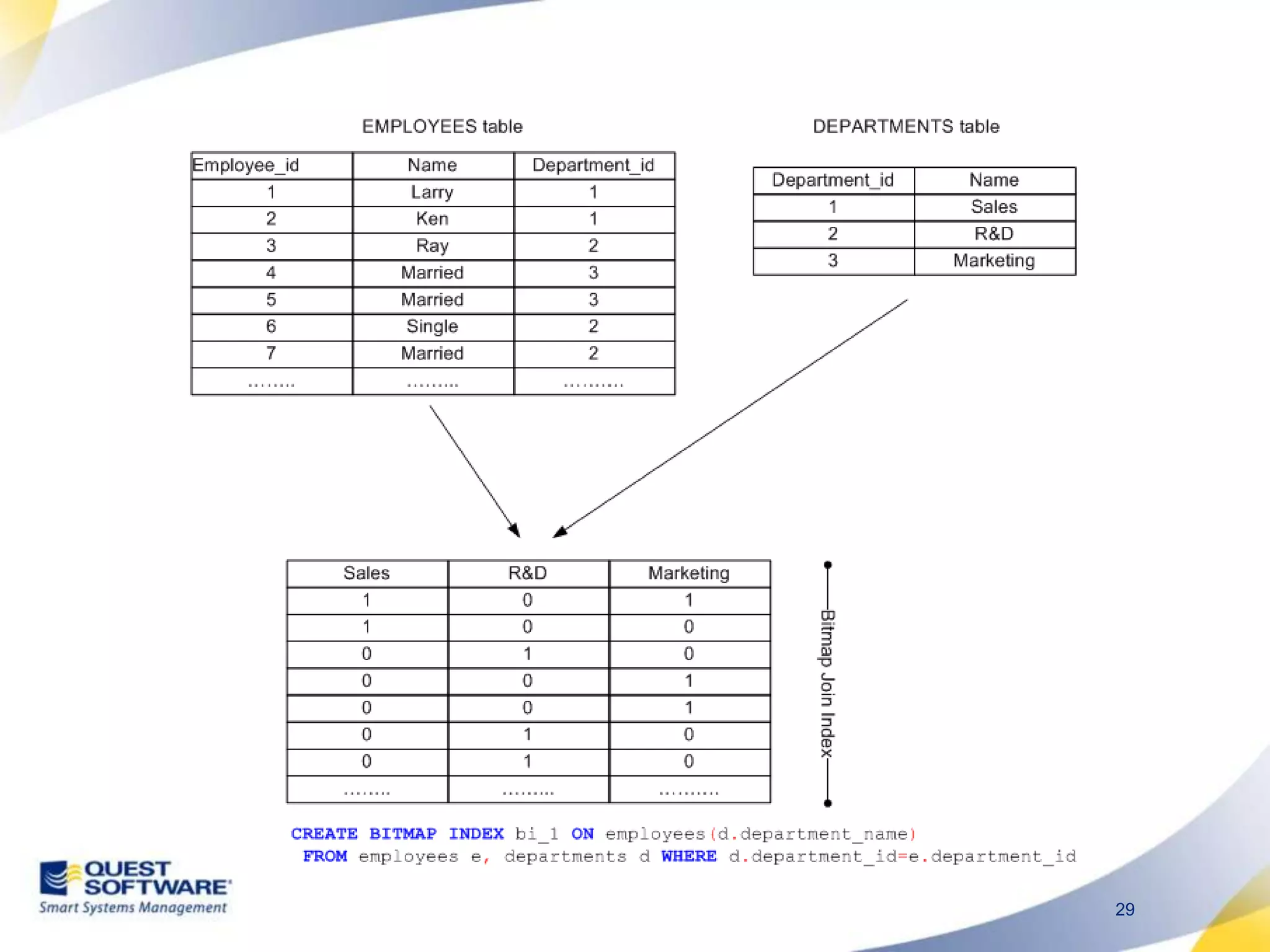
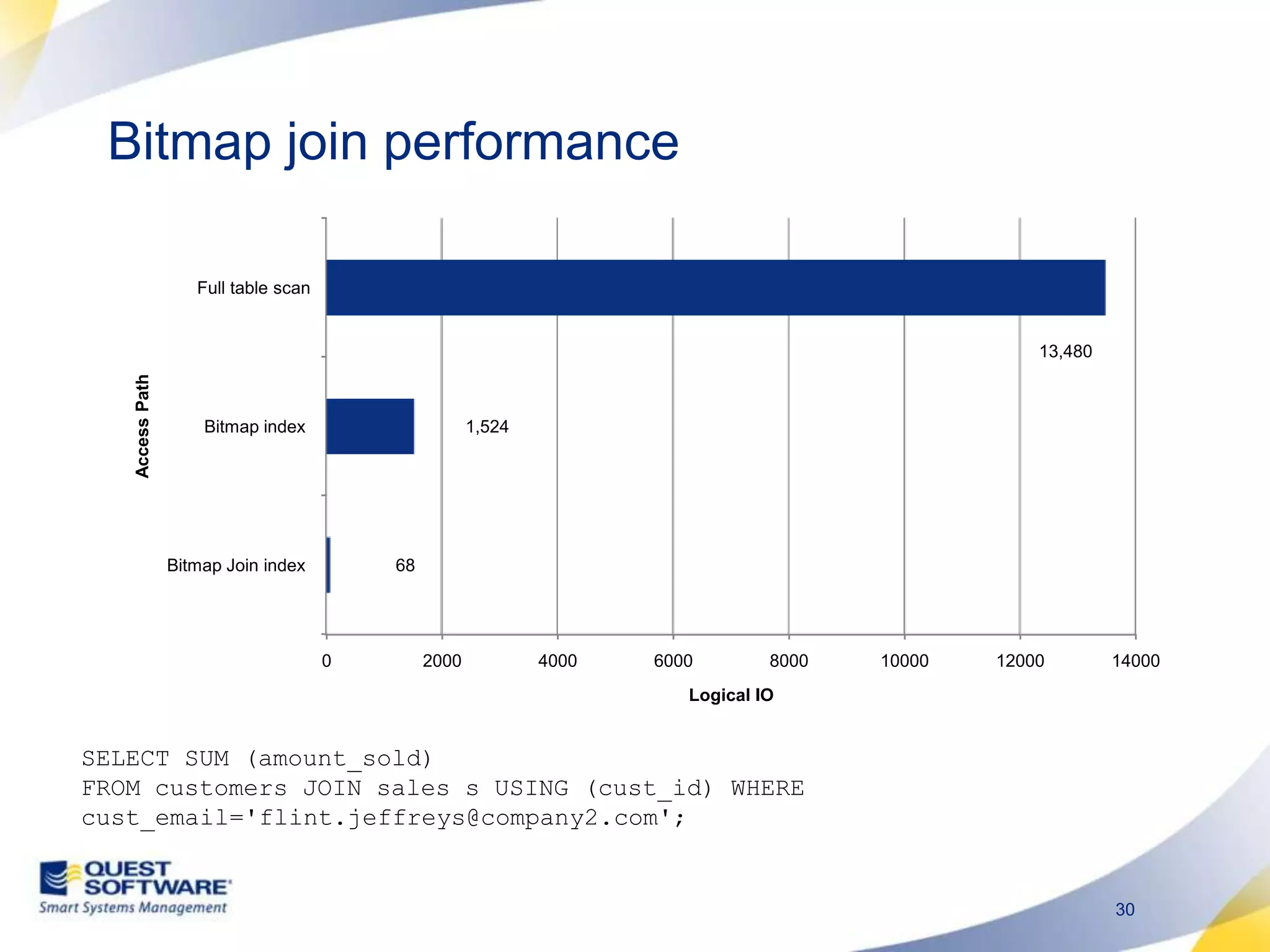
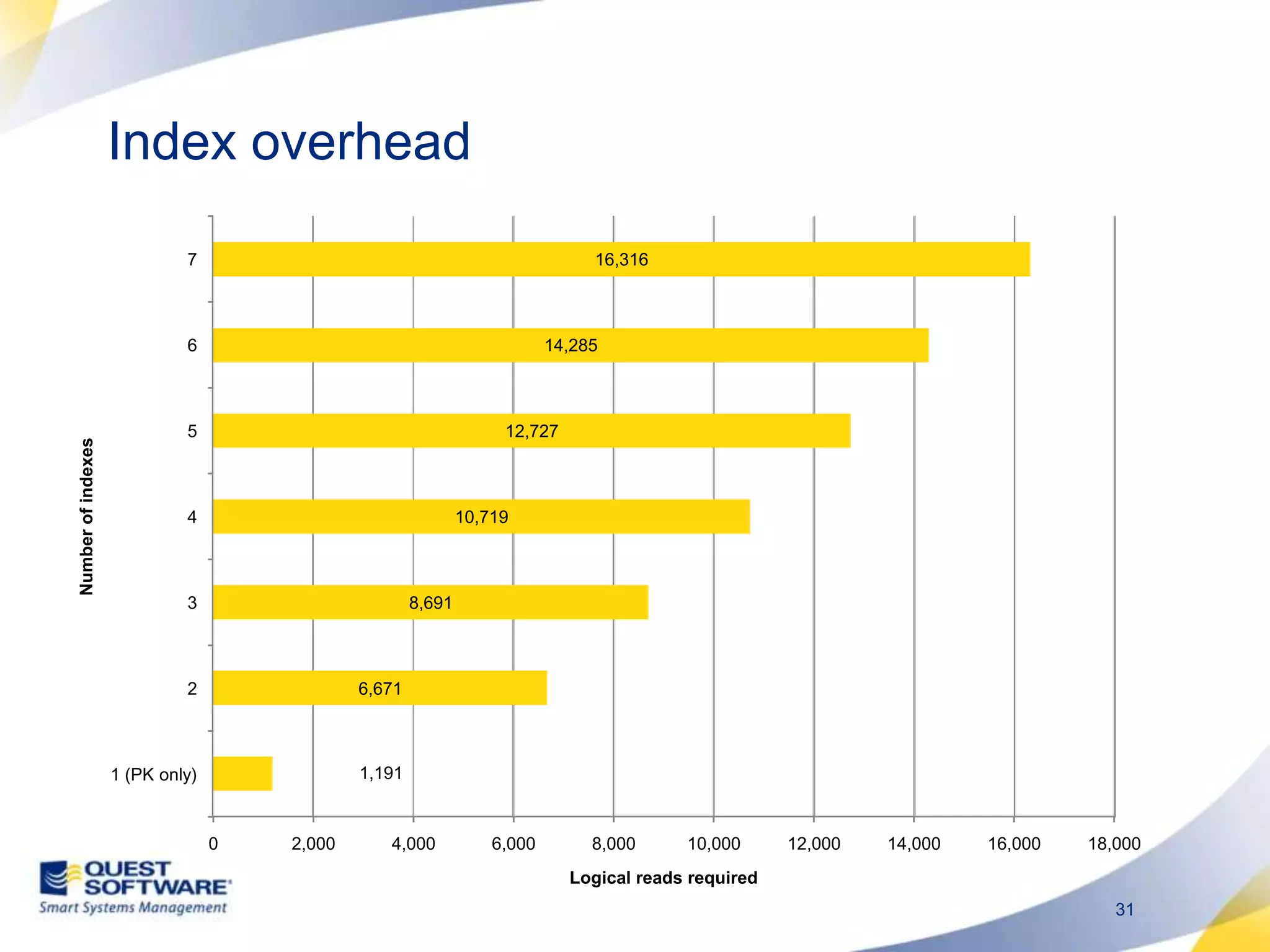
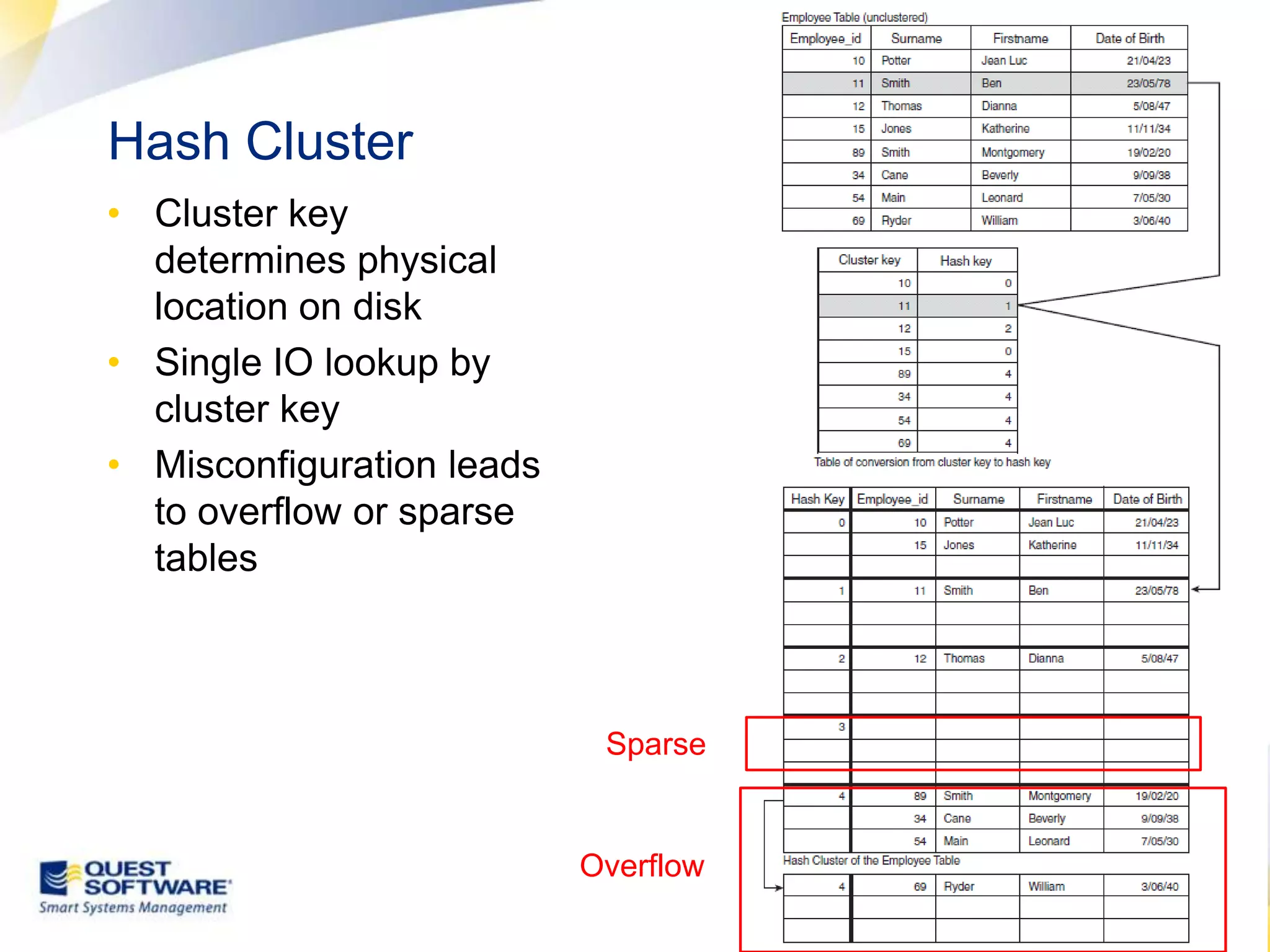
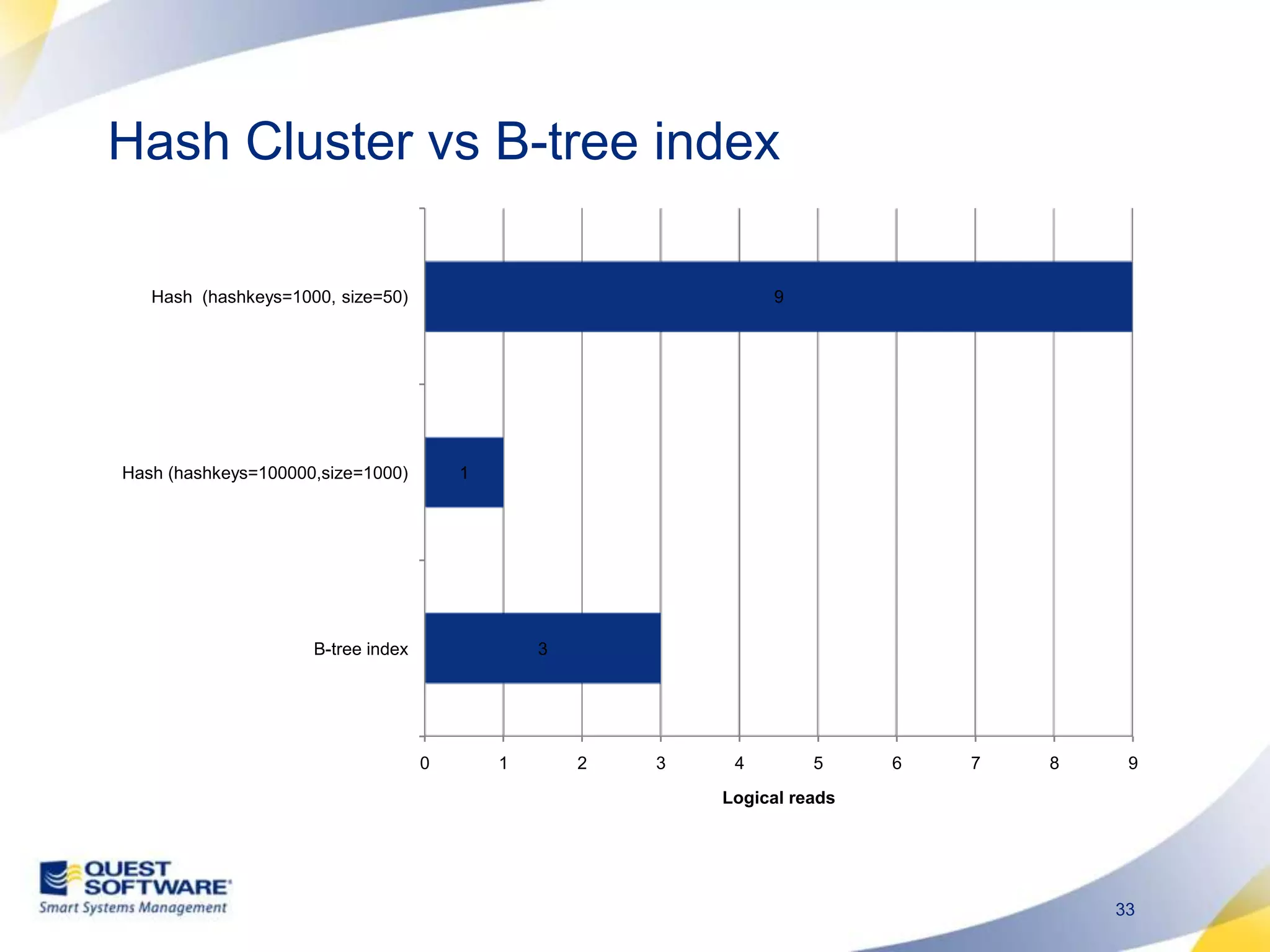
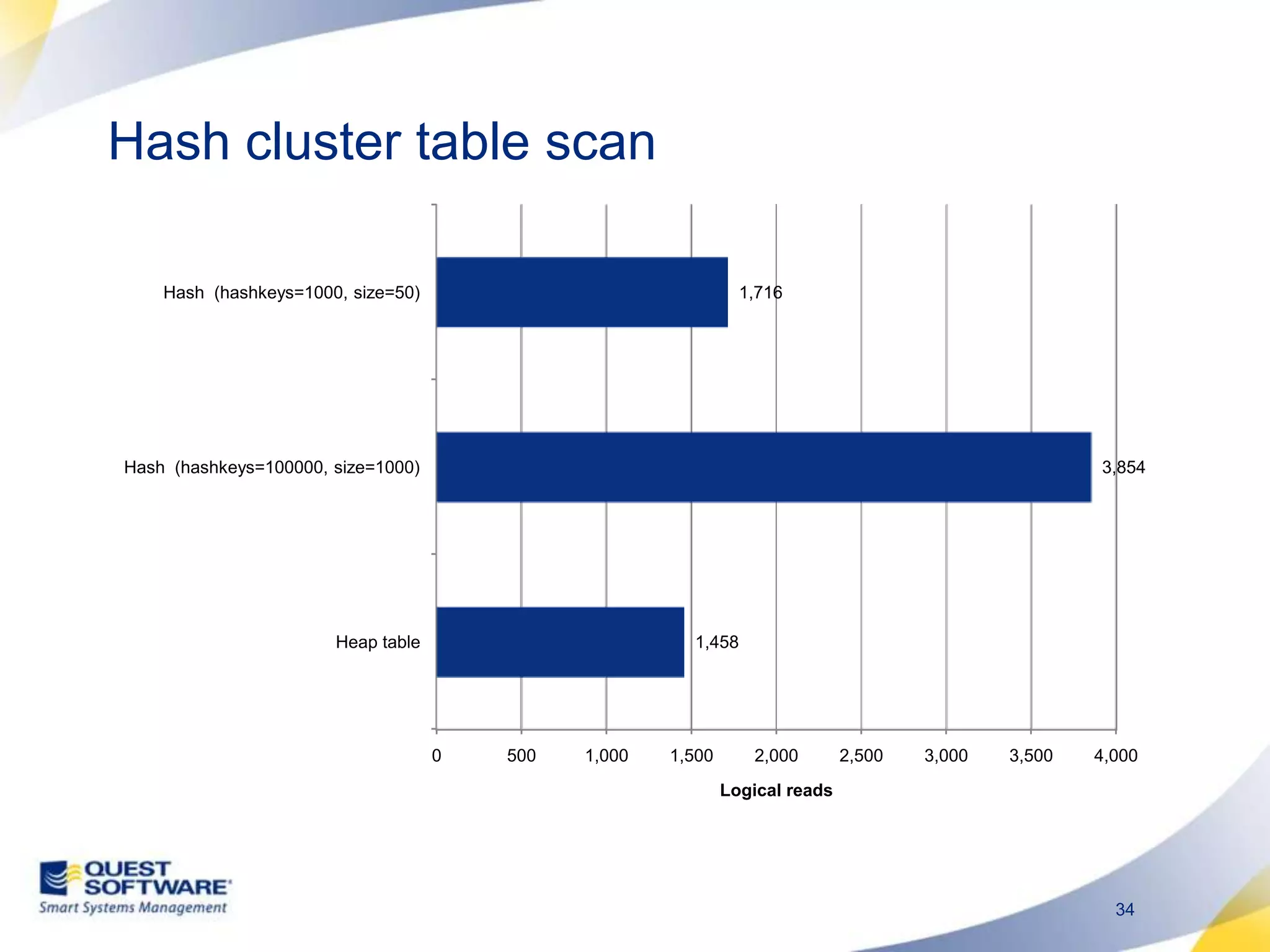

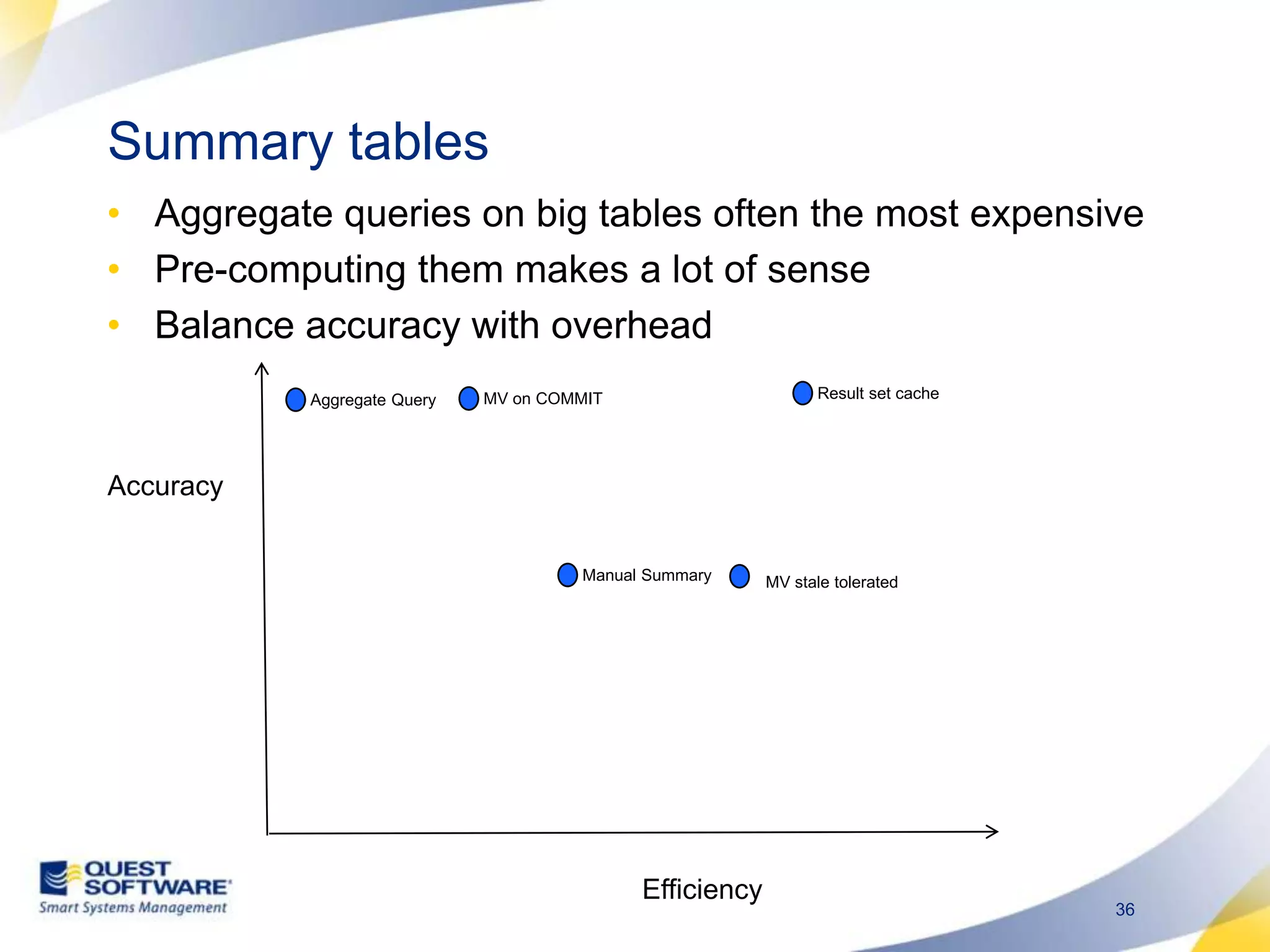


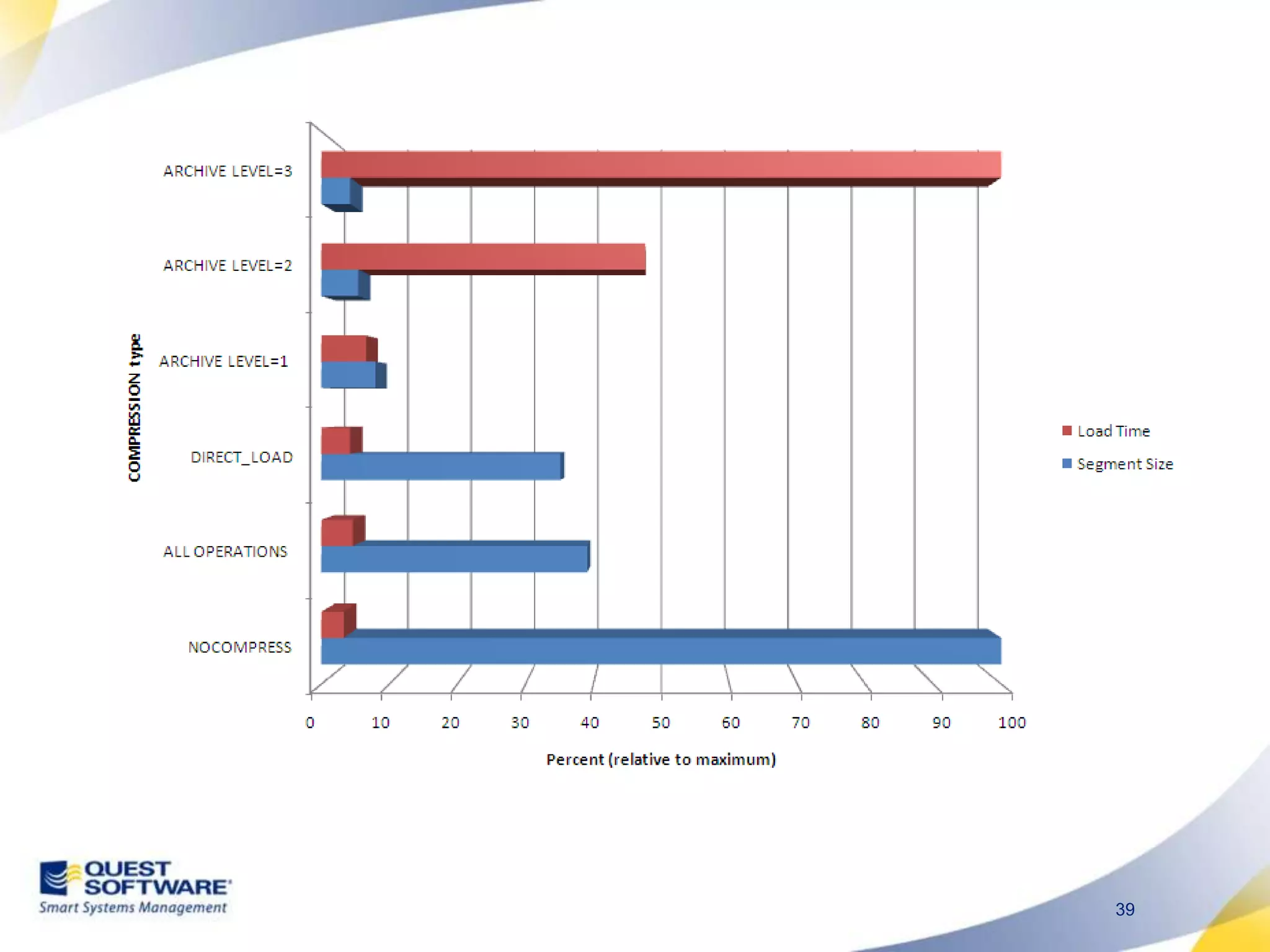





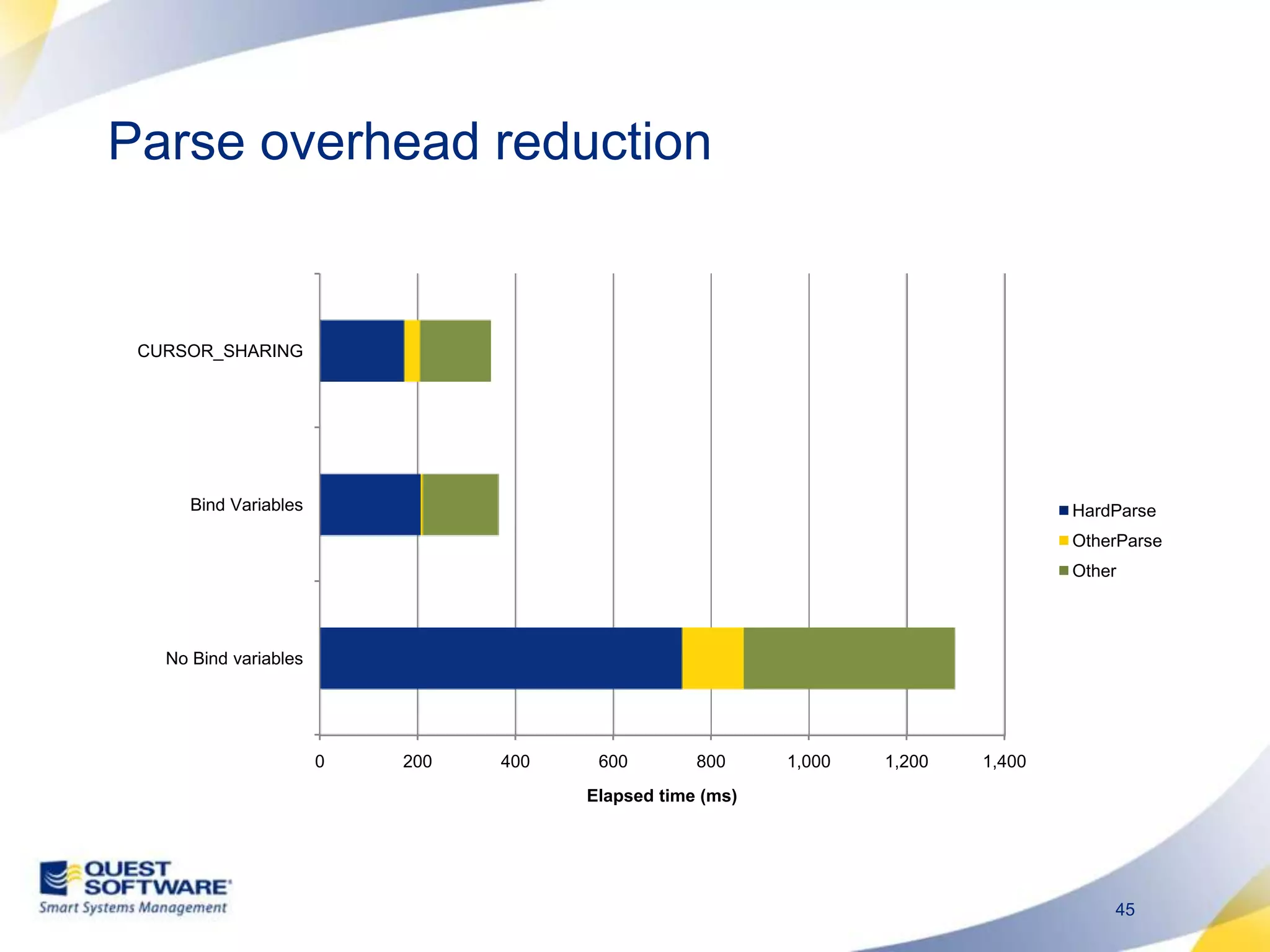
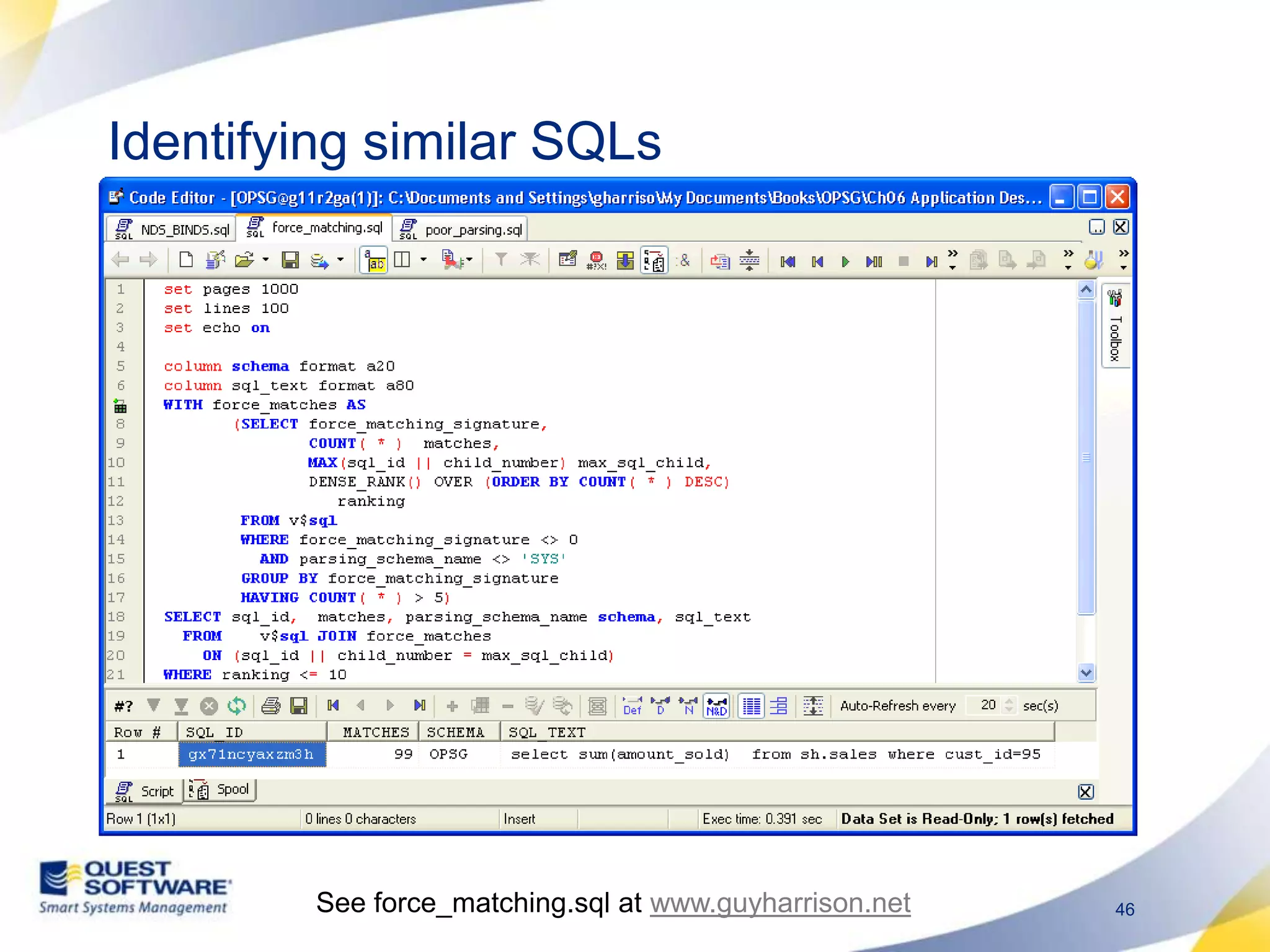
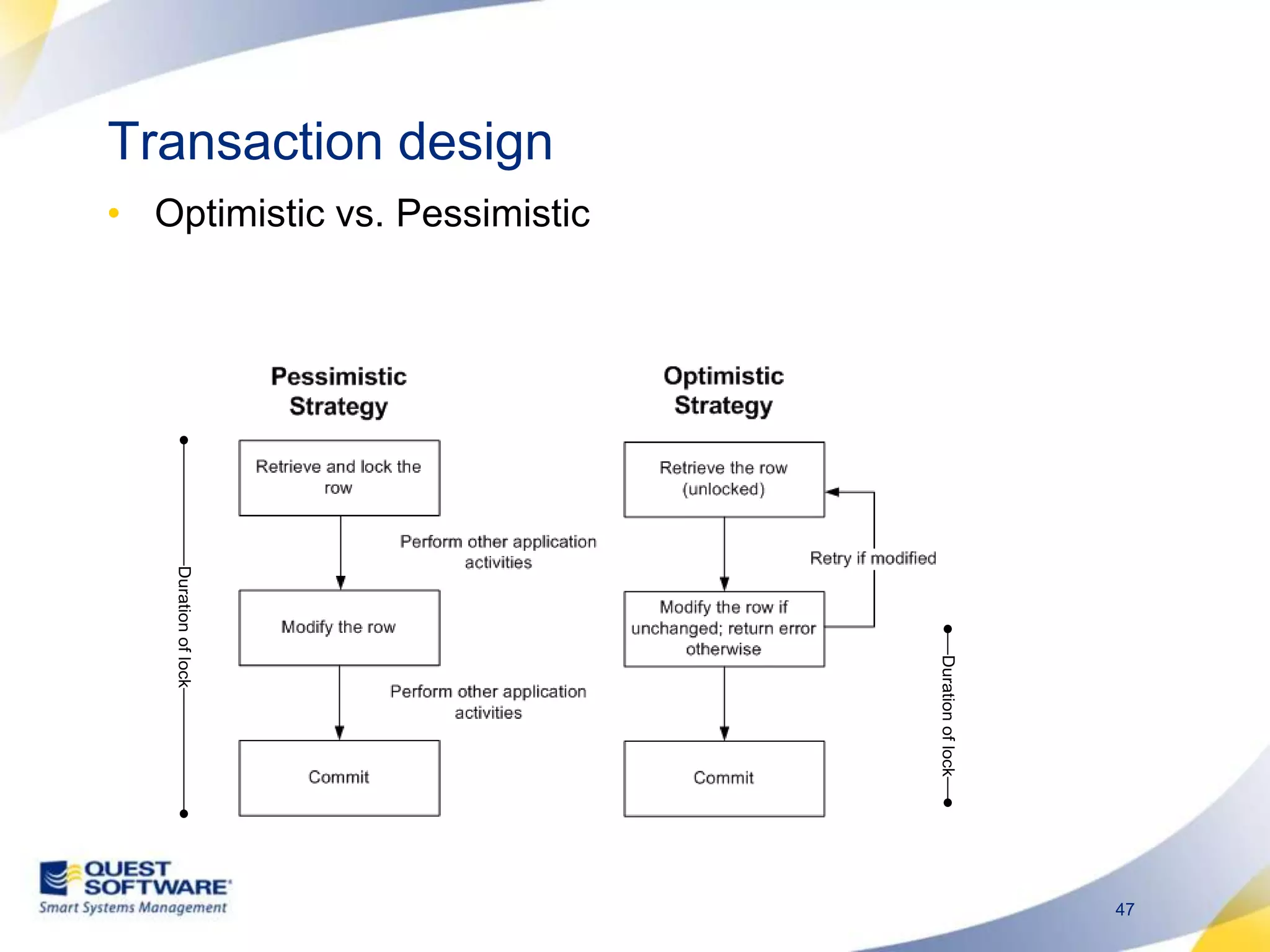

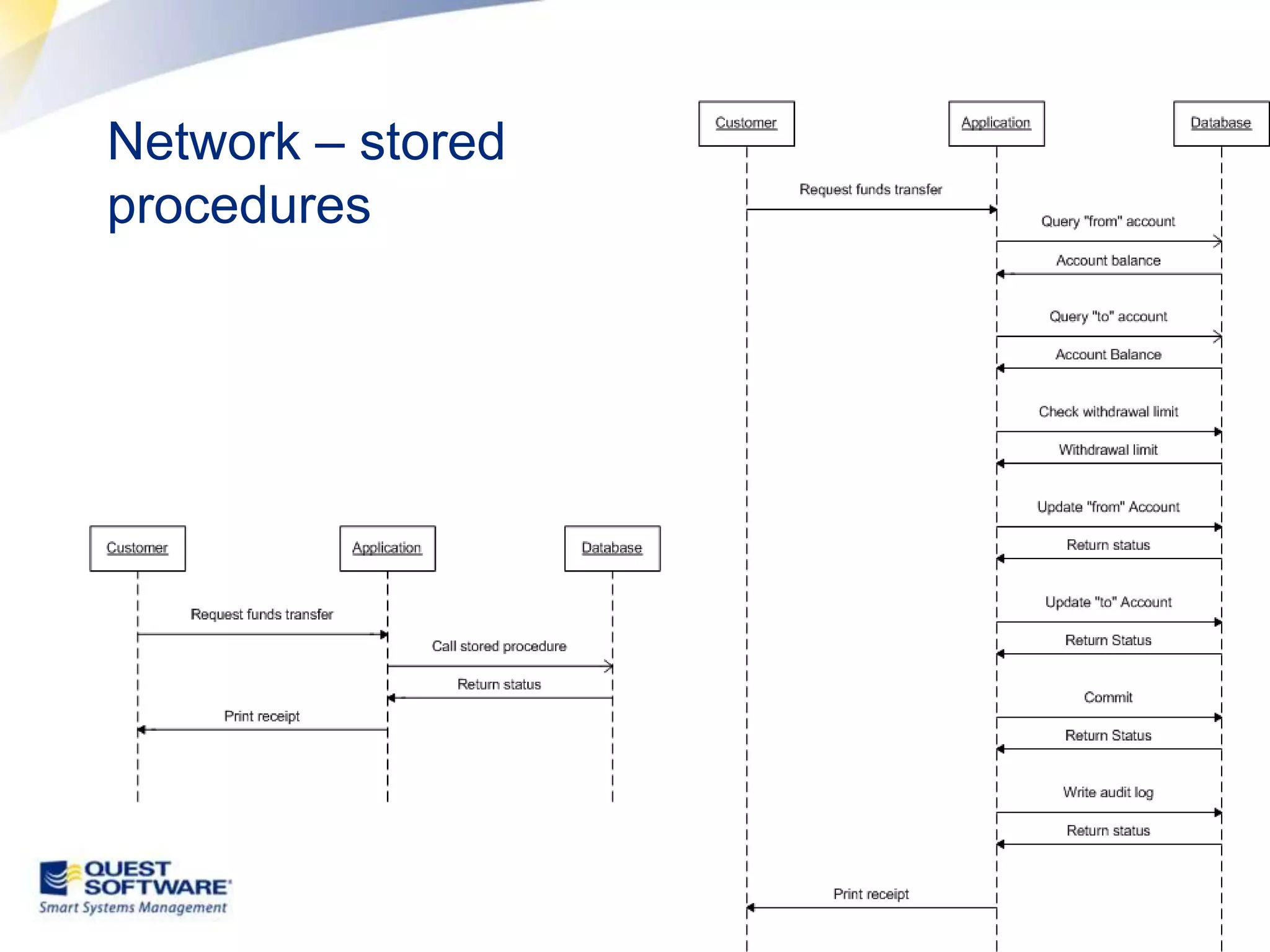
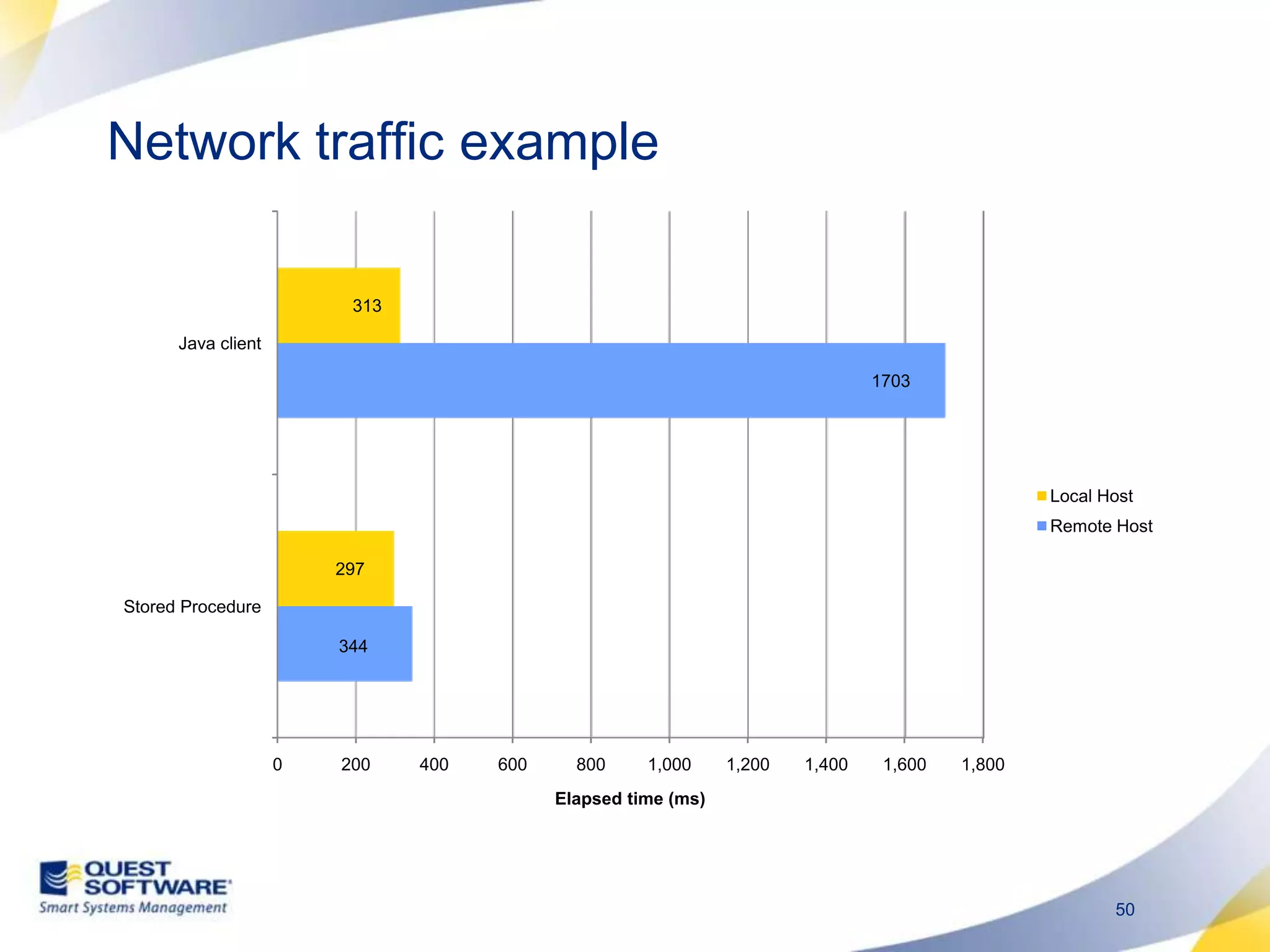
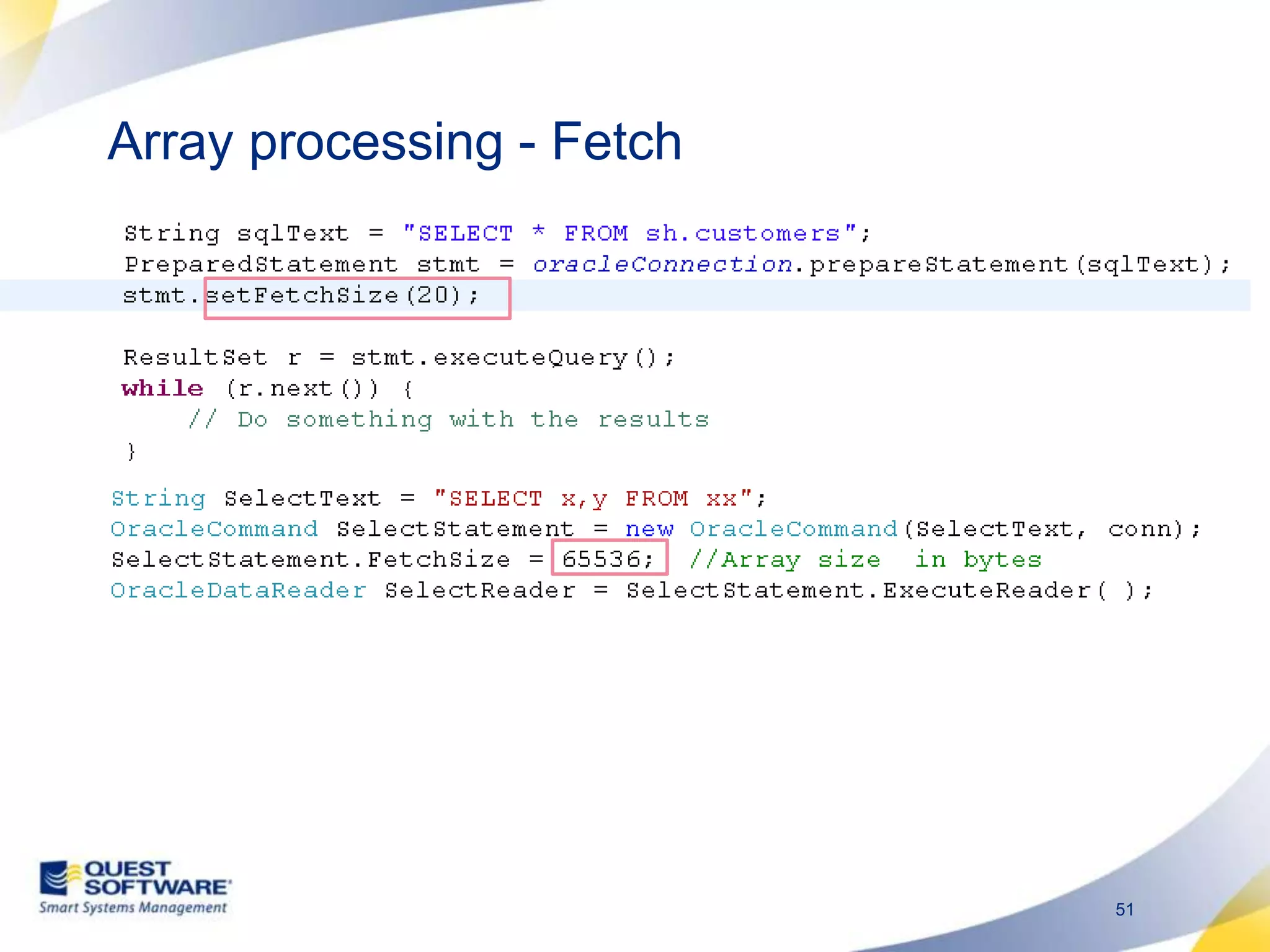
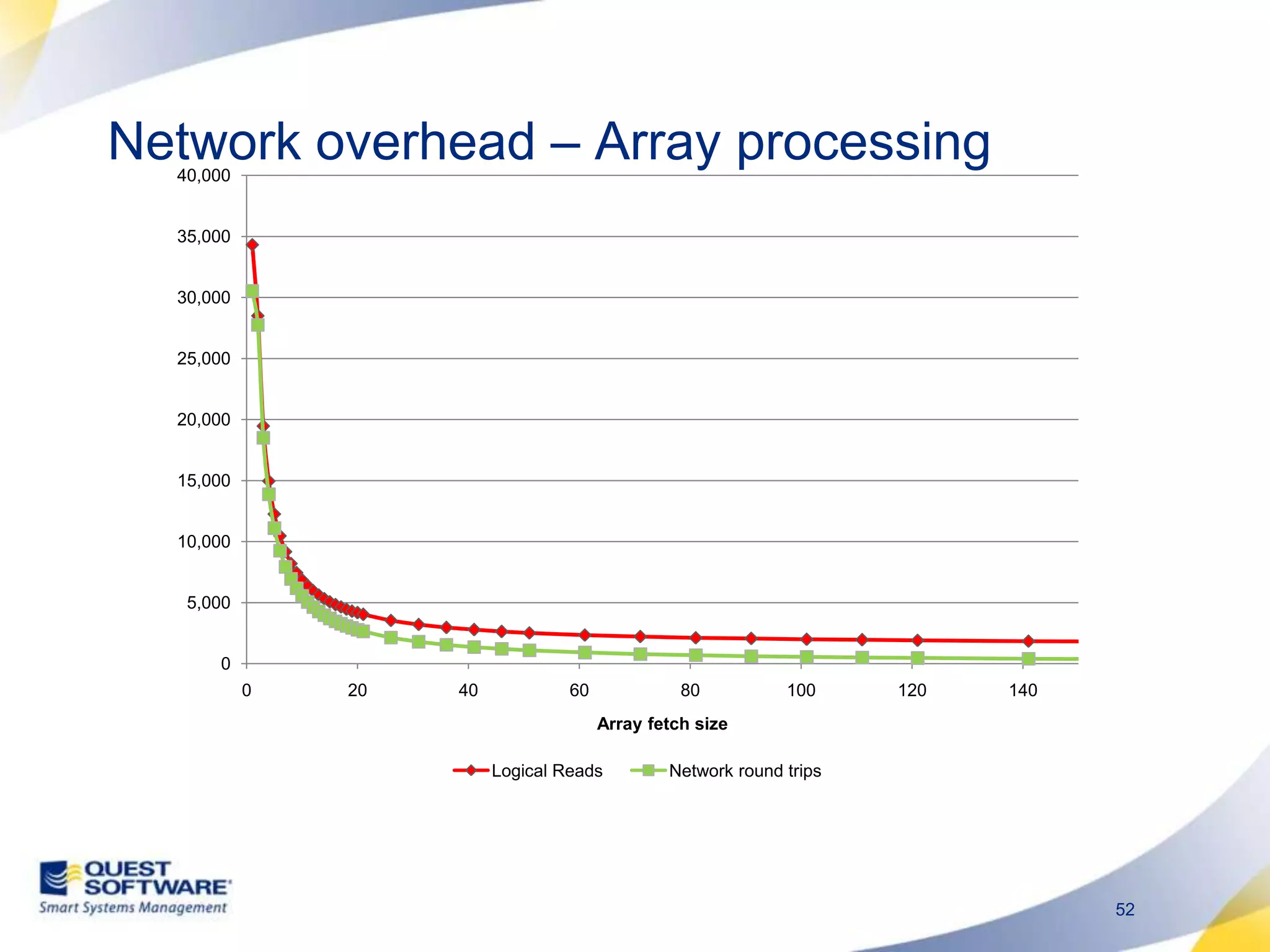



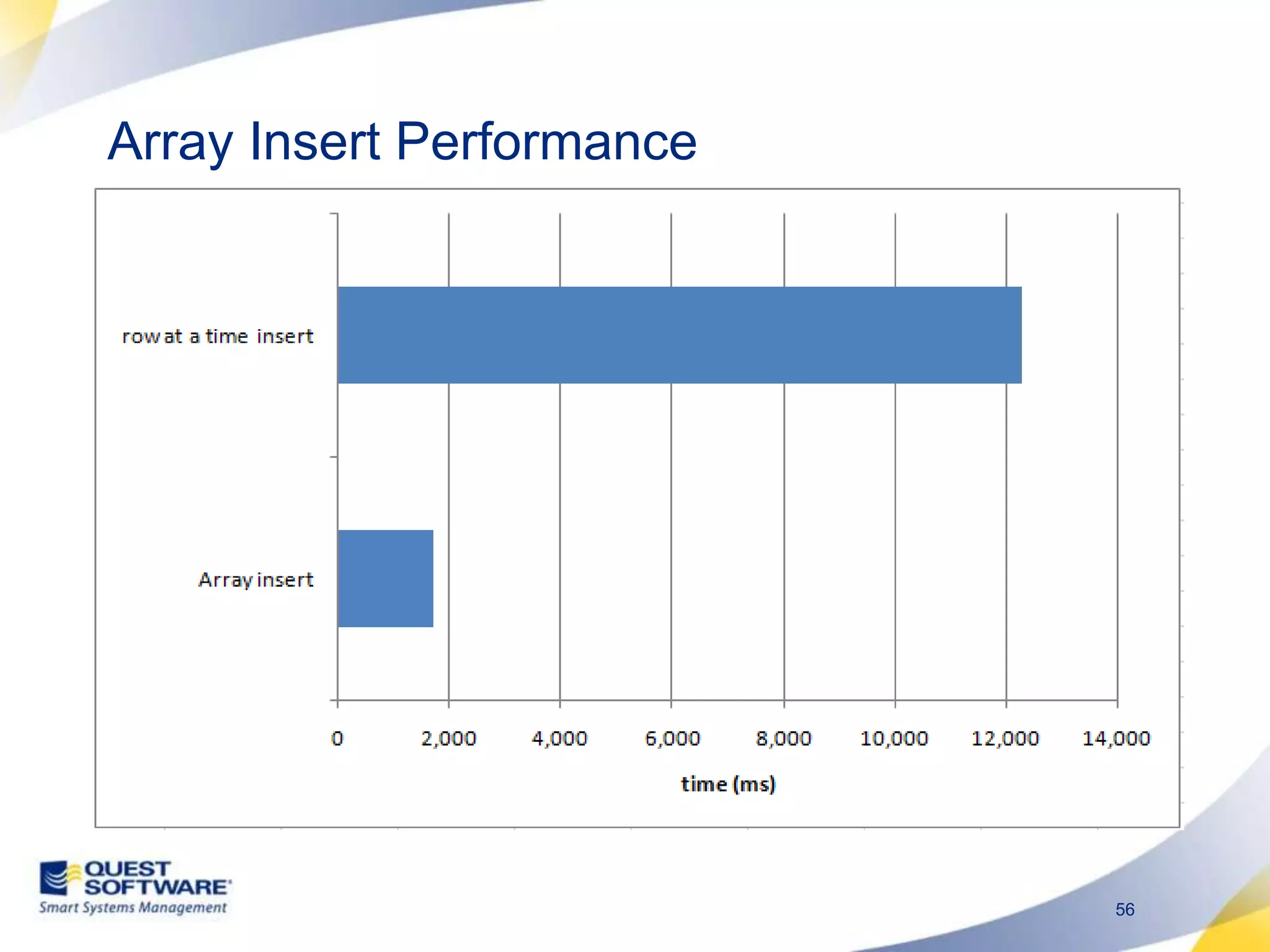



The document discusses designing database architectures and applications for high performance. It provides guidance on defining clear performance requirements, designing databases and applications to meet those requirements, and techniques like indexing, partitioning, caching, and array processing to optimize performance. The goal is to map performance needs to the architecture from the start to avoid later issues and ensure requirements are actually achieved.