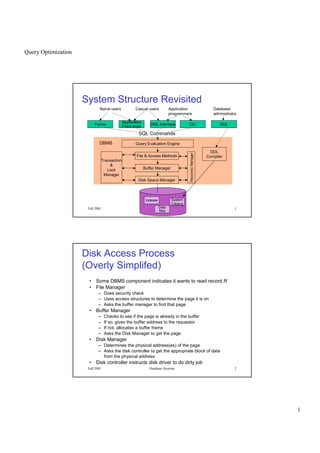
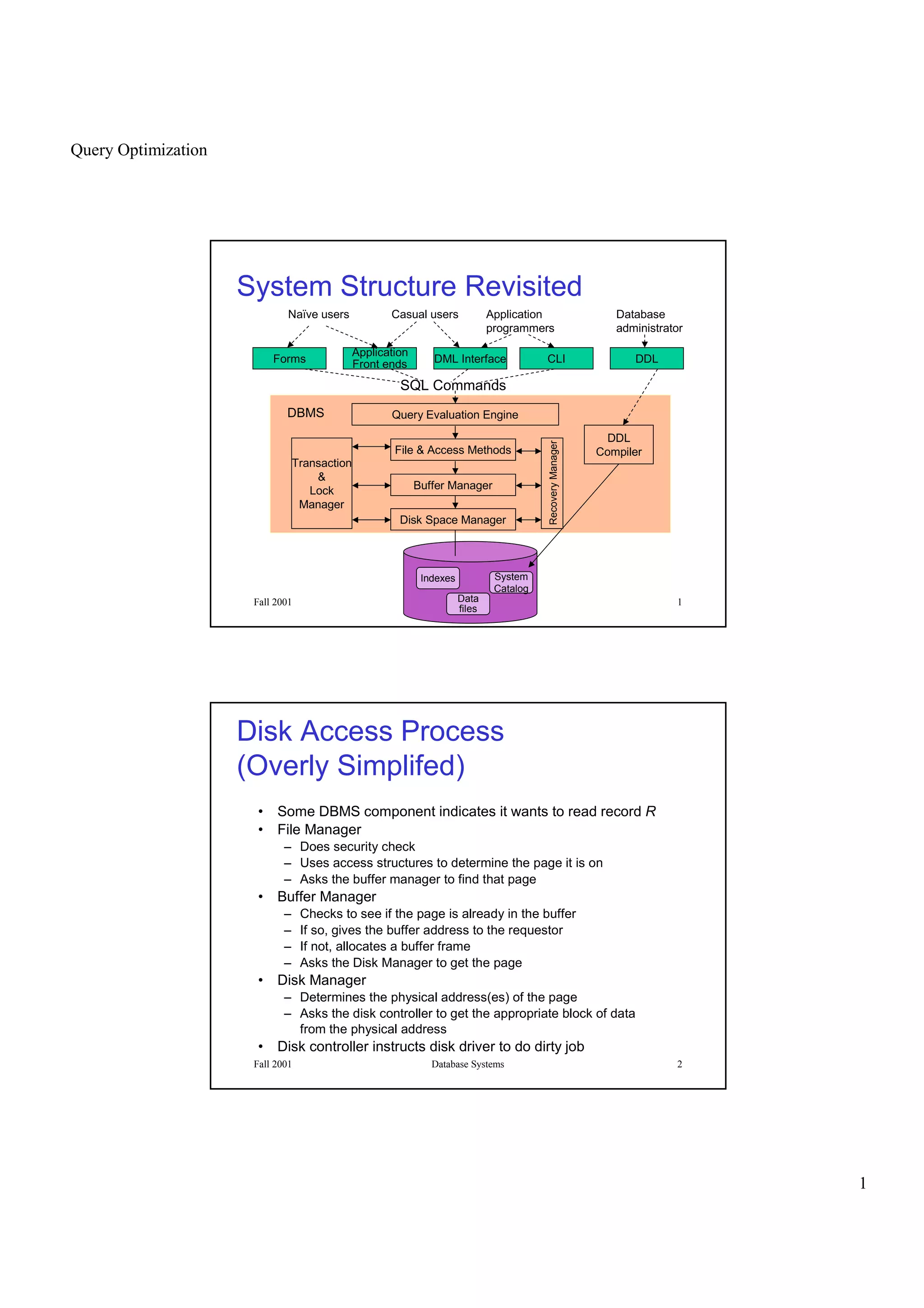
This document discusses query optimization in database systems. It begins by describing the components of a database management system and how queries are processed. It then explains that the goal of query optimization is to reduce the execution cost of a query by choosing efficient access methods and ordering operations. The document outlines different query plans involving table scans, index scans, and joins. It also introduces concepts like filter factors, statistics about tables and indexes, and how these are used to estimate the cost of alternative query execution plans.




![Query Optimization
7
Fall 2001 Database Systems 13
SELECT * FROM T WHERE P
• Table scan methods
– read the entire table and select tuples that satisfy
the predicate P [sequential scan]
– prefetching is used to reduce the read time (read
blocks of N pages at once from the same track)
[sequential scan with prefetch]
• Index scan methods
– use indices to find tuples that satisfy all of P and
then read the tuples from disk [index scan]
– use indices to find tuples that satisfy part of P and
then read the tuples from disk and check the rest
of P [index scan+select]
Fall 2001 Database Systems 14
SELECT * FROM T WHERE P
• Index scan methods (continued)
– use indices to find tuples that satisfy all of P and output the
indexed attributes [index-only scan]
– use indices to find tuples that satisfy part of P and then find the
intersection of different sets of tuples [multi-index scan]](https://image.slidesharecdn.com/www-pkbul-blogspot-comdbms13-130615034551-phpapp01/85/Www-pkbulk-blogspot-com-dbms13-7-320.jpg)















































![[Www.pkbulk.blogspot.com]dbms10](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms10-130615034621-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms02](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms02-130615034556-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms05](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms05-130615034608-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms12](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms12-130615034629-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms03](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms03-130615034558-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms11](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms11-130615034624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Www.pkbulk.blogspot.com]file and indexing](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comfileandindexing-130615034648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms09](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms09-130615034619-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms07](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms07-130615034615-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms06](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms06-130615034613-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms04](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms04-130615034606-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Www.pkbulk.blogspot.com]dbms01](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms01-130615034553-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























