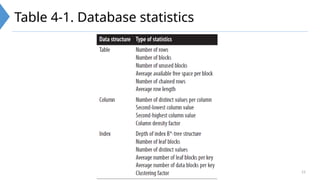
The document details advanced database administration topics including partitioning strategies, additional data structures, and query optimization techniques for Oracle databases. It covers various partitioning methods, such as interval and composite partitioning, their benefits, and the usage of sequences, synonyms, and clusters for data management. Additionally, it explains query optimization processes, contrasting rule-based and cost-based optimization approaches, highlighting the importance of statistics in determining optimal execution paths.



















![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































