Download as PDF, PPTX


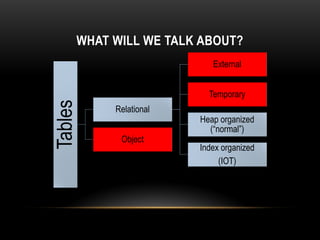






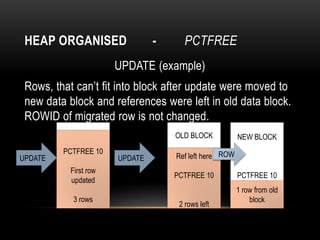




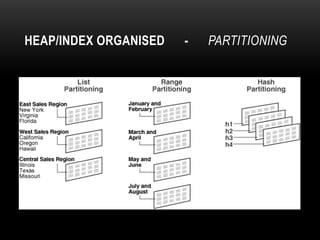


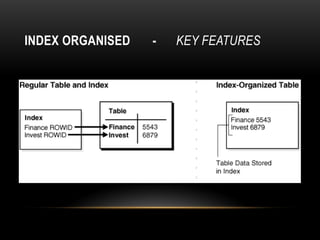

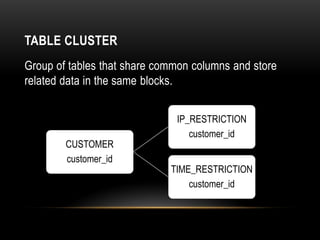

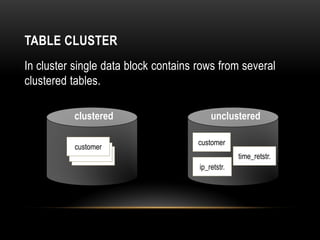

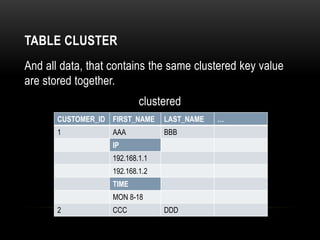





Oracle tables can be organized as heap tables or index organized tables. Heap tables store rows together in blocks without any particular order, while index organized tables order rows based on primary key values. Tables can be partitioned to improve manageability and performance for large volumes of data. Table clusters group related tables together in blocks to reduce disk I/O and access time for joined queries on those tables.





![Introduction into MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-210717011329-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)





![[INSIGHT OUT 2011] B26 optimising a two table join(jonathan lewis)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b26optimisingatwo-tablejoinjonathanlewis-111114181039-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































