Downloaded 22 times













![Factors
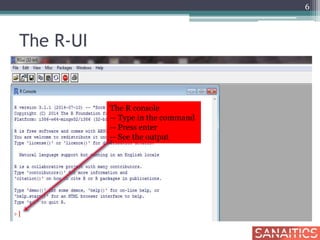
• Tell R that a variable is nominal by making it a
factor
• The factor stores the nominal values as a vector of
integers in the range [ 1... k ] (where k is the number
of unique values in the nominal variable), and an
internal vector of character strings (the original
values) mapped to these integers
• An ordered factor is used to represent an ordinal
variable
17](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-17-320.jpg)




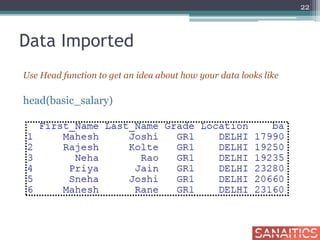
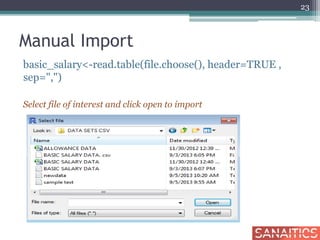




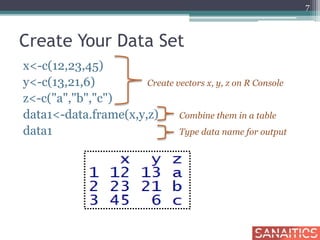
![Row Sub-Setting
basic_salary[c(5:10), ] Display rows from 5th to 10th
28](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-28-320.jpg)
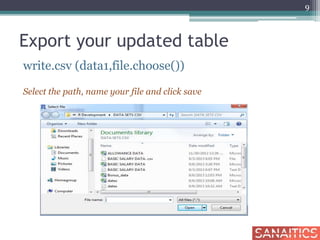
![Row Sub-Setting
basic_salary[c(1,3,5,8), ] Display only selected rows
29](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-29-320.jpg)
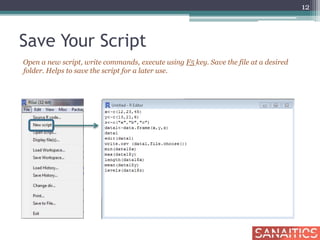
![Condition on Observations
basic_salary1 <- basic_salary[basic_salary$Location
==“DELHI” & basic_salary$ba > 20000, ]
head(basic_salary1)
30](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-30-320.jpg)
![More than one value of Variable
basic_salary2 <-basic_salary[basic_salary$Location %in%
c("MUMBAI"),]
head(basic_salary2)
31](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-31-320.jpg)
![Column Sub-Setting
basic_salary3<-basic_salary[ , 1:2]
head(basic_salary3)
32](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-32-320.jpg)
![Condition on Variable Names
basic_salary4 <- basic_salary[ ,c("First_Name","Location",
"ba")]
head(basic_salary4)
33](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-33-320.jpg)
![Selected Rows for Selected Columns
basic_salary5<-basic_salary[c(1,5,8,4), c(1,2)]
basic_salary5
34](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-34-320.jpg)
![Condition on Variables & Observations
basic_salary6<-basic_salary[basic_salary$Grade=="GR1"
& basic_salary$ba >15000 , c("First_Name","Location",
"ba") ]
head(basic_salary6)
35](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-35-320.jpg)




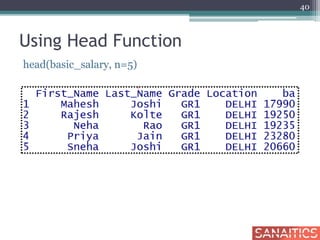
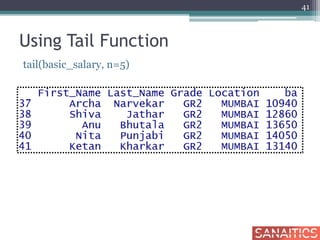
![Using Split Function
basic_salary10<-
split(basic_salary,basic_salary$Location)
delhi_salary<-data.frame(basic_salary10[1])
head(delhi_salary)
42](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-42-320.jpg)
![Using Split Function
mumbai_salary<-data.frame(basic_salary10[2])
head(mumbai_salary,5)
43](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-43-320.jpg)
![Delete Cases
basic_salary11<-
basic_salary[!(basic_salary$Grade=="GR1") &
!(basic_salary$Location=="MUMBAI"), ]
basic_salary11
44](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-44-320.jpg)
![Delete Cases
basic_salary12<-basic_salary[ !(basic_salary$ba>14500), ]
basic_salary12
45](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-45-320.jpg)

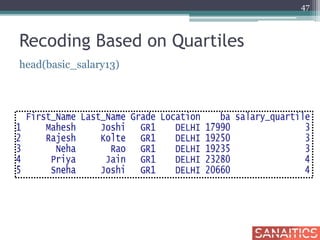



![Recoding Based on User Cut Points
basic_salary15[c(20,30),]
51](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-51-320.jpg)
![Remove Variables
#using remove.vars function (need to load “gdata”
package)
Removing variable 'Name'
Removing variable 'Place‘
basic_salary<-remove.vars(basic_salary,c("Last_Name",
"Location"))
names(basic_salary)
[1] "X" "First_Name" "Grade" "ba"
52](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-52-320.jpg)

![Sorting Data
attach(basic_salary)
bs_sorted1<-basic_salary[order(-ba), ]
head(bs_sorted1)
54](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-54-320.jpg)
![Sorting by Multiple Variables
bs_sorted2<-basic_salary[order( First_Name, ba) , ]
head(bs_sorted2)
55](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-55-320.jpg)









![Deleting missing cases# complete.cases, na.exclude(), na.omit()are for dealing manually with NAs in a
dataset
x<-c(12,NA,13,12)
y<-c(25,48,NA,NA)
data<-data.frame(x,y)
data
65
data1<-na.omit(data)
data1
x y
1 12 25
data[complete.cases(da
ta),]
x y
1 12 25
na.exclude(data)
x y
1 12 25](https://image.slidesharecdn.com/getstartedifull-150212064245-conversion-gate02/85/R-Get-Started-I-Sanaitics-65-320.jpg)

R is a free and open-source language and environment for statistical computing and graphics. It contains a variety of statistical and graphical techniques built in. This document provides an introduction to using R, including how to import and manage data, perform basic analyses and visualizations, and save scripts. It covers topics such as importing data from CSV and text files, creating and subsetting data frames, recoding variables, sorting and merging data, and using basic functions.











![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































































