Download to read offline



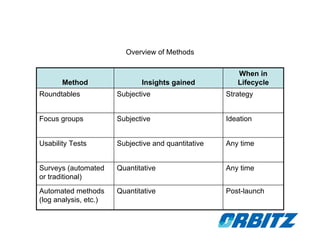





The document discusses user research methods like focus groups, usability tests, and surveys that are used to understand users, predict adoption of new features, and evaluate design performance. It provides an overview of when different methods are used in the product lifecycle and notes that usability tests can evaluate existing versus new designs. The document also provides guidance on properly conducting, interpreting, and communicating the results of usability tests to product teams.


















































































