Downloaded 11 times












![A Simple Example
// Input: int A[N], array of N integers
// Output: Sum of all numbers in array A
int Sum(int A[], int N) {
int s=0;
for (int i=0; i< N; i++)
s = s + A[i];
return s;
}
• How should we analyze this?](https://image.slidesharecdn.com/week2-searchalgorithms-191013065807/85/Searching-Algorithms-13-320.jpg)
![A Simple Example
• Analysis of Sum
• 1.) Describe the size of the input in terms of one ore
more parameters:
▫ Input to Sum is an array of N ints, so size is N.
• 2.) Then, count how many steps are used for an
input of that size:
▫ A step is an elementary operation such as
+, <, =, A[i]](https://image.slidesharecdn.com/week2-searchalgorithms-191013065807/85/Searching-Algorithms-14-320.jpg)























![Linear Search - Algorithm
set found to false;
set position to –1;
set index to 0
while (index < number of elements) and (found is false)
if list[index] is equal to search value
found = true
position = index
end if
add 1 to index
end while
return position](https://image.slidesharecdn.com/week2-searchalgorithms-191013065807/85/Searching-Algorithms-38-320.jpg)
![Linear Search - Program
Int LinSearch(int [] list, int item, int size) {
int found = 0;
int position = -1;
int index = 0;
while (index < size) && (found == 0) {
if (list[index] == item ) {
found = 1;
position = index;
} // end if
index++;
} // end of while
return position;
} // end of function LinSearch](https://image.slidesharecdn.com/week2-searchalgorithms-191013065807/85/Searching-Algorithms-39-320.jpg)

















![Binary Search Program
int binarySearch (int list[], int size, int key) {
int first = 0, last , mid, position = -1;
last = size - 1
int found = 0;
while (!found && first <= last) {
middle = (first + last) / 2; /* Calculate mid point */
if (list[mid] == key) { /* If value is found at mid */
found = 1;
position = mid;
}
else if (list[mid] > key) /* If value is in lower half */
last = mid - 1;
else
first = mid + 1; /* If value is in upper half */
} // end while loop
return position;
} // end of function](https://image.slidesharecdn.com/week2-searchalgorithms-191013065807/85/Searching-Algorithms-57-320.jpg)














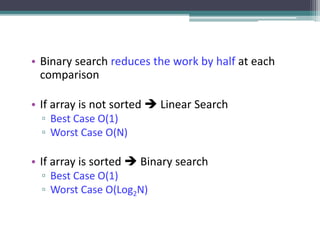









Linear search examines each element of a list sequentially, one by one, and checks if it is the target value. It has a time complexity of O(n) as it requires searching through each element in the worst case. While simple to implement, linear search is inefficient for large lists as other algorithms like binary search require fewer comparisons.



![Data Structures - Lecture 8 [Sorting Algorithms]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-8sortingalgorithms-150205105023-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































