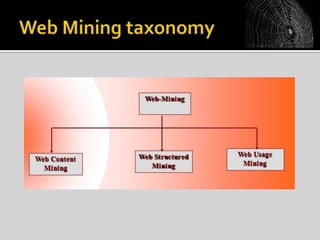
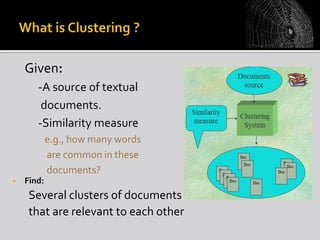
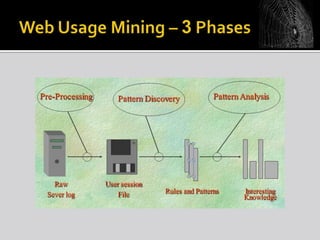
The document discusses web mining, which involves applying data mining techniques to discover useful information and patterns from web data. It covers the types of web data, various applications of web mining, challenges, and different techniques used. These include classification, clustering, association rule mining. It also discusses how web mining can be used to solve search engine problems and how cloud computing provides a new approach for web mining through software as a service.