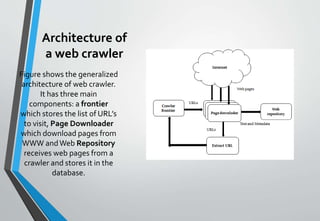
A web crawler is a program that browses the World Wide Web methodically by following links from page to page and downloading each page to be indexed later by a search engine. It initializes seed URLs, adds them to a frontier, selects URLs from the frontier to fetch and parse for new links, adding those links to the frontier until none remain. Web crawlers are used by search engines to regularly update their databases and keep their indexes current.


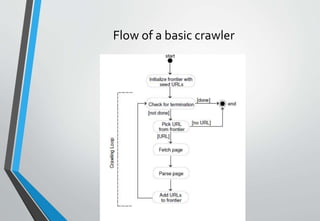
![The working of a web crawler is as follows:
• Initializing the seed URL or URLs
• Adding it to the frontier
• Selecting the URL from the frontier
• Fetching the web-page corresponding to that URLs
• Parsing the retrieved page to extract the URLs[21]
• Adding all the unvisited links to the list of URL i.e.
into the frontier
• Again start with step 2 and repeat till the frontier is
empty.](https://image.slidesharecdn.com/1webcrawlers-170104071447/85/Web-Crawlers-3-320.jpg)





































































![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


