Downloaded 2,041 times




































![More Notables…
“This enables organizations to take control of
their data warehousing destiny, supporting
better and more relevant data warehouses in
less time than before.” Howard Dresner
“[The Data Vault] captures a practical body of
knowledge for data warehouse development
which both agile and traditional practitioners
will benefit from..” Scott Ambler](https://image.slidesharecdn.com/introdatavaultoow2011-111011131815-phpapp02/85/Introduction-to-Data-Vault-Modeling-56-320.jpg)








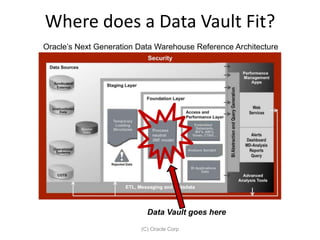
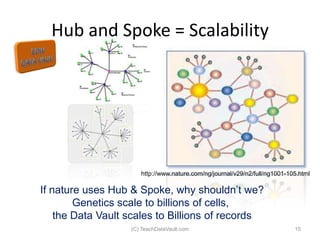
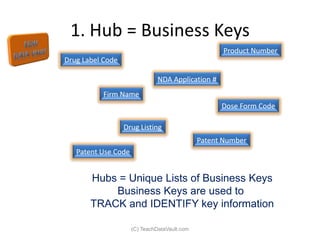
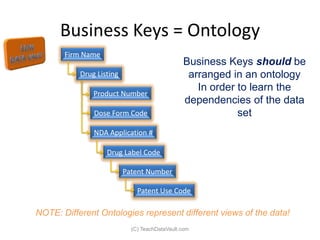
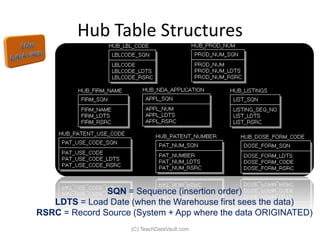
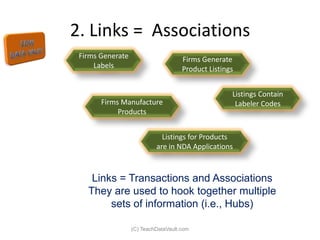
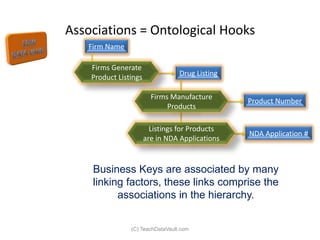
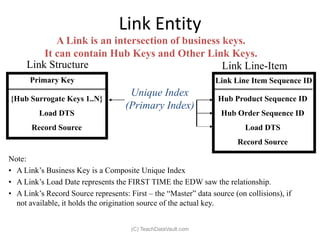
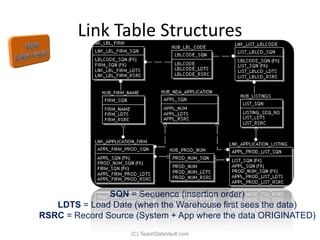
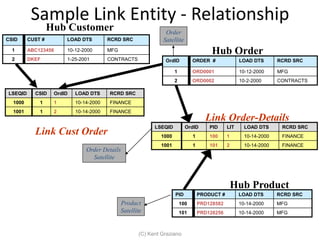
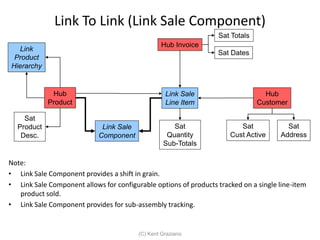
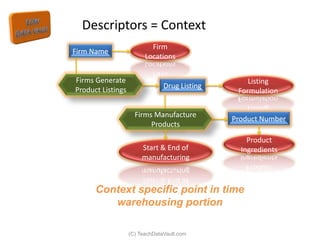
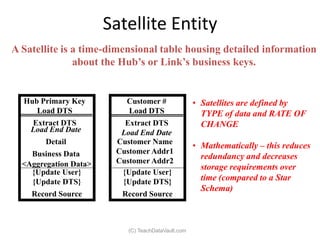
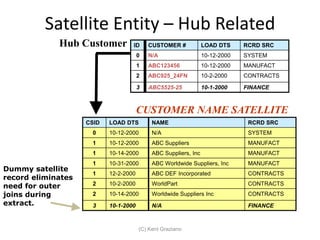
The document provides an introduction to data vault modeling by Kent Graziano, outlining its definition as a flexible and scalable data model that supports enterprise data warehouses. It contrasts traditional modeling techniques like 3rd normal form and star schema, highlighting the advantages of data vault modeling. The content also discusses the structure of data vault components, including hubs, links, and satellites, and their roles in maintaining historical data integrity and facilitating business intelligence.


















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

