Downloaded 29 times



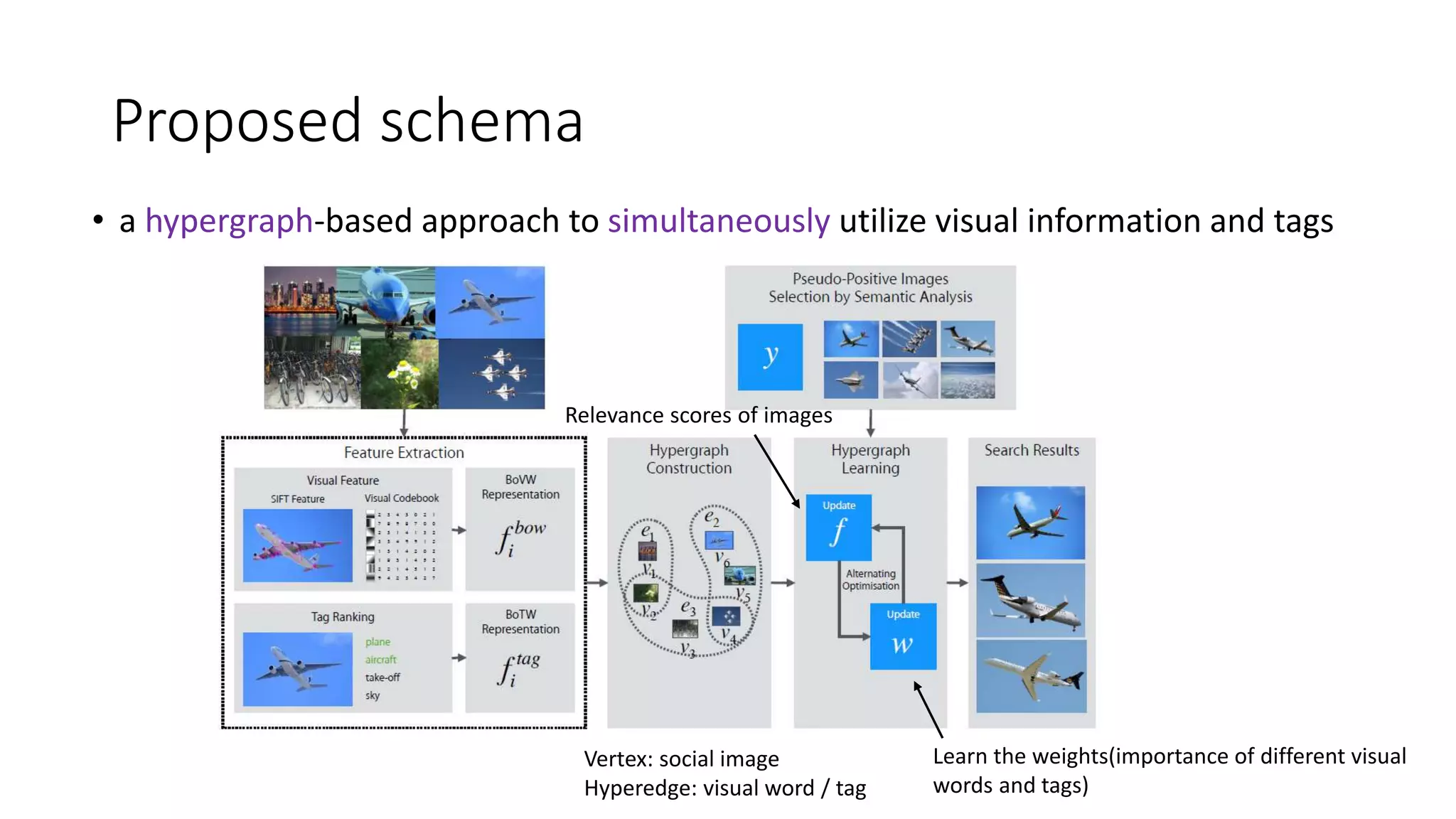


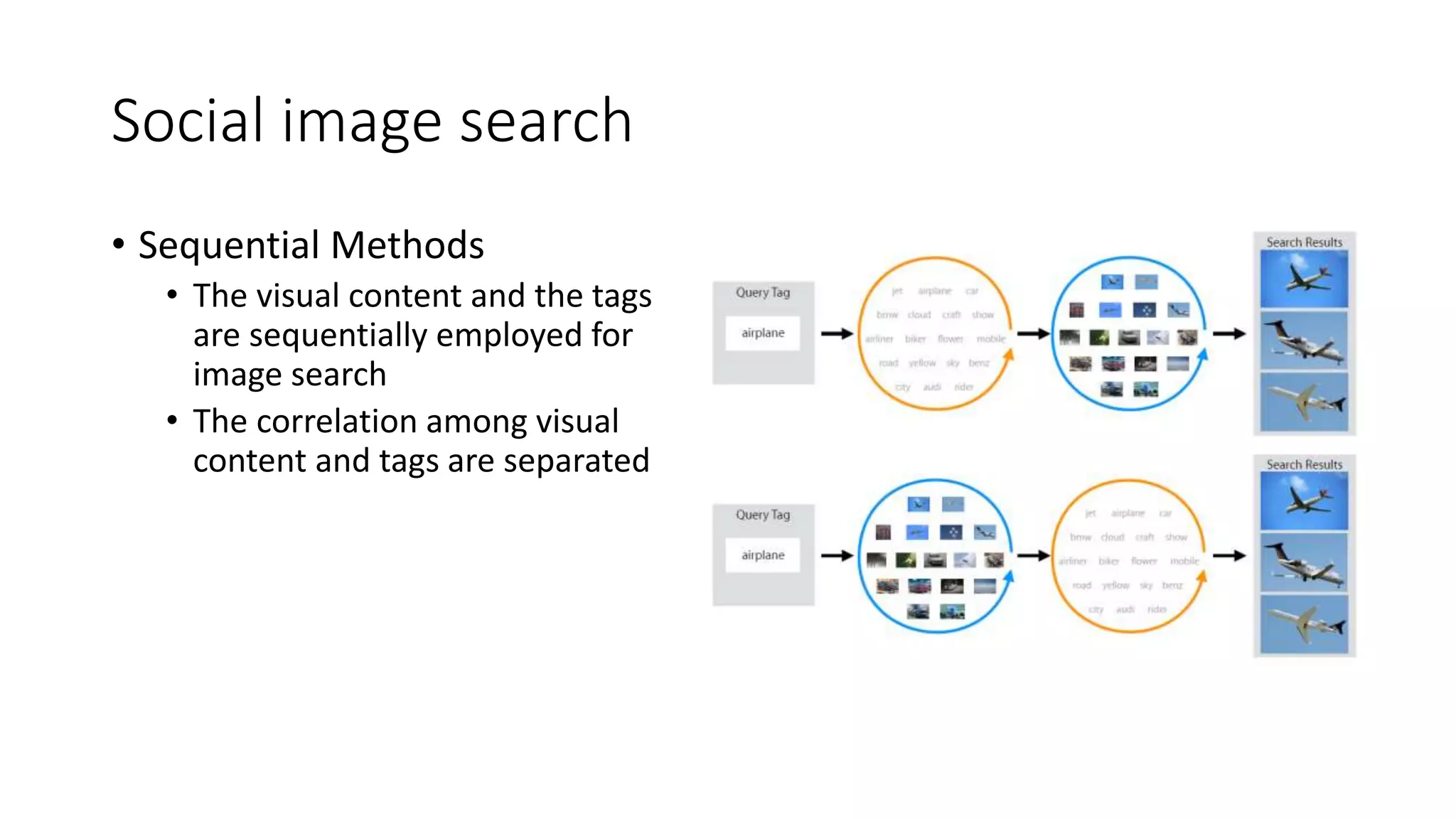
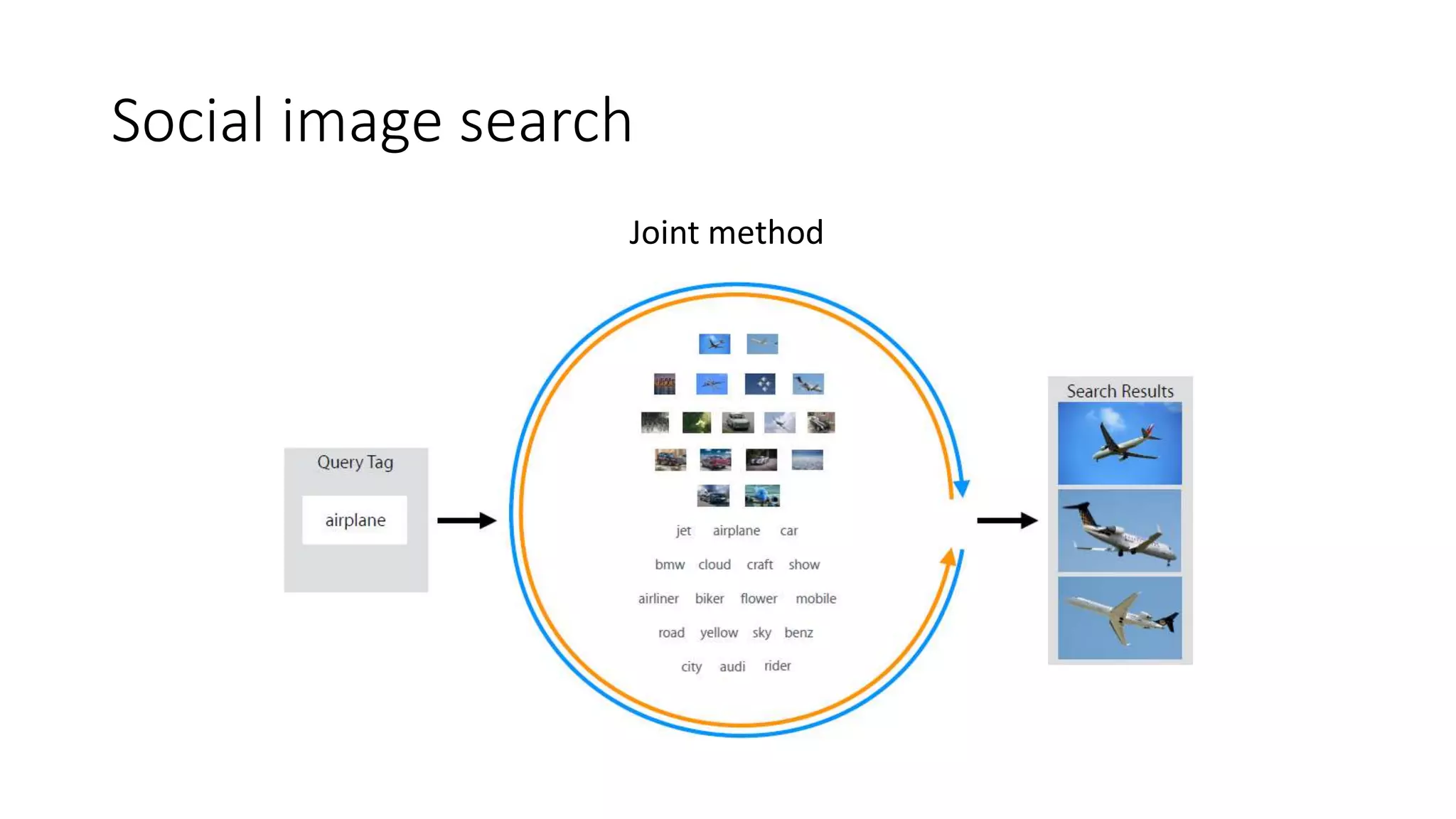


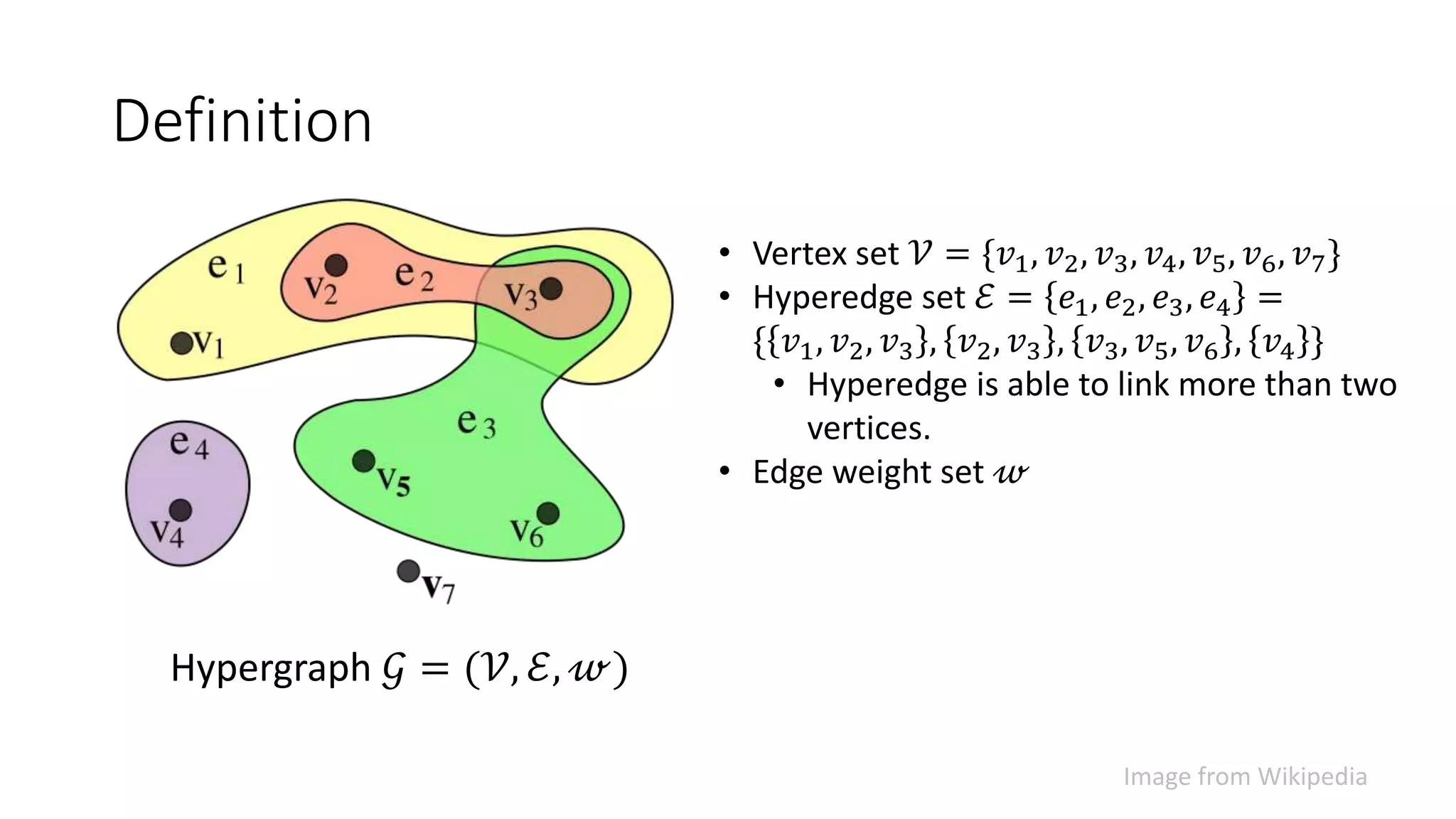






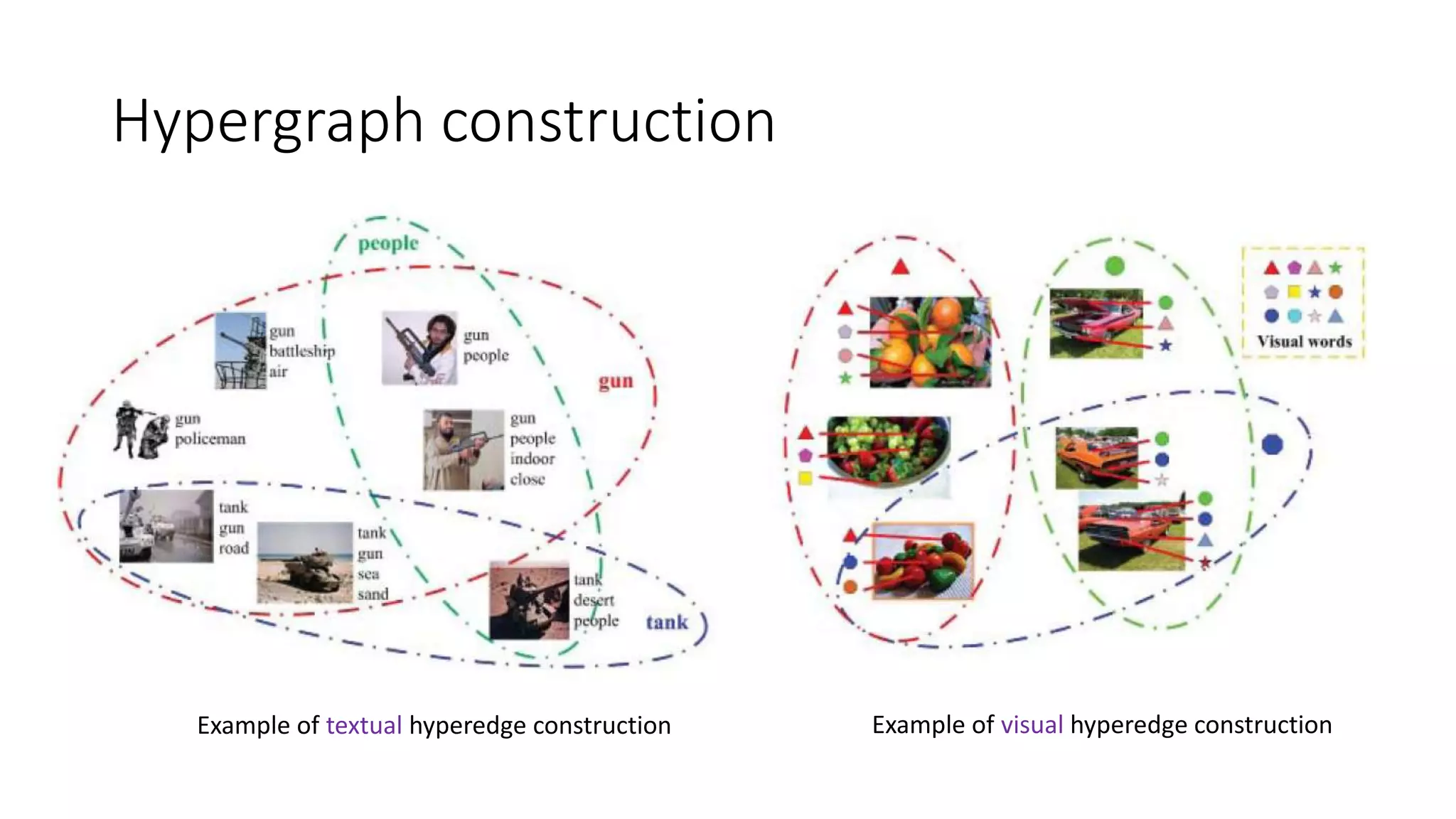
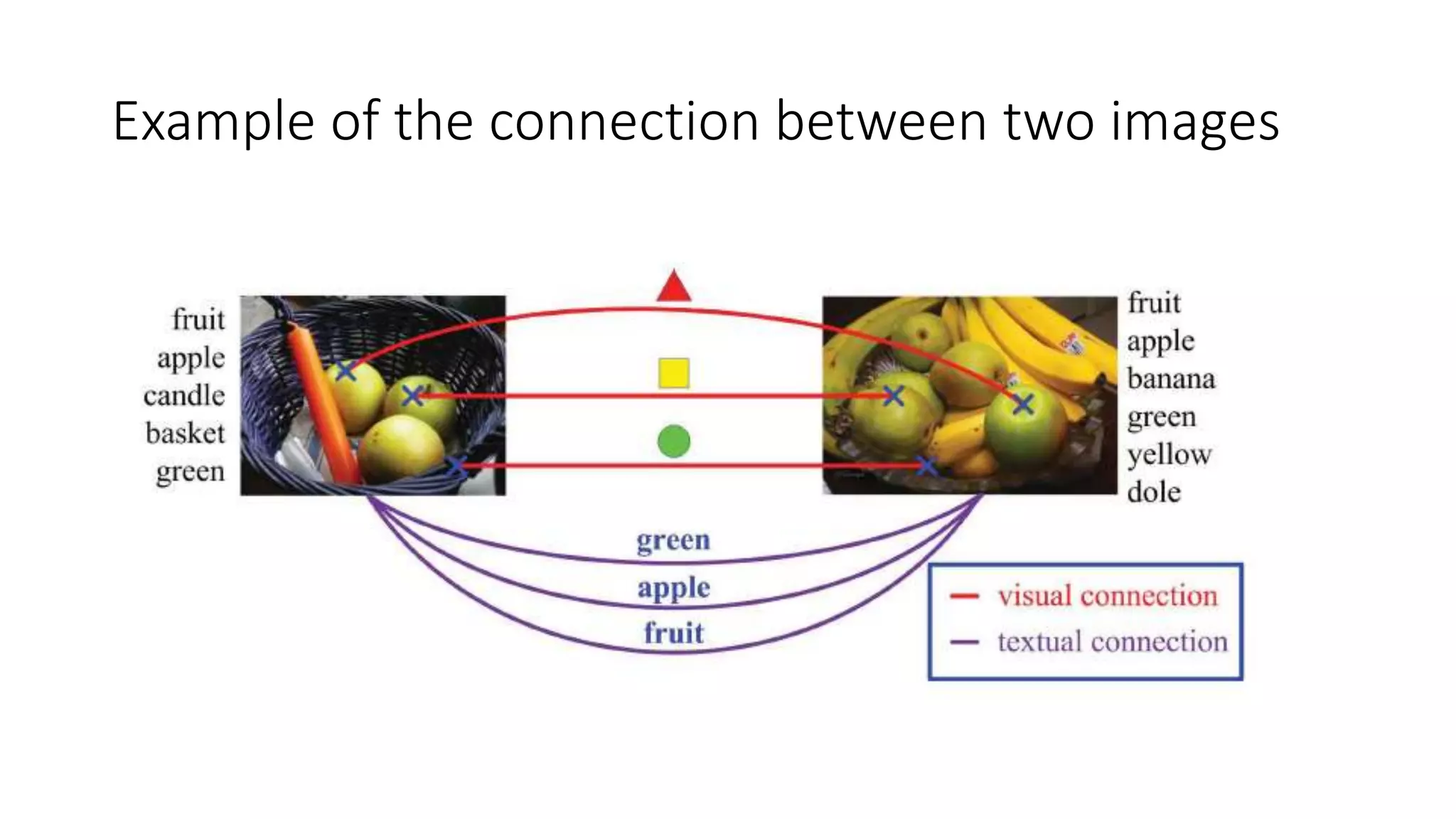








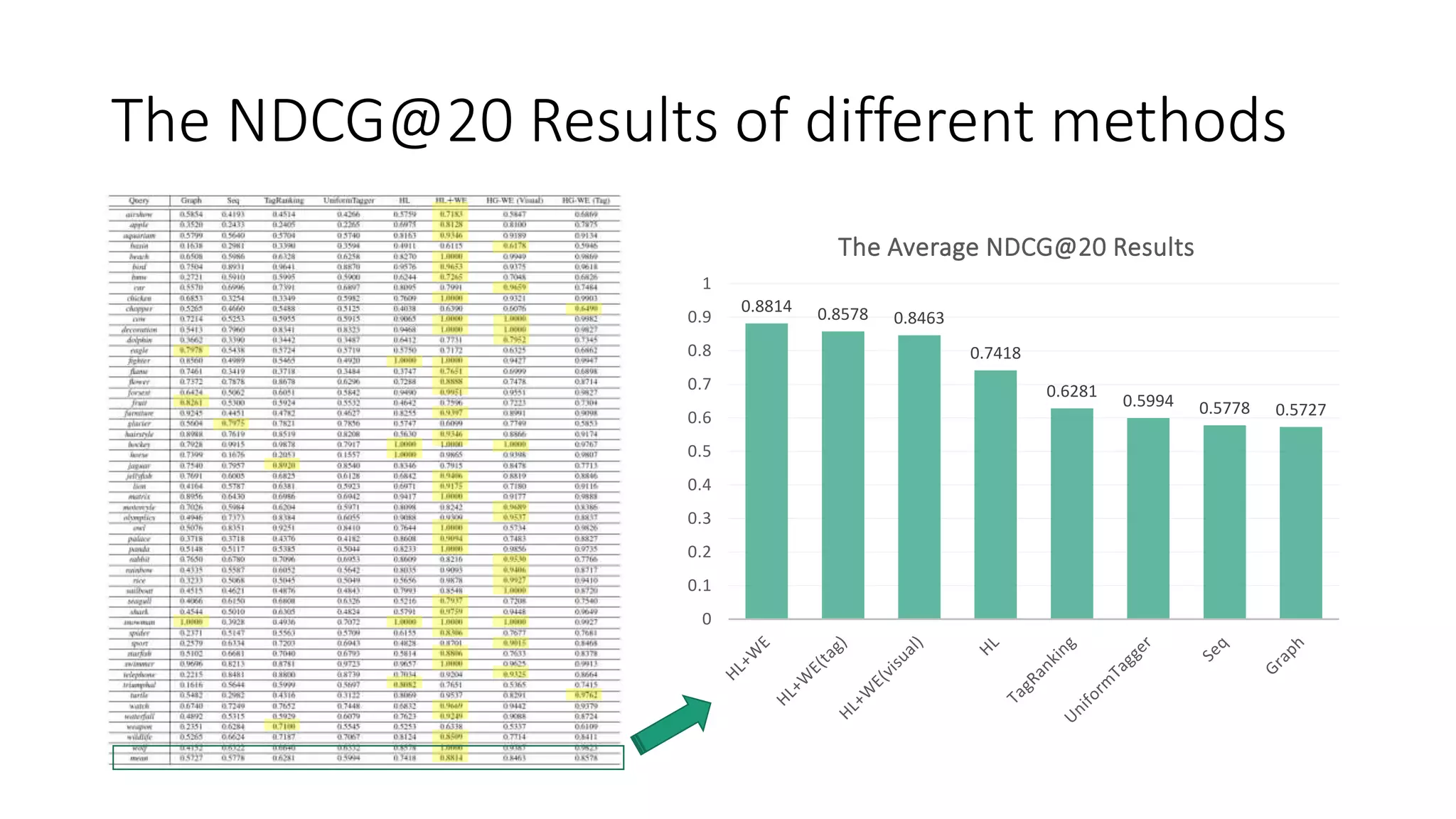
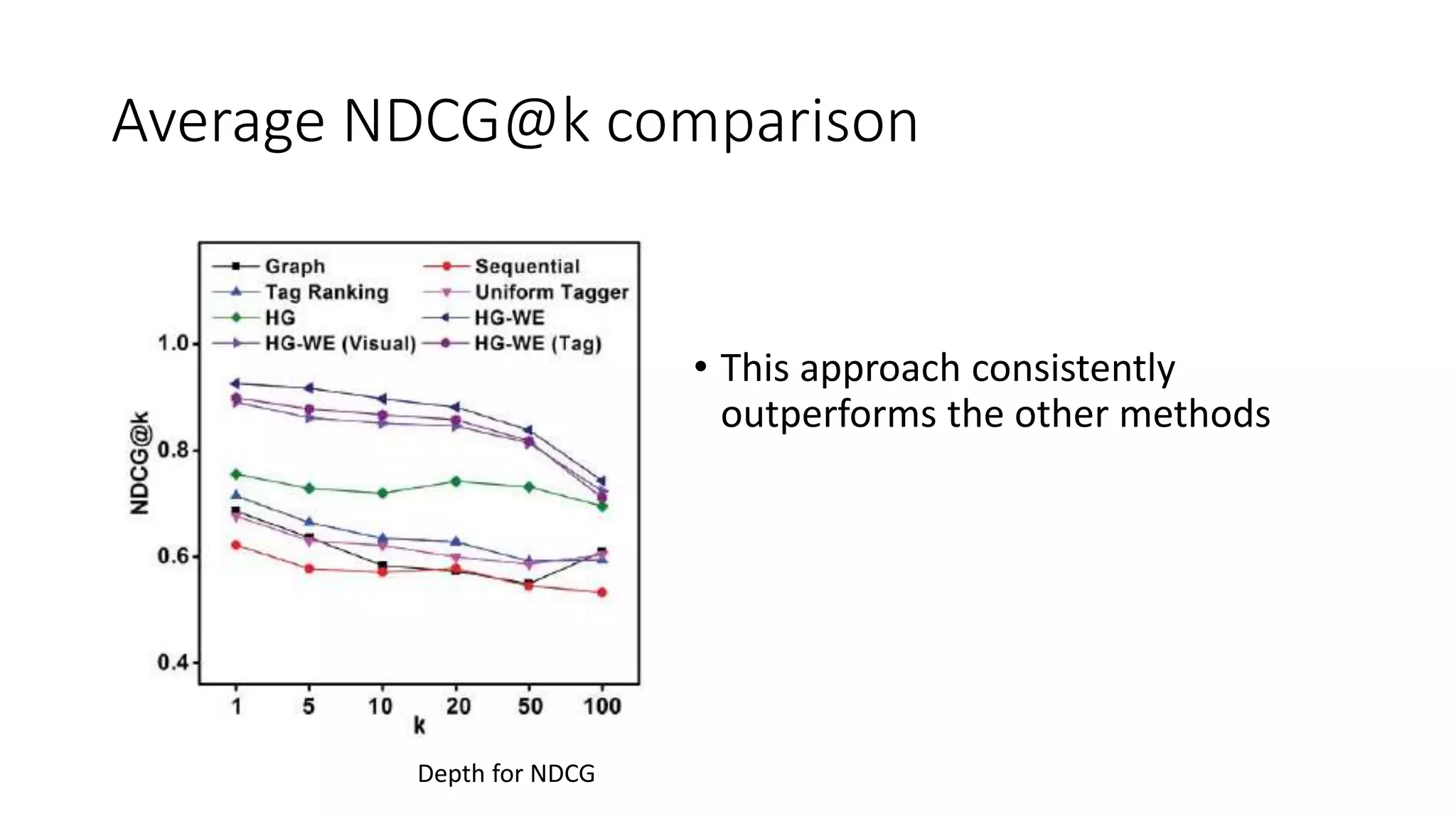



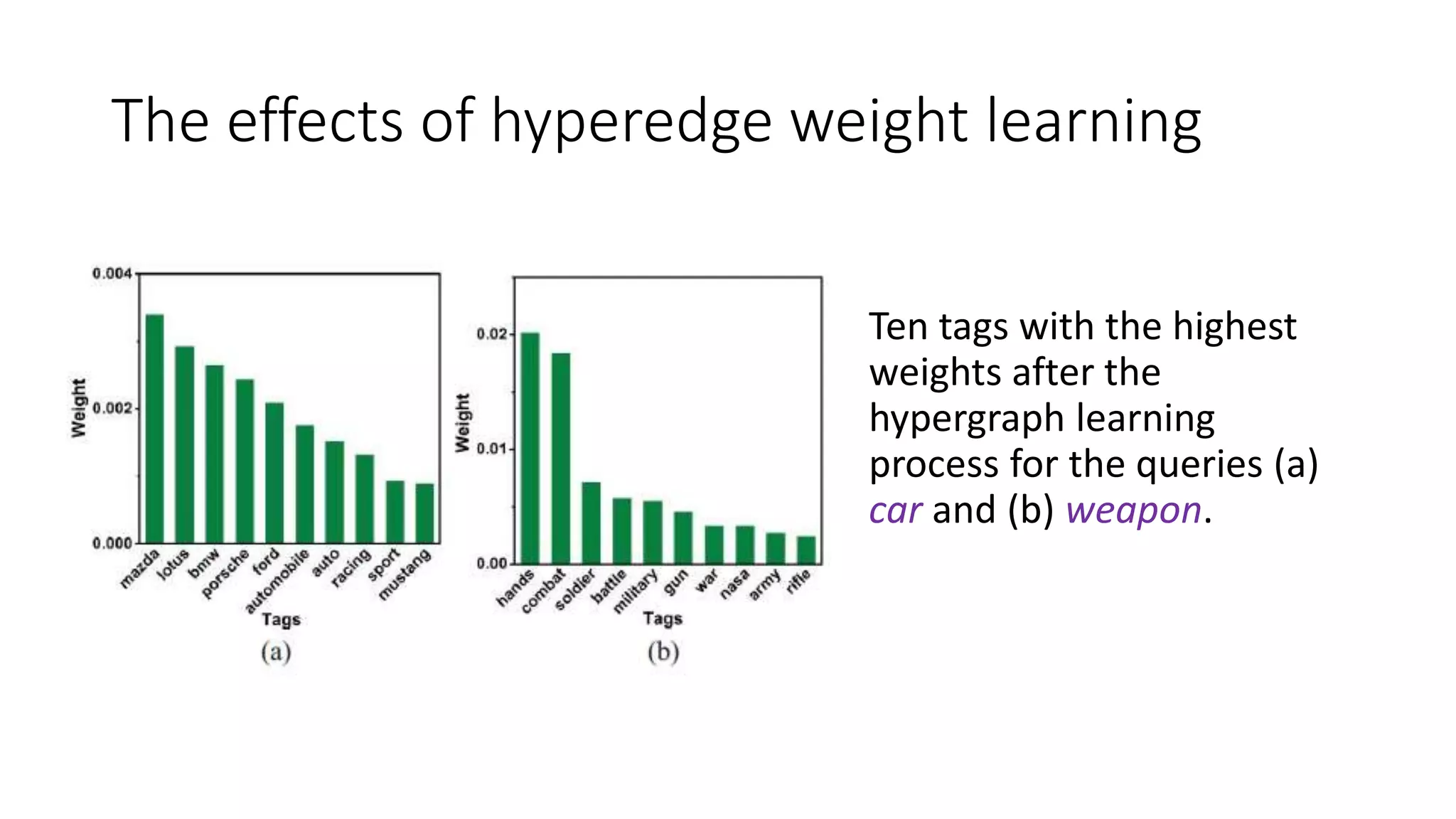
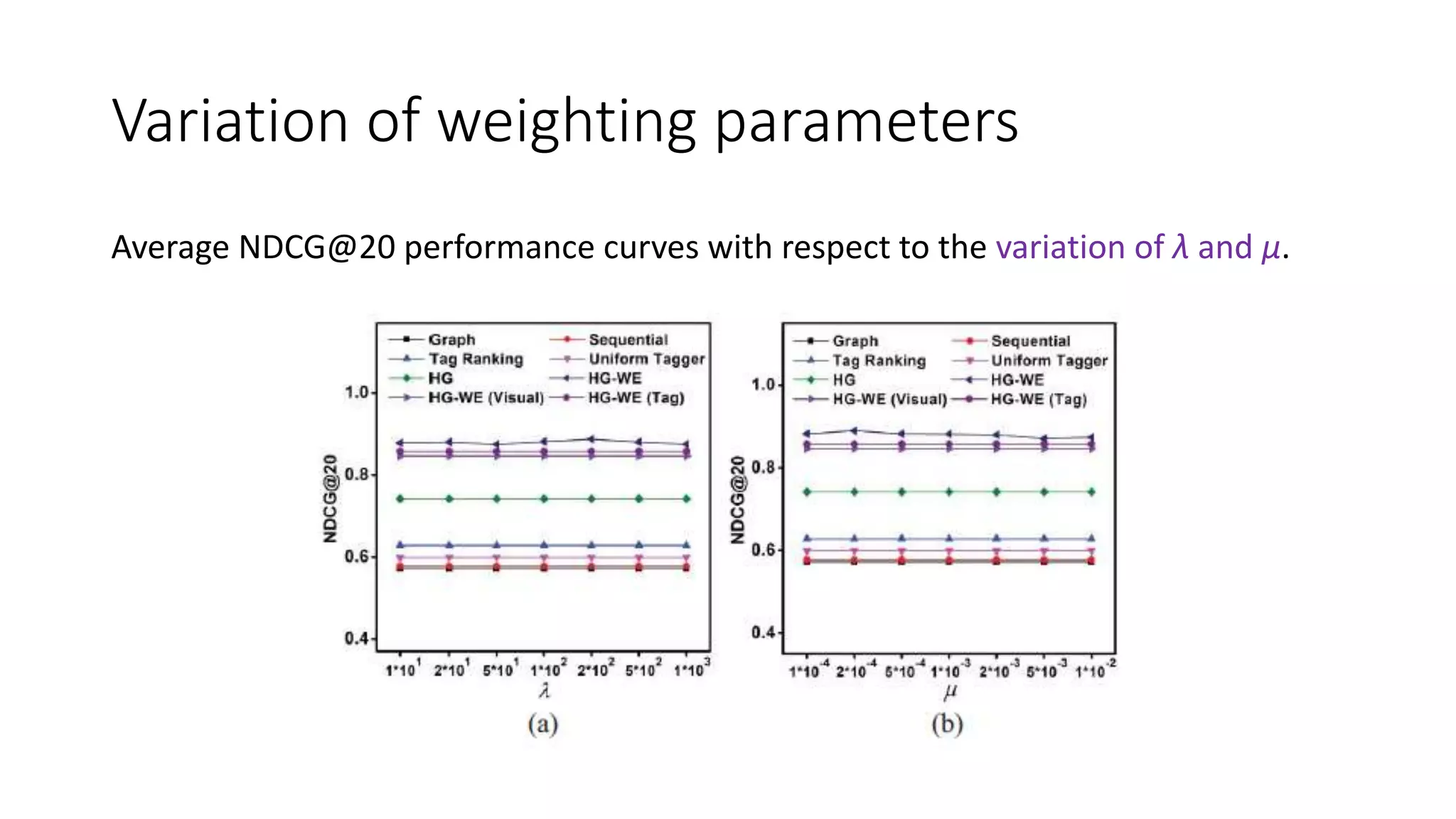


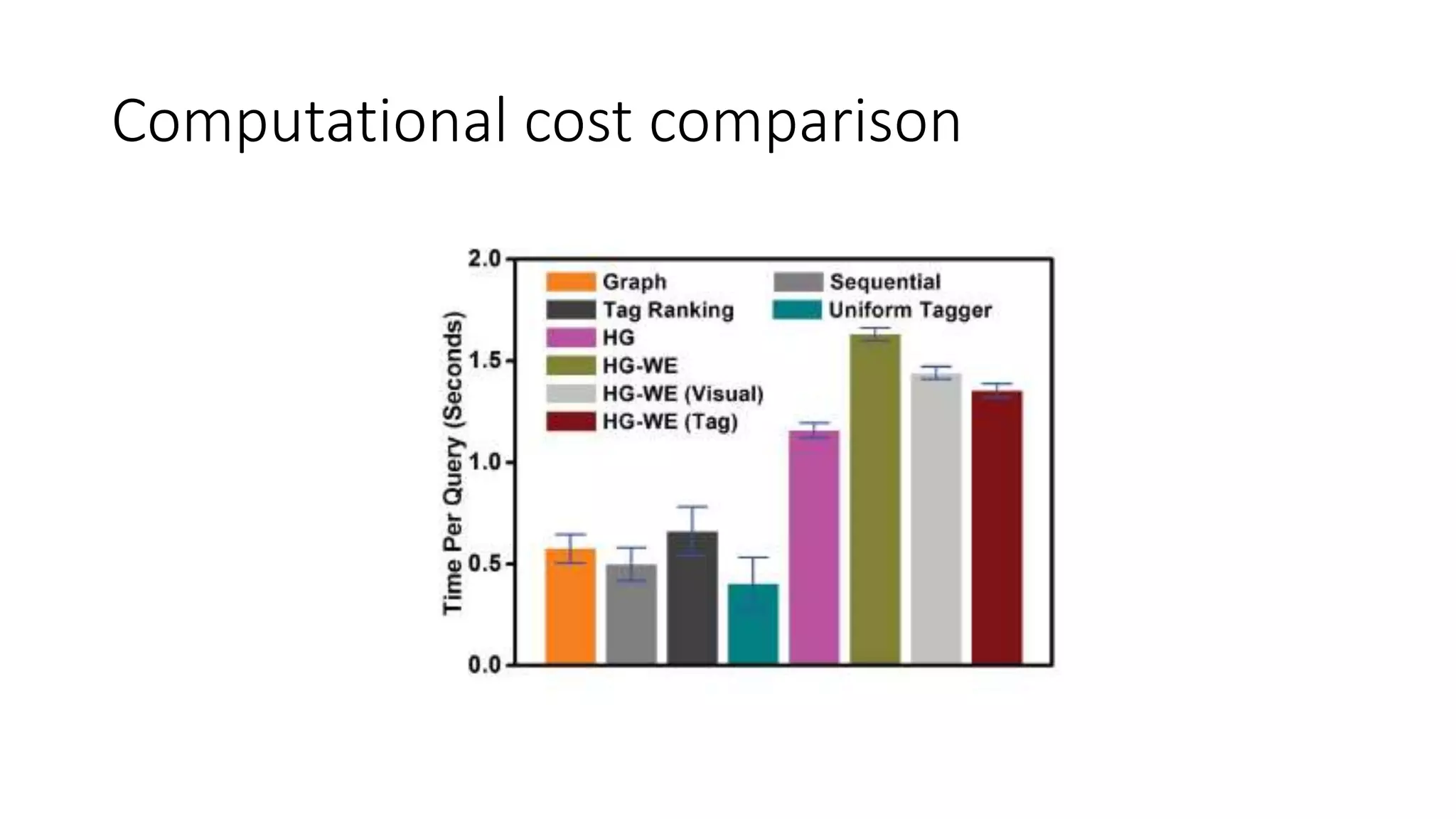




The document presents a hypergraph-based approach for improving tag-based social image search by jointly leveraging visual content and textual tags, addressing the limitations of conventional methods that treat these elements separately. It details the construction of hypergraphs to represent social images, the learning of relevance scores through binary classification, and optimization techniques used for this purpose. Experimental results demonstrate the proposed method's superiority over existing algorithms in accurately ranking images based on relevance to user queries.
































![[DL輪読会]Unsupervised Learning of 3D Structure from Images](https://cdn.slidesharecdn.com/ss_thumbnails/sugihara-161213071700-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning What and Where to Draw (NIPS’16)](https://cdn.slidesharecdn.com/ss_thumbnails/20170120misono-170215035536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]TREE-STRUCTURED VARIATIONAL AUTOENCODER](https://cdn.slidesharecdn.com/ss_thumbnails/161216tree-structuredvae-161216031644-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...](https://cdn.slidesharecdn.com/ss_thumbnails/20170203dlhacks-170203004925-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20160113-170222033302-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[NS][Lab_Seminar_250908]HGFormer: Topology-Aware Vision Transformer With Hype...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250908hgformer-250909013815-b301a76c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_241230]HiGDA: Hierarchical Graph of Nodes to Learn Local-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241230higda-241230113157-126d4bfa-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)