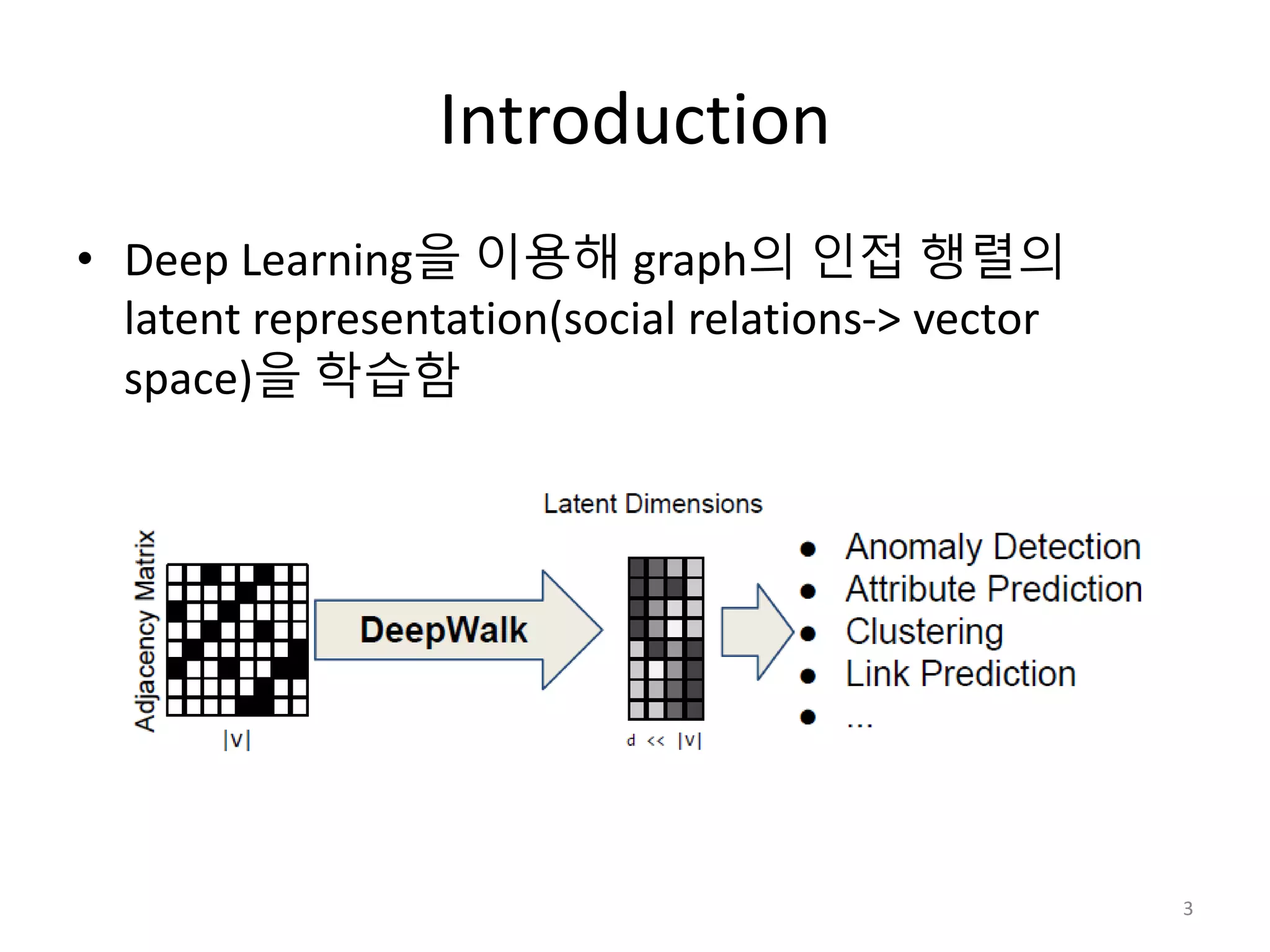
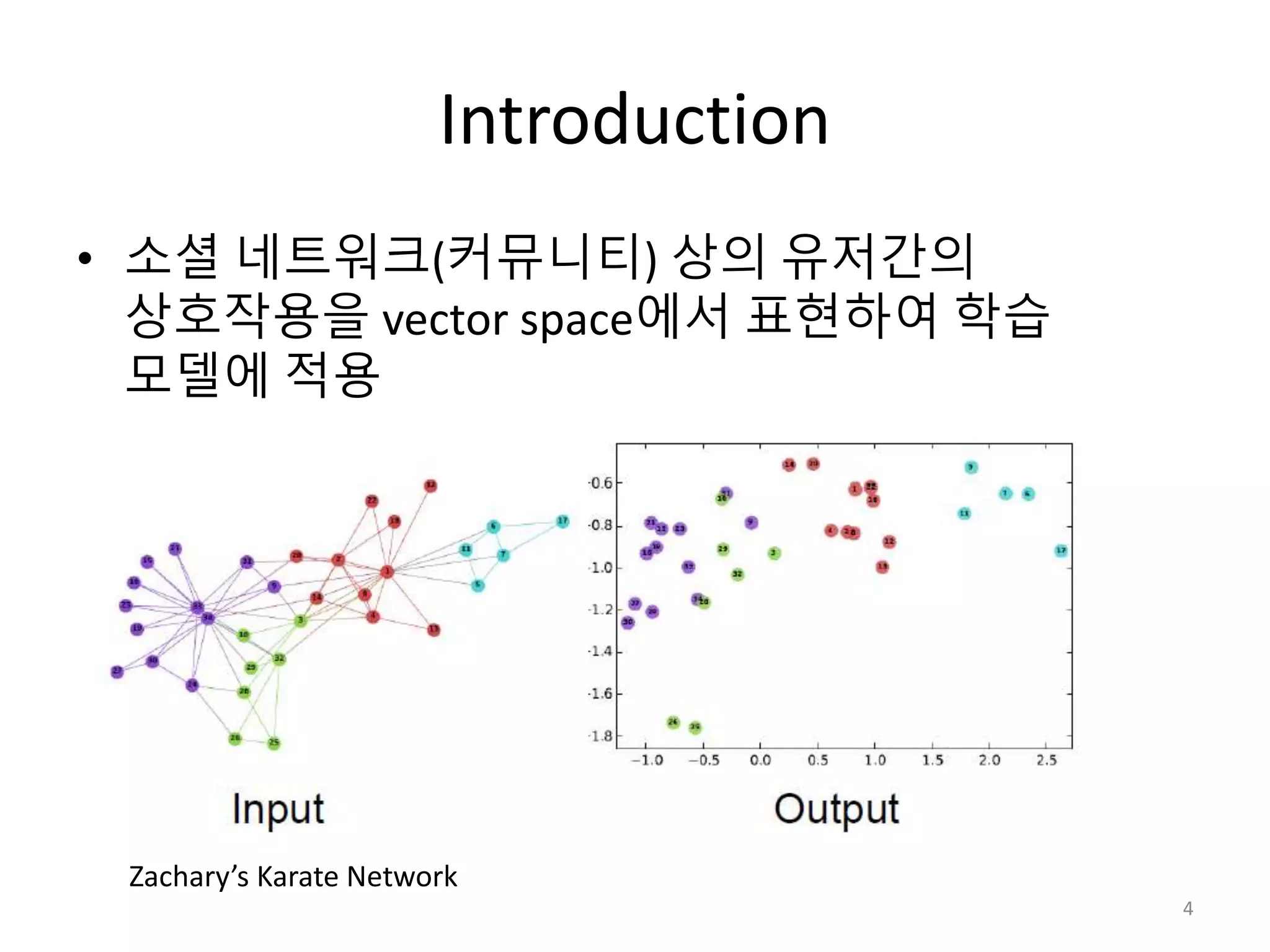
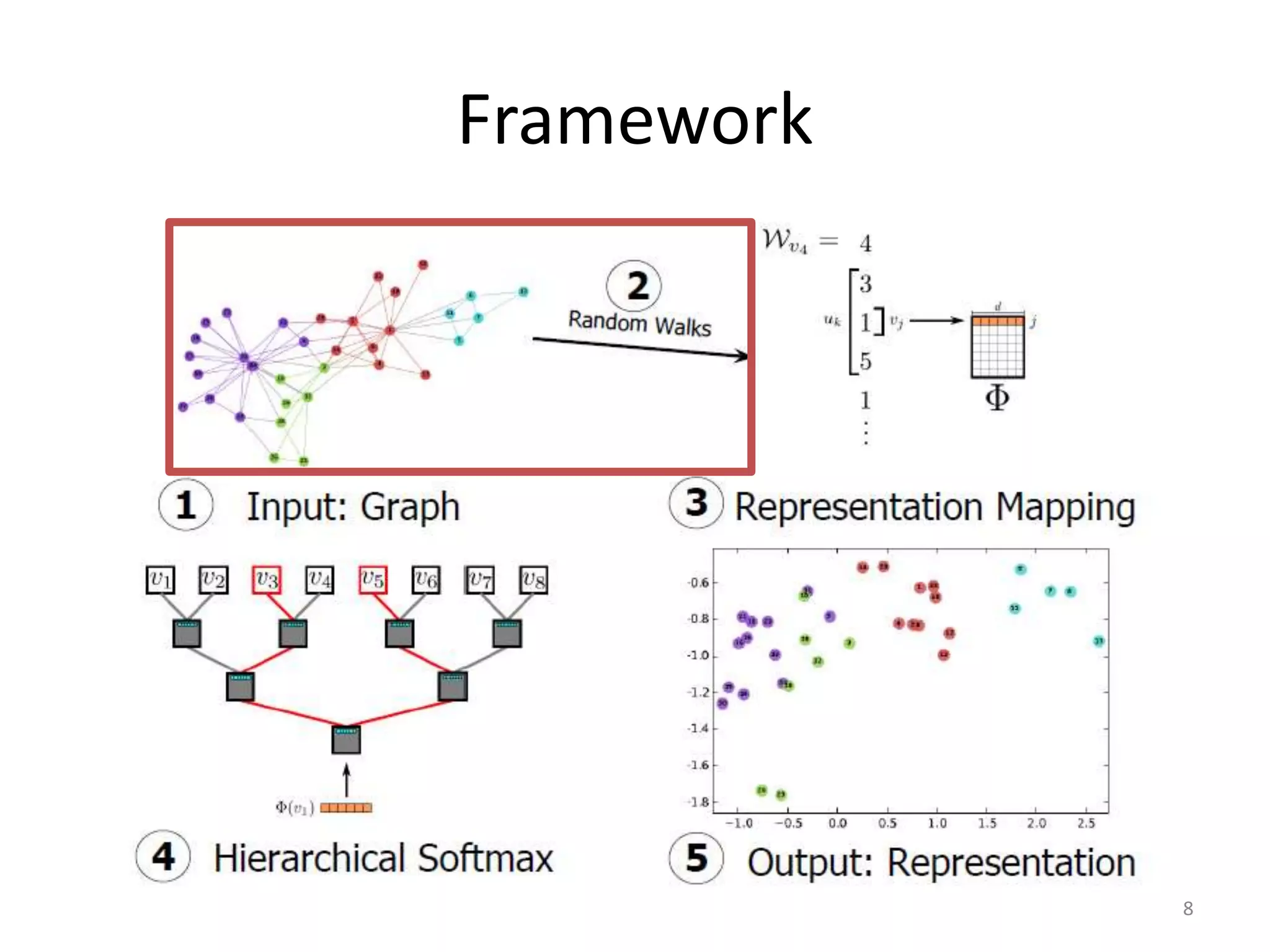
Language modeling
• Corpus안에서 특정 word
sequence가 얼마나 나오는지
• 문서상에서 word의 latent
representation을
학습함(word co-occurrence):
– word2vec:
• 단어의 semantic한 의미를
나타낼 수 있다
5
6.
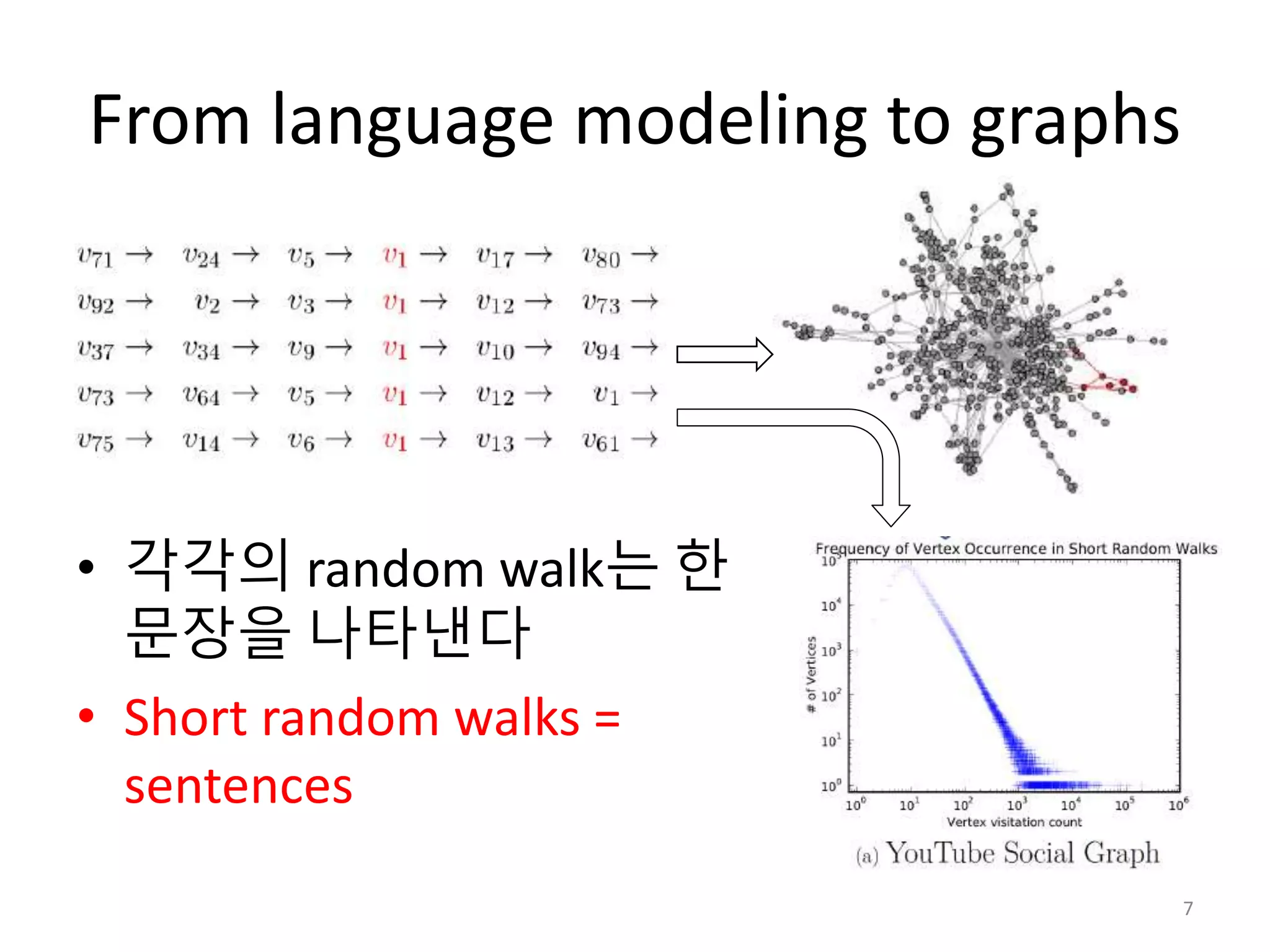
From language modelingto graphs
• 자연어 corpus에서 단어의
빈도가 power law를 따른다
• scale-free graph의 Random
walk에서 vertex frequency
역시 power law를 따른다
6
7.
From language modelingto graphs
• 각각의 random walk는 한
문장을 나타낸다
• Short random walks =
sentences
7
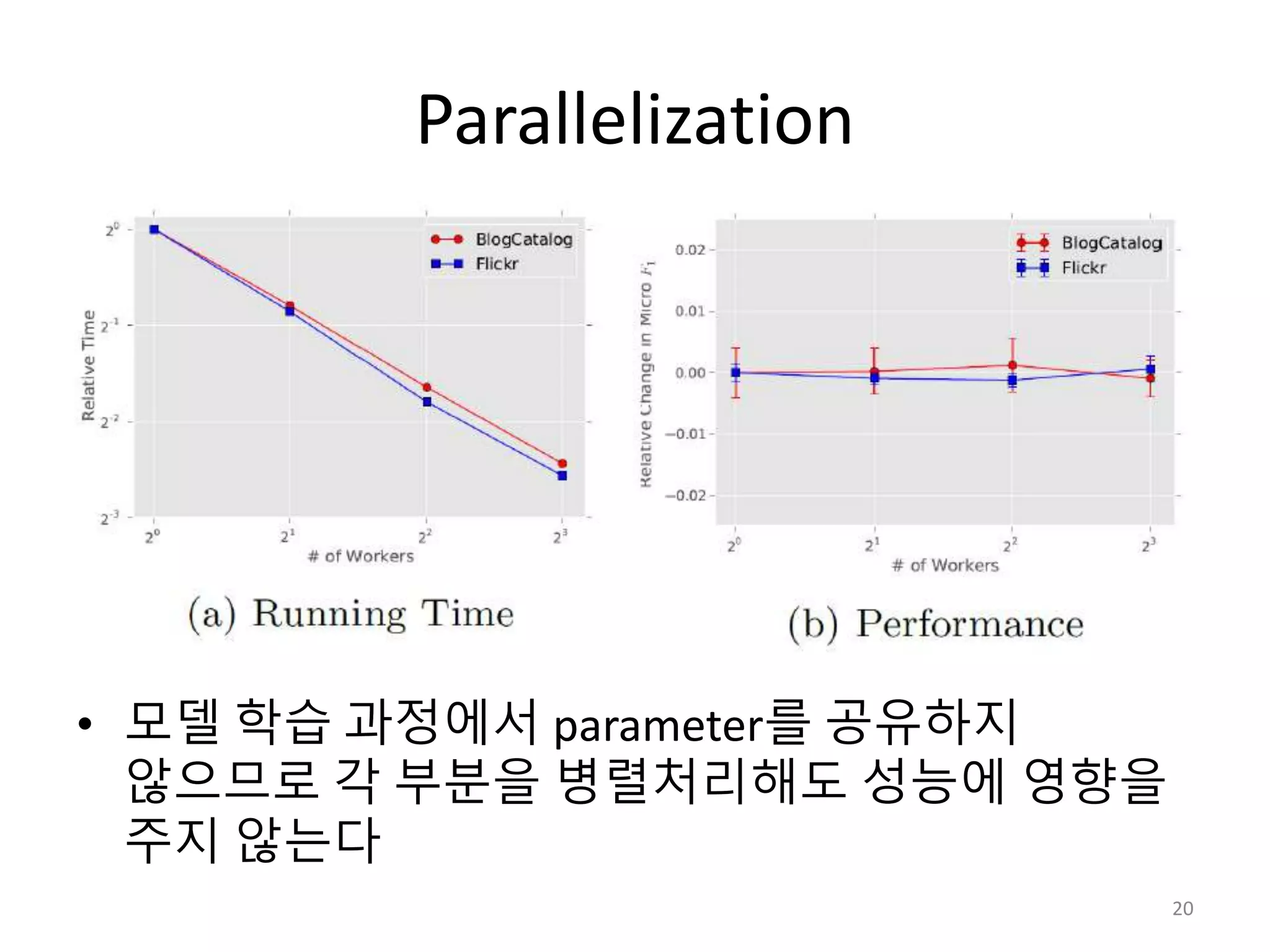
Conclusions
• Network로 표현되는데이터를 continuous
vector space 상에서 표현하여 학습이
가능하다.
• Word sequence들을 graph로 표현하여
language model에 사용 가능하다.
• label이 부족한 경우에도 잘 작동하다.
• 큰 graph에도 Scalable하기 때문에 online
learning에 사용 가능하다
21













![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)







![[부스트캠프 Tech Talk] 신원지_Wandb Visualization](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkshinwonji-211210113635-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/170224qrnn-170224005353-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20160113-170222033302-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Exploiting Cyclic Symmetry in Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170217-170228044623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]TREE-STRUCTURED VARIATIONAL AUTOENCODER](https://cdn.slidesharecdn.com/ss_thumbnails/161216tree-structuredvae-161216031644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...](https://cdn.slidesharecdn.com/ss_thumbnails/20170203dlhacks-170203004925-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Unsupervised Learning of 3D Structure from Images](https://cdn.slidesharecdn.com/ss_thumbnails/sugihara-161213071700-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Semi supervised qa with generative domain-adaptive nets](https://cdn.slidesharecdn.com/ss_thumbnails/semi-supervisedqawithgenerativedomain-adaptivenets-170317041122-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning What and Where to Draw (NIPS’16)](https://cdn.slidesharecdn.com/ss_thumbnails/20170120misono-170215035536-thumbnail.jpg?width=640&height=640&fit=bounds)


![[226]대용량 텍스트마이닝 기술 하정우](https://cdn.slidesharecdn.com/ss_thumbnails/226-161025031656-thumbnail.jpg?width=640&height=640&fit=bounds)









![[사이람 커넥트] 그래프 머신러닝 기술과 혁신 사례 - 그래프 머신러닝의 의의와 핵심 기술](https://cdn.slidesharecdn.com/ss_thumbnails/random-250512073631-8f5414ce-thumbnail.jpg?width=640&height=640&fit=bounds)

![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















