Downloaded 23 times






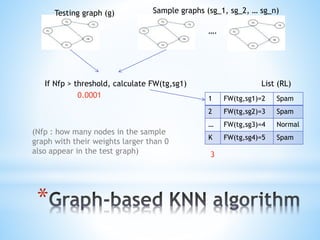
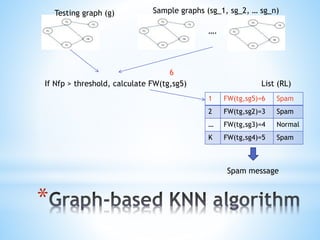
![*
NUS SMS Corpus (5,574 messages)
– 4,827 normal(86.6%), 747 spam(13.4%)
[Uysal and Yildiz] SMS
collection
(875 messages)
- 450 normal, 425 spam](https://image.slidesharecdn.com/graph-basedknnalgorithmforspamsmsdetection-150305195058-conversion-gate01/85/Graph-based-KNN-Algorithm-for-Spam-SMS-Detection-13-320.jpg)
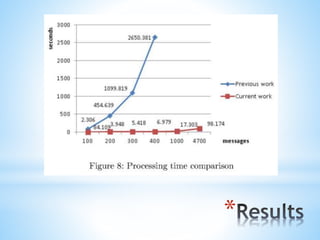
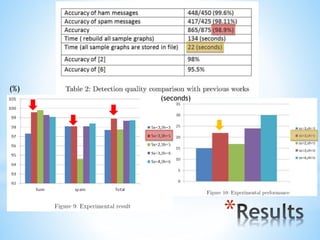


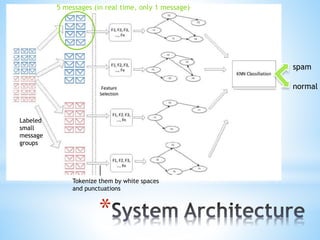
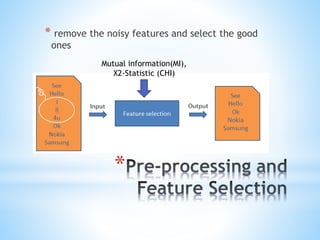
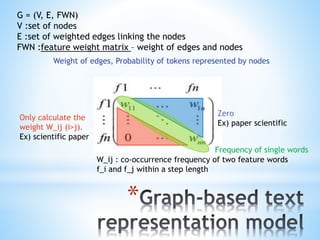
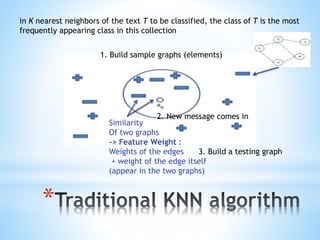
The document discusses a content-based approach to classify spam SMS messages using graph-based text representation and KNN algorithms. It details the process of feature selection, including mutual information and chi-statistic, to weigh tokens that indicate whether a message is spam or normal. The methodology also highlights the evolution of spam messages and the need to consider communication patterns alongside content for accurate classification.

































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)

