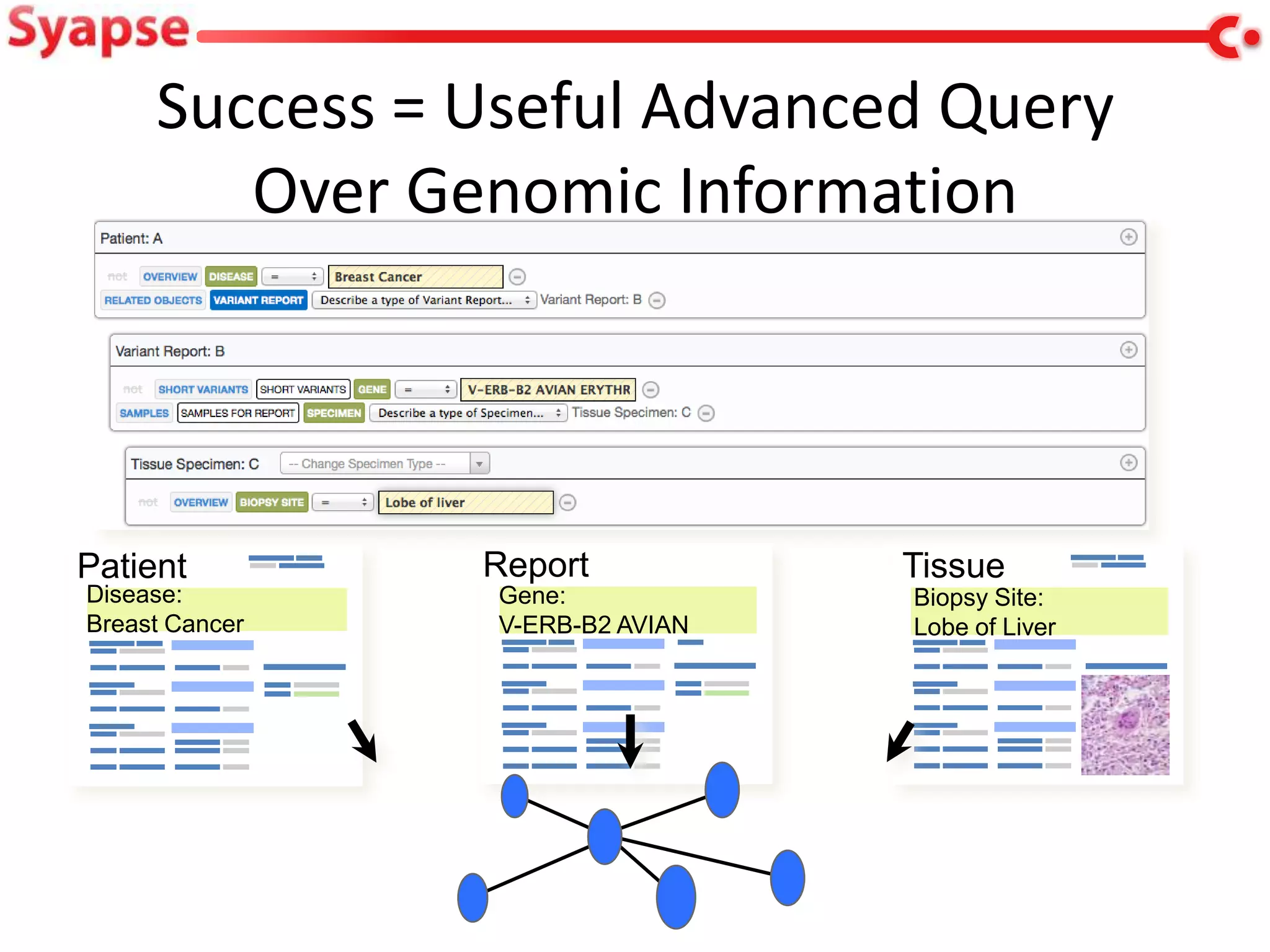
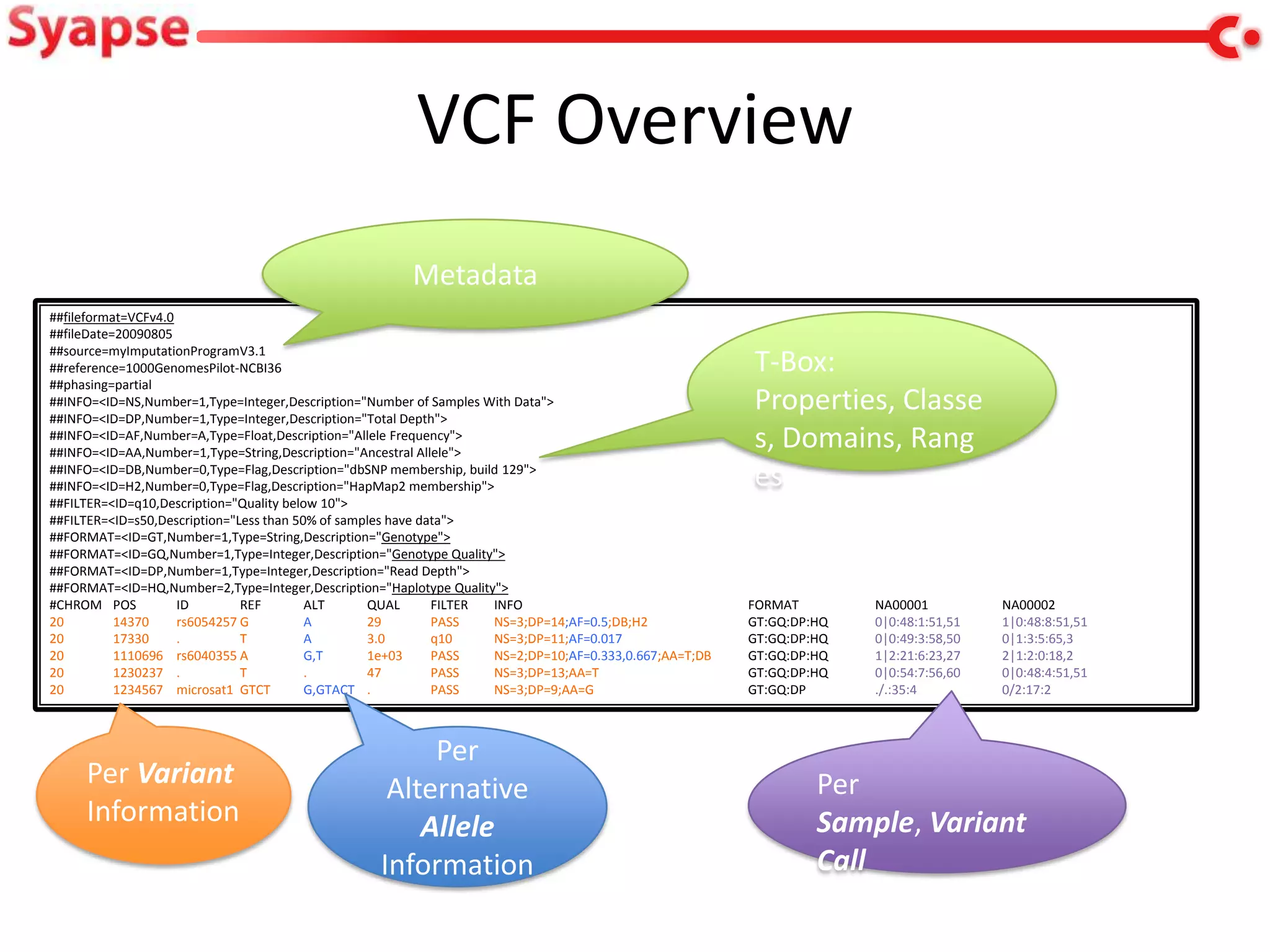
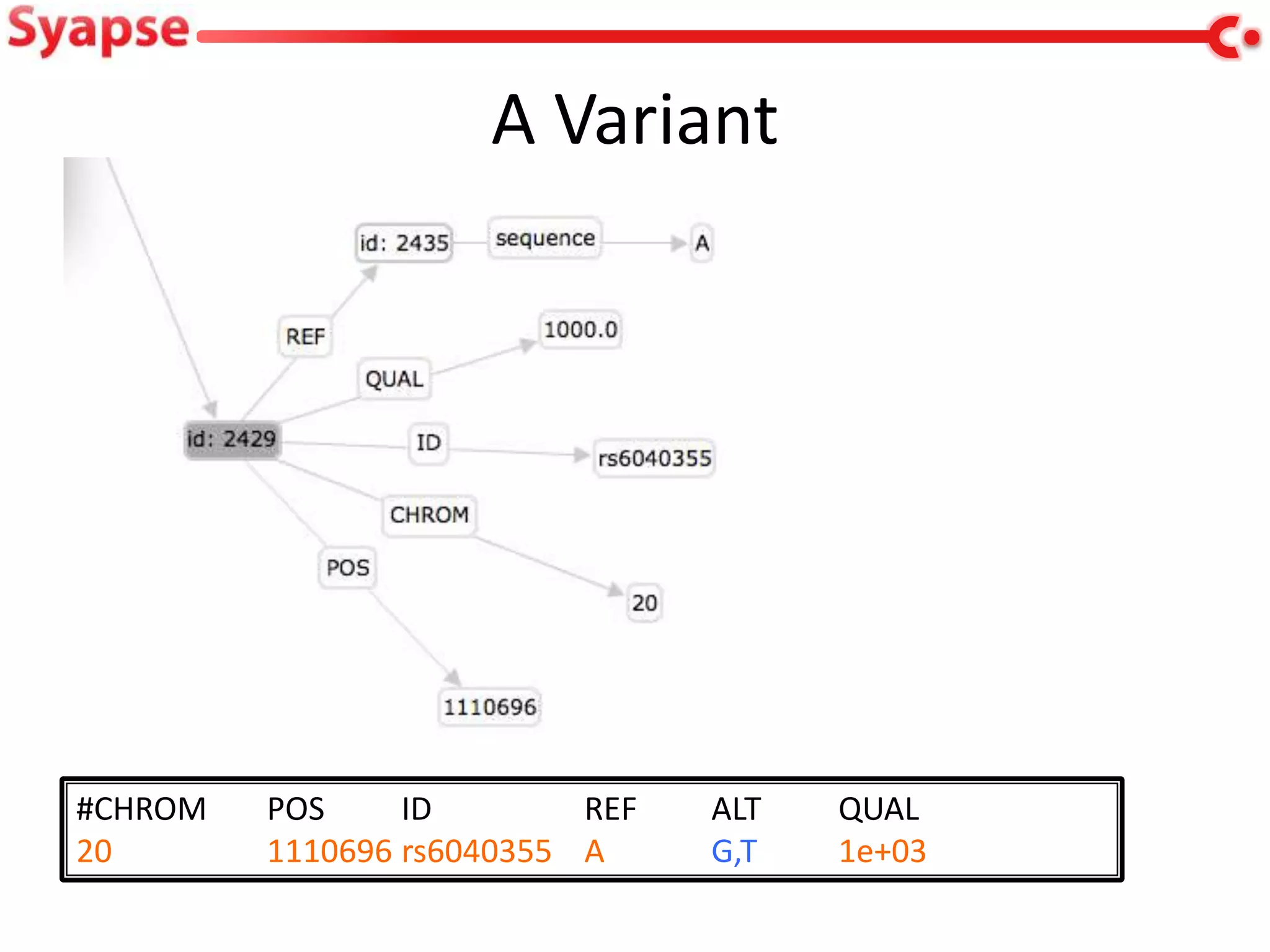
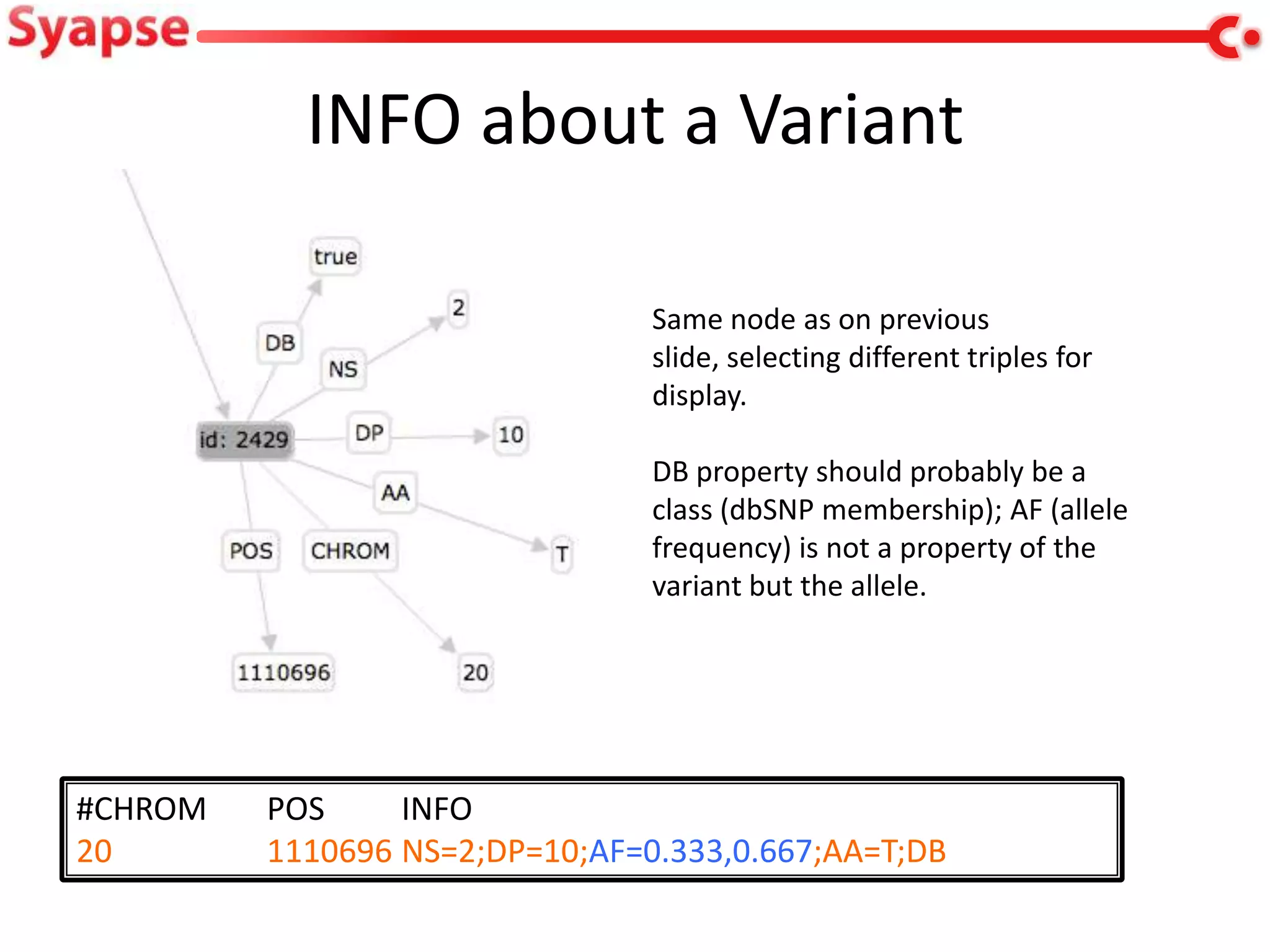
This document explores mapping variant call format (VCF) genomic data into resource description framework (RDF) triples. It presents examples of transforming VCF metadata, variant-level information, allele information, and genotype calls into RDF. It discusses challenges around materializing versus virtual transformations and questions whether the transformed data would be useful for querying to answer interesting biological questions.


![Background
• Syapse Discovery provides an end-to-end
solution for […] laboratories deploying next-
generation sequencing-based diagnostics, […]
configurable semantic data structure enables
users to bring omics data together with
traditional medical information […]
• This work: initial exploration of VCF
import, what useful information is in a VCF
etc.](https://image.slidesharecdn.com/w3c-jjc-lifesci-130401125200-phpapp01/75/VCF-and-RDF-3-2048.jpg)




















































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
