Downloaded 1,872 times




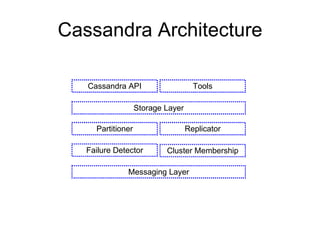
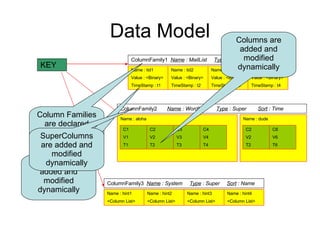

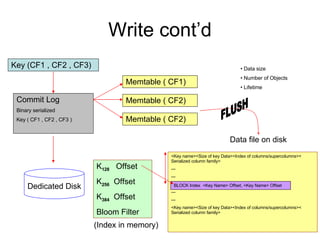
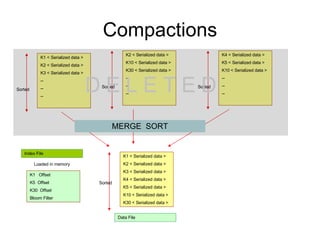

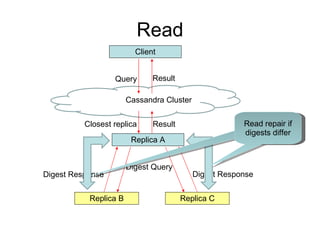
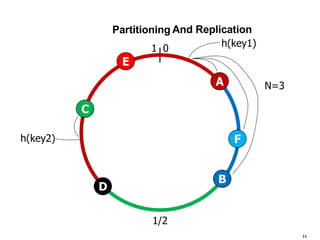




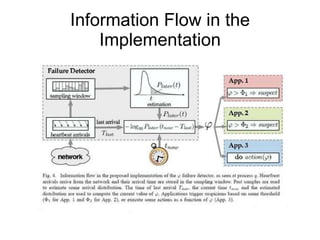





Cassandra is a structured storage system designed for large amounts of data across commodity servers. It provides high availability with eventual consistency and scales incrementally without centralized administration. Data is partitioned across nodes and replicated for fault tolerance. Writes are applied locally and propagated asynchronously, prioritizing availability over consistency. It uses a gossip protocol for membership and failure detection.







































































































