Download to read offline







![super simple solution
haskell
fizzBuzz :: Integer -> String
fizzBuzz i
| i `mod` 15 == 0 = "fizzbuzz"
| i `mod` 5 == 0 = "buzz"
| i `mod` 3 == 0 = "fizz"
| otherwise = show i
mapM_ (putStrLn . fizzBuzz) [1..100]
ok, then python
def fizz_buzz(i):
if i % 15 == 0: return "fizzbuzz"
elif i % 5 == 0: return "buzz"
elif i % 3 == 0: return "fizz"
else: return str(i)
for i in range(1, 101):
print(fizz_buzz(i))](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-10-2048.jpg)


![ground truth
def fizz_buzz_encode(i):
if i % 15 == 0: return np.array([0, 0, 0, 1])
elif i % 5 == 0: return np.array([0, 0, 1, 0])
elif i % 3 == 0: return np.array([0, 1, 0, 0])
else: return np.array([1, 0, 0, 0])](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-13-2048.jpg)


![feature selection - cheating clever
def x(i):
return np.array([1, i % 3 == 0, i % 5 == 0])
def predict(x):
return np.dot(x, np.array([[ 1, 0, 0, -1],
[-1, 1, -1, 1],
[-1, -1, 1, 1]]))
for i in range(1, 101):
prediction = np.argmax(predict(x(i)))
print([i, "fizz", "buzz", "fizzbuzz"][prediction])
It's hard to
imagine an
interviewer
who wouldn't
be impressed
by even this
simple
solution.](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-16-2048.jpg)
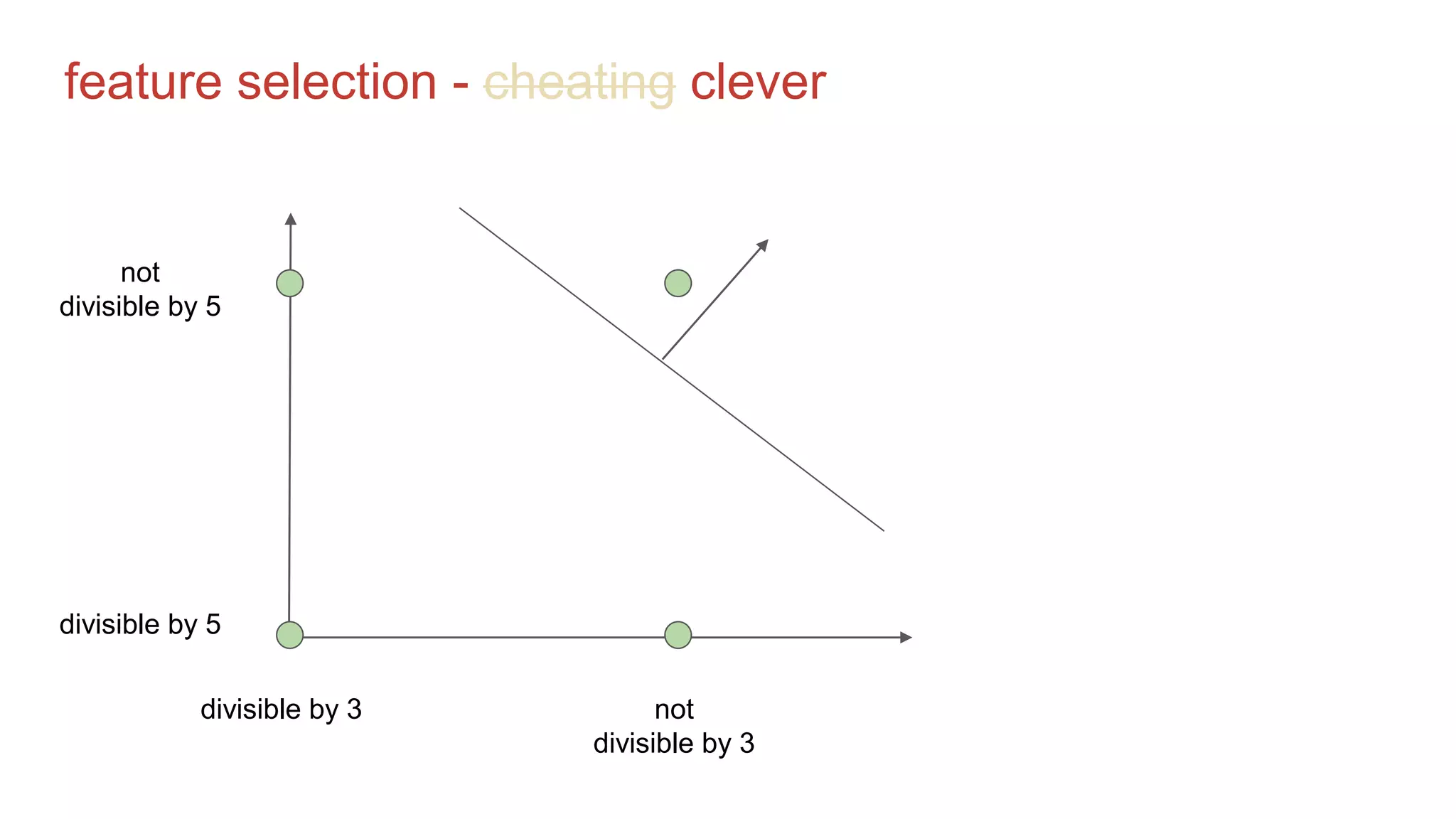
![what if we aren't that clever?
binary encoding, say 10
digits (up to 1023)
1 -> [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
2 -> [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
3 -> [1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
and so on
in comments, someone
suggested one-hot decimal
encoding the digits, say up to
999
315 -> [0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
and so on](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-18-2048.jpg)

![tensorflow in one slide
import numpy as np
import tensorflow as tf
X = tf.placeholder("float", [None, input_dim])
Y = tf.placeholder("float", [None, output_dim])
beta = tf.Variable(tf.random_normal(beta_shape, stddev=0.01))
def model(X, beta):
# some function of X and beta
p_yx = model(X, beta)
cost = some_cost_function(p_yx, Y)
train_op = tf.train.SomeOptimizer.minimize(cost)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
for _ in range(num_epochs):
sess.run(train_op, feed_dict={X: trX, Y: trY})
the extent of what I know
about
standard
imports
placeholders for our
data
parameters to
learn
some parametric
model
applied to the symbolic
variables
train by minimizing some cost
function
create session and initialize
variables
train using
data](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-20-2048.jpg)
![Visualizing the results (a hard problem by itself)
1 100correct "11"
incorrect "buzz"
actual "fizzbuzz"
correct "fizz"
black + red = predictions
black + tan = actuals
predicted "fizz"
actual "buzz"
[[30, 11, 6, 2],
[12, 8, 4, 1],
[ 4, 3, 2, 3],
[ 4, 2, 0, 0]]](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-21-2048.jpg)
![linear regression
def model(X, w, b):
return tf.matmul(X, w) + b
py_x = model(data.X, w, b)
cost = tf.reduce_mean(tf.pow(py_x - data.Y, 2))
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost)
binary
decimal
[[54, 27, 14, 6],
[ 0, 0, 0, 0],
[ 0, 0, 0, 0],
[ 0, 0, 0, 0]]
[[54, 27, 0, 0],
[ 0, 0, 0, 0],
[ 0, 0, 14, 6],
[ 0, 0, 0, 0]]
black + red = predictions
black + tan = actuals](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-22-2048.jpg)
![logistic regression
def model(X, w, b):
return tf.matmul(X, w) + b
py_x = model(data.X, w, b)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(py_x, data.Y))
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost)
binary
[[54, 27, 14, 6],
[ 0, 0, 0, 0],
[ 0, 0, 0, 0],
[ 0, 0, 0, 0]]
[[54, 27, 0, 0],
[ 0, 0, 0, 0],
[ 0, 0, 14, 6],
[ 0, 0, 0, 0]]
decimal
black + red = predictions
black + tan = actuals](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-23-2048.jpg)

![by # of hidden units (after 1000's of epochs)
5
10
25
50
100
200
[[52, 2, 1, 0],
[ 0, 25, 0, 0],
[ 1, 0, 13, 0],
[ 0, 0, 0, 6]]
[[45, 16, 3, 0],
[ 8, 11, 1, 0],
[ 0, 0, 10, 0],
[ 0, 0, 0, 6]]
black + red = predictions
black + tan = actuals](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-25-2048.jpg)

![HIDDEN LAYERS (50% dropout in 1st hidden layer)
[100, 100]
will sometimes get it 100% right, but not reliably
[2000, 2000]
seems to get it exactly right every time (in ~200 epochs)
black + red = predictions
black + tan = actuals](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-27-2048.jpg)
![But how does it work?
25-hidden-neuron shallow net was simplest interesting model
in particular, it gets all the "divisible by 15" exactly right
not obvious to me how to learn "divisible by 15" from binary
[[45, 16, 3, 0],
[ 8, 11, 1, 0],
[ 0, 0, 10, 0],
[ 0, 0, 0, 6]]
black + red = predictions
black + tan = actuals](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-28-2048.jpg)
![which inputs produce largest "fizz buzz" values?
(120, array([ -4.51552565, -11.66495565, -17.10086776, 0.32237191])),
(240, array([ -5.04136949, -12.02974626, -17.35017639, 0.07112655])),
(90, array([ -4.52364648, -11.48799399, -16.91179542, -0.20747044])),
(465, array([ -4.95231711, -11.88604214, -17.5155363 , -0.34996536])),
(210, array([ -5.04364677, -11.85627498, -17.17183826, -0.4049097 ])),
(720, array([ -4.98066528, -11.68684173, -17.01117473, -0.46671827])),
(345, array([ -4.49738021, -11.34621705, -16.88004503, -0.4713167 ])),
(600, array([ -4.48999048, -11.30909995, -16.70980522, -0.53889132])),
(360, array([ -9.32991992, -15.18924931, -17.8993147 , -4.35817601])),
(480, array([ -9.79430086, -15.72038142, -18.51560547, -4.38727747])),
(450, array([ -9.80194752, -15.54985676, -18.32664509, -4.89815184])),
(330, array([ -9.34660544, -15.01537882, -17.69651957, -4.95658813])),
(960, array([ -9.74109305, -15.37921101, -18.16552369, -4.95677615])),
(840, array([ -9.31266483, -14.83212949, -17.49181923, -5.26606825])),
(105, array([ -8.73320381, -11.08279653, -9.31921242, -5.52620068])),
(225, array([ -9.22702329, -11.50045288, -9.64725618, -5.76014854])),
(585, array([ -8.62907369, -10.84616688, -9.23592859, -5.79517941])),
(705, array([ -9.12030976, -11.2651869 , -9.56738927, -6.02974533])),
last column only needs
to be larger than the
other columns but in
this case it works out --
these are all divisible
by 15
notice that they cluster
into similar outputs
notice also that we
have pairs of numbers
that differ by 120](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-29-2048.jpg)

![two-bit SWAPS that are congruent mod 15
-8 +128 = +120
120 [0 0 0 1 1 1 1 0 0 0]
240 [0 0 0 0 1 1 1 1 0 0]
+2 -32 = -30 (from 120/240)
90 [0 1 0 1 1 0 1 0 0 0]
210 [0 1 0 0 1 0 1 1 0 0]
-32 +512 = +480 (from 120/240)
600 [0 0 0 1 1 0 1 0 0 1]
720 [0 0 0 0 1 0 1 1 0 1]
+1 -256 = -255 (from 600/720)
345 [1 0 0 1 1 0 1 0 1 0]
465 [1 0 0 0 1 0 1 1 1 0]](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-31-2048.jpg)
![two-bit SWAPS that are congruent mod 15
-8 +128 = +120
120 [0 0 0 1 1 1 1 0 0 0]
240 [0 0 0 0 1 1 1 1 0 0]
+2 -32 = -30
90 [0 1 0 1 1 0 1 0 0 0]
210 [0 1 0 0 1 0 1 1 0 0]
-32 +512 = +480
600 [0 0 0 1 1 0 1 0 0 1]
720 [0 0 0 0 1 0 1 1 0 1]
+1 -256 = -255
345 [1 0 0 1 1 0 1 0 1 0]
465 [1 0 0 0 1 0 1 1 1 0]
-8 +128
360 [0 0 0 1 0 1 1 0 1 0]
480 [0 0 0 0 0 1 1 1 1 0]
330 [0 1 0 1 0 0 1 0 1 0]
450 [0 1 0 0 0 0 1 1 1 0]
840 [0 0 0 1 0 0 1 0 1 1]
960 [0 0 0 0 0 0 1 1 1 1]](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-32-2048.jpg)
![two-bit SWAPS that are congruent mod 15
-8 +128 = +120
120 [0 0 0 1 1 1 1 0 0 0]
240 [0 0 0 0 1 1 1 1 0 0]
+2 -32 = -30
90 [0 1 0 1 1 0 1 0 0 0]
210 [0 1 0 0 1 0 1 1 0 0]
-32 +512 = +480
600 [0 0 0 1 1 0 1 0 0 1]
720 [0 0 0 0 1 0 1 1 0 1]
+1 -256 = -255
345 [1 0 0 1 1 0 1 0 1 0]
465 [1 0 0 0 1 0 1 1 1 0]
-8 +128
360 [0 0 0 1 0 1 1 0 1 0]
480 [0 0 0 0 0 1 1 1 1 0]
330 [0 1 0 1 0 0 1 0 1 0]
450 [0 1 0 0 0 0 1 1 1 0]
840 [0 0 0 1 0 0 1 0 1 1]
960 [0 0 0 0 0 0 1 1 1 1]
105 [1 0 0 1 0 1 1 0 0 0]
225 [1 0 0 0 0 1 1 1 0 0]
-32 +512
585 [1 0 0 1 0 0 1 0 0 1]
705 [1 0 0 0 0 0 1 1 0 1]
any neuron with the same weight on those
two inputs will produce the same outcome
if they're swapped
if you want to drive yourself mad, spend a
few hours staring at the neuron weights
themselves!](https://image.slidesharecdn.com/07grusfizzbuzzintensorflow-wrangleconf20161-160829191856/75/Wrangle-2016-Lightning-Talk-FizzBuzz-in-TensorFlow-33-2048.jpg)




This document discusses using machine learning to solve the "Fizz Buzz" problem in an unconventional way. The author first presents simple Python solutions to Fizz Buzz. He then frames Fizz Buzz as a classification problem, where the goal is to predict the correct "Fizz", "Buzz", "FizzBuzz", or number output given an input number. Various machine learning models are applied to this problem, including linear regression, logistic regression, multilayer perceptrons, and deep learning models. The author finds that deeper neural networks can reliably solve Fizz Buzz after training.





































![Instacart_Presentation[1]](https://cdn.slidesharecdn.com/ss_thumbnails/d49bb9f3-ce45-452e-a8c2-b91747921356-150620044625-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











































