Download as PDF, PPTX








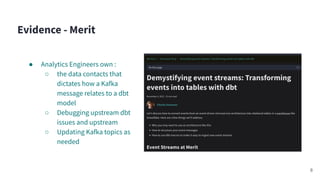



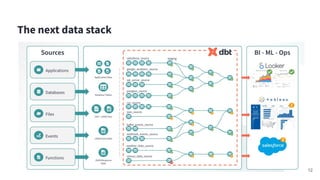




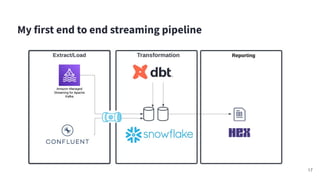

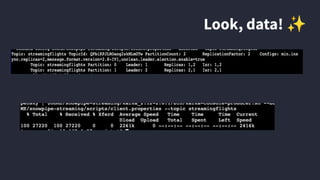




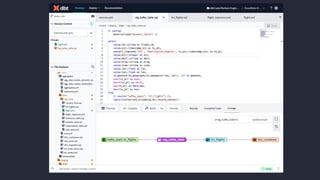









Amy Chen's presentation at Kafka Summit 2023 focuses on the role of Apache Kafka in enhancing the skills of analytics engineers. She emphasizes the importance of practical experience and knowledge in areas like AWS architecture, data warehousing, and monitoring to effectively utilize Kafka for data streaming. The document outlines her personal learning journey, the tools used, and key lessons learned while building a streaming analytics pipeline.




![[오픈소스컨설팅] Red Hat ReaR (relax and-recover) Quick Guide](https://cdn.slidesharecdn.com/ss_thumbnails/redhatrearrelax-and-recoverquickguidev1-170419093210-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































